linux中grep命令的用法
grep说明
作为linux中最为常用的三大文本(awk,sed,grep)处理工具之一,掌握好其用法是很有必要的。
首先谈一下grep命令的常用格式为:grep [选项] ”模式“ [文件]
grep家族总共有三个:grep,egrep,fgrep。
常用选项
语法:grep [选项]
--v:(等同于–version):查看版本
-E:开启扩展(Extend)的正则表达式。
-i:忽略大小写(ignore case)。
-v:反过来(invert),只打印没有匹配的,而匹配的反而不打印。
-q:安静。不向标准输出写任何东西。如果找到任何匹配的内容就立即以状态值 0
-n :显示行号
-w:被匹配的文本只能是单词,而不能是单词中的某一部分,如文本中有liker,而我搜寻的只是like,就可以使用-w选项来避免匹配liker

-c:显示总共有多少行被匹配到了,而不是显示被匹配到的内容,注意如果同时使用-cv选项是显示有多少行没有被匹配到。
-o :只显示被模式匹配到的字符串。
--color :将匹配到的内容以颜色高亮显示。
-A n:显示匹配到的字符串所在的行及其后n行,after
-B n:显示匹配到的字符串所在的行及其前n行,before
-C n:显示匹配到的字符串所在的行及其前后各n行,context
[root@control ~]$grep --v #查看版本
grep (GNU grep) 2.20
Copyright (C) 2014 Free Software Foundation, Inc.
[root@control ~]$grep --version #查看版本
grep (GNU grep) 2.20
Copyright (C) 2014 Free Software Foundation, Inc.
[root@control ~]$
[root@control ~]$grep ccx /etc/passwd #普通查找
ccx:x:1000:1000:ccx:/home/ccx:/bin/bash
ccx1:x:1001:1001::/home/ccx1:/bin/bash
ccx2:x:1002:1002::/home/ccx2:/bin/bash
ccx3:x:1003:1003::/home/ccx3:/bin/bash
[root@control ~]$
[root@control ~]$grep -i CCx /etc/passwd #忽略大小写
ccx:x:1000:1000:ccx:/home/ccx:/bin/bash
ccx1:x:1001:1001::/home/ccx1:/bin/bash
ccx2:x:1002:1002::/home/ccx2:/bin/bash
ccx3:x:1003:1003::/home/ccx3:/bin/bash
[root@control ~]$
[root@control ~]$cat a #测试文本
root
ccx
hero
[root@control ~]$grep -v root a #过滤root
ccx
hero
[root@control ~]$
[root@control ~]$grep -q ccx /etc/passwd #不会打印内容,即使ccx存在
[root@control ~]$echo $? #返回0就是说明上上面-q有内容,一般用于脚本中返回判断条件用
0
[root@control ~]$grep -q ccxcxxc /etc/passwd # 这个ccxcxxc明显不存在
[root@control ~]$echo $? #所以返回1
1
[root@control ~]$
[root@control ~]$grep -n ccx /etc/passwd #显示行号
42:ccx:x:1000:1000:ccx:/home/ccx:/bin/bash
46:ccx1:x:1001:1001::/home/ccx1:/bin/bash
47:ccx2:x:1002:1002::/home/ccx2:/bin/bash
48:ccx3:x:1003:1003::/home/ccx3:/bin/bash
[root@control ~]$grep -nw ccx /etc/passwd #-w精确查找
42:ccx:x:1000:1000:ccx:/home/ccx:/bin/bash
