本文记录了分析Ajax请求抓取今日头条街拍美图,并将相关信息保存到数据库以及将图片保存到本地的过程。网络库使用requests,解析库使用BeautifulSoup以及正则表达式,存储的数据库使用MongoDB。
在抓取网页信息时,有些内容是通过Ajax加载,并通过js渲染生成的,所以直接请求得到的html代码里面可能没有我们在浏览器中看到的内容,这时候就需要对网页请求作出分析。
(1)目标站点分析
首先打开今日头条网页(www.toutiao.com),在搜索框输入“街拍”:
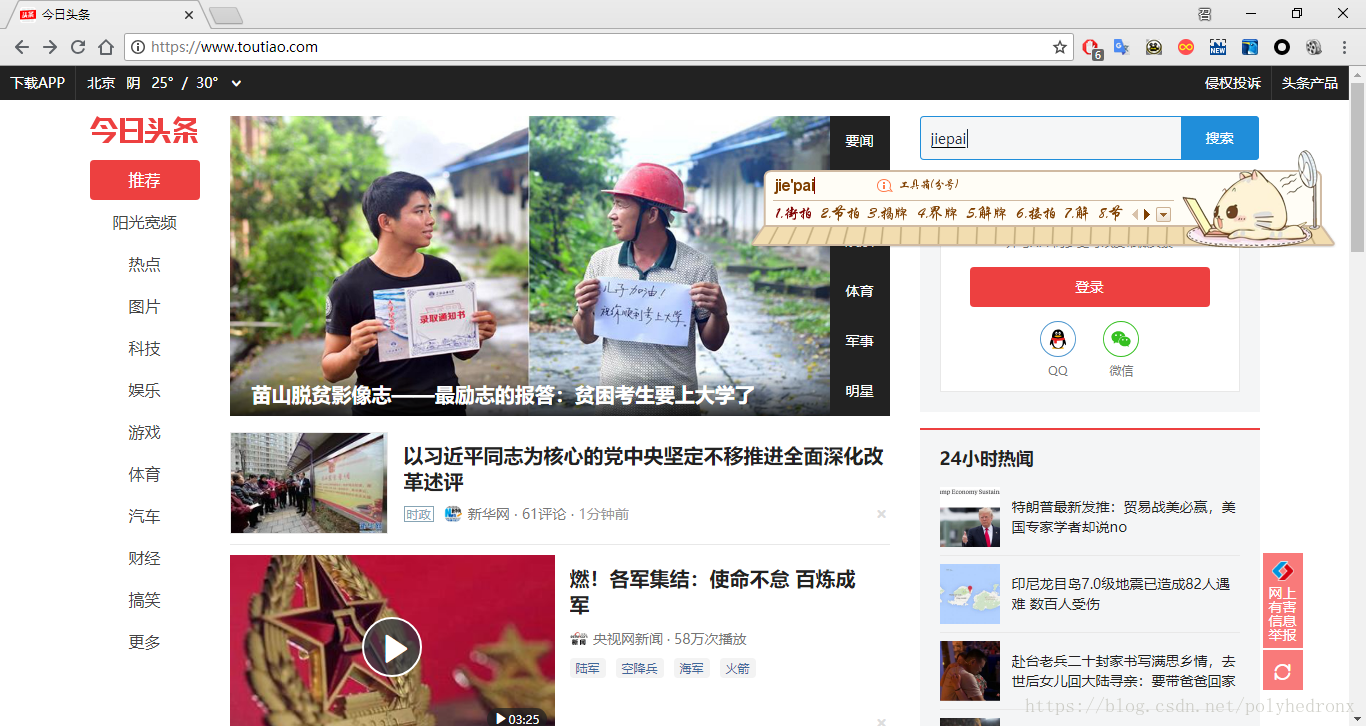
成功加载出了街拍的内容,点击“图集”,出现了一系列的街拍组图,也就是我们要爬取的内容。

接下来在网页中右键,打开“检查”,选中Network选项卡,勾选上“Preserve log”,并刷新网页,找到原始请求,查看请求返回结果:
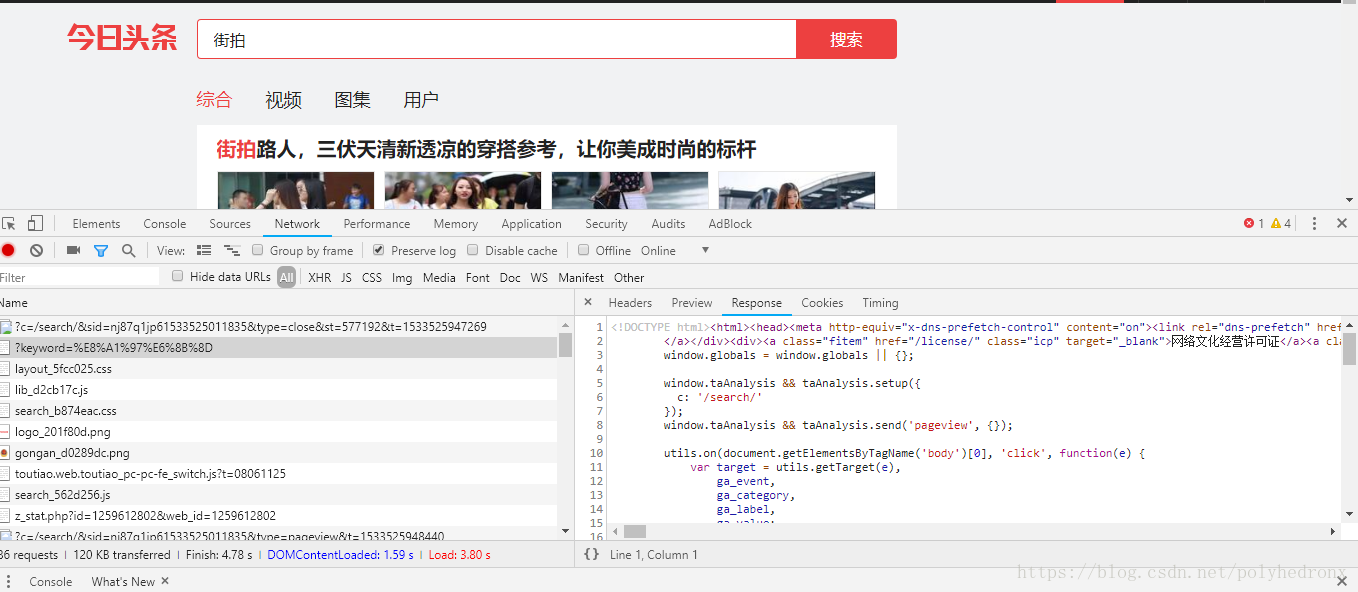
可以看到,返回的都是一些js标签,并没有网页中的组图标题和图片链接等信息,这说明信息是通过Ajax加载,Ajax又是什么呢?
