一、单机的问题:
1、机器故障:导致redis不可用
2、容量瓶颈:容量不能水平扩展
3、OPS瓶颈:一台机器的网络带宽总是有限的,如果能够分配到多台机器,可以有效解决QPS问题
二、主从复制的作用
1、数据副本:多一份数据副本,保证redis高可用
2、扩展性能:如容量、QPS等
三、主从复制特点
1、一个master可以有多个slave
2、一个slave只能有一个master
3、数据流向是单向的,master到slave
四、实现主从复制的两种方式
1、slaveof命令:
A、在运行的时候执行
B、取消:slaveof no one
2、配置:
A、在启动之前配置,重新配置需要重启,可以统一配置
B、配置项:
slaveof ip port
slave-read-only yes #配置只读
五、redis主从复制的一些概念
1、runid,每次启动redis都会分配一个id,重启之后runid变化。

2、offset,请求master数据额偏移量,部分复制的时候,根据这个进行复制

3、repl_backlog_size,复制缓冲区大小,默认为1M,部分复制的时候,如果offset在这个范围内,则开始部分复制,否者要进行全量复制。可以修改这个大小以达到更好地复制机制。
例如我们计算平均网络断开时间,在算上单位时间内产生的数据数量,两个相乘,就大概得到了我们需要的复制缓冲区大小。可以在这个基础上增加或者减少。
六、全量复制
1、全量复制的原理,过程:
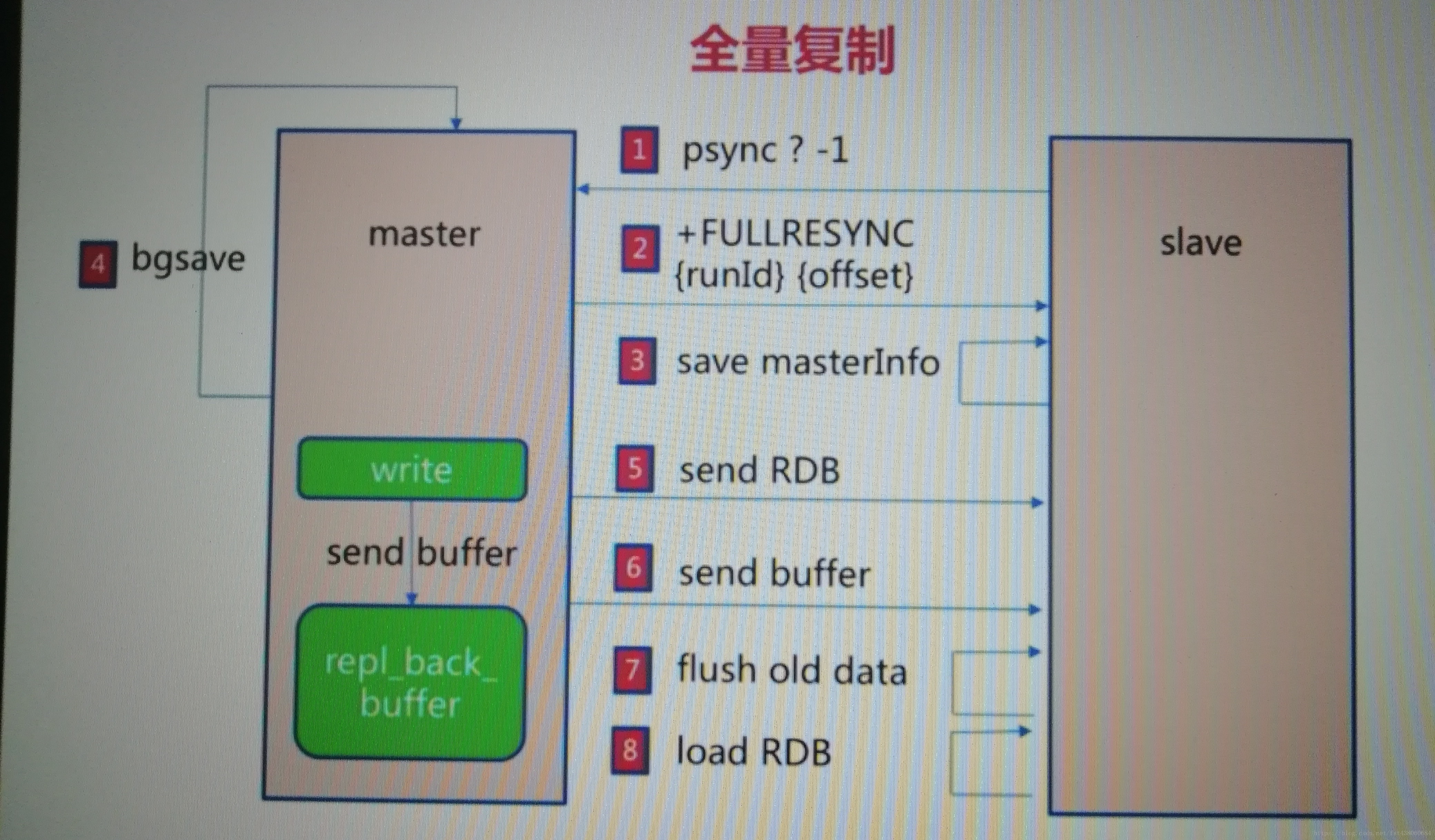
