文章目录
- 一.JPA,Hibernate,Spring Data JPA之间关系
- 实例表
- 二.Hibernate基本使用
- 三.基于Hibernate的JPA的基本使用
- 四.springDataJpa的基本使用
- 五.springBootDataJpa
- spring-data-jpa官方文档地址
- 1.访问数据库的传统方式
- 2.SpringBootDataJpa基本配置
- 3.SpringBootDataJpa常用注解
- 4.SpringDataJpa数据持久化两种方式
- 5.Spring Data JPA 的接口继承结构
- 5.1.CrudRepository
- 5.2.PagingAndSortingRepository
- 5.3.JpaRepository
- 5.4.QueryByExampleExecutor
- 5.5.JpaSpecificationExecutor
- 5.6.使用save方法添加/修改数据
- 5.7.根据id查询
- 5.8.Repository方法的Null值处理
- 5.9.自定义删除/修改
- 5.10. 使用`SPEL表达式`
- 6.基于方法名称命名规则查询
- 7.基于@Query 注解查询
- 8.分页及排序
- 9.@NamedQueries创建查询
- 10.多表查询
- 11.审计字段
- 12. 使用@MappedSuperclass抽出实体的公共字段
其实很多框架都是对另一个框架的封装,我们在学习类似的框架的时候,难免会进入误区
一.JPA,Hibernate,Spring Data JPA之间关系
Java 持久层框架访问数据库的方式大致分为两种。
- 一种
以 SQL 核心,封装一定程度的 JDBC 操作,比如: MyBatis。 - 另一种是
以 Java 实体类为核心,将实体类的和数据库表之间建立映射关系,也就是我们说的ORM框架,如:Hibernate、Spring Data JPA
1.JPA
1.1.JPA是什么
JPA全称为Java Persistence API(Java持久层API),是一个基于ORM(或叫O/R mapping ,对象关系映射) 的标准规范,在这个规范中,JPA只定义标准规则,不提供实现。
- 它是Sun公司在
Java5中提出的Java持久化规范,内部由一系列的接口和抽象类构成。可以通过注解或者XML描述对象-关系表之间的映射关系,并将运行期的实体对象持久化到数据库。 - 目前,JPA的主要实现有Hibernate,EclipseLink,OpenJPA等。
- 由于Hibernate在数据访问解决技术领域的霸主地位,所以JPA标准基本由Hibernate主导。
需要注意的是JPA
统一了Java应用程序访问ORM框架的规范,使得应用程序以统一的方式访问持久层
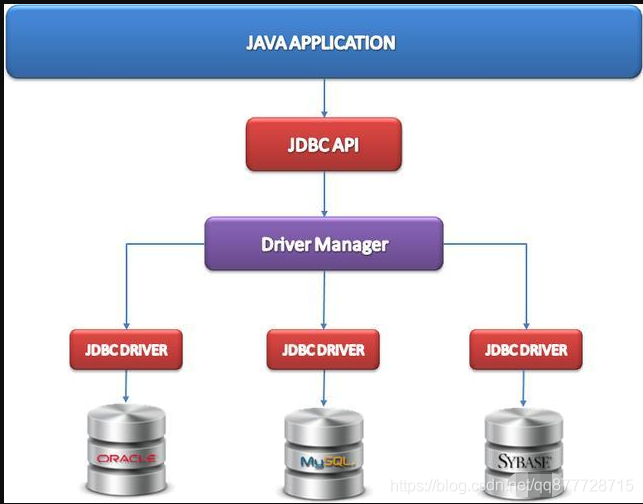
我们知道不同的数据库厂商都有自己的实现类,后来统一规范也就有了数据库驱动,Java在操作数据库的时候,底层使用的其实是JDBC,而JDBC是一组操作不同数据库的规范。我们的Java应用程序,只需要调用JDBC提供的API就可以访问数据库了,而JPA也是类似的道理。
1.2.JPA提供的规范
JPA为我们提供了以下规范:
-
ORM映射元数据:JPA支持
XML和注解两种元数据的形式描述对象和表之间的映射关系,框架据此将实体对象持久化到数据库表中如:@Entity、@Table、@Column、@Transient等注解。
-
JPA 的API:用来操作实体对象,执行CRUD操作,框架在后台替我们完成所有的事情,开发者从繁琐的JDBC和SQL代码中解脱出来
如:entityManager.merge(T t);
-
JPQL查询语言:通过
面向对象而非面向数据库的查询语言查询数据,避免程序的SQL语句紧密耦合。JPA定义了独特的JPQL(Java Persistence Query Language),JPQL是EJBQL的一种扩展,它是针对实体的一种查询语言,操作对象是实体,而不是关系数据库的表,而且能够支持批量更新和修改、JOIN、GROUP BY、HAVING 等通常只有 SQL 才能够提供的高级查询特性,甚至还能够支持子查询。
.
如:from Student s where s.name = ?
但是:
JPA仅仅是一种规范,也就是说JPA仅仅定义了一些接口,而接口是需要实现才能工作的。所以底层需要某种实现,而Hibernate就是实现了JPA接口的ORM框架。
2.Hibernate
2.1.Hibernate是什么
JPA是一套ORM规范,Hibernate实现了JPA规范!
Hibernate是一个开源的全自动ORM框架,它对JDBC进行了非常轻量级的对象封装,它将实体对象与数据库表建立映射关系,hibernate可以自动生成SQL语句,自动执行,使得Java程序员可以随心所欲的使用对象编程思维来操纵数据库。
- Hibernate 不仅关注于 从
Java对象到数据库表的映射,也有Java 数据类型到SQL 数据类型的映射。

2.2.Hibernate 和 JPA的关系
JPA和Hibernate的关系就像
JDBC和JDBC驱动的关系,JPA是规范,Hibernate除了作为ORM框架之外,它也是一种JPA实现。JPA怎么取代Hibernate呢?JDBC规范可以驱动底层数据库吗?答案是否定的,也就是说,如果使用JPA规范进行数据库操作,底层需要hibernate作为其实现类完成数据持久化工作。
JPA和Hibernate的关系:
- JPA是一个
规范,而不是框架 - Hibernate是
JPA的一种实现,是一个框架
2.3.Hibernate和Mybatis关系
-
Hibernate是一个自动化更强、更高级的框架,在java代码层面上,省去了绝大部分sql编写,取而代之的是用面向对象的方式操作关系型数据库的数据。
-
而MyBatis则是一个能够灵活编写sql语句,并将sql的入参和查询结果映射成POJO的一个持久层框架。从表面上看,Hibernate很方便、自动化更强,而MyBatis 在Sql语句编写方面则更灵活自由。
-
Hibernate是面向对象的,而MyBatis是面向关系的。当然,用Hibernate也可以写出面向关系代码和系统,但却得不到面向关系的各种好处,最大的便是编写sql的灵活性,同时也失去面向对象意义和好处——一句话,不伦不类。
一、应用场合:
传统公司、部分个人开发者喜欢用jpa;而互联网公司更青睐于mybatis
二.原因:
- mybatis更加灵活,开发迭代模式决定了他是互联网公司的首先;每一次的修改不会带来性能上的下降。
- 传统公司需求迭代速度慢、项目改动小,hibernate可以做到一劳永逸;hibernate容易因为添加关联关系或者开发者不了解优化导致项目,造成越改越糟糕。
二、各自特点:
- mybatis官方文档就说了他是一个半自动化的持久层框架,相对于按自动的hibernate更加灵活可控;
- mybatis的学习成本低于hibernate。
- 使用hibernate需要对他有深入的了解,尤其是缓存方面,作为一个持久层框架,性能还是第一位的。hibernate具有三级缓存,一级缓存默认是开启的,二级缓存需要手动开始并配置优化,三级缓存可以整合业界流行的缓存技术:redis,ecache等等。
- hibernate在关联查询中的懒加载。(在开发中,还是不建议去过多使用外键去关联操作)
- jpa是一种规范,hibernate也是遵从这种规范;
- springDataJpa是对repository的封装,简化了repository的操作。
灵活性方面,jpa更灵活,包括基本的增删改查、数据关系以及数据库的切换上都比mybatis灵活,但是jpa门槛较高,另外就是
更新数据需要先将数据查出来才能进行更新,数据量大的时候,jpa效率会低一些,这时候需要做一些额外的工作去处理!
3.Spring Data 是什么
Spring Data是Spring 社区的一个子项目,主要用于简化数据(关系型&非关系型)访问,其主要目标是使得数据库的访问变得方便快捷。
它提供很多模板操作
- Spring Data Elasticsearch: 简化Elasticsearch搜索引擎操作
- Spring Data MongoDB:分布式数据访问
- Spring Data Redis: 简化redis的操作
- Spring Data Solr:简化Solr搜索引擎操作
4.Spring Data Jpa
1.Spring Data Jpa是什么
Spring Data JPA是Spring Data的子模块,是在实现了JPA规范的基础上封装的一套 JPA 应用框架
- 虽然ORM框架都实现了JPA规范,但使用不同的ORM框架时需要编写不同的代码,使用Spring Data JPA能够方便大家
在使用不同的ORM框架之间进行切换而不需要更改代码。通过统一ORM框架的访问持久层的操作,来提高开发的效率。
Spring Data JPA也可以理解为 JPA 规范的再次封装抽象,底层还是使用了 Hibernate 的 JPA 技术实现
- JPA默认使用Hibernate作为ORM实现,所以,一般会使用Spring Data JPA就会使用Hibernate。
如图:
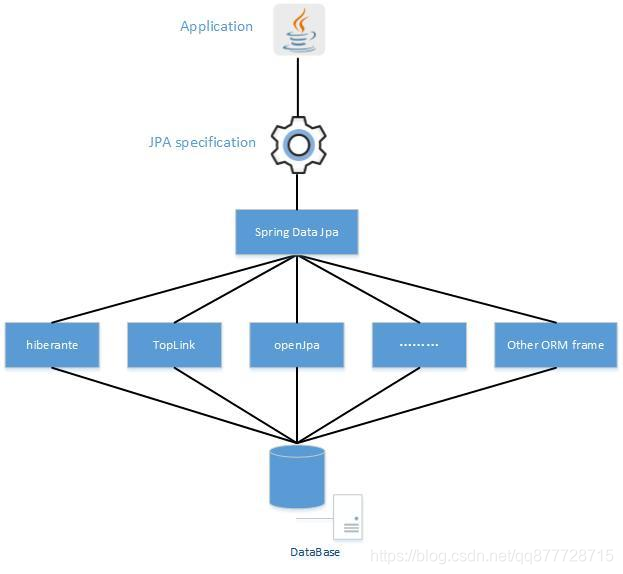
- Spring Data Jpa 是基于Repository的,作为使用者 ,重点就是如何定义自己的Repository接口,使用JPA规范编写增删改查方法
2.Spring Data JPA主要的类和接口
Repository 接口:
- Repository
- CrudRepository
- JpaRepository
Repository 实现类:
- SimpleJpaRepository
- QueryDslJpaRepository
以上这些类和接口就是我们以后在使用Spring Data JPA的时候需要掌握的
3.Spring Data JPA和Hibernate的关系
-
Hibernate是JPA的一种实现,是一个框架
-
Spring Data JPA不是一个实现或JPA提供的程序,它是spring提供的一套简化JPA开发的框架,它只是一个抽象层,主要用于减少为各种持久层存储实现数据访问层所需的样板代码量。但是它还是需要JPA提供实现程序,所以Spring Data JPA底层默认使用的就是 Hibernate实现。
5.Hibernate、JPA与Spring Data JPA之间的关系
- JPA是一套规范,内部是由接口和抽象类组成的。
- Hibernate是一套ORM框架,而且Hibernate实现了JPA规范,所以也可以称
hibernate为JPA的一种实现方式 - Spring Data JPA是Spring提供的一套对JPA操作更加高级的封装,是在JPA规范下的专门用来进行数据持久化的解决方案。
总结:
- JPA是一种规范,Hibernate实现了JPA规范,即Hibernate为JPA的一种实现;而Spring Data JPA是对JPA进行更高级的封装,让其Dao层编码变得更简单。
实例表
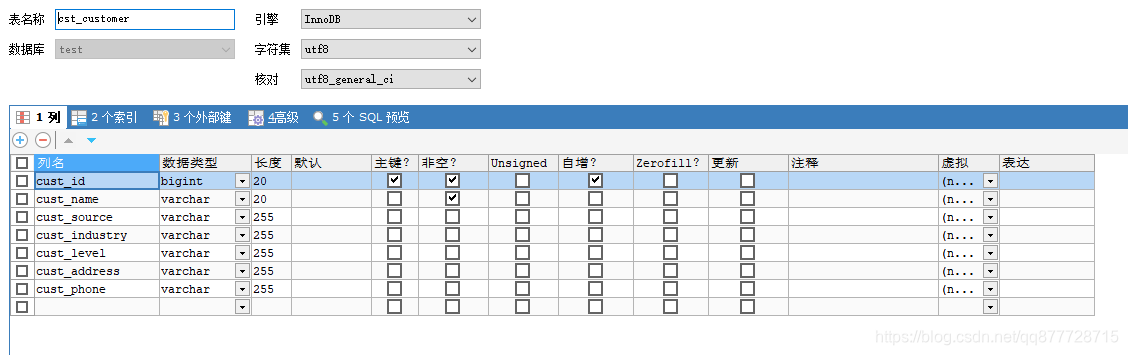
CREATE TABLE `cst_customer` (
`cust_id` bigint(20) NOT NULL AUTO_INCREMENT,
`cust_name` varchar(20) NOT NULL,
`cust_source` varchar(255) DEFAULT NULL,
`cust_industry` varchar(255) DEFAULT NULL,
`cust_level` varchar(255) DEFAULT NULL,
`cust_address` varchar(255) DEFAULT NULL,
`cust_phone` varchar(255) DEFAULT NULL,
PRIMARY KEY (`cust_id`),
UNIQUE KEY `UK_14ctafs86r97xwblaca93janm` (`cust_name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
二.Hibernate基本使用
1.基本配置
- 在
resources下创建Hibernate核心配置文件hibernate.cfg.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE hibernate-configuration PUBLIC
"-//Hibernate/Hibernate Configuration DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-configuration-3.0.dtd">
<!--hibernate核心配置文件-->
<hibernate-configuration>
<session-factory>
<!-- 1、数据库连接信息 -->
<property name="connection.url">jdbc:mysql://localhost:3306/test?serverTimezone=GMT%2b8</property>
<property name="connection.driver_class">com.mysql.jdbc.Driver</property><!--com.mysql.cj.jdbc.Driver-->
<property name="connection.username">root</property>
<property name="connection.password">root</property>
<!-- 设置连接池提供者 -->
<property name="hibernate.connection.provider_class">org.hibernate.connection.C3P0ConnectionProvider</property>
<!--c3p0连接池的配置 -->
<property name="hibernate.c3p0.max_size">20</property> <!--最大连接池 -->
<property name="hibernate.c3p0.min_size">5</property> <!--最小连接数 -->
<property name="hibernate.c3p0.timeout">120</property> <!--超时 -->
<property name="hibernate.c3p0.idle_test_period">3000</property> <!--空闲连接 -->
<!--2、数据库操纵信息-->
<!-- 可以将向数据库发送的sql显示出来 -->
<property name="hibernate.show_sql">true</property>
<!-- 格式化sql -->
<property name="hibernate.format_sql">true</property>
<!-- hibernate的方言 -->
<property name="hibernate.dialect">org.hibernate.dialect.MySQLDialect</property>
<!-- 指定自动生成数据表的策略 -->
<property name="hibernate.hbm2ddl.auto">update</property>
<!-- 用于设置事务提交方式 -->
<property name="hibernate.connection.autocommit">false</property>
<!--
设置事务隔离级别
1 Read Uncommited 可读未提交
2 Read Commited 可读已提交
4 Repeatable Read 可重复读
8 Serializable 串行化-->
<property name="hibernate.connection.isolation">4</property>
<!-- 配置和当前线程绑定的session进行开启配置 -->
<property name="hibernate.current_session_context_class">thread</property>
<!-- 3、添加实体类映射文件 -->
<mapping resource="com/hb/domain/Customer.hbm.xml" />
</session-factory>
</hibernate-configuration>
配置连接池需要引入对应的连接池驱动
<!-- 连接池C3P0 -->
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-c3p0</artifactId>
<version>5.0.7.Final</version>
</dependency>
- 创建实体类
Customer(和数据库表映射的类)(这里使用了lombok生成get/set方法)
package com.hb.domain;
import lombok.Data;
@Data
public class Customer {
private Long cust_id;// '客户编号(主键)',
private String cust_name;// '客户名称(公司名称)',
private String cust_source;// '客户信息来源',
private String cust_industry;//'客户所属行业',
private String cust_level;// '客户级别',
private String cust_address;// '客户联系地址',
private String cust_phone;// '客户联系电话',
}
- 在
Customer类的同级目录创建映射文件Customer.hbm.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd">
<!-- 描述类(Customer)和表(cst_customer)的映射关系 -->
<hibernate-mapping>
<!--
class标签: 作用类和表的映射的
name:类的全限定名(com.hb.entity.Customer)
table:表的全名(cst_customer)
name属性它是实体类的全名
table 表的名称
catalog 数据库名称
-->
<class name="com.hb.domain.Customer" table="cst_customer">
<!--
id标签:做类中的某个属性 和 表的主键映射关系
name:类的某个属性名
column:表的主键字段名
-->
<id name="cust_id" column="cust_id" type="java.lang.Long"> <!-- java数据类型 -->
<!-- 主键生成策略 native: AUTO_INCREMENT 让主键自动增长 -->
<generator class="native"></generator>
</id>
<!--使用property来描述属性与字段的对应关系 -->
<!-- property标签:做其它属性和其它字段的映射关系
name属性:类的其它属性名
column属性:表的其它字段名-->
<!-- ps:如果属性名和字段名一致 column可以省略不写-->
<property name="cust_name" column="cust_name" length="20" not-null="true" unique="true"/>
<property name="cust_source" column="cust_source" type="java.lang.String"/> <!-- hibernate数据类型 -->
<property name="cust_industry">
<column name="cust_industry" length="255" sql-type="varchar(255)"></column> <!-- sql数据类型 -->
</property>
<property name="cust_level" column="cust_level" type="java.lang.String"></property>
<property name="cust_address" column="cust_address" type="java.lang.String"></property>
<property name="cust_phone" column="cust_phone" type="java.lang.String"></property>
</class>
</hibernate-mapping>
4 创建工具类HibernateUtils
package com.hb.utils;
import org.hibernate.Session;
import org.hibernate.SessionFactory;
import org.hibernate.cfg.Configuration;
public class HibernateUtils {
static Configuration configuration = null;
static SessionFactory sessionFactory = null;
static {
// 加载一次配置文件
configuration = new Configuration();
configuration.configure();
// 获取一个sessionFactory
sessionFactory = configuration.buildSessionFactory();
}
// 从连接池获取的
public static Session openSession() {
return sessionFactory.openSession();
}
// 从当前线程中获取绑定的session
// 好处: 在多层之间调用方法获取的都是同一个session
public static Session getCurrentSession() {
/*特点: 1 默认是关闭的 需要配置开启