Ajax即Asynchronous JavaScript and XML(异步的 JavaScript 和 XML),它是一种用于创建快速动态网页的技术。传统的网页(不使用 Ajax)如果需要更新内容,必须重载整个网页页面。通过在后台与服务器进行少量数据交换,Ajax 可以使网页实现异步更新,这意味着可以在不重新加载整个网页的情况下,对网页的某部分进行更新。
这个定义虽然看的云里雾里,但大概知道了我们的请求并没有直接返回有用信息,而是在网页(的外壳?)加载出来后通过Ajax技术创建XMLHttpRequest (XHR)对象,用于在后台与服务器交换数据。根据推断,我们打开XHR选项,再次点击“图集”,并点击“Preview”查看返回结果:
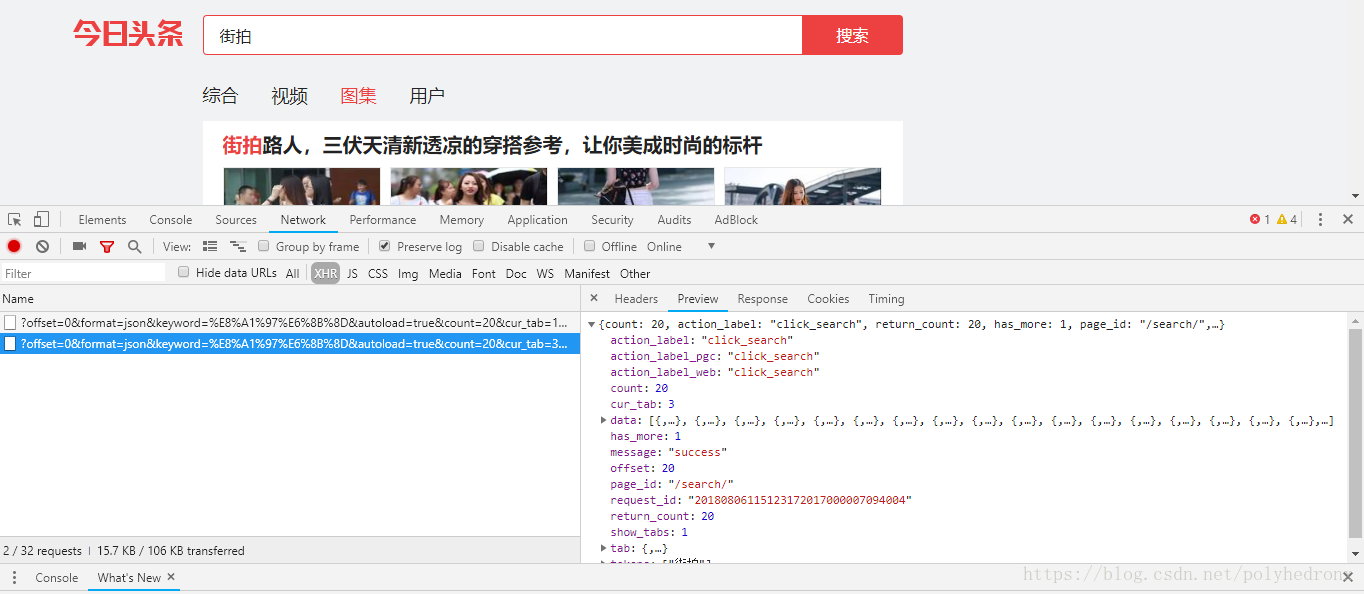
我们打开data-->0,下拉找到“title”选项,发现这就是我们要找的返回数据。
