今天用scrapy框架抓取淘宝信息,因为淘宝的页面都是一个网关程序加载实现的,所以可以说每个页面的信息会随着每一次的刷新有所不同。当然这个我只是普及一下,跟我们今天的抓取关系不大
首先今天的抓取主要的内容是分析ajax请求,然后构造请求。实现的话我用的是scrapy框架,但是用requests也是可以的,只不过抓取的会慢一点而已!所以着重讲的是分析ajax请求,OK?
好了,废话有点多!
今天抓取的是商品“空军一号”的所有搜索结果
首先我们打开fiddler(抓包工具),打开淘宝搜索“空军一号”,通过进入首页我们在fiddler中截获到了几条请求,如图:
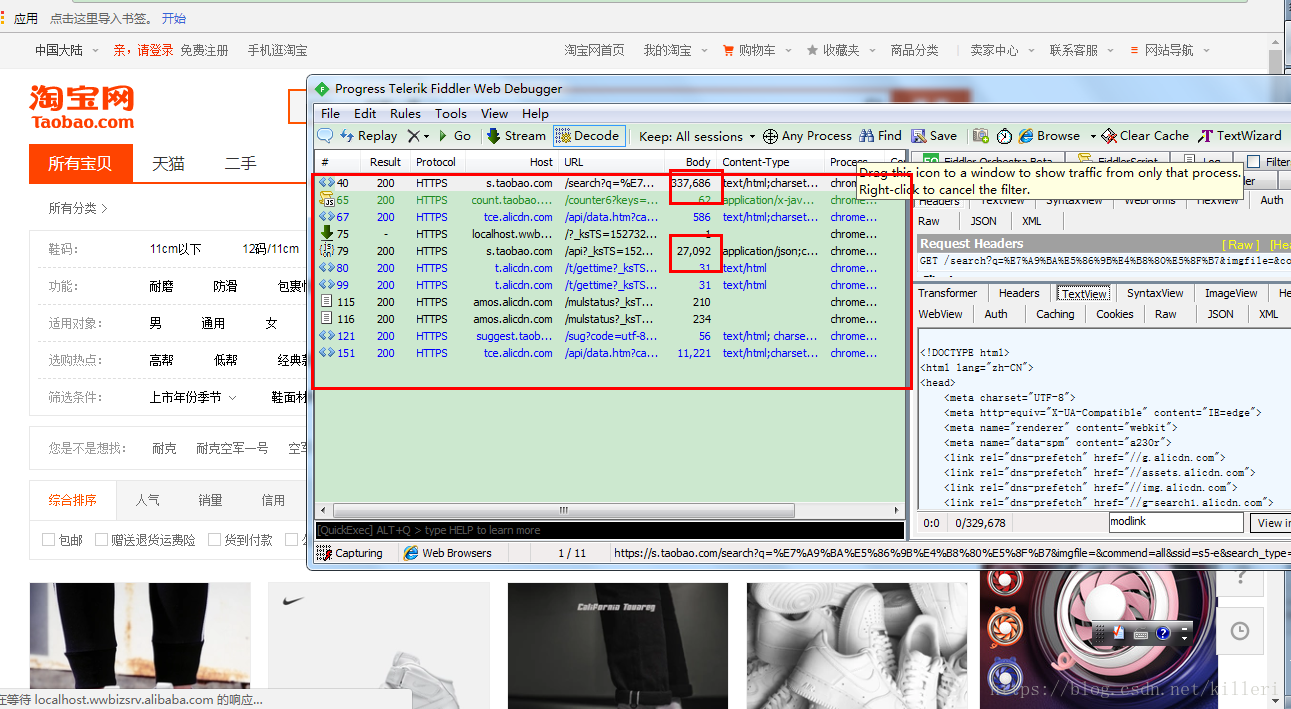
从图中可以看到那几条请求中字节数较多的只有两条,很有可能我们的首页数据就藏在这个里面。
实际上也确实是,首页中的48个商品信息分为两个请求,在两个响应中。第一个是一个标准的html文件,第二个的格式是一个json型的数据,第二个里面放着后面12个商品的信息,那么前36个的信息就在第一个请求中。我们来着重看一下第一个请求。
可以在响应的主体中看到也藏有json型的数据,如图中框起来的!