2 会自动给你关闭连接*/
Session session = sessionFactory.getCurrentSession();
return session;
}
}
获取管理hibernate的seesion对象就可以对数据库进crud了
2.CRUD操作
import com.hb.domain.Customer;
import com.hb.utils.HibernateUtils;
import org.hibernate.Session;
import org.hibernate.Transaction;
import org.hibernate.query.Query;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.List;
/**
* Hibernate的crud操作测试
*/
/*@RunWith(SpringRunner.class)*/
@SpringBootTest
public class TestHibernateCrud {
private static Session session;
private static Transaction tx;
/**
* 调用单元测试方法方法前的处理 获取会话/开启事务
*/
@Before
public void testBefore() {
System.out.println("openSession");
this.session = HibernateUtils.openSession();
System.out.println("session.beginTransaction");
this.tx = this.session.beginTransaction();
}
/**
* 调用单元测试方法方法前的处理 提交事务/关闭会话
*/
@After
public void testAfter() {
System.out.println("tx.commit");
this.tx.commit();
System.out.println("session.close");
this.session.close();
}
/**
* Hibernate新增
*/
@Test
public void testSave() {
Customer customer = new Customer();
customer.setCust_name("11111111");
this.session.save(customer);
}
/**
* Hibernate oid查询
*/
@Test
public void testOid() {
Customer customer = this.session.get(Customer.class, 6L);
System.out.println(customer);
}
/**
* Hibernate hql查询 下标
* 将HQL语句中的"?"改为JPA-style:
*/
@Test
public void testHSQLByIndex() {
// 条件查 类似sql语句的表达式 from 持久化类 where 属性=?
Query query = session.createQuery("FROM Customer WHERE cust_name like ?1 and cust_id=?2")
.setParameter(1, "h%")//模糊查询 h开头字符串
.setParameter(2, 2L);
List<Customer> list = query.list();
for (Customer customer : list) {
System.out.println(customer);
}
}
/**
* Hibernate hql查询 别名
* <p>
* 别名:要求必须以冒号开头:
*/
@Test
public void testHSQLByAlias() {
// 条件查 类似sql语句的表达式 from 持久化类 where 属性=?
Query query = session.createQuery("FROM Customer WHERE cust_name like :custName and cust_id=:custId")
.setParameter("custName", "h%")//模糊查询 h开头字符串
.setParameter("custId", 2L);
List<Customer> list = query.list();
for (Customer customer : list) {
System.out.println(customer);
}
}
/*
hibernate 中createQuery与createSQLQuery两者区别是:
前者用的hql语句进行查询,后者可以用sql语句查询
前者以hibernate生成的Bean为对象装入list返回,后者则是以对象数组进行存储
*/
/**
* 通过SQL方式查询—下标
*/
@Test
public void testSQLByIndex() {
// 单列查 返回是Object
Query query = this.session.createSQLQuery("select * from cst_customer where cust_name like ? and cust_id = ?")
.setParameter(1, "h%")//模糊查询 h开头字符串
.setParameter(2, 2L);
List<Object> list = query.list();
for (Object object : list) {
System.out.println(object);
}
}
/**
* 通过SQL方式查询—下标
*/
@Test
public void testSQLByIndex2() {
// 单列查 返回是Object
Query query = this.session.createSQLQuery("select * from cst_customer where cust_name like ?1 and cust_id = ?2")
.setParameter(1, "h%")//模糊查询 h开头字符串
.setParameter(2, 2L);
List<Object> list = query.list();
for (Object object : list) {
System.out.println(object);
}
}
/**
* 通过SQL方式查询—别名
*/
@Test
public void testSQLByAlias() {
// 单列查 返回是Object
Query query = this.session.createSQLQuery("select * from cst_customer where cust_name like :custName and cust_id =:custId")
.setParameter("custName", "h%")//模糊查询 h开头字符串
.setParameter("custId", 2L);
List<Object> list = query.list();
for (Object object : list) {
System.out.println(object);
}
}
}
如果使用 spring-boot-starter-data-jpa ,底层内置了Hibernate,不需要引入关于Hibernate的jar包
三.基于Hibernate的JPA的基本使用
1.基本配置
- 引入依赖
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.hibernate.version>5.0.7.Final</project.hibernate.version>
</properties>
<dependencies>
<!-- junit -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<!-- hibernate对jpa的支持包 -->
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-entitymanager</artifactId>
<version>${project.hibernate.version}</version>
</dependency>
<!-- c3p0 -->
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-c3p0</artifactId>
<version>${project.hibernate.version}</version>
</dependency>
<!-- log日志 -->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<!-- Mysql-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.6</version>
</dependency>
</dependencies>
- 在
resources目录下创建META-INF目录,并在该目录下创建persistence.xml文件

<?xml version="1.0" encoding="UTF-8"?>
<persistence xmlns="http://java.sun.com/xml/ns/persistence"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/persistence
http://java.sun.com/xml/ns/persistence/persistence_2_0.xsd"
version="2.0">
<!--以标准JPA方式使用hibernate 核心配置文件,默认情况下查找META-INF下面的persistence.xml -->
<!--配置持久化单元
name:持久化单元名称
transaction-type:事务类型
RESOURCE_LOCAL:本地事务管理
JTA:分布式事务管理 -->
<persistence-unit name="myJpa" transaction-type="RESOURCE_LOCAL">
<!--配置JPA规范的服务提供商 -->
<provider>org.hibernate.jpa.HibernatePersistenceProvider</provider>
<properties>
<!-- 数据库驱动 -->
<property name="javax.persistence.jdbc.driver" value="com.mysql.jdbc.Driver" />
<!-- 数据库地址 -->
<property name="javax.persistence.jdbc.url" value="jdbc:mysql://localhost:3306/test?characterEncoding=utf-8" />
<!-- 数据库用户名 -->
<property name="javax.persistence.jdbc.user" value="root" />
<!-- 数据库密码 -->
<property name="javax.persistence.jdbc.password" value="root" />
<!--jpa提供者的可选配置:我们的JPA规范的提供者为hibernate,所以jpa的核心配置中兼容hibernate的 -->
<!--配置jpa实现方(hibernate)的配置信息
显示sql : false|true
自动创建数据库表 : hibernate.hbm2ddl.auto
create : 程序运行时创建数据库表(如果有表,先删除表再创建)
update :程序运行时创建表(如果有表,不会创建表)
none :不会创建表
-->
<property name="hibernate.show_sql" value="true" />
<property name="hibernate.format_sql" value="true" />
<property name="hibernate.hbm2ddl.auto" value="update" />
</properties>
</persistence-unit>
</persistence>
- 创建和
数据表(cst_customer)和实体类(Customer)的映射
package com.jpa.domain;
import lombok.Data;
import javax.persistence.*;
import java.io.Serializable;
/**
* @Entity 作用:指定当前类是实体类。
*
* @Table 作用:指定实体类和表之间的对应关系。
* 属性:name:指定数据库表的名称
*
* @Id 作用:指定当前字段是主键。
* @GeneratedValue 作用:指定主键的生成方式。。
* 属性:strategy :指定主键生成策略。
*
* @Column 作用:指定实体类属性和数据库表之间的对应关系
* 属性:
* name:指定数据库表的列名称。
* unique:是否唯一
* nullable:是否可以为空
* inserttable:是否可以插入
* updateable:是否可以更新
* columnDefinition: 定义建表时创建此列的DDL
* secondaryTable: 从表名。如果此列不建在主表上(默认建在主表),该属性定义该列所在从表的名字搭建开发环境[重点]
*/
@Data
@Entity //声明该类是和数据库表映射的实体类
@Table(name = "cst_customer") //建立实体类与表的映射关系
public class Customer implements Serializable {
private static final long serialVersionUID = -4422124275710090220L;
@Id //声明当前私有属性为主键
@GeneratedValue(strategy = GenerationType.IDENTITY) //配置主键的生成策略,为自增主键
@Column(name = "cust_id")
private Long custId;
@Column(name = "cust_name") //指定和表中cust_name字段的映射关系
private String custName;
@Column(name = "cust_source") //指定和表中cust_source字段的映射关系
private String custSource;
@Column(name = "cust_industry")
private String custIndustry;
@Column(name = "cust_level")
private String custLevel;
@Column(name = "cust_address")
private String custAddress;
@Column(name = "cust_phone")
private String custPhone;
}
- 创建工具类JpaUtils,获取实体管理器
package com.jpa.utils;
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
import javax.persistence.Persistence;
/**
* 解决实体管理器工厂的浪费资源和耗时问题
* 通过静态代码块的形式,当程序第一次访问此工具类时,创建一个公共的实体管理器工厂对象
* <p>
* 第一次访问getEntityManager方法:经过静态代码块创建一个factory对象,再调用方法创建一个EntityManager对象
* 第二次方法getEntityManager方法:直接通过一个已经创建好的factory对象,创建EntityManager对象
*/
public class JpaUtils {
private static EntityManagerFactory entityManagerFactory;
static {
//1.加载配置文件,创建entityManagerFactory
entityManagerFactory = Persistence.createEntityManagerFactory("myJpa");
}
public static EntityManager getEntityManager() {
return entityManagerFactory.createEntityManager();
}
}
- 通过以上工具类,我们就可以得到`EntityManager实体管理类器来进行crud等操作。
- 在 JPA 规范中, EntityManager是完成持久化操作的核心对象。实体类作为普通 java对象,只有在调用 EntityManager将其持久化后才会变成持久化对象。EntityManager对象在
一组实体类与底层数据源之间进行 O/R 映射的管理。它可以用来管理和更新 Entity Bean, 根椐主键查找 Entity Bean, 还可以通过JPQL语句查询实体。 - 我们可以通过调用EntityManager的方法完成获取事务,以及持久化数据库的操作。
方法说明:
getTransaction : 获取事务对象
persist : 保存操作
merge : 更新操作
remove : 删除操作
find(立即加载)/getReference(延迟加载) : 根据id查询
2.CRUD操作
package com.test.springbootjpademo;
import com.jpa.domain.Customer;
import com.jpa.utils.JpaUtils;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import org.springframework.boot.test.context.SpringBootTest;
import javax.persistence.EntityManager;
import javax.persistence.EntityTransaction;
import java.util.Random;
@SpringBootTest
public class TestJpaCrud {
private static EntityManager em;
private static EntityTransaction tx;
/**
* 调用单元测试方法方法前的处理 获取EntityManager对象/开启事务
*/
@Before
public void testBefore() {
System.out.println("JpaUtils.getEntityManager");
//通过工具类来获取EntityManager对象
this.em = JpaUtils.getEntityManager();
System.out.println("em.getTransaction");
//获取事务对象
this.tx = this.em.getTransaction();
System.out.println("tx.begin");
//开启事务
this.tx.begin();
}
/**
* 调用单元测试方法方法后的处理 获取提交事务/关闭EntityManager对象
*/
@After
public void testAfter() {
System.out.println("tx.commit");
this.tx.commit(); //提交事务
System.out.println("em.close");
this.em.close(); //释放资源
}
/**
* 保存操作
*/
@Test
public void testPersist() {
//完成增删改查操作,保存一个用户到数据库中
Customer customer = new Customer();
customer.setCustName("授课");
customer.setCustIndustry("教育");
try {
//保存操作
em.persist(customer);
} catch (Exception e) {
System.out.println("tx.rollback");
// 回滚事务
tx.rollback();
e.printStackTrace();
}
}
/**
* 保存一个实体
*/
@Test
public void testPersist2() {
try {
Random random = new Random();
for (int i = 0; i < 100; i++) {
//int num = random.nextInt(10000000);
Thread.sleep(50);
Long num = System.currentTimeMillis();
// 定义对象
Customer c = new Customer();
c.setCustName("李家沟" + num);
c.setCustLevel("VIP客户" + num);
c.setCustSource("网络"+ num);
c.setCustIndustry("教育"+ num);
c.setCustAddress("昌平区北七家镇" + num);
c.setCustPhone("010-" + num);
// 执行操作
em.persist(c);
}
} catch (Exception e) {
// 回滚事务
tx.rollback();
e.printStackTrace();
}
}
/**
* 修改操作
*/
@Test
public void testMerge() {
try {
Customer c1 = em.find(Customer.class, 3L);
c1.setCustName("江苏NIUBIU学院");
em.clear();//把c1对象从缓存中清除出去
em.merge(c1);
