原文链接 https://www.cnblogs.com/52mm/articles/a27.html
MPI常用函数
- MPI_Init(&argc, &argv)
来初始化MPI环境,可能是一些全局变量的初始化。MPI程序的第一个调用,它完成MPI程序所有的初始化工作,所有MPI程序的第一条可执行语句都是这条语句。
- MPI_Comm_rank(communicator, &myid)
来获取当前进程在通信器中具有的进程号。不同的进程就可以将自身和其它的进程区别开来,实现各进程的并行和协作。
- MPI_Comm_size(communicator, &numprocs)
来获取通信器中包含的进程数目。不同的进程通过这一调用得知在给定的通信域中一共有多少个进程在并行执行。
- MPI_Finalize()
来结束并行编程环境。之后我们就可以创建新的MPI编程环境了。MPI程序的最后一个调用,它结束MPI程序的运行,它是MPI程序的最后一条可执行语句,否则程序的运行结果是不可预知的。
- int MPI_Send(void* buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm)
将发送缓冲区中的count个datatype数据类型的数据发送到目的进程,目的进程在通信域中的标识号是dest,本次发送的消息标志是tag,使用这一标志,就可以把本次发送的消息和本进程向同一目的进程发送的其它消息区别开来。发送缓冲区是由count个类型为datatype的连续数据空间组成,起始地址为buf。注意这里不是以字节计数,而是以数据类型为单位指定消息的长度。
- int MPI_Recv(void* buf, int count, MPI_Datatype datatype, int source, int tag,
MPI_Comm comm, MPI_Status *status)
从指定的进程source接收消息,并且该消息的数据类型和消息标识和本接收进程指定的datatype和tag相一致,接收到的消息所包含的数据元素的个数最多不能超过count。
接收缓冲区是由count个类型为datatype的连续元素空间组成,由datatype指定其类型,起始地址为buf。如果一个短于接收缓冲区的消息到达,那么只有相应于这个消息的那些地址被修改。count可以是零,这种情况下消息的数据部分是空的。
通过对status.MPI_SOURCE,status.MPI_TAG和status.MPI_ERROR的引用,就可以得到返回状态中所包含的发送数据进程的标识,发送数据使用的tag标识和本接收操作返回的错误代码。
虚拟进程
虚拟进程(MPI_PROC_NULL)是不存在的假想进程,在MPI中的主要作用是充当真实进程通信的目或源,引入虚拟进程的目的是为了在某些情况下编写通信语句的方便。当一个真实进程向一个虚拟进程发送数据或从一个虚拟进程接收数据时,该真实进程会立即正确返回,如同执行了一个空操作。
在很多情况下为通信指定一个虚拟的源或目标是非常方便的,这不仅可以大大简化处理边界的代码,而且使程序显得简洁易懂。在捆绑发送接收操作中经常用到这种通信手段。一个真实进程向虚拟进程MPI_PROC_NULL发送消息时会立即成功返回;一个真实进程从虚拟进程MPI_PROC_NULL的接收消息时也会立即成功返回,并且对接收缓冲区没有任何改变。
进程间的通信需要通过一个通信器来完成。MPI 环境在初始化时会自动创建两个通信器,一个称为 MPI_COMM_WORLD,它包含程序中的所有进程,另一个称为 MPI_COMM_SELF,它是每个进程独自构成的、仅包含自己的通信器。MPI 系统提供了一个特殊进程号 MPI_PROC_NULL,它代表空进程 (不存在的进程),与 MPI_PROC_NULL 进行通信相当于一个空操 作,对程序的运行没有任何影响。
MPI_SENDRECV(sendbuf,sendcount,sendtype,dest,sendtag,recvbuf,recvcount,
recvtype, source,recvtag,comm,status)发送缓冲区起始地址(可选数据类型)
发送数据的个数(整型)
发送数据的数据类型(句柄)
目标进程标识(整型)
发送消息标识(整型)
接收缓冲区初始地址(可选数据类型)
最大接收数据个数(整型)
接收数据的数据类型(句柄)
源进程标识(整型)
接收消息标识(整型)
通信域(句柄)
返回的状态(status)

MPI的消息传递过程可以分为三个阶段:
(1)消息装配,将发送数据从发送缓冲区中取出,加上消息信封等形成一个完整的消息。
(2)消息传递,将装配好的消息从发送端传递到接收端。
(3)消息拆卸,从接收到的消息中取出数据送入接收缓冲区。
在这三个阶段,都需要类型匹配:(1)在消息装配时,发送缓冲区中变量的类型必须和相应的发送操作指定的类型相匹配;(2)在消息传递时,发送操作指定的类型必须和相应的接收操作指定的类型相互匹配;(3)在消息拆卸时,接收缓冲区中变量的类型必须和接收操作指定的类型相匹配。
归纳起来,类型匹配规则可以概括为:
有类型数据的通信,发送方和接收方均使用相同的数据类型。
无类型数据的通信,发送方和接收方均以MPI_BYTE作为数据类型。
打包数据的通信, 发送方和接收方均使用MPI_PACKED。
- double MPI_Wtime(void)
返回一个用浮点数表示的秒数, 它表示从过去某一时刻到调用时刻所经历的时间。
如何计时
double starttime, endtime;
...