①slave发送psync,由于是第一次复制,不知道master的runid,自然也不知道offset,所以发送psync ? -1
②master收到请求,发送master的runid和offset给从节点。
③从节点slave保存master的信息
④主节点bgsave保存rdb文件
⑤主机点发送rdb文件
并且在④和⑤的这个过程中产生的数据,会写到复制缓冲区repl_back_buffer之中去。
⑥主节点发送上面两个步骤产生的buffer到从节点slave
⑦从节点清空原来的数据,如果它之前有数据,那么久会清空数据
⑧从节点slave把rdb文件的数据装载进自身。
2、全量复制的开销:
①bgsave时间
②rdb文件网络传输时间
③从节点清空数据的
④从节点加载rdb的时间
⑤可能的aof重写时间,这是针对从节点,例如开启了aof之后,从节点添加buffer数据时候,可能需要aof重写
基于上面的原因,有的情况下不适合使用全量复制,例如网络抖动之后,从节点只需要传送一部分数据,不需要传送全部数据,redis2.8之后实现了部分复制功能
七、部分复制
原理:
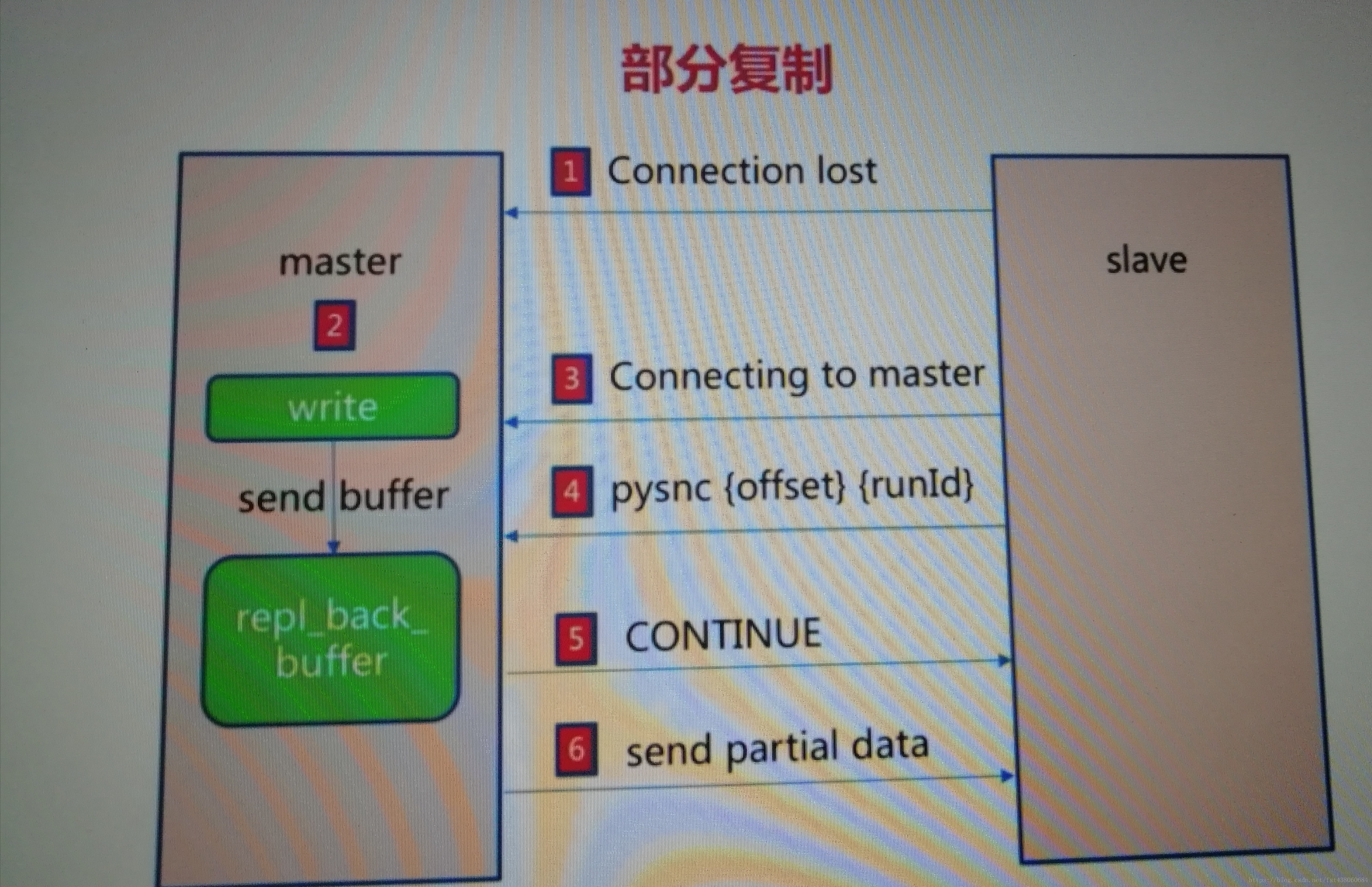
①假设发送网络抖动或者别的情况,暂时失去了连接
②这个时候,master还在继续往buffer里面写数据
③slave重新连接上了master
④slave向master发送自己的offset和runid
⑤master判断slave的offset是否在buffer的队列里面,如果是,那就返回continue给slave,否则需要进行全量复制(因为这说明已经错过了很多数据了)