} catch (Exception e) {
//回滚事务
tx.rollback();
e.printStackTrace();
}
}
/**
* 删除操作
*/
@Test
public void testRemove() {
try {
Customer c1 = em.find(Customer.class, 5L);
em.remove(c1);
} catch (Exception e) {
// 回滚事务
tx.rollback();
e.printStackTrace();
}
}
/**
* 查询操作find()
*/
@Test
public void testGetOne() {
try {
// 执行操作
Customer c1 = em.find(Customer.class, 3L);
System.out.println(c1); // 输出查询对象
} catch (Exception e) {
// 回滚事务
tx.rollback();
e.printStackTrace();
}
}
}
3.使用JPQL(java持久化查询语言)
与Hibernate的Hsql差不多
package com.test.springbootjpademo;
import com.jpa.domain.Customer;
import com.jpa.utils.JpaUtils;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import javax.persistence.EntityManager;
import javax.persistence.EntityTransaction;
import javax.persistence.Query;
import java.util.List;
/**
* 使用JPQL(java持久化查询语言)来查询数据-JPQL与hibernate的HQL方式类似。
*/
public class TestJpaJPsql {
private static EntityManager em;
private static EntityTransaction tx;
/**
* 调用单元测试方法方法前的处理 获取EntityManager对象/开启事务
*/
@Before
public void testBefore() {
System.out.println("JpaUtils.getEntityManager");
//通过工具类来获取EntityManager对象
this.em = JpaUtils.getEntityManager();
System.out.println("em.getTransaction");
//获取事务对象
this.tx = this.em.getTransaction();
System.out.println("tx.begin");
//开启事务
this.tx.begin();
}
/**
* 调用单元测试方法方法后的处理 获取提交事务/关闭EntityManager对象
*/
@After
public void testAfter() {
System.out.println("tx.commit");
this.tx.commit(); //提交事务
System.out.println("em.close");
this.em.close(); //释放资源
}
/**
* 查询全部的客户
* <p>
* TODO: 直接from查询出来的是一个映射对象,即:查询整个映射对象所有字段
*/
@Test
public void findAll() {
try {
String jpql = " from Customer";
//创建query对象
Query query = em.createQuery(jpql);
//使用query对象查询客户信息
List list = query.getResultList(); //查询所有的客户
for (Object object : list) {
System.out.println(object);
}
} catch (Exception e) {
//发生异常进行回滚
System.out.println("tx.rollback");
tx.rollback();
e.printStackTrace();
}
}
/**
* 查询全部的客户指定字段
*/
@Test
public void findAllField() {
try {
String jpql = "select custId,custName,custAddress from Customer";
//创建query对象
Query query = em.createQuery(jpql);
//使用query对象查询客户信息
List list = query.getResultList(); //查询所有的客户
for (Object object : list) {
System.out.println(object);
}
} catch (Exception e) {
//发生异常进行回滚
System.out.println("tx.rollback");
tx.rollback();
e.printStackTrace();
}
}
//分页查询客户
@Test
public void findPaged() {
try {
//创建query对象
String jpql = "from Customer";
Query query = em.createQuery(jpql);
//起始索引
query.setFirstResult(10);
//每页显示条数
query.setMaxResults(10);
//查询并得到返回结果
List list = query.getResultList(); //得到集合返回类型
for (Object object : list) {
System.out.println((Customer) object);
}
} catch (Exception e) {
// 回滚事务
tx.rollback();
e.printStackTrace();
}
}
//条件查询
// 通过数字占位符条件赋值
@Test
public void findConditionByIndex() {
try {
//创建query对象
String jpql = "from Customer where custName like ?1 ";
Query query = em.createQuery(jpql);
//对占位符赋值,从1开始
query.setParameter(1, "李家沟6225624%");
//查询并得到返回结果
Object object = query.getSingleResult(); //得到唯一的结果集对象
System.out.println((Customer) object);
} catch (Exception e) {
// 回滚事务
tx.rollback();
e.printStackTrace();
}
}
//条件查询
// 通过别名条件赋值
@Test
public void findConditionByAlias() {
try {
//创建query对象
String jpql = "from Customer where custName like :custName ";
Query query = em.createQuery(jpql);
//对占位符赋值,从1开始
query.setParameter("custName", "李家沟6225624%");
//查询并得到返回结果
Object object = query.getSingleResult(); //得到唯一的结果集对象
System.out.println((Customer) object);
} catch (Exception e) {
// 回滚事务
tx.rollback();
e.printStackTrace();
}
}
//根据客户id倒序查询所有客户
//查询所有客户
@Test
public void testOrder() {
try {
// 创建query对象
String jpql = "from Customer order by custId desc";
Query query = em.createQuery(jpql);
// 查询并得到返回结果
List list = query.getResultList(); // 得到集合返回类型
for (Object object : list) {
System.out.println((Customer) object);
}
} catch (Exception e) {
// 回滚事务
tx.rollback();
e.printStackTrace();
}
}
//统计查询
@Test
public void findCount() {
try {
// 查询全部客户
// 1.创建query对象
String jpql = "select count(custId) from Customer";
Query query = em.createQuery(jpql);
// 2.查询并得到返回结果
Object count = query.getSingleResult(); // 得到集合返回类型
System.out.println(count); //客户人数
} catch (Exception e) {
// 回滚事务
tx.rollback();
e.printStackTrace();
}
}
}
四.springDataJpa的基本使用
1.基本配置
- 引入依赖
<properties>
<spring.version>4.2.4.RELEASE</spring.version>
<hibernate.version>5.0.7.Final</hibernate.version>
<slf4j.version>1.6.6</slf4j.version>
<log4j.version>1.2.12</log4j.version>
<c3p0.version>0.9.1.2</c3p0.version>
<mysql.version>5.1.6</mysql.version>
</properties>
<dependencies>
<!-- junit单元测试 -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.9</version>
<scope>test</scope>
</dependency>
<!-- spring beg -->
<dependency>
<groupId>org.aspectj</groupId>
<artifactId>aspectjweaver</artifactId>
<version>1.6.8</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-aop</artifactId>
<version>${spring.version}</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>${spring.version}</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context-support</artifactId>
<version>${spring.version}</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-orm</artifactId>
<version>${spring.version}</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-beans</artifactId>
<version>${spring.version}</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-core</artifactId>
<version>${spring.version}</version>
</dependency>
<!-- spring end -->
<!-- hibernate beg -->
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-core</artifactId>
<version>${hibernate.version}</version>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-entitymanager</artifactId>
<version>${hibernate.version}</version>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-validator</artifactId>
<version>5.2.1.Final</version>
</dependency>
<!-- hibernate end -->
<!-- c3p0 beg -->
<dependency>
<groupId>c3p0</groupId>
<artifactId>c3p0</artifactId>
<version>${c3p0.version}</version>
</dependency>
<!-- c3p0 end -->
<!-- log end -->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>${log4j.version}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>${slf4j.version}</version>
</dependency>
<!-- log end -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-jpa</artifactId>
<version>1.9.0.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-test</artifactId>
<version>4.2.4.RELEASE</version>
</dependency>
<!-- el beg 使用spring data jpa 必须引入 -->
<dependency>
<groupId>javax.el</groupId>
<artifactId>javax.el-api</artifactId>
<version>2.2.4</version>
</dependency>
<dependency>
<groupId>org.glassfish.web</groupId>
<artifactId>javax.el</artifactId>
<version>2.2.4</version>
</dependency>
<!-- el end -->
</dependencies>
SpringBoot项目引入SpringBoot-web和SpringBooDataJpa等基本包后就不需要引入这么多依赖
- resources下创建spring配置文件
applicationContext.xml,使用spring来管理
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:aop="http://www.springframework.org/schema/aop"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:jdbc="http://www.springframework.org/schema/jdbc" xmlns:tx="http://www.springframework.org/schema/tx"
xmlns:jpa="http://www.springframework.org/schema/data/jpa" xmlns:task="http://www.springframework.org/schema/task"
xsi:schemaLocation="
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/jdbc http://www.springframework.org/schema/jdbc/spring-jdbc.xsd
http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx.xsd
http://www.springframework.org/schema/data/jpa
http://www.springframework.org/schema/data/jpa/spring-jpa.xsd">
<!-- 1.dataSource 配置数据库连接池-->
<bean id="dataSource" class="com.mchange.v2.c3p0.ComboPooledDataSource">
<property name="driverClass" value="com.mysql.jdbc.Driver" />
<property name="jdbcUrl" value="jdbc:mysql://localhost:3306/test?characterEncoding=utf-8" />
<property name="user" value="root" />
<property name="password" value="root" />
</bean>
<!-- 2.配置entityManagerFactory -->
<bean id="entityManagerFactory" class="org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean">
<property name="dataSource" ref="dataSource" />
<property name="packagesToScan" value="com.springData.entity" />
<property name="persistenceProvider">
<bean class="org.hibernate.jpa.HibernatePersistenceProvider" />
</property>
<!--JPA的供应商适配器-->
<property name="jpaVendorAdapter">
<bean class="org.springframework.orm.jpa.vendor.HibernateJpaVendorAdapter">
<property name="generateDdl" value="false" />
<property name="database" value="MYSQL" />
<property name="databasePlatform" value="org.hibernate.dialect.MySQLDialect" />
<property name="showSql" value="true" />
</bean>
</property>
<property name="jpaDialect">
<bean class="org.springframework.orm.jpa.vendor.HibernateJpaDialect" />
</property>
</bean>
<!-- 3.事务管理器-->
<!-- JPA事务管理器 -->
<bean id="transactionManager" class="org.springframework.orm.jpa.JpaTransactionManager">
<property name="entityManagerFactory" ref="entityManagerFactory" />
</bean>
<!-- 整合spring data jpa-->
<jpa:repositories base-package="com.springData.dao"
transaction-manager-ref="transactionManager"
entity-manager-factory-ref="entityManagerFactory"></jpa:repositories>
<!-- 4.txAdvice-->
<tx:advice id="txAdvice" transaction-manager="transactionManager">
<tx:attributes>
<tx:method name="save*" propagation="REQUIRED"/>
<tx:method name="insert*" propagation="REQUIRED"/>
<tx:method name="update*" propagation="REQUIRED"/>
<tx:method name="delete*" propagation="REQUIRED"/>
<tx:method name="get*" read-only="true"/>
<tx:method name="find*" read-only="true"/>
<tx:method name="*" propagation="REQUIRED"/>
</tx:attributes>
</tx:advice>
<!-- 5.aop-->
<aop:config>
<aop:pointcut id="pointcut" expression="execution(* com.springData.service.*.*(..))" />
<aop:advisor advice-ref="txAdvice" pointcut-ref="pointcut" />
</aop:config>
<!-- 6.扫描组件-->
<context:component-scan base-package="com.springData"></context:component-scan>