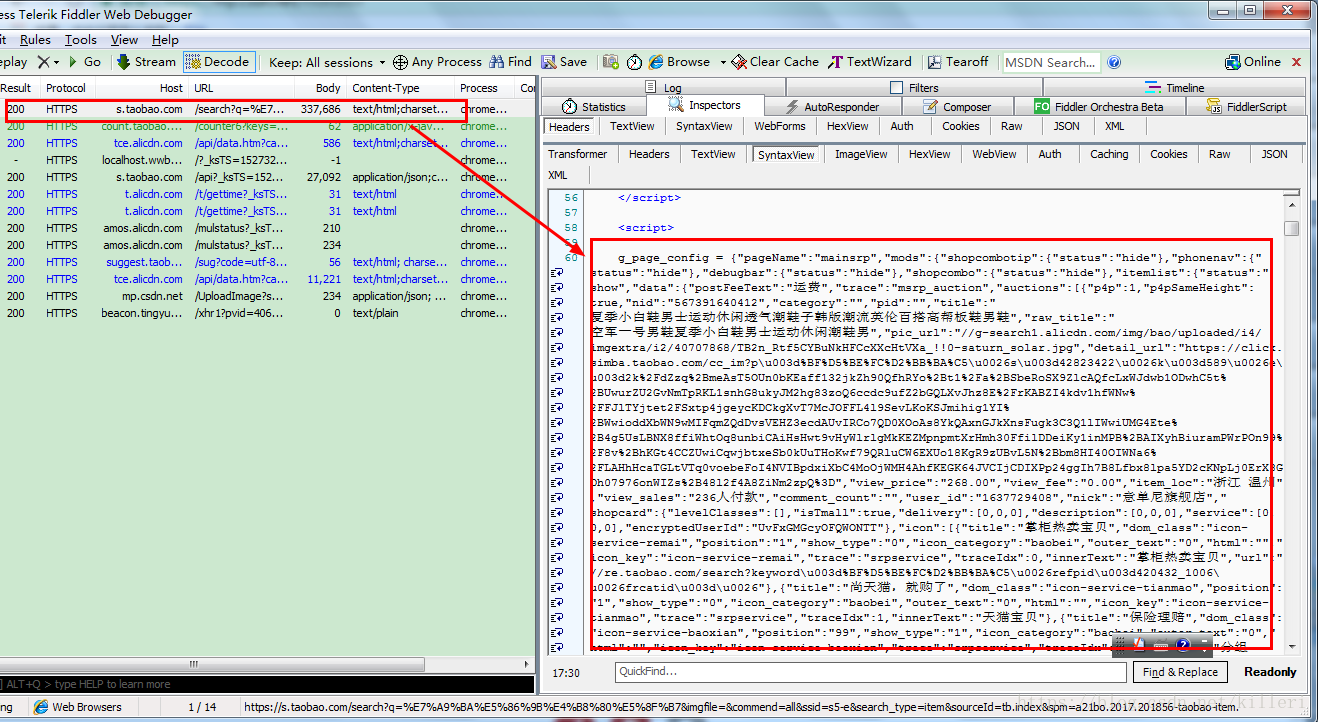
那么,那么我么将图中的json数据用正则匹配出来,然后如同json数据一样进行信息提取不就行了!
我们首先分析一下这个json数据,看看格式是怎么样的!