starttime = MPI_Wtime()
需计时部分
endtime = MPI_Wtime()
printf(“That tooks %f secodes\n”, endtime-starttime);
- int MPI_Get_processor_name ( char name, int resultlen)
在实际使用MPI编写并行程序的过程中,经常要将一些中间结果或最终的结果输出到程序自己创建的文件中,对于在不同机器上的进程,常希望输出的文件名包含该机器名,或者是需要根据不同的机器执行不同的操作,这样仅仅靠进程标识rank是不够的,MPI为此提供了一个专门的调用,使各个进程在运行时可以动态得到该进程所运行机器的名字。MPI_GET_PROCESSOR_NAME调用返回调用进程所在机器的名字。
例子
#include "mpi.h"
#include <stdio.h>
int main(argc, argv)
int argc;
char **argv;
{
int rank, size, i, buf[1];
MPI_Status status;
MPI_Init( &argc, &argv );/*初始化*/
MPI_Comm_rank( MPI_COMM_WORLD, &rank );/*进程号*/
MPI_Comm_size( MPI_COMM_WORLD, &size );/*总的进程个数*/
if (rank == 0) {
for (i=0; i<100*(size-1); i++) {
MPI_Recv( buf, 1, MPI_INT, MPI_ANY_SOURCE,
MPI_ANY_TAG, MPI_COMM_WORLD, &status );/*使用任意源和任意标识接收*/
printf( "Msg=%d from %d with tag %d\n",
buf[0], status.MPI_SOURCE, status.MPI_TAG );
}
}
else {
for (i=0; i<100; i++) {
buf[0]=rank+i;
MPI_Send( buf, 1, MPI_INT, 0, i, MPI_COMM_WORLD );/*发送*/
}
}
MPI_Finalize();/*结束*/
}
讲解:
在接收操作中,通过使用任意源和任意tag标识,使得该接收操作可以接收任何进程以任何标识发送给本进程的数据,但是该消息的数据类型必须和接收操作的数据类型相一致。
这里给出了一个使用任意源和任意标识的例子。其中ROOT进程(进程0)接收来自其它所有进程的消息,然后将各消息的内容,消息来源和消息标识打印出来。规约函数
int MPI_Reduce(
void *input_data, /*指向发送消息的内存块的指针 */
void *output_data, /*指向接收(输出)消息的内存块的指针 */
int count,/*数据量*/
MPI_Datatype datatype,/*数据类型*/
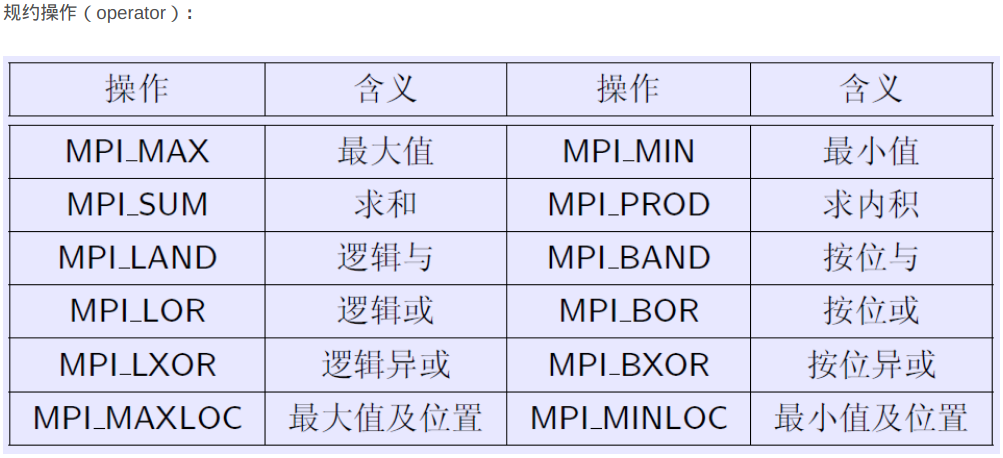
MPI_Op operator,/*规约操作*/
int dest,/*要接收(输出)消息的进程的进程号*/
MPI_Comm comm);/*通信器,指定通信范围*/
)
例子(梯形积分)
#include "stdafx.h"
#include <iostream>
#include<math.h>
#include "mpi.h"
using namespace std;
const double a = 0.0;
const double b = 3.1415926;
int n = 100;
double h = (b - a) / n;
double trap(double a, double b, int n, double h)
{
double*x = new double[n + 1];
double*f = new double[n + 1];
double inte = (sin(a) + sin(b)) / 2;
for (int i = 1; i<n + 1; i++) {
x[i] = x[i - 1] + h;
f[i] = sin(x[i]);
inte += f[i];
}
inte = inte*h;
return 0;
}
int main(int argc, char * argv[])
{
int myid, nprocs;
int local_n;
double local_a;
double local_b;
double total_inte;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &myid); /* get current process id */
MPI_Comm_size(MPI_COMM_WORLD, &nprocs); /* get number of processes */
local_n = n / nprocs;
local_a = a + myid*local_n*h;
local_b = local_a + local_n*h;
double local_inte = trap(local_a, local_b, local_n, h);
/*
@local_inte:send buffer;
@total_inte:receive buffer;
@MPI_SUM:MPI_Op;
@dest=0,rank of the process obtaining the result.
*/
MPI_Reduce(&local_inte, &total_inte, 1, MPI_DOUBLE, MPI_SUM, 0, MPI_COMM_WORLD);
if (myid == 0)
{
printf("integral output is %d", total_inte);
}
MPI_Finalize();
return 0;
}