</beans>
- 创建和
数据表(cst_customer)和实体类(Customer)的映射
package com.springData.entity;
import lombok.Data;
import javax.persistence.*;
import java.io.Serializable;
/**
* @Entity 作用:指定当前类是实体类。
*
* @Table 作用:指定实体类和表之间的对应关系。
* 属性:name:指定数据库表的名称
*
* @Id 作用:指定当前字段是主键。
* @GeneratedValue 作用:指定主键的生成方式。。
* 属性:strategy :指定主键生成策略。
*
* @Column 作用:指定实体类属性和数据库表之间的对应关系
* 属性:
* name:指定数据库表的列名称。
* unique:是否唯一
* nullable:是否可以为空
* inserttable:是否可以插入
* updateable:是否可以更新
* columnDefinition: 定义建表时创建此列的DDL
* secondaryTable: 从表名。如果此列不建在主表上(默认建在主表),该属性定义该列所在从表的名字搭建开发环境[重点]
*/
@Data
@Entity //声明该类是和数据库表映射的实体类
@Table(name = "cst_customer") //建立实体类与表的映射关系
public class Customer implements Serializable {
private static final long serialVersionUID = -4422124275710090220L;
@Id //声明当前私有属性为主键
@GeneratedValue(strategy = GenerationType.IDENTITY) //配置主键的生成策略,为自增主键
@Column(name = "cust_id")
private Long custId;
@Column(name = "cust_name") //指定和表中cust_name字段的映射关系
private String custName;
@Column(name = "cust_source") //指定和表中cust_source字段的映射关系
private String custSource;
@Column(name = "cust_industry")
private String custIndustry;
@Column(name = "cust_level")
private String custLevel;
@Column(name = "cust_address")
private String custAddress;
@Column(name = "cust_phone")
private String custPhone;
}
- 创建dao层接口CustomerDao,并继承
JpaRepository和JpaSpecificationExecutor接口
package com.springData.dao;
import com.springData.entity.Customer;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.JpaSpecificationExecutor;
/**
* 定义一个dao层接口,此接口只需要继承JpaRepository 和 JpaSpecificationExecutor接口即可,该接口就具备了增删改 * 查和分页等功能。
* JpaRepository<实体类类型,主键类型>:完成基本的CRUD操作
* JpaSpecificationExecutor<实体类类型>:用于复杂查询(分页等查询操作)
*/
public interface CustomerDao extends JpaRepository<Customer,Long> , JpaSpecificationExecutor<Customer> {
}
2.CRUD操作
package com.test.springbootjpademo;
import com.springData.dao.CustomerDao;
import com.springData.entity.Customer;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.domain.Example;
import org.springframework.test.context.ContextConfiguration;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
import java.util.Optional;
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration(locations="classpath:applicationContext.xml")
public class TestSpringDataJpa {
@Autowired
private CustomerDao customerDao;
/**
* 保存操作:调用save()方法
*/
@Test
public void testSave() {
Customer customer = new Customer();
customer.setCustName("黑马");
//保存
customerDao.save(customer);
}
/**
* 修改客户信息:调用save()方法
* 对于save():如果执行此方法时对象中存在id属性,即为更新操作,会根据id查询,再更新
* 如果此方法中不存在id属性,则为保存操作
*/
@Test
public void testUpdate() {
Customer customerParam = new Customer();
customerParam.setCustId(1L);
Example<Customer> example = Example.of(customerParam);
//先根据id查询id为1的客户
Optional<Customer> optionalCustomer = customerDao.findOne(example);
System.out.println(optionalCustomer.get());
//修改客户名称
optionalCustomer.get().setCustName("授课123");
System.out.println(optionalCustomer.get());
//更新
customerDao.save(optionalCustomer.get());
}
/**
* 删除操作
*/
@Test
public void testDelete() {
Customer customerParam = new Customer();
customerParam.setCustId(8L);
customerDao.delete(customerParam);
}
/**
* 根据id查询:调用findOne()
*/
@Test
public void testFindById() {
Customer customerParam = new Customer();
customerParam.setCustId(1L);
Example<Customer> example = Example.of(customerParam);
//先根据id查询id为1的客户
Optional<Customer> optionalCustomer = customerDao.findOne(example);
System.out.println(optionalCustomer.get());
}
}
五.springBootDataJpa
spring-data-jpa官方文档地址
1.访问数据库的传统方式
1.传统的JDBC
//传统的JDBC :connection(连接) Statement(执行者) ResultSet(结果集)
//1. 获取链接
String url = "jdbc:mysql:localhost:3306/数据库的名称"
String user ="root";
String password = "";
String diverClass = "com.mysql.jadb.Driver";
Connection con = DiverManager.getConnection(url,user,password);
//2. 编写sql 获取语句执行者
PreparesStatement pre = conn.prepareStatement(sql);
//3. 语句执行,操作结果集ResultSet
//4. 释放资源
//Dao 先写接口再写实现
2. Spring 中使用 JdbcTemplate
//1. 添加相关的依赖 ; 2.配置数据源DataSource 3. 注入JdbcTemplate
//实际上就是将 连接的获取管理资源的释放等都交给spring 进行管理,在bean 配置文件中配置JdbcTemplate 并且,在使用的时候获取
//使用:
JdbcTemplaye jdbcTemplate = ctx.getBean("JdbcTemplate");
String sql = "select * from tableName"; sql 语句
//jdbcTemplate.各种执行方式: 在执行方式中写入参数和结果集的处理
2.SpringBootDataJpa基本配置
- Spring Boot则提供了一款全自动的
“自动依赖模块”:spring-boot-starter-data-jpa,只需要引入这个starter,application.properties/yml加上相应的配置即可使用
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<!-- 说明:
mysql-connector-java提供了mysql驱动等类库,此处必须引入此依赖,否则将会提示:
Cannot load driver class: com.mysql.jdbc.Driver等错误信息。-->
2 . 在springBoot的 application.properties添加配置信息
#mysql
# 默认端口
server.port=8443
# 数据库四要素
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
spring.datasource.url=jdbc:mysql://127.0.0.1:3306/TEST?characterEncoding=UTF-8
spring.datasource.username=root
spring.datasource.password=root
# 配置是否自动创建数据库表
spring.jpa.generate-ddl=false
#指定数据库类型
spring.jpa.database=mysql
#显示sql语句
spring.jpa.show-sql=true
#数据库方言:支持的特有语法
spring.jpa.database-platform=org.hibernate.dialect.MySQL55Dialect
# 在springboot项目中使用springdata Jpa,并且希望当我的实体类发生了更改,数据库表结构随着实体类的改变而自动做出相应的改变。
spring.jpa.hibernate.ddl-auto=update
# 开启懒加载,不开启在实体类中使用 FetchType.LAZY 会报错
spring.jpa.properties.hibernate.enable_lazy_load_no_trans=true
jpa.hibernate.ddl-auto是hibernate的配置属性,其主要作用是:自动创建、更新、验证数据库表结构。该参数的几种配置如下:
- create: 每次加载hibernate时都会删除上一次的生成的表,然后根据你的model类再重新来生成新表,哪怕两次没有任何改变也要这样执行,这就是导致数据库表数据丢失的一个重要原因。
- create-drop: 每次加载hibernate时根据model类生成表,但是sessionFactory一关闭,表就自动删除。
- update: 最常用的属性,第一次加载hibernate时根据model类会自动建立起表的结构(前提是先建立好数据库),以后加载hibernate时根据model类自动更新表结构,即使表结构改变了但表中的行仍然存在不会删除以前的行。要注意的是当部署到服务器后,表结构是不会被马上建立起来的,是要等应用第一次运行起来后才会。
- validate: 每次加载hibernate时,验证创建数据库表结构,只会和数据库中的表进行比较,不会创建新表,但是会插入新值。
- 建立实体 对象与数据表的关系
//注解:
@Id(主键)
@GeneratedValue(主键的生成策略): 一般使用strategy = GenerationType.IDENTITY 主键自增
@Entity: 表明这个类要对数据表做一个映射
@Table(表名): 对应数据表的名字
@Colum: 可以对字段作相应的要求,一般是
@OneToOne: 表示一对一关系
@OneToMany: 表示一对多关系
@ManyToOne: 表示多对一关系
@ManyToMant: 表示多对多关系
- 编写xxxRepository接口
//xxxRepository 的继承方式有两种
//1. 继承JpaRepository
xxxRepository extends JpaRepository<类名,表的主键在类中的类型>{
//重点在这个抽象类的编写
}
//2. 继承Repository
xxxRepository extends Repository<类名,表的主键在类中的类型>{
//重点在这个抽象类的编写
}
//重点都是编写这个接口中的抽象方法
这两种继承方式不一样的是:
extends Repository: Repository是一个空的接口,里面没有任何内容,是一个标识接口,表明的继承他的xxxRepository 会被Springboot 管理,才能实现写抽象方法可以使用。extends jpaRepository: jpaRepository是Repository 的一个子接口,里面定义了一些方法,在使用这些方法的时候回出现一些局限性。
这里的局限性主要针对JpaRepository 中已经定义好的一些方法,有一些返回值,或者是异常处理的局限性。比如:findById(Integer id) 的返回值类型:Optional;getOne(Integer id) 如果查找不到id 就会直接报错
- 在service中注入xxxxRepository,并使用
2.1.用户自定义Repository接口
1.创建接口
public interface UserRepository {
public Users findUserById(Integer userid);
}
2.创建接口实现类
/**
* 用户自定义Repository接口讲解
*/
public interface UsersDao extends JpaRepository<Users, Integer>,JpaSpecificationExecutor<Users>,UserRepository{
}
3.创建接口实现类
public class UsersDaoImpl implements UserRepository {
@PersistenceContext(name="entityManagerFactory")
private EntityManager em;
@Override
public Users findUserById(Integer userid) {
System.out.println("MyRepository......");
return this.em.find(Users.class, userid);
}
}
4.测试
/**
* JpaRepository接口测试
*/
@RunWith(SpringJUnit4ClassRunner.class)
@SpringBootTest
public class RepositoryTest {
@Autowired
private UsersDao usersDao;
/**
* 需求:根据用户ID查询数据
*/
@Test
public void test6(){
Users users = this.usersDao.findUserById(5);
System.out.println(users);
}
}
3.SpringBootDataJpa常用注解
3.1.java对象与数据库字段转化
| 注解 | 说明 |
|---|---|
| @Entity | 标识实体类是JPA实体,告诉JPA在程序运行时生成实体类对应表 |
| @Table | 设置实体类在数据库所对应的表名 |
| @Basic | 表示简单属性到数据库表字段的映射(几乎不用) |
| @Embedded | 指定类或它的值是一个可嵌入的类的实例的实体的属性。 |
| @Id | 标识类里所在变量为主键 |
| @GeneratedValue | 设置主键生成策略,此方式依赖于具体的数据库: 指定如何标识属性可以被初始化,例如自动、手动、或从序列表中获得的值。 |
| @Transient | 表示属性并非数据库表字段的映射,ORM框架将忽略该属性 |
| @Temporal | 当我们使用到java.util包中的时间日期类型,则需要@Temporal注释来说明转化成java.util包中的类型。其中包含三种转化类型分别是: java.sql.Date日期型,精确到年月日,例如“2008-08-08” java.sql.Time时间型,精确到时分秒,例如“20:00:00” java.sql.Timestamp时间戳,精确到纳秒,例如“2008-08-08 20:00:00.000000001” |
| @Column | 表示对这个变量所对应的字段名进行一些个性化的设置,例如字段的名字,字段的长度,是否为空和是否唯一等等设置。 |
| @Enumerated | 使用此注解映射枚举字段,以String类型存入数据库 注入数据库的类型有两种: EnumType.ORDINAL(Interger) EnumType.STRING(String) |
| @SequenceGenerator | 指定在@GeneratedValue注解中指定的属性的值。它创建了一个序列。 |
| @TableGenerator | 指定在@GeneratedValue批注指定属性的值发生器。它创造了的值生成的表。 |
| @AccessType | 这种类型的注释用于设置访问类型。如果设置@AccessType(FIELD),则可以直接访问变量并且不需要getter和setter,但必须为public。如果设置@AccessType(PROPERTY),通过getter和setter方法访问Entity的变量。 |
| @JoinColumn | 指定一个实体组织或实体的集合。这是用在多对一和一对多关联。 |
| @UniqueConstraint | 指定的字段和用于主要或辅助表的唯一约束。 |
| @ColumnResult | 参考使用select子句的SQL查询中的列名。 |
| @ManyToMany | 定义了连接表之间的多对多一对多的关系。 |
| @ManyToOne | 定义了连接表之间的多对一的关系。 |
| @OneToMany | 定义了连接表之间存在一个一对多的关系。 |
| @OneToOne | 定义了连接表之间有一个一对一的关系。 |
| @NamedQueries | 指定命名查询的列表。 |
| @NamedQuery | 指定使用静态名称的查询。 |
| @CreatedDate、@CreatedBy、@LastModifiedDate、@LastModifiedBy | 表示字段为 创建时间字段(insert自动设置) 创建用户字段(insert自动设置) 最后修改时间字段(update自定设置 最后修改用户字段(update自定设置) |
| @Embedded、@Embeddable | 当一个实体类要在多个不同的实体类中进行使用,而其不需要生成数据库表 @Embeddable:注解在类上,表示此类是可以被其他类嵌套 @Embedded:注解在属性上,表示嵌套被@Embeddable注解的同类型类 |
| @ElementCollection | 集合映射 |
| @MappedSuperclass | 实现将实体类的多个属性分别封装到不同的非实体类中 1.注解的类将不是完整的实体类,不会映射到数据库表,但其属性将映射到子类的数据库字段 2.注解的类不能再标注@Entity或@Table注解,也无需实现序列化接口 3.注解的类继承另一个实体类 或 标注@MappedSuperclass类,他可使用@AttributeOverride 或 @AttributeOverrides注解重定义其父类属性映射到数据库表中字段。 |
3.2.常用注解的使用
@Entity
- 用于标注实体类,表明该Java 类为实体类,将映射到指定的数据库表。如声明一个实体类 Customer,它将映射到数据库中的 customer 表上。
@Table
- 用于标注实体类,当实体类与对应的数据库表名
不一致时需要使用 @Table 标注说明,该标注与 @Entity 标注并列使用 - @Table 标注的常用选项是 name,用于指明数据库的表名 @Table标注还有一个两个选项
catalog 和 schema用于设置表所属的数据库目录或模式,通常为数据库名。
@Column
- 用于标注实体类字段上,当实体类字段名与数据库表字段名
不一致时需要用@Column 说明,还可与 @Id 标注一起使用。常用属性是name,用于设置映射数据库表的列名。其他属性如:unique 、nullable、length等。 - columnDefinition 属性: 表示该字段在数据库中的实际类型.