⑥master发送从slave的offset开始到缓冲区队列结尾的数据给slave
八、redis故障处理
如果master重启了之后,slave再去读取就会读取到一个新的runid,所以就需要全量复制。这个时候最好能用另外一种方式,例如把slave作为晋升为主节点这种自动故障转移机制。redis做了这个功能,例如redis sentinel
九、redis复制常见的问题
1、读写分离:
好处:流量可以分摊到不同的从节点上
可能遇到的问题:
①复制数据的延迟:例如从节点发生阻塞,就会到值复制数据的延迟
②读到过期的数据
③从节点也有可能发生故障
2、配置不一致
例如maxmemory不一致,容易丢失数据,或者发生诡异的情况
数据结构优化参数(例如has-max-ziplist-entries):会出现内存不一致的情况
3、规避全量复制
①第一次全量复制:第一次不可避免,但是我们可以使用小的主节点,或者在半夜低峰的时刻做全量复制
②节点运营的ID不匹配:例如主节点重启,runid就会变化,我们可以使用自动故障转移,例如哨兵或者集群
③复制积压缓冲区不足:网络中断,部分复制功能无法满足,这个时候可以增大复制缓冲区配置rep_backlog_size。
4、规避复制风暴
①单主节点复制风暴:由于主节点从起,多个从节点要复制,会产生复制风暴,解决办法是:更换复制0拓扑
②单机器复制风暴:由于多个主节点都部署在同一个机器上面,机器宕机后需要大量的全量复制,解决办法是:主节点分配到多台机器上面或者使用一些高可用架构,讲从节点晋升为主节点