直接复制这一段类似于json型的数据,由于有点乱,所以我们可以用一个格式化的方法,我这里用的是notep++的JSON Viewer插件,把数据复制进去,然后就可以通过运行插件将json的数据已格式化的方式呈现出来。
如图:
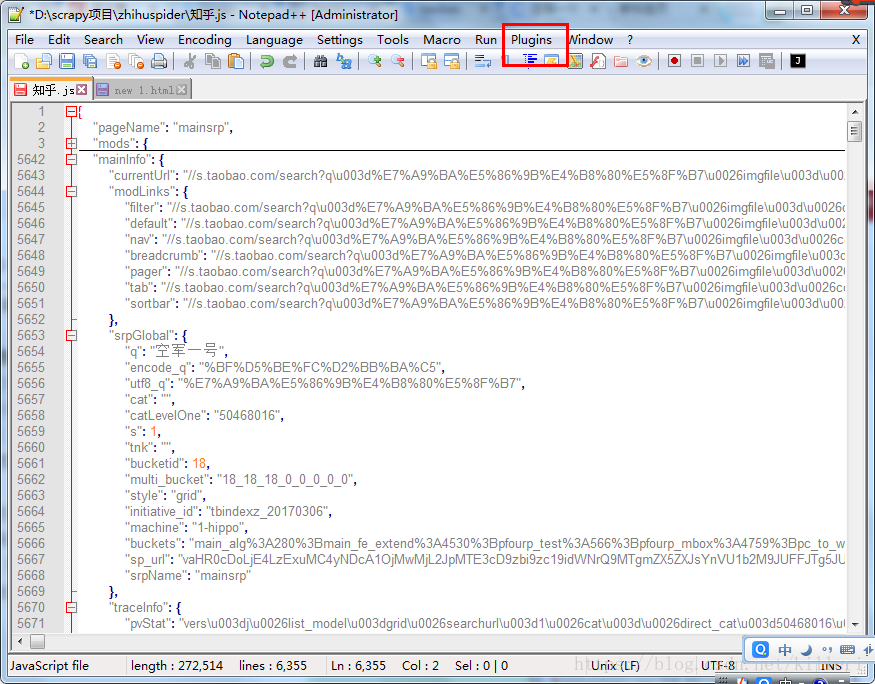
如图中框出来的就是插件位置,然后数据我们已经完全格式化成为我们所需要的json型的数据,接下来只是对首页的数据进行提取就行了。
这个首页的数据并没有动态改变的请求体(当然除了时间戳),所以可以直接请求即可,别忘了加上几个请求头,防止被识别,大致代码如下
pattern = re.compile('g_page_config = ({.*?});', re.S)
# 用正则匹配出json数据
json_data = re.search(pattern, response.text).group(1)
json_l = json.loads(json_data)
# 这里我们就得到了那个json型的数据具体的提取过程我就不详细说了,就是json数据的提取,别忘了加几个请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.162 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encodin': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Referer': 'https://www.taobao.com/',
'Host': 's.taobao.com'
}这是第一个36个商品的请求,和对数据的提取,接下来就是那个12个商品的请求,这个请求加了一个时间戳请求体