通常 ORM 框架可以根据属性类型自动判断数据库中字段的类型,但是对于Date类型仍无法确定数据库中字段类型究竟是DATE,TIME还是TIMESTAMP.此外,String的默认映射类型为VARCHAR,可以将 String 类型映射到特定数据库的 BLOB 或TEXT 字段类型. - @Column也可标注属性的getter方法
@Id
- 用于标注一个实体类的属性为数据库的主键列,属性也可标注对应的getter方法
//定义主键,生成主键的策略AUTO自动的根据数据的类型生成主键
@GeneratedValue(strategy=GenerationType.AUTO)
@Id //定义数据列
// @Column(name="ID")//定义数据库的列名如果与字段名一样可以省略
public Integer getId() {
return id;
}
@GeneratedValue
- 用于标注
主键的生成策略,通过strategy属性指定。默认情况下,JPA 自动选择一个最适合底层数据库的主键生成策略:- SqlServer 对应
identity, - MySQL 对应
auto increment。
- SqlServer 对应
在javax.persistence.GenerationType中定义了以下几种可供选择的策略:
IDENTITY:采用数据库 ID自增长的方式来自增主键字段,Oracle 不支持这种方式;AUTO: JPA自动选择合适的策略,是默认选项;SEQUENCE:通过序列产生主键,通过@SequenceGenerator注解指定序列名,MySql 不支持这种方式TABLE:通过表产生主键,框架借由表模拟序列产生主键,使用该策略可以使应用更易于数据库移植。
@Basic
- 表示一个简单的属性到数据库表的字段的映射,对于没有任何标注的
getXxxx()方法,默认 即为 @Basic
fetch: 表示该属性的读取策略,有EAGER和LAZY两种,分别表示主支抓取和延迟加载,默认为EAGER.FetchType.LAZY:懒加载,加载一个实体时,定义懒加载的属性不会马上从数据库中加载。FetchType.EAGER:急加载,加载一个实体时,定义急加载的属性会立即从数据库中加载。
@Temporal
在核心的 Java API 中并没有定义 Date 类型的精度(temporal precision). 而在数据库中,表示 Date 类型的数据有 DATE, TIME, 和 TIMESTAMP三种精度(即单纯的日期,时间,或者两者 兼备).
@Temporal(TemporalType.TIMESTAMP)// 时间戳
public Date getCreatedTime() {
return createdTime;
}
@Temporal(TemporalType.DATE) //时间精确到天
public Date getBirth() {
return birth;
}
3.3.java对象与json转化
| 注解 | 说明 |
|---|---|
| @JsonFormat | .@JsonFormat(pattern=“yyyy-MM-dd HH:mm:ss”,timezone=“GMT+8”):将Date属性转换为String类型, timezone解决(相差8小时) |
| @JsonSerialize | 作用在类或字段上,转化java对象到json格式(需自定义转化类继承JsonSerializer) |
| @JsonDeserialize | 作用在类或字段上,转化json格式到java对象(需自定义转化类继承JsonDeserializer) |
| @JsonProperty | 作用在属性上,把属性名称序列化为另一个名称(trueName属性序列化为name) |
| @JsonIgnoreProperties(ignoreUnknown = true) | 作用在类上,忽略掉json数据里包含了实体类没有的字段 |
| @JsonIgnore | 在json序列化时将java bean中的一些属性忽略掉,序列化和反序列化都受影响 |
4.SpringDataJpa数据持久化两种方式
使用 JPA 进行数据持久化有两种实现方式。
- 方式一:继承Spring Data JPA 提供的接口xxxRepository接口,使用该接口提供的默认增删改查实现
- 方式二:自定义符合Spring Data JPA规则的增删改查实现,由框架将其自动解析为SQL。
5.Spring Data JPA 的接口继承结构
Repository 接口 是 Spring Data JPA 中为我我们提供的所有接口中的顶层接口 Repository 提供了两种查询方式的支持
- 基于方法名称命名规则查询
- 基于@Query 注解查询
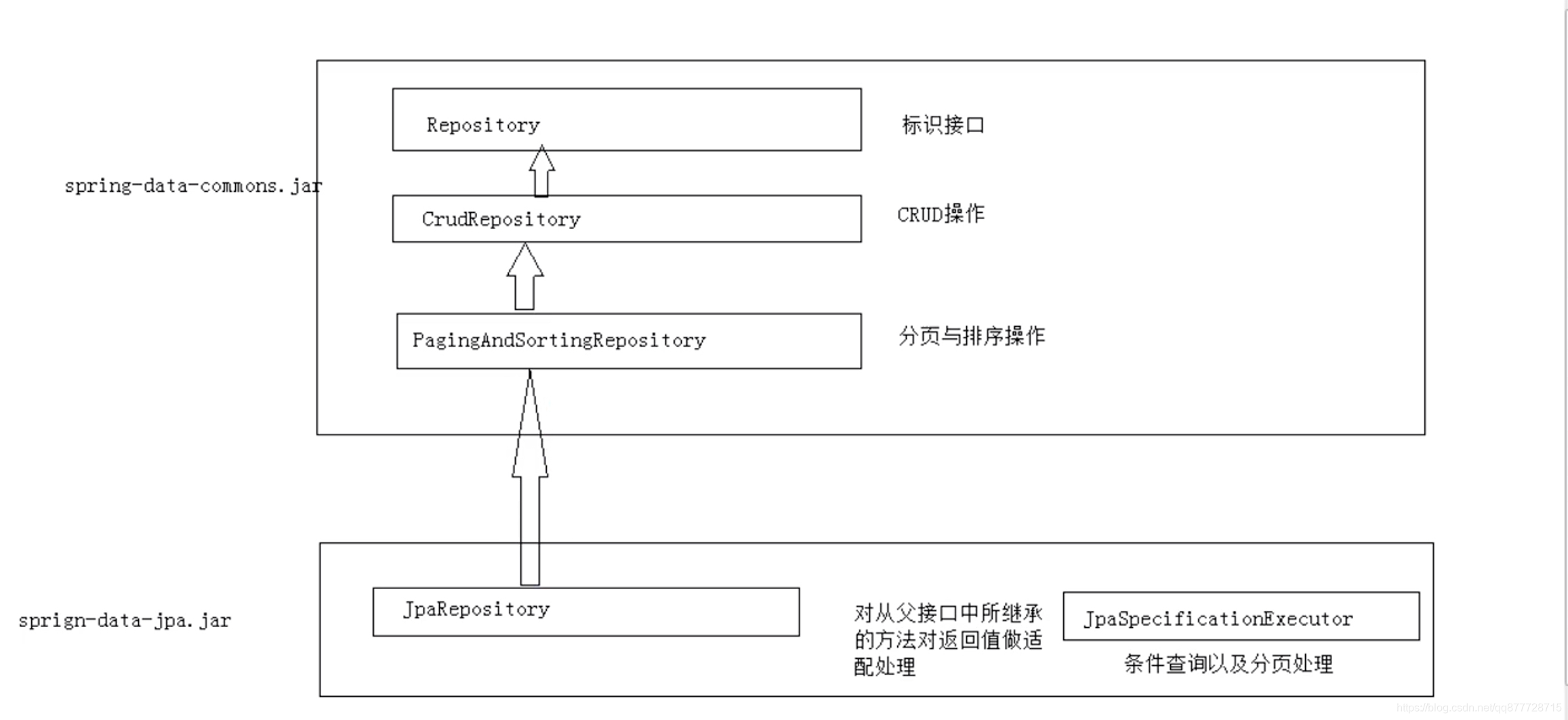
继承树:
Repository->CrudRepository->PagingAndSortingRepository->JpaRepository->xxxRepository
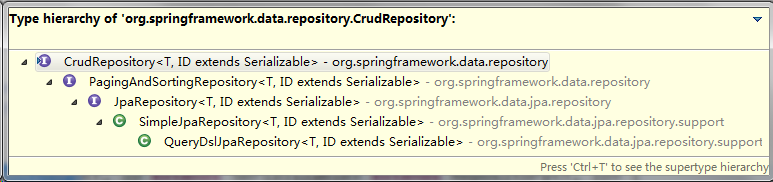
5.1.CrudRepository
CrudRepository : 定义了基本的crud 操作,接口如下
package org.springframework.data.repository;
import java.io.Serializable;
@NoRepositoryBean
public interface CrudRepository<T, ID extends Serializable> extends Repository<T, ID> {
<S extends T> S save(S entity); // 保存并返回(修改后的)实体
<S extends T> Iterable<S> save(Iterable<S> entities); //保存并返回(修改后的)实体集合(批量保存)
T findOne(ID id); // 根据ID获取实体
boolean exists(ID id); // 判断指定ID的实体是否存在
Iterable<T> findAll(); // 查询所有实体
Iterable<T> findAll(Iterable<ID> ids); // 根据ID集合查询实体
long count(); // 获取实体的数量
void delete(ID id); // 删除指定ID的实体
void delete(T entity); // 删除实体
void delete(Iterable<? extends T> entities); // 删除实体集合(批量删除)
void deleteAll(); // 删除所有实体
}
5.2.PagingAndSortingRepository
PagingAndSortingRepository继承于CrudRepository,除了具有CrudRepository接口的能力外,还新增了分页和排序的功能
- 带查找的排序 :findAll(Sort sort)
- 带排序的分页查询: findAll(Pageable pageable)
接口如下:
package org.springframework.data.repository;
import java.io.Serializable;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.Pageable;
import org.springframework.data.domain.Sort;
@NoRepositoryBean
public interface PagingAndSortingRepository<T, ID extends Serializable> extends CrudRepository<T, ID> {
Iterable<T> findAll(Sort sort); // 查询所有实体并排序(不带分页的排序)
Page<T> findAll(Pageable pageable); // 分页查询实体(带分页的排序)
}
//分页查询:
findAll(Pageable)
//构建Pageable
Pageable pageable = PageRequest.of(0,1);//springData2.0之前 用new PageRequest(0,1)
Page<User> page = userRepository.findAll(pageable);
//注释:
//PageRequest 是常用的Pageable 的子类
//springData2.0之前使用new构造方式创建分页对象
//构造函数:
public PageRequest(int page, int size) {} //:当前要获取那一页,每一页的数据数量
public PageRequest(int page, int size, Sort sort) {}//: 将当前页数据排序排序之后获取
//springData2.0之后使用PageRequest.of()方式创建分页对象
public static PageRequest of(int page, int size);
public static PageRequest of(int page, int size, Sort sort);
public static PageRequest of(int page, int size, Direction direction, String... properties);
//可以通过Page的方法获得很多信息:
page.getTotalElements(); //数据的总数
page.getTotalPages(); //页数
page.getNumber(); //当前的页数
page.getContent(); //当前页数的所有元素
page.getNumberOfElements(); //当前页的数据总数
//排序查询:
findAll(Sort sort)
//构建 Sort:
Sort.Order order = new Sort.Order(Sort.Direction.ASC,"id");
Sort sort = new Sort(order);
List<User> list = userRepository.findAll(sort);
//注释:Order的参数:Sort.Direction.ASC 升序;Sort.Direction.DESC 降序;排序的数据
5.3.JpaRepository
JpaRepository开发时使用的最多的接口,继承于PagingAndSortingRepository,所以它传递性地拥有了以上接口的所有方法,同时,它还继承了另外一个QueryByExampleExecutor接口。其特点是可以帮助我们将其他接口的方法的返回值做适配处理。可以使得我们在开发时更方便的使用这些方法。
package org.springframework.data.jpa.repository;
import java.io.Serializable;
import java.util.List;
import javax.persistence.EntityManager;
import org.springframework.data.domain.Example;
import org.springframework.data.domain.Sort;
import org.springframework.data.repository.NoRepositoryBean;
import org.springframework.data.repository.PagingAndSortingRepository;
import org.springframework.data.repository.query.QueryByExampleExecutor;
@NoRepositoryBean
public interface JpaRepository<T, ID extends Serializable>
extends PagingAndSortingRepository<T, ID>, QueryByExampleExecutor<T> {
List<T> findAll(); // 查询所有实体(不排序)
List<T> findAll(Sort sort); // 查询所有实体并排序
List<T> findAll(Iterable<ID> ids); // 根据ID集合查询实体
<S extends T> List<S> save(Iterable<S> entities); // 保存并返回(修改后的)实体集合(批量保存)
void flush(); // 提交事务(强制缓存与数据库同步)
<S extends T> S saveAndFlush(S entity); // 保存实体并立即提交事务
void deleteInBatch(Iterable<T> entities); // 批量删除实体集合(批量删除)
void deleteAllInBatch();// 批量删除所有实体(删除所有)
T getOne(ID id); // 根据ID查询实体
@Override
<S extends T> List<S> findAll(Example<S> example); // 查询与指定Example匹配的所有实体
@Override
<S extends T> List<S> findAll(Example<S> example, Sort sort);// 查询与指定Example匹配的所有实体并排序
}
以上的接口是一个自上而下的继承树,通常使用的是JpaRepository。
5.4.QueryByExampleExecutor
QueryByExampleExecutor接口允许开发者根据给定的样例执行查询操作,接口定义如下。
package org.springframework.data.repository.query;
import org.springframework.data.domain.Example;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.Pageable;
import org.springframework.data.domain.Sort;
public interface QueryByExampleExecutor<T> {
<S extends T> S findOne(Example<S> example); // 查询与指定Example匹配的唯一实体
<S extends T> Iterable<S> findAll(Example<S> example); // 查询与指定Example匹配的所有实体
<S extends T> Iterable<S> findAll(Example<S> example, Sort sort); // 查询与指定Example匹配的所有实体并排序
<S extends T> Page<S> findAll(Example<S> example, Pageable pageable);// 分页查询与指定Example匹配的所有实体
<S extends T> long count(Example<S> example); // 查询与指定Example匹配的实体数量
<S extends T> boolean exists(Example<S> example); // 判断与指定Example匹配的实体是否存在
}
5.5.JpaSpecificationExecutor
JpaSpecificationExecutor : 是一个单独的接口,不属于上面的继承关系,主要是为分页查询提供过滤条件。在实际的开发中使用的也比较多,
- 作用:用于完成多条件查询,并且支持分页与排序, 使用Specification 定义了
JPA critice查询条件,在这个接口中的方法中传入Specification为分页定义条件
源码如下:
public interface JpaSpecificationExecutor<T> {
/*根据查询条件返回一个实体*/
T findOne(Specification<T> spec);
/* 根据查询条件返回多个实体.*/
List<T> findAll(Specification<T> spec);
/*根据查询条件和分页参数,返回当前页的实体信息.*/
Page<T> findAll(Specification<T> spec, Pageable pageable);
/*根据查询条件和排序规则,返回一个排序好的实体集合. */
List<T> findAll(Specification<T> spec, Sort sort);
/**
*根据查询条件统计实体的数量 */
long count(Specification<T> spec);
}
Specification
- Specification封装
JPA Criteria查询条件。通常使用匿名内部类的方式来创建该接口的对象。 - Spring Data JPA提供的一个查询规范,要做复杂的查询,只需围绕这个规范来设置查询条件即可。
源码如下:
public interface Specification<T> {
Predicate toPredicate(Root<T> root, CriteriaQuery<?> query, CriteriaBuilder cb);
}
使用
//1. xxxRepository 继承JpaRepository,JpaSpecificationExecutor
public interface UserRepositorySpecification extends JpaRepository<User,Integer>,JpaSpecificationExecutor<User>{}
//2. 在Service层中构建Specification
public class ImSpecificationService implements SpecificationService {
@Autowired
UserRepositorySpecification userRepositorySpecification;
//测试Specification
@Override
public void TestSpecification() {
Pageable pageable = PageRequest.of(0,1);//springData2.0之前 用new PageRequest(0,1)
//构建Specification
Specification<User> specification = new Specification<User>() {
/**
*
* @param root: 将User 对象映射为 Root 可以通过它的对象获取对象中的各种字段
* @param criteriaQuery :查询条件的容器,存放查询条件;存放单个条件或者条件数组
* @param criteriaBuilder :构造查询条件,大于/小于/等于/like,比较对象
* @return predicate :定义查询条件;条件和比较的对象
*/
@Override
public Predicate toPredicate(Root<User> root, CriteriaQuery<?> criteriaQuery, CriteriaBuilder criteriaBuilder) {
Path path = root.get("id"); //查询过滤的对象,这里是id
//这个路径是 Root(User(id)),字段路径
//定义过滤条件
criteriaBuilder.gt(path,5);//条件是查询id >5 的数据进行分页
return criteriaBuilder.gt(path,5);
}
};
Page<User> page = userRepositorySpecification.findAll(specification,pageable);
}
}
5.5.1.单条件查询
创建接口
/**
* JpaSpecificationExecutor接口讲解
*注意:JpaSpecificationExecutor<Users>:不能单独使用,需要配合着jpa中的其他接口一起使用
*/
public interface UsersDao extends JpaRepository<Users, Integer>,JpaSpecificationExecutor<Users>{
}
测试接口
/**
* JpaRepository接口测试
* @author Administrator
*
*/
@RunWith(SpringJUnit4ClassRunner.class)
@SpringBootTest
public class RepositoryTest {
@Autowired
private UsersDao usersDao;
/**
* 需求:根据用户姓名查询数据
*/
@Test
public void test1(){
Specification<Users> spec = new Specification<Users>() {
/**
* @return Predicate:定义了查询条件
* @param Root<Users> root:根对象。封装了查询条件的对象
* @param CriteriaQuery<?> query:定义了一个基本的查询。一般不使用
* @param CriteriaBuilder cb:创建一个查询条件
*/
@Override
public Predicate toPredicate(Root<Users> root, CriteriaQuery<?> query, CriteriaBuilder cb) {
Predicate pre = cb.equal(root.get("username"), "王五");
return pre;
}
};
List<Users> list = this.usersDao.findAll(spec);
for (Users users : list) {
System.out.println(users);
}
}
}
5.5.2.多条件查询
5.5.2.1.给定查询条件方式一
/**
* 多条件查询 方式一
* 需求:使用用户姓名以及年龄查询数据
*/
@Test
public void test2(){
Specification<Users> spec = new Specification<Users>() {
@Override
public Predicate toPredicate(Root<Users> root, CriteriaQuery<?> query, CriteriaBuilder cb) {
List<Predicate> list = new ArrayList<>();
list.add(cb.equal(root.get("username"),"王五"));