[root@control ~]$
[root@control ~]$grep -c ccx /etc/passwd #仅显示匹配到的行数
4
[root@control ~]$grep -on ccx /etc/passwd# 仅显示匹配到的内容,也就是该文中所有ccx,结合n更直观
42:ccx
42:ccx
42:ccx
46:ccx
46:ccx
47:ccx
47:ccx
48:ccx
48:ccx
[root@control ~]$
[root@control ~]$cat a#测试文档
root
ccx
hero
go fot it
just
do
it
[root@control ~]$grep -nA 2 ccx a #打印关键字后两行,有时候在脚本中筛选比awk还好用,记住ABC的使用方法
2:ccx
3-hero
4-go fot it
[root@control ~]$grep -nB 2 go a #打印关键字前2行
2-ccx
3-hero
4:go fot it
[root@control ~]$grep -nC 2 go a #打印关键字前后2行
2-ccx
3-hero
4:go fot it
5-just
6-do
[root@control ~]$
模式部分
1、直接输入要匹配的字符串,这个可以用fgrep(fast grep)代替来提高查找速度,比如我要匹配一下hello.c文件中printf的个数:fgrep -c "printf" hello.c
2、使用基本正则表达式,下面谈关于基本正则表达式的使用:
匹配字符:
. :任意一个字符。
[abc]:表示匹配一个字符,这个字符必须是abc中的一个。
[a-zA-Z] :表示匹配一个字符,这个字符必须是a-z或A-Z这52个字母中的一个。
[^123]:匹配一个字符,这个字符是除了1、2、3以外的所有字符。
对于一些常用的字符集,系统做了定义:
[A-Za-z]等价于 [[:alpha:]]
[0-9]等价于 [[:digit:]]
[A-Za-z0-9] 等价于 [[:alnum:]]
tab,space 等空白字符 [[:space:]]
[A-Z]等价于 [[:upper:]]
[a-z]等价于 [[:lower:]]
,.:等标点符号[[:punct:]]
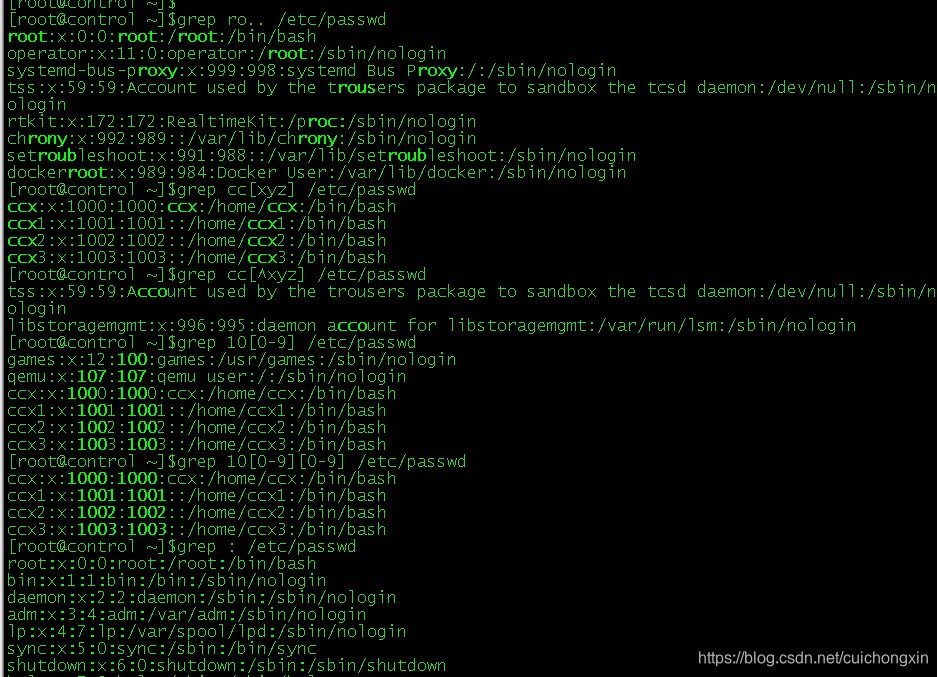
[root@control ~]$grep ro.. /etc/passwd #ro.. 表示ro后面要有2个任意字母
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
systemd-bus-proxy:x:999:998:systemd Bus Proxy:/:/sbin/nologin
tss:x:59:59:Account used by the trousers package to sandbox the tcsd daemon:/dev/null:/sbin/nologin
rtkit:x:172:172:RealtimeKit:/proc:/sbin/nologin
chrony:x:992:989::/var/lib/chrony:/sbin/nologin
setroubleshoot:x:991:988::/var/lib/setroubleshoot:/sbin/nologin
dockerroot:x:989:984:Docker User:/var/lib/docker:/sbin/nologin
[root@control ~]$grep cc[xyz] /etc/passwd #ccx后面必须是xyz中的一个
ccx:x:1000:1000:ccx:/home/ccx:/bin/bash
ccx1:x:1001:1001::/home/ccx1:/bin/bash
ccx2:x:1002:1002::/home/ccx2:/bin/bash
ccx3:x:1003:1003::/home/ccx3:/bin/bash
[root@control ~]$grep cc[^xyz] /etc/passwd #ccx后面除了xyz的任意字母
tss:x:59:59:Account used by the trousers package to sandbox the tcsd daemon:/dev/null:/sbin/nologin