请求如下:
https://s.taobao.com/api?_ksTS=1527320555634_238&callback=jsonp239&ajax=true&m=customized&sourceId=tb.index&q=%E7%A9%BA%E5%86%9B%E4%B8%80%E5%8F%B7&spm=a21bo.2017.201856-taobao-item.1&s=36&imgfile=&initiative_id=tbindexz_20170306&bcoffset=-1&commend=all&ie=utf8&rn=07ca89f6b994ae6b55d0c874c3dda726&ssid=s5-e&search_type=item
上面请求中的斜体部分就是加入的时间戳,是一个毫秒级的时间戳,下划线后面的部分我们可以随机生成一个三位或四位的数字,callback加一就可以了,具体构造这两个参数,函数如下:
import time,random
time_stamp = int(round(time.time()*1000))
# 生成毫秒级的时间戳
ran_num = random.randint(100,3000)
# 在100到3000之间随机生成一个数
ksts_str = str(time_stamp) + '_' +str(ran_num)
# 这个就是ksts后面的值
callback_str = 'jsonp' + str(ran_num+1)
# 这个是callback后面的值
# 具体上面代码你有看不懂的可以去百度一下,这里主要是构造的思路 这样我们就可以构造那十二个商品的请求了,这个请求只有时间戳会改变,其他的也是固定不变的。
这里说明一下,由于这两个请求都是首页的请求,所以参数并不会有很大的变化,只有更深层次的请求会从从前面的响应中提取一些数据作为参数,在这里理解请求头中的referer请求头很重要