list.add(cb.equal(root.get("userage"),24));
//此时条件之间是没有任何关系的。
Predicate[] arr = new Predicate[list.size()];
return cb.and(list.toArray(arr));
}
};
List<Users> list = this.usersDao.findAll(spec);
for (Users users : list) {
System.out.println(users);
}
}
5.5.2.2.给定查询条件方式二
/**
* 多条件查询 方式二
* 需求:使用用户姓名或者年龄查询数据
*/
@Test
public void test3(){
Specification<Users> spec = new Specification<Users>() {
@Override
public Predicate toPredicate(Root<Users> root, CriteriaQuery<?> query, CriteriaBuilder cb) {
return cb.or(cb.equal(root.get("username"),"王五"),cb.equal(root.get("userage"), 25));
}
};
List<Users> list = this.usersDao.findAll(spec);
for (Users users : list) {
System.out.println(users);
}
}
5.5.2.3.分页
/**
* 需求:查询王姓用户,并且做分页处理
*/
@Test
public void test4(){
//条件
Specification<Users> spec = new Specification<Users>() {
@Override
public Predicate toPredicate(Root<Users> root, CriteriaQuery<?> query, CriteriaBuilder cb) {
return cb.like(root.get("username").as(String.class), "王%");
}
};
//分页
Pageable pageable = PageRequest.of(2, 2);//springData2.0之前 用new PageRequest(0,1)
Page<Users> page = this.usersDao.findAll(spec, pageable);
System.out.println("总条数:"+page.getTotalElements());
System.out.println("总页数:"+page.getTotalPages());
List<Users> list = page.getContent();
for (Users users : list) {
System.out.println(users);
}
}
5.5.2.4.排序
/**
* 需求:查询数据库中王姓的用户,并且根据用户id做倒序排序
*/
@Test
public void test5(){
//条件
Specification<Users> spec = new Specification<Users>() {
@Override
public Predicate toPredicate(Root<Users> root, CriteriaQuery<?> query, CriteriaBuilder cb) {
return cb.like(root.get("username").as(String.class), "王%");
}
};
//排序
Sort sort = new Sort(Direction.DESC,"userid");
List<Users> list = this.usersDao.findAll(spec, sort);
for (Users users : list) {
System.out.println(users);
}
5.5.2.5.分页与排序
/**
* 需求:查询数据库中王姓的用户,做分页处理,并且根据用户id做倒序排序
*/
@Test
public void test6(){
//排序等定义
Sort sort = new Sort(Direction.DESC,"userid");
//分页的定义
Pageable pageable = PageRequest.of(2,2, sort);//springData2.0之前 用new PageRequest(0,1)
//查询条件
Specification<Users> spec = new Specification<Users>() {
@Override
public Predicate toPredicate(Root<Users> root, CriteriaQuery<?> query, CriteriaBuilder cb) {
return cb.like(root.get("username").as(String.class), "王%");
}
};
Page<Users> page = this.usersDao.findAll(spec, pageable);
System.out.println("总条数:"+page.getTotalElements());
System.out.println("总页数:"+page.getTotalPages());
List<Users> list = page.getContent();
for (Users users : list) {
System.out.println(users);
}
5.6.使用save方法添加/修改数据
添加数据: xxxRepository.save(对象)
- 数据的
添加和修改使用的都是save(), 判断的依据是主键,如果对象中没有赋值主键那么就是添加新的数据;如果对象中主键有值 那就是对这行数据的修改。
5.7.根据id查询
getOne(id)//根据主键查找数据,缺点:当数据库中没有相应的数据的时候会直接抛出异常,当你在 查找数据发现出现的错误莫名其妙 ,找不到错在有可能就是它
findById(id)// 返回值为:Optional<类> Puser = xxxRepository.findById(id);
//可以对返回值进行处理:
User user = null;
try{
user = Puser.get();
}catch(Exception ex){
//出现异常说明:Puser 中没有 user
}
//这样的获取就不会有异常抛出,user=Null 就表示没有查询得到数据
//使用场景:常用在用户登录;为了判断数据是否在数据库中,可能在也可能不在;如果是单纯的为了把数据拿
//出来用其实可以使用getOne(id)。前提是保证数据表中也一定有这个数据,在测试的时候要注意
//这两个方法都是JpaRepository 中写好的方法,换句话说如果你的repository 继承JpaRepository 使用时就要注意这样的问题
5.8.Repository方法的Null值处理
从Spring Data2.0开始对于返回单个实例的CRUD方法可以使用java8Optional接口作为方法返回值来可能存在的默认值,典型示例为CrudRepository的findById方法
另外Spring也提供了几个注解来处理Null值
@NonNullApi: 在包级别使用来声明参数和返回值不能为Null@NonNull:在参数或返回值上使用,当它们不能为Null时(如果在包级别上使用了@NonNullApi注解则没有必要再使用@NonNull注解了)@Nullable: 在参数或返回值上使用,当它们可以为Null时
5.9.自定义删除/修改
Delete/Updata 操作实现:@Modifying / @Trasational
// 1. 在Repository中定义的方法上添加@Modifying 和 @Trasational
public interface UserRepository extends JpaRepository<User,Integer> {
@Transactional
@Modifying
@Query("delete from User u where u.name =?1")
void deleteUser(String name);
@Transactional()
@Modifying
@Query("update User u set u.password = ?2 where u.username = ?1")
int updatePasswordByUsername(String username, String password);
@Transactional()
@Modifying
@Query("delete from User where username = ?1")
void deleteByUsername(String username);
}
// 2.Repository添加@Modifying,在Serice 层对应的方法上添加注解 @Transational
// Repostory层:
@Modifying
@Query("delete from User u where u.name =?1")
void deleteUser(String name);
// Service层
@Transactional
@Override
public void TestModify(String name) {
//测试Modify
userRepository.deleteUser(name);
}
-
在
@Query注解中编写JPQL语句实现DELETE和UPDATA操作必须加上@Modifying注解,以通知Spring DATA这是一个DELETE或者UPDATA操作。@Modifying声明这是一个DELETE或者UPDATA的操作;@Modifying的返回值为:void 或者 int(表示改变的数据行数)
-
UPDATA 和DELETE 操作需要使用事务,必须定义
service层,在service层的方法上添加@Transactional。在默认的情况下,JPA的事务会设置为只读@Transational(readOnly = true),就是不能对数据库进行任何修改, 如果Query语句在执行的时候出现问题,将会回滚到执行前的状态- @Transational 注释声明该方法的事务,默认的为只读
@Transational(readOnly = false)
- @Transational 注释声明该方法的事务,默认的为只读
事务一般在service 层中进行处理
5.10. 使用SPEL表达式
在原生SQL语句中使用(从Spring Data JPA版本1.4开始使用)
//#{#entityName} 值为'Book'对象对应的数据表名称(book)。
@Query(value = "select * from #{#entityName} b where b.name=?1", nativeQuery = true)
#{#entityName}获取到的是实体类的类名。,使用@Entity注解标注实体类Book,Spring会将实体类Book纳入管理。默认·#{#entityName}·的值就是Book·。- 如果使用了
@Entity(name = “book”)来标注实体类Book,此时#{#entityName}的值就变成了book - 只需要用
@Entity来标注实体类时指定name等于实体类对应的表名。在原生sql语句中,就可以把#{#entityName}来作为数据表名使用。
- 如果使用了
6.基于方法名称命名规则查询
除了可以直接使用Spring Data JPA接口已经实现的增删改查方法外,Spring Data JPA还允许开发者自定义查询方法,符合SpringDataJPA命名规则的方法,Spring Data JPA能够根据其方法名为其自动生成SQL,还支持的关键字有:find,query、get、read、count、delete、remove等。
- Spring Data Jpa 提供了一套可以通过方法命名规则进行查询的机制。通过解析方法名创建查询,框架在进行方法名解析时,会先把方法名多余的前缀
find…By, read…By, query…By, count…By以及get…By截取掉,然后对剩下部分进行解析,第一个By会被用作分隔符来指示实际查询条件的开始。 我们可以在实体属性上定义条件,并将它们与And和Or连接起来,从而创建不同的查询。
规范的方法名不仅能完成查找还能完成count 操作
在Repository 子接口中声明方法:
- 方法名需要符合一定规范,如: 查询方法以
find | read | get ...开头,删除方法以delete|remove开头- 涉及条件查询时,条件的属性用条件关键字连接
- 要注意的是:条件属性以首字母大写
命名规则
** findBy(关键字) + 属性名称(属性名称的首字母大写) + 查询条件(首字母大写)**
| 连接查询条件关键字 | 方法命名 | 对应的sql where字句 |
|---|---|---|
| And | findByNameAndPwd | where name= ?1 and pwd =?2 |
| Or | findByNameOrSex | where name= ?1 or sex=?2 |
| Is,Equals | findById,findByIdEquals | where id= ?1 |
| Between | findByIdBetween | where id between ?1 and ?2 |
| LessThan | findByIdLessThan | where id < ?1 |
| LessThanEquals | findByIdLessThanEquals | where id <= ?1 |
| GreaterThan | findByIdGreaterThan | where id > ?1 |
| GreaterThanEquals | findByIdGreaterThanEquals | where id > = ?1 |
| After | findByIdAfter | where id > ?1 |
| Before | findByIdBefore | where id < ?1 |
| IsNull | findByNameIsNull | where name is null |
| isNotNull,NotNull | findByNameNotNull | where name is not null |
| Like | findByNameLike | where name like ? |
| NotLike | findByNameNotLike | where name not like ?1 |
| StartingWith | findByNameStartingWith | where name like ‘?1%’ |
| EndingWith | findByNameEndingWith | where name like ‘%?1’ |
| Containing | findByNameContaining | where name like ‘%?1%’ |
| OrderBy | findByIdOrderByAgeDesc | where id=?1 order by age=?2 desc |
| Not | findByNameNot | where name <> ?1 |
| In | findByIdIn(Collection<?> c) | where id in (?1) |
| NotIn | findByIdNotIn(Collection<?> c) | where id not in (?1) |
| True | findByActiveTrue() | where active= true |
| False | findByActiveFalse() | where active= false |
| IgnoreCase | findByNameIgnoreCase | where UPPER(name)=UPPER(?1) |
另外,Spring Data JPA 还提供了对分页查询、自定义SQL、查询指定N条记录、联表查询等功能的支持,以员工实体资源库接口EmployeeRepository为例,功能代码示意如下。
@Repository
public interface EmployeeRepository extends JpaRepository<Employee, Long> {
//根据部门ID获取员工数量
int countByDepartmentId(Long departmentId);
//根据部门ID分页查询
Page<Employee> queryByDepartmentId(Long departmentId, Pageable pageable);
// 根据员工ID升序查询前10条
List<Employee> readTop10ByOrderById();
//根据员工姓名取第一条记录
Employee getFirstByName(String name, Sort sort);
//连表查询
@Query("select e.id as employeeId,e.name as employeeName,d.id as departmentId,d.name as departmentName from Employee e , Department d where e.id= ?1 and d.id= ?2")
EmployeeDetail getEmployeeJoinDepartment(Long eid, Long did);
//修改指定ID员工的姓名
@Modifying
@Transactional(timeout = 10)
@Query("update Employee e set e.name = ?1 where e.id = ?2")
int modifyEmployeeNameById(String name, Long id);
//删除指定ID的员工
@Transactional(timeout = 10)
@Modifying
@Query("delete from Employee where id = ?1")
void deleteById(Long id);
}
7.基于@Query 注解查询
@Query用于编写方法名命名规则查询无法完成的查询语句- 使用
@Query注解,只需在声明的方法上面标注该注解,同时提供一个 JPQL 查询语句就行了 - 如果设置
nativeQuery = true, 可以在@Query注解中编写原生的SQL语句
//一.索引参数:
@Query("SELECT p FROM Person p WHERE p.lastName = ?1 AND p.email = ?2")
List<Person> testQueryAnnotationParams1(String lastName, String email);
//?1,?2 是占位符,需要方法传递的参数顺序与其保持一致
//二.命名参数:
@Query("SELECT p FROM Person p WHERE p.lastName = :lastName AND p.email = :email")
List<Person> testQueryAnnotationParams2(@Param("email") String email, @Param("lastName") String lastName);
//三.含有like关键字的查询:
// 3.1.在占位符上添加%,在查询方法的参数中就不需要添加%
@Query("SELECT p FROM Person p WHERE p.lastName LIKE %?1% OR p.email LIKE %?2%")
List<Person> testQueryAnnotationLikeParam(String lastName, String email);
// 3.2.在命名参数上添加%,在查询方法的参数中就不需要添加%
@Query("SELECT p FROM Person p WHERE p.lastName LIKE %:lastName% OR p.email LIKE %:email%")
List<Person> testQueryAnnotationLikeParam3(@Param("email") String email, @Param("lastName") String lastName);
// 3.3.在传递的参数上添加%
@Query("SELECT p FROM Person p WHERE p.lastName LIKE ?1 OR p.email LIKE ?2")
List<Person> testQueryAnnotationLikeParam2(String lastName, String email);
// 传递的参数: “%A%” ,"%[email protected]%"
//四.使用原生的SQL 语句进行查询 设置 nativeQuery = true
@Query(value = "SELECT count(id) FROM jpa_persons", nativeQuery = true)
以上在@Query() 中写的类似sql 语句叫做 JPQL 是在JavaEE 中面向对象的查询语句,基于原生的SQL,JPQL 不支持INSERT,用save代替。但JPQL到SQL的转换无须开发者关心,JPQL解析器会负责完成这种转换,并负责执行这种转换的SQL语句来更新数据库。
使用原生的SQL语句.参数传递的方式还是可以使用占位符和命名参数
//使用原生的SQL 语句进行查询 设置 nativeQuery = true
@Query(value = "SELECT count(id) FROM jpa_persons", nativeQuery = true)
// 1.from 的后面接的 数据表名
// 2.参数传递的方式还是可以使用占位符和命名参数
8.分页及排序
在方法参数中直接传入Pageable或Sort可以完成动态分页或排序,通常Pageable或Sort会是方法的最后一个参数,如:
@Query("select u from User u where u.username like %?1%")
Page<User> findByUsernameLike(String username, Pageable pageable);
@Query("select u from User u where u.username like %?1%")
List<User> findByUsernameAndSort(String username, Sort sort);
那调用repository方法时传入什么参数呢?