libstoragemgmt:x:996:995:daemon account for libstoragemgmt:/var/run/lsm:/sbin/nologin
[root@control ~]$grep 10[0-9] /etc/passwd #10后面跟一个0-9的数字
games:x:12:100:games:/usr/games:/sbin/nologin
qemu:x:107:107:qemu user:/:/sbin/nologin
ccx:x:1000:1000:ccx:/home/ccx:/bin/bash
ccx1:x:1001:1001::/home/ccx1:/bin/bash
ccx2:x:1002:1002::/home/ccx2:/bin/bash
ccx3:x:1003:1003::/home/ccx3:/bin/bash
[root@control ~]$grep 10[0-9][0-9] /etc/passwd #10后面跟2个0-9的数字
ccx:x:1000:1000:ccx:/home/ccx:/bin/bash
ccx1:x:1001:1001::/home/ccx1:/bin/bash
ccx2:x:1002:1002::/home/ccx2:/bin/bash
ccx3:x:1003:1003::/home/ccx3:/bin/bash
[root@control ~]$grep : /etc/passwd # 符号这直接替换为 想要筛选的符号即可
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
匹配次数(筛选)
一个正则表达式后面可以跟随多种重复操作符之一,主要是用来匹配任意字符出现的次数!
{}的符号在shell有特殊意义,因此要用到转义字符\。
? 先前的项是可选的,最多匹配一次,等价于{0,1}。
* 先前的项可以匹配零次或多次,等价于{0,},所以 "." 表述任意字符任意次,即无论什么内容全部匹配。
+ 先前的项可以匹配一次或多次。
"x\{n\}y" x是代表需要出现次数的任意字符,y是后面需要跟的任意字符(可选项,也可以用),先前x的项将匹配恰好 n 次。
"x\{n,\}y" x是代表需要出现次数的任意字符,y是后面需要跟的任意字符(可选项,也可以用*),先前的项可以匹配 n 或更多次。
"x\{n,m\}y" x是代表需要出现次数的任意字符,y是后面需要跟的任意字符(可选项,也可以用*),先前的项将匹配至少 n 次,但是不会超过 m 次。
注:上面的x和y均可以套入正则,如[A-Z],y是可选项,但也可以套入正则,如[A-Z],但如果x不满足条件,y是没有意义的。
[root@control ~]$grep -n "\/*sh" /etc/passwd #\转义/,等同于grep "/.*sh" /etc/passwd
1:root:x:0:0:root:/root:/bin/bash
7:shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
33:setroubleshoot:x:991:988::/var/lib/setroubleshoot:/sbin/nologin
37:sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin
42:ccx:x:1000:1000:ccx:/home/ccx:/bin/bash
43:apache:x:48:48:Apache:/usr/share/httpd:/sbin/nologin
44:tomcat:x:53:53:Apache Tomcat:/usr/share/tomcat:/sbin/nologin
46:ccx1:x:1001:1001::/home/ccx1:/bin/bash
47:ccx2:x:1002:1002::/home/ccx2:/bin/bash
48:ccx3:x:1003:1003::/home/ccx3:/bin/bash
[root@control ~]
[root@control ~]$cat a
root
ccx
hero
go fot it
just
do
it
2020 years
05 mon
[root@control ~]$grep "[0-9]\{2\}" a # 我怀疑我系统有问题,按理说不应该出现2020的,注意这个问题!