referer请求头,指明该请求是从哪个请求跳转过来的。,一般我们找到这个跳转的请求的响应体,可以从响应体重找到下一个请求的参数(有点绕口,望仔细品读)
好了,从上面的两步,我们已经提取了首页的全部48个商品的信息了,接下来还有99个页面等着我们去提取(一共有100页的请求结果)
我们点击下一页,看抓包工具又多了哪些请求如图:
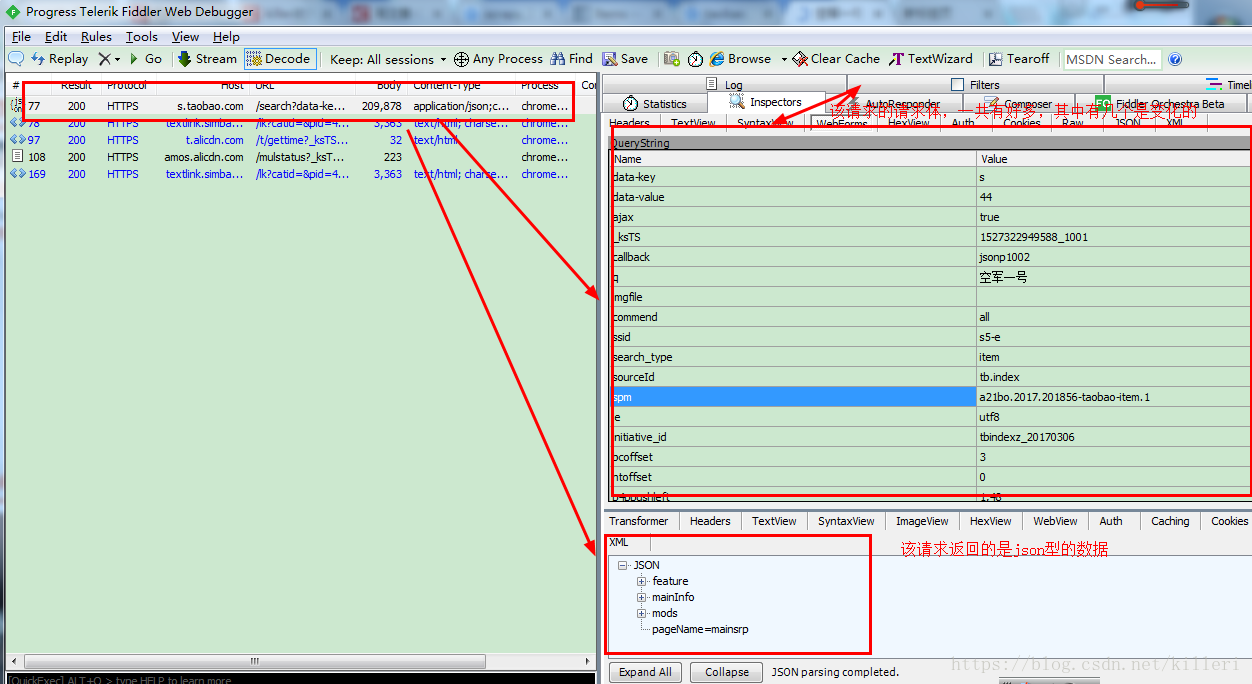
如图我们翻到第二页,看到返回的是一个全是json型的数据,那对数据的提取并不难,但是有一个难题的这个请求的请求体很多,经过测试,其中除了时间戳外还有好几项都是改变的。
所以接下来我们重点分析的是请求体,在哪里可以找到请求体,只有找到了哪些变化的请求体我们才能构造出接下来的请求,实现自动化的抓取(对json型数据的提取我就不说了,很简单的。)

我们要用到fiddler的关键字搜索功能,既然是第二页的请求, 而这个请求又是 从图中的请求跳转过来的,那么我们就一定可以从跳转请求的响应体中找到这些请求体
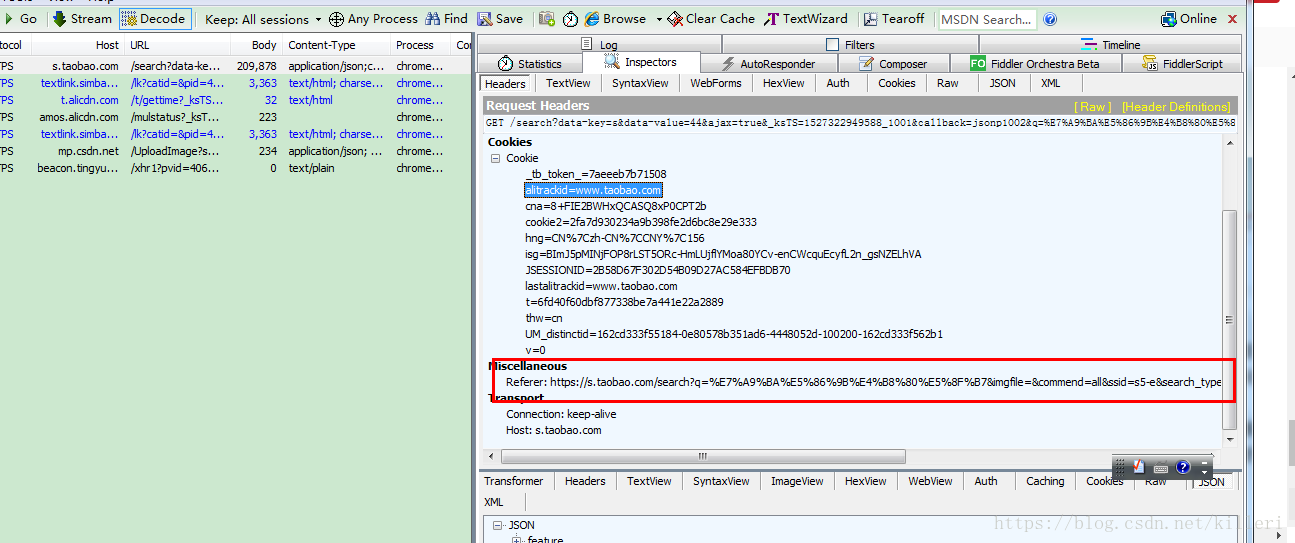
图中框出来的请求就是第一个36个商品的请求,那么我们在它的响应体重搜索
如图:
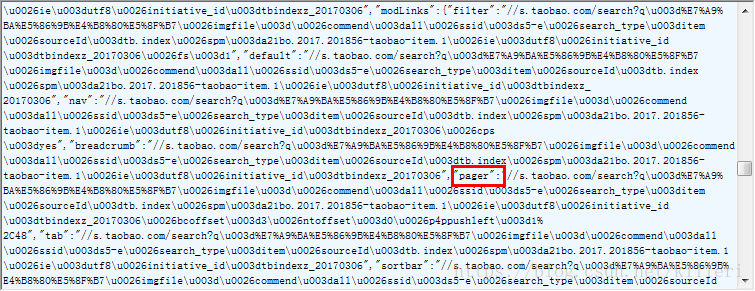
至于为什么按那个关键字搜索请求体,且听下面更多的分解。
到这个我们已经找到了这个可变的参数在哪里(这里你不明白就往下看,下面有更详细的原因解释!!!!)
好了,经过上面的解析,我们已经知道了该去哪找变化的参数(仅限于第二页的变化参数)
继续下行,我们要找到第三页,第四页的变化参数在那呀!