对于Pageable参数,在Spring Data 2.0之前我们可以new一个org.springframework.data.domain.PageRequest对象,现在这些构造方法已经废弃 ,取而代之Spring推荐我们使用PageRequest的of方法
new PageRequest(0, 5);
new PageRequest(0, 5, Sort.Direction.ASC, "username");
new PageRequest(0, 5, new Sort(Sort.Direction.ASC, "username"));
PageRequest.of(0, 5);
PageRequest.of(0, 5, Sort.Direction.ASC, "username");
PageRequest.of(0, 5, Sort.by(Sort.Direction.ASC, "username"));
注意:Spring Data PageRequest的page参数是从
0开始的zero-based page index
对于Sort参数,同样可以new一个org.springframework.data.domain.Sort,但推荐使用Sort.by方法
9.@NamedQueries创建查询
- 命名查询是 JPA 提供的一种将查询语句从方法体中独立出来,以供多个方法共用的功能
- 用户只需要按照 JPA 规范在 orm.xml 文件或者在代码中使用
@NamedQuery(或 @NamedNativeQuery)定义好查询语句,唯一要做的就是为该语句命名时,需要满足”DomainClass.methodName()”的 命名规则
//1.编写持久层接口继承JpaRepository接口:
public interface FindUserByNamedQueryRepository extends JpaRepository<User, Integer> {
User findUserWithName(@Param("name") String name);
}
//2.编写实体类类:
@Entity
@NamedQueries(value={
@NamedQuery(name="User.findUserWithName",query="select u from User u where u.name = :name")
})
//省略以下是实体类......
注意:
-
@NamedQuery中的name属性的值要和接口中的方法名称一样。
-
如果只有一个方法,则可以使用
@NamedQuery,此处如果是多个方法,那么需要使用@NamedQueries
10.多表查询
10.1.一对一
需求:用户与角色的一对一的关联关系
人=>一端=>一个人只有一个身份证
身份证=>一端=>一个身份证只能属于一个人
10.1.1.通过外键的方式(一个实体通过外键关联到另一个实体的主键)
//---------------人类表---------------
CREATE TABLE `t_person` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`birthday` datetime DEFAULT NULL,
`name` varchar(20) DEFAULT NULL,
`sex` varchar(1) DEFAULT NULL,
`card_id` bigint(20) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `FKq7y12min0l1gij5ixjtyhxfks` (`card_id`),
CONSTRAINT `FKq7y12min0l1gij5ixjtyhxfks` FOREIGN KEY (`card_id`) REFERENCES `t_id_card` (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8
insert into `t_person` (`id`, `birthday`, `name`, `sex`, `card_id`) values('1','2020-04-13 11:57:03','张三','男','1');

//------------身份证表---------------
CREATE TABLE `t_id_card` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`census_register` varchar(50) DEFAULT NULL,
`id_number` varchar(19) DEFAULT NULL,
`nation` varchar(50) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8
insert into `t_id_card` (`id`, `census_register`, `id_number`, `nation`) values('1','湖南省郴州市xxx县','431022199502367215','汉');

用户类
@Entity(name = "t_person")
@Getter
@Setter
@EqualsAndHashCode(exclude = {"idCard"}) //不重写当前类的idCard字段equals()和HashCode()方法,否则会因为循环依赖保存
@ToString(exclude = {"idCard"})//不重写当前类的idCard字段ToString()方法,,否则会因为循环依赖保存
/**
* 人
*/
public class Person {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "id", nullable = false)
private Long id;//id
@Column(name = "name", nullable = true, length = 20)
private String name;//姓名
@Column(name = "sex", nullable = true, length = 1)
private String sex;//性别
@Column(name = "birthday", nullable = true)
private Timestamp birthday;//出生日期
@OneToOne(cascade = CascadeType.ALL)//Person是关系的维护端,当删除 Person,会级联删除 IDCard
@JoinColumn(name = "card_id", referencedColumnName = "id")//Person表中的card_id字段参考IDCard表中的id字段,会在t_person表多生成一个card_id字段
private IDCard idCard;//身份证
}
身份证类
@Entity(name = "t_id_card")
@Getter
@Setter
@EqualsAndHashCode(exclude = {"person"})
@ToString(exclude = {"person"})
/**
* 身份证
*/
public class IDCard {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "id", nullable = false)
private Long id;//id
@Column(name = "id_number", nullable = true, length = 19)
private String idNumber;//身份证好
@Column(name = "nation", nullable = true, length = 50)
private String nation;//民族
@Column(name = "census_register", nullable = true, length = 50)
private String censusRegister;//户籍地址
@OneToOne(mappedBy = "idCard", cascade = {CascadeType.MERGE, CascadeType.REFRESH}, optional = false) //mappedBy的意思就是“被映射”,即mappedBy这方不用管关联关系,关联关系交给另一方处理
private Person person;
}
持久层接口
/**
* 用户持久层接口
*/
public interface UsersRepository extends JpaRepository<Users, Integer>,JpaSpecificationExecutor<Users>{
}
/**
* 身份证持久层接口
*/
public interface IDCardRepository extends JpaRepository<IDCard, Integer>, JpaSpecificationExecutor<IDCard> {
}
测试
/**
* 一对一关联关系测试
*/
@RunWith(SpringJUnit4ClassRunner.class)
@SpringBootTest
public class OneToOneTest {
@Autowired
private PersonRepository personRepository;
@Autowired
private IDCardRepository idCardRepository;
/**
* 添加用户同时添加角色
*/
@Test
public void testAdd() {
//创建角色
Person person = new Person();
person.setBirthday(new Timestamp(System.currentTimeMillis()));
person.setName("张三");
person.setSex("男");
IDCard idCard = new IDCard();
idCard.setIdNumber("431022199502367215");
idCard.setCensusRegister("湖南省郴州市xxx县");
idCard.setNation("汉");
person.setIdCard(idCard);
//保存数据
this.personRepository.save(person);
}
/**
* 根据用户ID查询用户,以及身份证信息
*/
@Test
public void testGetPeople() {
Person personParam = new Person();
personParam.setId(1L);
Example<Person> example = Example.of(personParam);
Optional<Person> peopleOptional = this.personRepository.findOne(example);
System.out.println("用户信息:" + peopleOptional.get());
IDCard idCard = peopleOptional.get().getIdCard();
System.out.println("身份证信息:" + idCard);
//用户信息:Person(id=1, name=张三, sex=男, birthday=2020-04-13 11:57:03.0)
//身份证信息:IDCard(id=1, idNumber=431022199502367215, nation=汉, censusRegister=湖南省郴州市xxx县)
}
/**
* 根据身份证id查询身份证信息,以及该身份证对对应的用户
*/
@Test
public void testGetAddress() {
IDCard addressParam = new IDCard();
addressParam.setId(1L);
Example<IDCard> example = Example.of(addressParam);
Optional<IDCard> idCardOptional = this.idCardRepository.findOne(example);
System.out.println("身份证信息:" + idCardOptional.get());
Person person = idCardOptional.get().getPerson();
System.out.println("用户信息:" + person);
//身份证信息:IDCard(id=1, idNumber=431022199502367215, nation=汉, censusRegister=湖南省郴州市xxx县)
//用户信息:Person(id=1, name=张三, sex=男, birthday=2020-04-13 11:57:03.0)
}
}
10.2.一对多(多对一)
需求:部门与员工的一对一的关联关系
部门:一端
员工:多端
-
JPA使用
@OneToMany和@ManyToOne来标识一对多的双向关联。一端(Department )使用 @OneToMany ,多端(Employee )使用 @ManyToOne。 -
在JPA规范中,一对多的双向关系由
多端(Employee )来维护。就是说多端(Employee )为关系维护端,负责关系的增删改查。一端(Department )则为关系被维护端,不能维护关系。 -
一端(Department)使用 @OneToMany 注释的mappedBy="xxxxx"属性表明Department 是关系被维护端。 -
多端(Employee )使用 @ManyToOne 和 @JoinColumn 来注释属性dept_id,@ManyToOne表明Employee是多端,@JoinColumn 设置在Employee表中的关联字段(外键)。
部门类
@Entity
@Table(name = "tb_dept")
@Setter
@Getter
@EqualsAndHashCode(exclude = {"employees"})//不使用employees字段参与hashCode/equals的重写
@ToString(exclude = {"employees"})//不使用employees字段参与toString的重写
/**
* 部门
*/
public class Department {
@Id
@GenericGenerator(name = "idGenerator", strategy = "uuid")//自定义主键生成策略自动插入uuid
@GeneratedValue(generator = "idGenerator")
private String id;
@Column(name = "dept_name", unique = true, nullable = false, length = 64)
private String deptName;
//@OneToMany(mappedBy = "department", cascade = CascadeType.ALL, fetch = FetchType.LAZY)
@OneToMany(targetEntity = Employee.class, cascade = CascadeType.ALL,fetch = FetchType.EAGER) //先保存targetEntity,设置外键后,再保存sourceEntity。
@JoinColumn(name="dept_id",referencedColumnName = "id")
private Set<Employee> employees;
}
关于级联,一定要注意: cascade = CascadeType.ALL 只能写在 One 端,只有One端改变Many端,不准Many端改变One端。
.