2020 years
05 mon
[root@control ~]$grep -o "[0-9]\{2,3\}" a #如果要精确 就需要 -o 参数,但这样就不是整行内容了。
202
05
[root@control ~]$grep "[0-9]\{3,4\}" a #0-9出现3或4次,这个对了
2020 years
[root@control ~]$grep "c\{2\}" a #字符c出现2次,这也没问题。
ccx
[root@control ~]$
位置锚定
^x:锚定行首,x代表任意字符。
x$:锚定行尾,x代表任意字符。技巧:^$用于匹配空白行,所以grep -v ^$ 就是过滤空白行
"\bx或\<":锚定单词的词首,x代表任意字符。如"\blike"不会匹配alike,但是会匹配liker
"x\b或\>":锚定单词的词尾,x代表任意字符。如"like\b"不会匹配alike,但是会匹配liker
"\bx\b":筛选固定单词,x代表任意字符(必须是一个完整的单词,不能是一个单词的一部分)。如"\blike\b"不会匹配alike和liker,只会匹配like
"\B":与\b作用相反。
[root@control ~]$cat a
root
ccx
hero
go fot it
just
do
it
2020 years
05 mon
[root@control ~]$grep ^c a#c开头
ccx
[root@control ~]$grep x$ a #x结尾
ccx
[root@control ~]$grep -v "^$" a #过滤空白行
root
ccx
hero
go fot it
just
do
it
2020 years
05 mon
[root@control ~]$grep "\bc" a #c开头
ccx
[root@control ~]$grep "s\b" a #b结尾
2020 years
[root@control ~]$grep "\bcx\b" a #只有ccx没有cx这个单词,不能为单词的一部分,如下面的ccx可以正常筛选
[root@control ~]$grep "\bccx\b" a # 固定筛选ccx
ccx
[root@control ~]$
分组及引用
\(string\) :将string作为一个整体方便后面引用
\1 :引用第1个左括号及其对应的右括号所匹配的内容。
\2:引用第2个左括号及其对应的右括号所匹配的内容。
\n :引用第n个左括号及其对应的右括号所匹配的内容。
[root@control ~]$grep "^\([[:alpha:]]\).*\1$" /etc/passwd #开头和结尾相同字母的行
nobody:x:99:99:Nobody:/:/sbin/nologin
nfsnobody:x:65534:65534:Anonymous NFS User:/var/lib/nfs:/sbin/nologin
ntp:x:38:38::/etc/ntp:/sbin/nologin
[root@control ~]$
过滤IP代码分解
说明
筛选IP 首先你得知道 你的IP是配置在哪个网卡的,如果有多个bond,你要知道自己想筛选哪个bond的IP。
查看方式有很多,这里说3种吧!
- 第一种
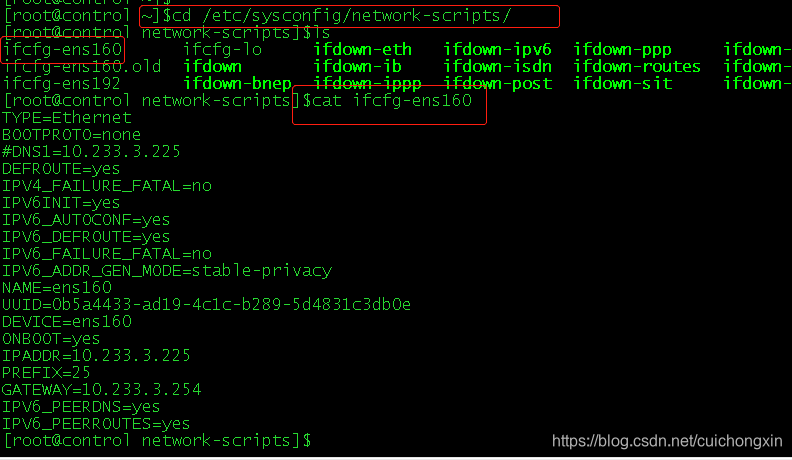
这种方法适用于你知道网卡(ip配在哪个网卡中)。
去网络配置文件中查看网卡,网络配置文件 /etc/sysconfig/network-scripts/ifcfg-ens33(网卡名称)
egrep 筛选ip代码块(下面会说代码的) /etc/sysconfig/network-scripts/ifcfg-ens160(网卡名称)
- 第二种
和第一种方式一样,你得知道你ip配在哪个网卡中,只是这不用去配置文件里查看,稍微简单些。
ip a show 网卡名称 | egrep 筛选ip代码块(下面会说代码的)

- 第三种
这种就是你不必去查ip配在哪个网卡上的,只需要知道,ip段即可! ifconfig 和 ip a 相同。
ifconfig | egrep 筛选ip代码块(下面会说代码的)| grep ip段(比如0.0)

代码
代码分解
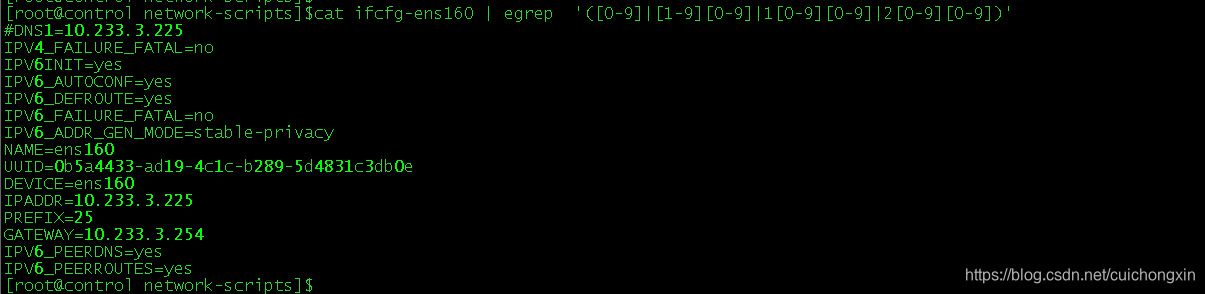
先来康康,检索出 0-299(其实到255就可以了,但我想提高到299,反正也没坏处)的范围代码:egrep '([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-9][0-9])' (这里()可以不需要加,但为了养成好习惯,加上吧)
实现原理:|在这起分割作用,具体的我就不做解释了。 [0-9]提取个位数,[1-9][0-9]提取10-99,1[0-9][0-9]提取100-199的数,2[0-9][0-9]提取200-299的数
全部代码
- 完整代码