对于第三页的参数,我们当然是从它的跳转页面的响应中找变化的参数了,
第三页的链接如下:
https://s.taobao.com/search?data-key=s&data-value=88&ajax=true&_ksTS=1527324090969_1099&callback=jsonp1100&q=%E7%A9%BA%E5%86%9B%E4%B8%80%E5%8F%B7&imgfile=&commend=all&ssid=s5-e&search_type=item&sourceId=tb.index&spm=a21bo.2017.201856-taobao-item.1&ie=utf8&initiative_id=tbindexz_20170306&bcoffset=0&ntoffset=6&p4ppushleft=1%2C48&s=44**其中加粗的值会改变的参数**
由于第二页的响应是一个比较纯的json数据,我们只好一个标签一个标签的找:
最终在这里
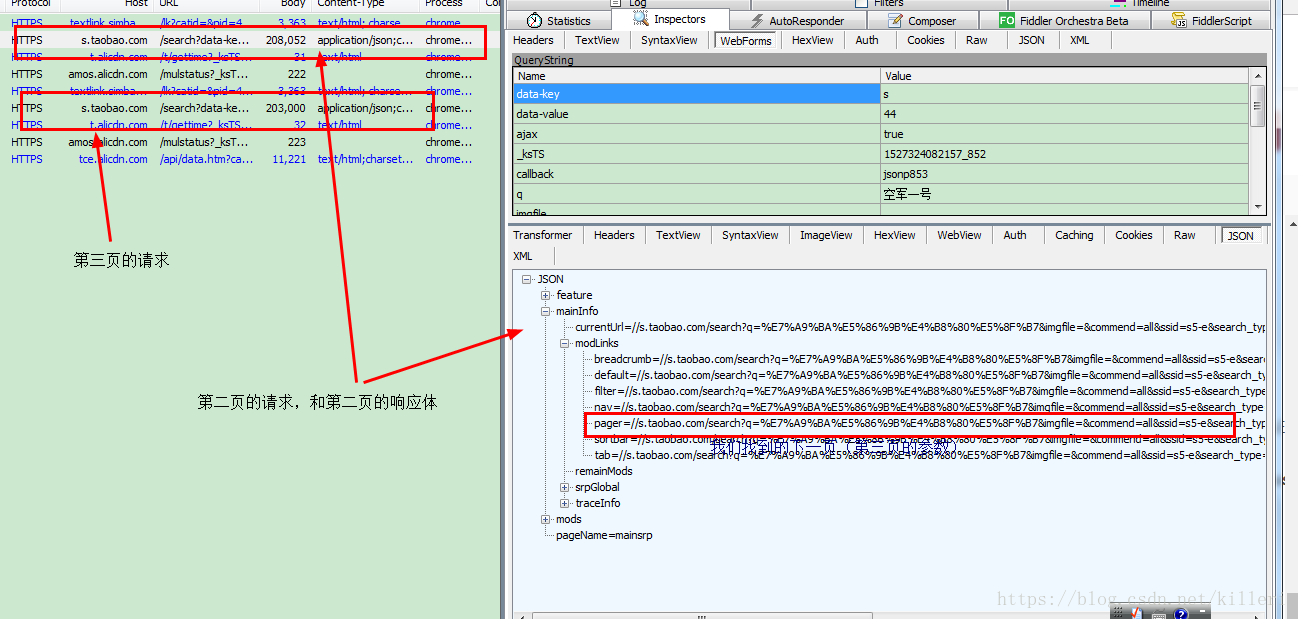
如图中,我们最终在第二页的响应体的pager这一个链接地址找到了第三页的链接参数,复制过来如下:
pager=//s.taobao.com/search?q=%E7%A9%BA%E5%86%9B%E4%B8%80%E5%8F%B7&imgfile=&commend=all&ssid=s5-e&search_type=item&sourceId=tb.index&spm=a21bo.2017.201856-taobao-item.1&ie=utf8&initiative_id=tbindexz_20170306&bcoffset=0&ntoffset=6&p4ppushleft=1%2C48&s=44
注意看这个加粗的是不是和第三页请求中变化的参数是一样的。
接下来我们只要加工一下这个请求就可以构造出第三页的链接了。
查看pager所表示的链接中少了那几个参数,加进去就可以构造出第三页的链接了。
next_partial_url = json_l.get('mainInfo').get('modLinks').get('pager')
time = self.get_time_stamp()
callback = 'jsonp' + str(int(time[1]) + 1)
data_value = 44
# 每一页的data-value要加上44,这是一个有规律的变化参数
other_data = {
'data-key' : 's',
'data-value' : str(data_value),
'ajax' : 'true',
'_ksTS': time[0],
'callback' : callback
}
# 这是需要补齐的参数
next_url = 'https:' + next_partial_url + '&' + parse.urlencode(other_data)
# 这里我们构造出了下一页的链接现在知道我们前面的搜索的关键字为什么是modlinks了吗?因为从后面看,pager这个就是包含在modlinks里面的
**好了,这样我们就能通过这种方式不断地构造出后面的链接了,一直到100页。
详细代码我贴出来,使用scrapy实现的,可以认真的看一下,对于新手来说,有一些必须掌握的方法在里面,对了,看了这个我相信你对scrapy和python的类会有一个更深的了解**
spider文件:taobaospider.py
# -*- coding: utf-8 -*-
import scrapy
import time,re,json,random
from time import sleep
from urllib import parse
from scrapy.http import Request
from taobao.items import TaobaoItem
class TaobaospiderSpider(scrapy.Spider):
name = 'taobaospider'
allowed_domains = ['taobao.com']
def get_time_stamp(self):
time_stamp = int(round(time.time() * 1000))
ran_num = random.randint(100, 3000)
ksts = str(time_stamp) + '_' + str(ran_num)
return ksts,str(ran_num)
# 这里我直接声明了一个方法,用于获取时间戳和callback,返回两者的元组。
def start_requests(self):
# 这里我们去掉了start_urls,直接用这个方法来构造初始请求
data_fir = {
'q' : '空军一号',
'imgfile' : '',
'commend' : 'all',
'ssid' : 's5-e',
'search_type' : 'item',
'sourceId' : 'tb.index',
'spm' : 'a21bo.2017.201856-taobao-item.1',
'ie' : 'utf8',
'initiative_id' : 'tbindexz_20170306'
}
url = 'https://s.taobao.com/search?' + parse.urlencode(data_fir)
# 构造参数的链接的方式
yield Request(url=url,callback=self.parse)
time = self.get_time_stamp()