比如 文章和评论,文章是One,评论是Many,如果删除一条评论,就把文章删了,那算谁的。所以,在使用的时候要小心。cascade = CascadeType.ALL一定要在 One 端使用。
员工类
@Entity
@Table(name = "tb_emp")
@Setter
@Getter
@EqualsAndHashCode(exclude = {"department"})//不使用department字段参与hashCode/equals的重写
@ToString(exclude = {"department"})//不使用department字段参与toString的重写
/**
* 员工
*/
public class Employee {
@Id
@GenericGenerator(name = "idGenerator", strategy = "uuid")//自定义主键生成策略自动插入uuid
@GeneratedValue(generator = "idGenerator")
private String id;
@Column(name = "emp_name", nullable = false, length = 64)
private String empName;
@Column(name = "emp_job", length = 64)
private String empJob;
@ManyToOne(targetEntity = Department.class, fetch = FetchType.LAZY)
//targetEntity:先保存targetEntity,设置外键后,再保存sourceEntity。
//FetchType.LAZY: 开启懒加载 需要在配置文件配置 spring.jpa.properties.hibernate.enable_lazy_load_no_trans=true
@JoinColumn(name="dept_id")//会自动根据配置在数据表生成dept_id字段
private Department department;
}
持久层接口
public interface DepartmentRepository extends JpaRepository<Department, String>, JpaSpecificationExecutor<Department> {
}
public interface EmployeeRepository extends JpaRepository<Employee, String>, JpaSpecificationExecutor<Employee> {
}
测试
/**
* 一对多/多对一关联关系测试
*
* @author Administrator
*/
@RunWith(SpringJUnit4ClassRunner.class)
@SpringBootTest
public class OneToManyTest {
@Autowired
private EmployeeRepository employeeRepository;
@Autowired
private DepartmentRepository departmentRepository;
/**
* 添加部门
*/
@Test
public void testDepartmentAdd() {
Department department = new Department();
department.setDeptName("市场部");
departmentRepository.save(department);
}
/**
* 添加员工并设置外键
*/
@Test
public void testEmployeeAdd() {
Employee employee = new Employee();
employee.setEmpName("王九");
employee.setEmpJob("拓展市场");
Department department = new Department();
department.setId("402880e57191dd87017191dd960f0000");
employee.setDepartment(department);
employeeRepository.save(employee);
}
/**
* 查询市场部的所有员工
*/
@Test
public void testFindDepartmentById() {
Optional<Department> departmentOptional = departmentRepository.findById("402880e57191dd87017191dd960f0000");
System.out.println("部门:" + departmentOptional.get());
System.out.println("部门员工:" + departmentOptional.get().getEmployees());
}
/**
* 查询员工所属部门
*/
@Test
public void testFindEmployeeById() {
Optional<Employee> employeeOptional = employeeRepository.findById("402880e57191df20017191df2c8d0000");
System.out.println("员工:" + employeeOptional.get());
System.out.println("所属部门:" + employeeOptional.get().getDepartment());//懒加载
}
}
10.3.多对多
这里以用户-角色表关系为例,一个用户可以有多个角色,一个角色也可以属于多个用户,所以他们的关系是多对多关系
用户类
@Entity
@Table(name = "tb_user")
@Setter
@Getter
@EqualsAndHashCode(exclude = {"roleList"})//不使用roleList字段参与hashCode/equals的重写
@ToString(exclude = {"roleList"})//不使用roleList字段参与toString的重写
public class User {
@Id
@GenericGenerator(name = "idGenerator", strategy = "uuid")//自动生成UUID
@GeneratedValue(generator = "idGenerator")
private String id;
@Column(name = "username", unique = true, nullable = false, length = 64)
private String username;
@Column(name = "password", nullable = false, length = 64)
private String password;
@Column(name = "email", unique = true, length = 64)
private String email;
// FetchType.LAZY 懒加载方式获取数据
@ManyToMany
@JoinTable(name = "tb_user_role", joinColumns = {@JoinColumn(name = "user_id")},
inverseJoinColumns = {@JoinColumn(name = "role_id")})
//mappedBy:绝对不能再存于JoinTable和JoinColumn注解时使用
//joinColumns:当前类主键 inverseJoinColumns:关联对象主键
private List<Role> roleList;
//1、关系维护端,负责多对多关系的绑定和解除
//2、@JoinTable注解的name属性指定关联表的名字,joinColumns指定外键的名字,关联到关系维护端(User),inverseJoinColumns指定外键的名字,要关联的关系被维护端(Role)
//3、其实可以不使用@JoinTable注解,默认生成的关联表名称为主表表名+下划线+从表表名,
//4.主表就是关系维护端对应的表,从表就是关系被维护端对应的表
}
角色类
@Entity
@Table(name = "tb_role")
@Setter
@Getter
@EqualsAndHashCode(exclude = {"userList"})//不使用userList字段参与hashCode/equals的重写
@ToString(exclude = {"userList"})//不使用userList字段参与toString的重写
public class Role {
@Id
@GenericGenerator(name = "idGenerator", strategy = "uuid")
@GeneratedValue(generator = "idGenerator")
private String id;
@Column(name = "role_name", unique = true, nullable = false, length = 64)
private String roleName;
// FetchType.LAZY 懒加载方式获取数据
@ManyToMany(cascade = CascadeType.ALL)
@JoinTable(name = "tb_user_role", joinColumns = {@JoinColumn(name = "role_id", referencedColumnName = "id")},
inverseJoinColumns = {@JoinColumn(name = "user_id")})
//mappedBy:绝对不能再存于JoinTable和JoinColumn注解时使用
//joinColumns:当前类主键 inverseJoinColumns:关联对象主键
private List<User> userList;
//1、关系维护端,负责多对多关系的绑定和解除
//2、@JoinTable注解的name属性指定关联表的名字,joinColumns指定外键的名字,关联到关系维护端(User),inverseJoinColumns指定外键的名字,要关联的关系被维护端(Role)
//3、其实可以不使用@JoinTable注解,默认生成的关联表名称为主表表名+下划线+从表表名,
//4.主表就是关系维护端对应的表,从表就是关系被维护端对应的表
}
持久层接口
public interface UserRepository extends JpaRepository<User, String>, JpaSpecificationExecutor<User> {
}
public interface RoleRepository extends JpaRepository<Role, String>, JpaSpecificationExecutor<Role> {
}
测试
/**
* 多对多关联关系测试
*
* @author Administrator
*/
@RunWith(SpringJUnit4ClassRunner.class)
@SpringBootTest
public class ManyToManyTest {
@Autowired
private UserRepository userRepository;
@Autowired
private RoleRepository roleRepository;
/**
* 添加角色并生成外键
*/
@Test
public void testRoleAdd() {
Role role = new Role();
role.setRoleName("普通用户");
roleRepository.save(role);
}
/**
* 新增用户张三并绑定所有角色
*/
@Test
public void testUserRoleAdd() {
User user = new User();
user.setUsername("zhangshan");
user.setPassword("123456");
user.setEmail("[email protected]");
List<Role> roleList = roleRepository.findAll();
user.setRoleList(roleList);
userRepository.save(user);
}
/**
* 新新增用户李四并绑定 超级管理员/企业管理员角色
*/
@Test
public void testUserRoleAdd2() {
List<Role> roleList = new ArrayList<>();
Role role1 = new Role();
role1.setId("402880e571922ae80171922afe7e0000");//超级管理员
Role role2 = new Role();
role2.setId("402880e571922ce20171922ceec60000");//企业管理员
roleList.add(role1);
roleList.add(role2);
User user = new User();
user.setUsername("lisi");
user.setPassword("123456222");
user.setEmail("[email protected]");
user.setRoleList(roleList);
userRepository.save(user);
}
/**
* 修改增用户李四并绑定 超级管理员/企业管理员角色
*/
@Test
public void testUserUpdate() {
List<Role> roleList = new ArrayList<>();
Role role1 = new Role();
role1.setId("402880e571922ae80171922afe7e0000");//超级管理员
Role role2 = new Role();
role2.setId("402880e571922ce20171922ceec60000");//企业管理员
roleList.add(role1);
roleList.add(role2);
User user = new User();
user.setId("402880e571929b260171929b33840000");
user.setUsername("lisi-123123123123");
user.setPassword("123456222");
user.setEmail("[email protected]");
user.setRoleList(roleList);
userRepository.save(user);
}
//-----------------------------------------------
/**
* 新增角色运营管理员 并绑定到所有用户
*/
@Test
public void testRoleUserAdd() {
Role role = new Role();
role.setRoleName("运营管理员");
List<User> userList = userRepository.findAll();
role.setUserList(userList);
roleRepository.save(role);
}
/**
* 新增用户 小花/小明 并绑定 普通用户角色
*/
@Test
public void testRoleUserAdd2() {
List<User> userList = new ArrayList<>();
User user1 = new User();
user1.setUsername("xiaohua");
user1.setPassword("123456222");
user1.setEmail("[email protected]");
userList.add(user1);
User user2 = new User();
user2.setUsername("xiaoming");
user2.setPassword("123456222");
user2.setEmail("[email protected]");
userList.add(user2);
Role role = new Role();
role.setId("402880e571922d480171922d53db0000");//普通用户
role.setRoleName("普通用户");
role.setUserList(userList);
roleRepository.save(role);
}
/**
* 查询指定用户及其所属角色
*/
@Test
public void testFindUserById() {
Optional<User> userOptional = userRepository.findById("402880e5719296d301719296e0f90000");
System.out.println("用户:" + userOptional.get());
System.out.println("所属用户角色:" + userOptional.get().getRoleList());
}
/**
* 查询指定角色及其所属用户
*/
@Test
public void testFindRoleById() {
Optional<Role> roleOptional = roleRepository.findById("402880e571922d480171922d53db0000");
System.out.println("角色:" + roleOptional.get());
System.out.println("所属角色用户:" + roleOptional.get().getUserList());
}
}
不出意外会报Hibernate懒加载异常,无法初始化代理类,No Session:
org.hibernate.LazyInitializationException: failed to lazily initialize a collection of role: com.example.springbootjpa.entity.User.roles, could not initialize proxy - no Session
原因: Spring Boot整合JPA后Hibernate的Session就交付给Spring去管理。每次数据库操作后,会关闭Session,当我们想要用懒加载方式去获得数据的时候,原来的Session已经关闭,不能获取数据,所以会抛出这样的异常。
解决方法:
在application.peoperties中做如下配置:
spring.jpa.open-in-view=true
spring.jpa.properties.hibernate.enable_lazy_load_no_trans=true
使用lombok框架时可能会操作循环依赖问题:慎用
@Data注解,使用@Getter、@Setter注解,需要时自己重写toString()、equals()以及hashCode()方法
使用Hibernate、JPA、Lombok遇到的有趣问题cmazxiaoma
11.审计字段
参考自官方文档5.9Auditing
- 一般数据库表在设计时都会添加4个审计字段,Spring Data Jpa同样支持审计功能,提供了
@CreatedBy,@LastModifiedBy,@CreatedDate,@LastModifiedDate4个注解来记录表中记录的创建及修改信息。
1.在SpringBoot启动类上添加@EnableJpaAuditing
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.data.jpa.repository.config.EnableJpaAuditing;
@SpringBootApplication
@EnableJpaAuditing
public class SpringBootJpaApplication {
public static void main(String[] args) {
SpringApplication.run(SpringBootJpaApplication.class, args);
}
}
2.在实体类上使用以上注解
package com.example.springbootjpa.entity;
import lombok.Data;
import org.hibernate.annotations.GenericGenerator;
import org.springframework.data.annotation.CreatedBy;
import org.springframework.data.annotation.CreatedDate;
import org.springframework.data.annotation.LastModifiedBy;
import org.springframework.data.annotation.LastModifiedDate;
import org.springframework.data.jpa.domain.support.AuditingEntityListener;
import javax.persistence.*;
import java.util.Date;
import java.util.Set;
@Entity
@EntityListeners(AuditingEntityListener.class)
@Table(name = "tb_user")
@Data
public class User {
@Id
@GenericGenerator(name = "idGenerator", strategy = "uuid")
@GeneratedValue(generator = "idGenerator")
private String id;
@Column(name = "username", unique = true, nullable = false, length = 64)
private String username;
@Column(name = "password", nullable = false, length = 64)
private String password;
@Column(name = "email", unique = true, length = 64)
private String email;
@ManyToMany(targetEntity = Role.class, cascade = CascadeType.ALL, fetch = FetchType.LAZY)
@JoinTable(name = "tb_user_role", joinColumns = {@JoinColumn(name = "user_id", referencedColumnName = "id")},
inverseJoinColumns = {@JoinColumn(name = "role_id", referencedColumnName = "id")})
private Set<Role> roles;
@CreatedDate
@Column(name = "created_date", updatable = false)
private Date createdDate;
@CreatedBy
@Column(name = "created_by", updatable = false, length = 64)
private String createdBy;
@LastModifiedDate
@Column(name = "updated_date")
private Date updatedDate;
@LastModifiedBy
@Column(name = "updated_by", length = 64)
private String updatedBy;
}
实体类上还添加了
@EntityListeners(AuditingEntityListener.class),而AuditingEntityListener是由Spring Data Jpa提供的
3.实现 AuditorAware 接口,泛型T是返回的限定类型,并注册到Spring管理的容器中
- 光添加了4个审计注解还不够,得告诉程序到底是谁在创建和修改表记录
package com.example.springbootjpa.auditing;
import org.springframework.data.domain.AuditorAware;
import org.springframework.stereotype.Component;
import java.util.Optional;
//测试处理审计字段方式
@Component
public class AuditorAwareImpl implements AuditorAware<String> {
@Override
public Optional<String> getCurrentAuditor() {
return Optional.of("admin");
}
}
//真实处理审计字段方式
/*class SpringSecurityAuditorAware implements AuditorAware<User> {
public Optional<User> getCurrentAuditor() {
return Optional.ofNullable(SecurityContextHolder.getContext())
.map(SecurityContext::getAuthentication)
.filter(Authentication::isAuthenticated)
.map(Authentication::getPrincipal)
.map(User.class::cast);
}
}*/
这里简单的返回了一个"admin"字符串来代表当前用户名
12. 使用@MappedSuperclass抽出实体的公共字段
import java.io.Serializable;
import javax.persistence.Column;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.persistence.MappedSuperclass;
@MappedSuperclass
@Data
public class BaseEntity implements Serializable{
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@column(name="created_by")
private String createdBy;
@column(name="created_at")
private Integer createdAt;
@column(name="updated_by")
private String updatedBy;
@column(name="updated_at")
private Integer updatedAt;
@column(name="is_deleted")
private Integer isDeleted;
}
子类
import javax.persistence.Entity;
import javax.persistence.Table;
@Entity
@Table(name = "yyh_user")
public class User extends BaseEntity{
}
使用方式:
-
@MappedSuperclass注解使用在一个实体类父类上,来标识这个父类。
-
@MappedSuperclass标识的类表示其不能映射到数据库表,因为其不是一个完整的实体类,但它所拥有的属性能够映射到其子类所在的表中。
-
@MappedSuperclass标识的类不能再有@Entity和@Table注解。
写完之后才感觉有点写多了,这篇文章我单纯是为了学习SpringDataJPA而写下的笔记,大多了地方都使用了伪代码方式实现,有点繁杂了,如果有什么不懂的可以在下方进行留言,我会继续为大家补充