egrep '\<([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-9][0-9])\.([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-9][0-9])\.([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-9][0-9])\.([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-9][0-9])\>'
- 原理:
\<和 \>是精确查找,等同于"\bx\b",不明白的看上面位置锚定的说明。
\.就是转义后.的意思。
(检索出 0-299代码)\.(检索出 0-299代码)\.(检索出 0-299代码)\.(检索出 0-299代码)因为IP是由3个.隔开的4串数字,这是固定的。
[root@control network-scripts]$cat ifcfg-ens160 | egrep '\<([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-9][0-9])\.([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-9][0-9])\.([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-9][0-9])\.([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-9][0-9])\>'
#DNS1=10.233.3.225
IPADDR=10.233.3.225
GATEWAY=10.233.3.254

- 简化代码
其实也就是相同的代码用{3}替代而已,建议了解就好,没必要为了少些点代码,把自己搅晕了。
这里放完整版代码和简化代码你对比一下吧!
完整版:
egrep '\<([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-9][0-9])\.([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-9][0-9])\.([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-9][0-9])\.([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-9][0-9])\>'
简化版:
egrep '\<(([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-9][0-9])\.){3}([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-9][0-9])\>'
[root@control network-scripts]$ifconfig | egrep '\<(([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-9][0-9])\.){3}([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-9][0-9])\>'
inet 172.17.0.1 netmask 255.255.0.0 broadcast 0.0.0.0
inet 10.233.3.225 netmask 255.255.255.128 broadcast 10.233.3.255
inet 127.0.0.1 netmask 255.0.0.0
inet 192.168.122.1 netmask 255.255.255.0 broadcast 192.168.122.255
[root@control network-scripts]$
提取ip
既然说到 ip筛选了,顺便说说,提取ip,这里用上面的方法三做说明,除了egrep以外还需要用到 awk。
[root@control network-scripts]$ifconfig | egrep '\<([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-9][0-9])\.([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-9][0-9])\.([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-9][0-9])\.([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-9][0-9])\>'|grep 10.233|awk '{print $2}'
10.233.3.225
[root@control network-scripts]$