callback = 'jsonp' + str(int(time[1])+1)
# 时间戳和callback参数的构造
data_sec = {
'_ksTS' : time[0],
'callback' : callback,
'ajax' : 'true',
'm' : 'customized',
'sourceId' : 'tb.index',
'q' : '空军一号',
'spm' : 'a21bo.2017.201856-taobao-item.1',
's' : '36',
'ie': 'utf8',
'initiative_id': 'tbindexz_20170306',
'bcoffset' : '-1',
'imgfile' : '',
'rn' : '15339ec798bab63adebc3d45909aaaef',
'ssid' : 's5 - e',
'search_type' : 'item'
}
urls = 'https://s.taobao.com/api?' + parse.urlencode(data_sec)
yield Request(url=urls,callback=self.parse_sec)
def parse_sec(self,response):
json_html = re.search('jsonp\d+?\(({.*?})\)', response.text, re.S).group(1)
json_htmll = json.loads(json_html)
item = TaobaoItem()
for datas in json_htmll.get('API.CustomizedApi').get('itemlist').get('auctions'):
item['item_loc'] = datas.get('item_loc')
item['pic_url'] = 'https:' + datas.get('pic_url')
item['raw_title'] = datas.get('raw_title')
item['shop_link'] = datas.get('shop_link')
item['view_price'] = datas.get('view_price')
item['view_sales'] = datas.get('view_sales')
file_names = ['item_loc', 'pic_url', 'raw_title', 'view_price', 'view_sales', 'shop_link']
for name in file_names:
if item[name] == None:
item[name] = 'there is no item data'
yield item
def parse(self, response):
pattern = re.compile('g_page_config = ({.*?});', re.S)
# 匹配出json型的数据,用正则。
json_data = re.search(pattern, response.text).group(1)
json_l = json.loads(json_data)
item = TaobaoItem()
for datas in json_l.get('mods').get('itemlist').get('data').get('auctions'):
item['item_loc'] = datas.get('item_loc')
item['pic_url'] = 'https:' + datas.get('pic_url')
item['raw_title'] = datas.get('raw_title')
item['shop_link'] = datas.get('shop_link')
item['view_price'] = datas.get('view_price')
item['view_sales']= datas.get('view_sales')
file_names = ['item_loc', 'pic_url', 'raw_title', 'view_price', 'view_sales', 'shop_link']
for name in file_names:
if item[name] == None:
item[name] = 'there is no item data'
yield item
next_partial_url = json_l.get('mainInfo').get('modLinks').get('pager')
time = self.get_time_stamp()
callback = 'jsonp' + str(int(time[1]) + 1)
data_value = 44
other_data = {
'data-key' : 's',
'data-value' : str(data_value),
'ajax' : 'true',
'_ksTS': time[0],
'callback' : callback
}
next_url = 'https:' + next_partial_url + '&' + parse.urlencode(other_data)
# 这里获得第二页的基本链接,要加上时间戳
data_values = data_value + 44
yield Request(url=next_url,meta={'data_value' : data_values},callback=self.parse_item)
