目录
一、单机有什么问题?
单机即在一台机器上部署一个redis节点,主要会存在以下问题:
1. 机器故障
如果发生机器故障,例如磁盘损坏,主板损坏等,未能在短时间内修复好,客户端将无法连接redis。
当然如果仅仅是redis节点挂掉了,可以进行问题排查然后重启,姑且不考虑这段时间对外服务的可用性,那还是可以接受的。
而发生机器故障,基本是无济于事。除非把redis迁移到另一台机器上,并且还要考虑数据同步的问题。
2. 容量瓶颈
假如一台机器是16G内存,redis使用了12G内存,而其他应用还需要使用内存,假设我们总共需要60G内存要如何去做呢,是否有必要购买64G内存的机器?
3. QPS瓶颈
redis官方数据显示可以达到10w的QPS,如果业务需要100w的QPS怎么去做呢?
关于容量瓶颈和QPS瓶颈是redis分布式需要解决的问题,而机器故障就是高可用的问题了
二、主从复制的作用
一主一从
如图所示左边是Master节点,右边是slave节点,即主节点和从节点。从节点也是可以对外提供服务的,主节点是有数据的,从节点可以通过复制操作将主节点的数据同步过来,并且随着主节点数据不断写入,从节点数据也会做同步的更新。
整体起到的就是数据备份的效果。
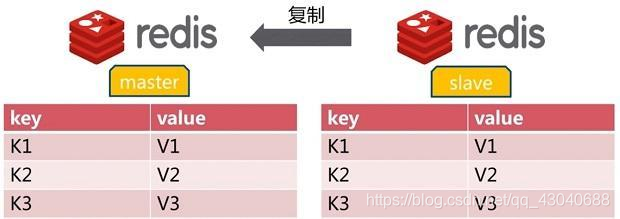
一主多从
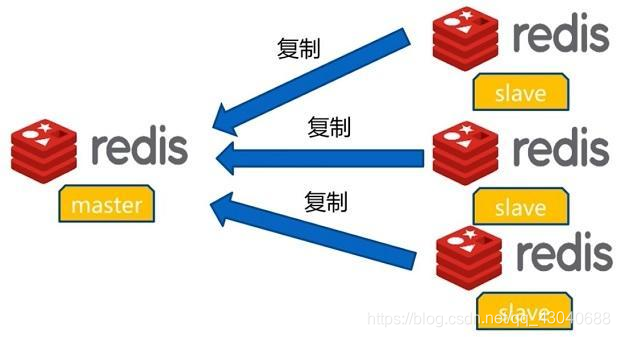
读写分离
除了作为数据备份,主从模型还能做另外一个功能,就是读写分离。
让master节点负责提供写服务,而将数据读取的压力进行分流和负载,分摊给所有的从节点。
总结
主从复制的作用
- 数据副本(
备份) - 扩展读性能(
读写分离).
三、主从复制的配置
slaveof命令
如图,想让6380节点成为6379的从节点,只需要执行 slaveof 命令即可,此复制命令是异步进行的,redis会自动进行后续数据复制的操作。
注:一般生产环境不允许主从节点都在一台机器上,因为没有任何的价值。

如果6380节点不希望成为6379的从节点,可以执行 slave of on one 命令,取消后6380节点的数据不会被清除,只是说后续6379节点新写入的数据不会再同步到该节点了。

注意:如果取消复制后想slave一个新的主节点,新的主节点在同步给slave节点数据时,会先将从节点的数据全部清除
修改配置
配置主节点的IP和端口号
# 配置主节点的IP和端口号
slaveof ip port
# 从节点只做读的操作,保证主从数据的一致性
slave-read-only yes
四、全量复制
全量复制主节点会将RDB文件也就是当前状态去同步给slave,在此期间主新写入的命令会单独记录起来,然后当RDB文件加载完毕之后
全量复制的开销
实际上全量复制的开销是非常大的,主要体现在如下方面
- bgsave时间(对cpu、 内存、硬盘都会有一定的开销)
- RDB文件网络传输时间(网络带宽)
- 从节点清空数据时间(根据从节点的数据规模)
- 从节点加载RDB的时间
- 可能的AOF重写时间(在最后从加载完RDB之后如果开启了AOF,会做AOF重写)
五、部分复制
假如master和slave网络发生了抖动,那一段时间内这些数据就会丢失,对于slave来说这段时间master更新的数据是不知道的
解决:
- 如果发生了抖动,相当于连接断开了
- 主会将写命令记录到缓冲区,repl_back_buffer
- 当slave再次去连接master时候,就是说网络抖动结束之后,会触发增量复制
- 从会执行pysnc命令,将当前自己的offset和主的runid传递给master
- 如果发现传输的offset偏移量是在buffer内的,不在期间内就证明你已经错过了很多数据,buffer也是有限的,默认是1M,会将offset开始到队列结束的数据同步给从。这样master和slave就达到了一致
六、可能出现的问题
读写分离
目的:将读节点分摊到从节点
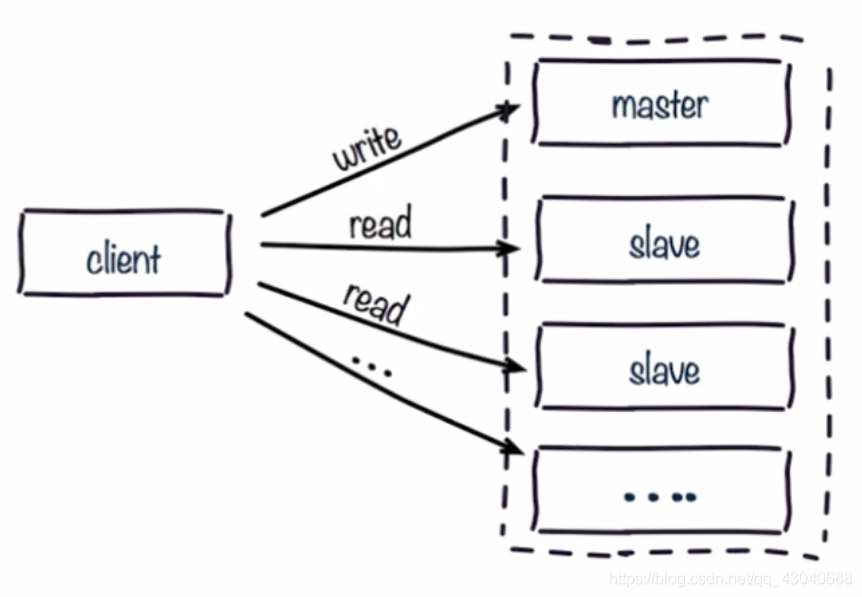
可能遇到问题:
复制数据的延迟读到过期数据(Redis3.2以前的两种删除策略:使用到key的时候,才会查看是否过期;定时查看是否过期)从节点故障
配置不一致
- 例如maxmemory不一致:丢失数据
- 例如数据结构优化参数(例如hash-max-ziplist-entries) :内存不一致
规避复制风暴
当一个主节点挂载多个从节点时,一旦主节点重启,会造成多个从节点的全量复制
解决:改变架构