# meta参数用于传递页数
def parse_item(self,response):
str_data = re.search('jsonp\d+?\(({.*?})\)',response.text,re.S).group(1)
with open('D:/taobao/x.txt','w') as f:
f.write(str_data)
json_data = json.loads(str_data)
itemlist = json_data.get('mods').get('itemlist').get('data').get('auctions')
for datas in itemlist:
item = TaobaoItem()
item['item_loc'] = datas.get('item_loc')
item['pic_url'] = 'https:' + datas.get('pic_url')
item['raw_title'] = datas.get('raw_title')
item['shop_link'] = datas.get('shop_Link')
item['view_price'] = datas.get('view_price')
item['view_sales'] = datas.get('view_sales')
file_names = ['item_loc', 'pic_url', 'raw_title', 'view_price', 'view_sales', 'shop_link']
for name in file_names:
if item[name] == None:
item[name] = 'there is no item data'
yield item
pager = json_data.get('mainInfo').get('modLinks').get('pager')
print('爬取一页结束')
# 调试信息
# 这里获得了下一页的基本链接,还有加上时间戳
time = self.get_time_stamp()
callback = 'jsonp' + str(int(time[1]) + 1)
other_data = {
'data-key': 's',
'data-value': str(response.meta['data_value']),
'ajax': 'true',
'_ksTS': time[0],
'callback': callback
}
next_url = 'https:' + pager + '&' + parse.urlencode(other_data)
# 这里获得第二页的基本链接,要加上时间戳
data_values = response.meta['data_value'] + 44
yield Request(url=next_url,meta={'data_value':data_values}, callback=self.parse_item)
基本上就是这样,这里有什么不懂得可以私信我!
管道文件:pipelines.py
import csv
class TaobaoPipeline(object):
def open_spider(self,spider):
self.file = open('D://taobao/淘宝信息.csv','w')
def process_item(self, item, spider):
# 将信息写进csv文件中
file_names = ['item_loc','pic_url','raw_title','view_price','view_sales','shop_link']
for name in file_names:
if item[name] == None:
item[name] = 'there is no item data'
dict_writer = csv.DictWriter(self.file,fieldnames=file_names)
dict_writer.writerow(dict(item))
return item
def close_item(self,spider):
self.file.close()csv内置模块了解一下?
设置文件:settings.py
DEFAULT_REQUEST_HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.162 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encodin': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Referer': 'https://www.taobao.com/',
'Host': 's.taobao.com'
}主要是请求头的设置
tiem文件:items.py
from scrapy import Item,Field
class TaobaoItem(Item):
item_loc = Field()
pic_url = Field()
raw_title = Field()
view_price = Field()
view_sales = Field()
shop_link = Field()
好了,基本上就是这样,我们已经爬去了关于所有‘空军一号’信息了,当然改良一下就可以爬取其他商品了。
成果贴一下:

可以看到我们已经爬取了5000条的信息了,算算,每页44个,一共也差不多!爬完了。
有什么问题私信和我交流!