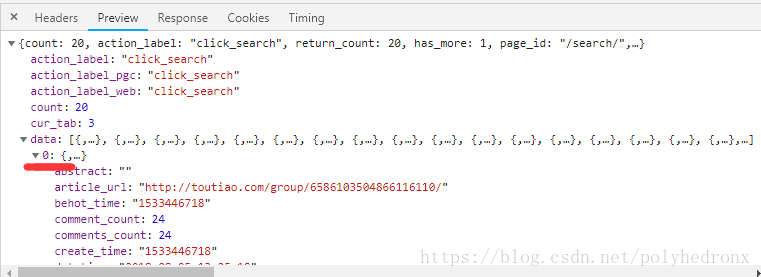

当我们不断下拉网页时,开始加载出了新的图集,也开始出现新的Ajax请求:
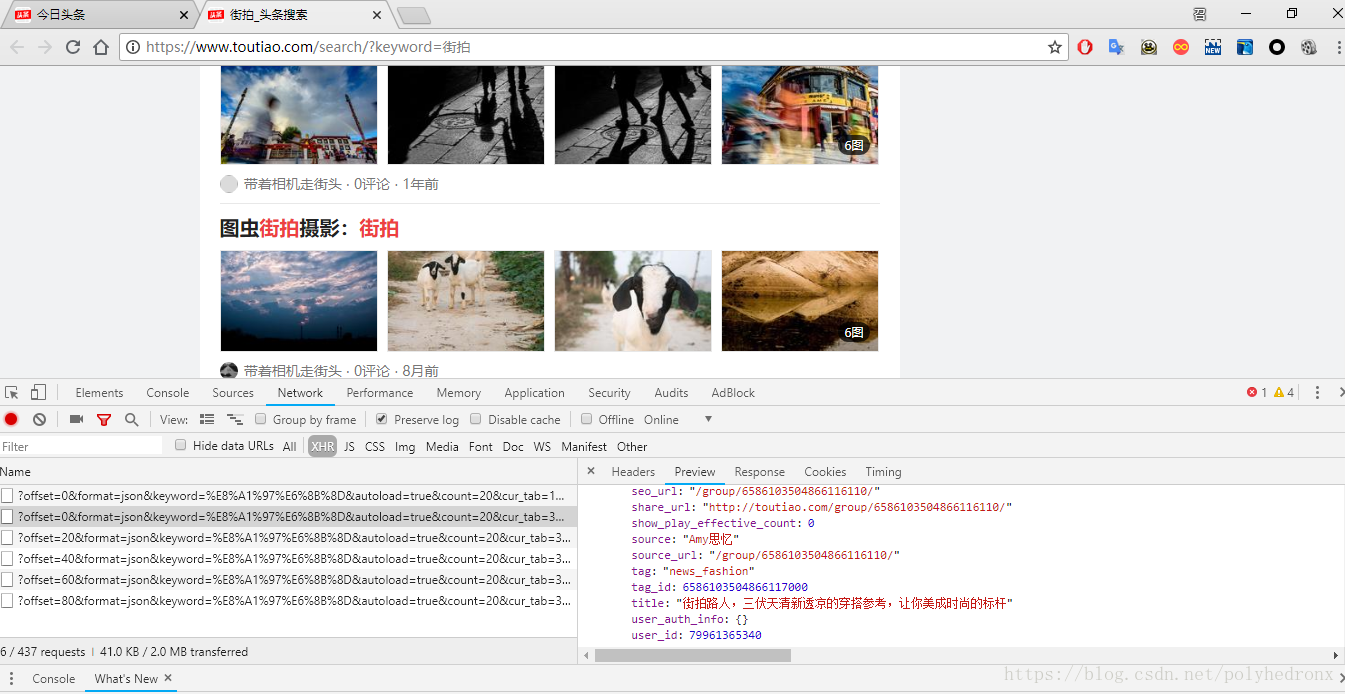
而且显而易见,不同的Ajax请求唯一的不同点就是“offset”值的变化,从0变成了20又变成40-60-80这种,也就是说,我们只要改变请求参数里面的“offset”的值,就可以得到不同的返回数据,即通过一个循环,就可以不断得到网页中街拍组图数据。
Ajax请求返回的是一些json格式的数据,拿到返回信息以后用json包处理即可得到想要的数据。
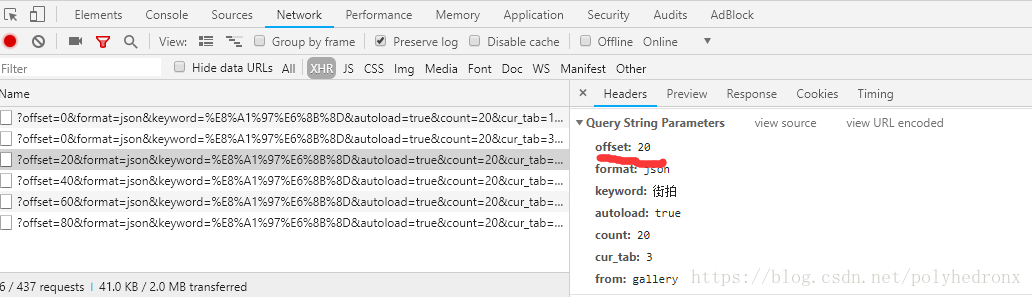
下面我们分析一下每个页面的街拍美图。点开其中一个组图,同样右键“检查”,点击“Network”,选中“Preserve log”,然后刷新页面,找到最原始的请求,分析其Response中有没有我们想要的数据:
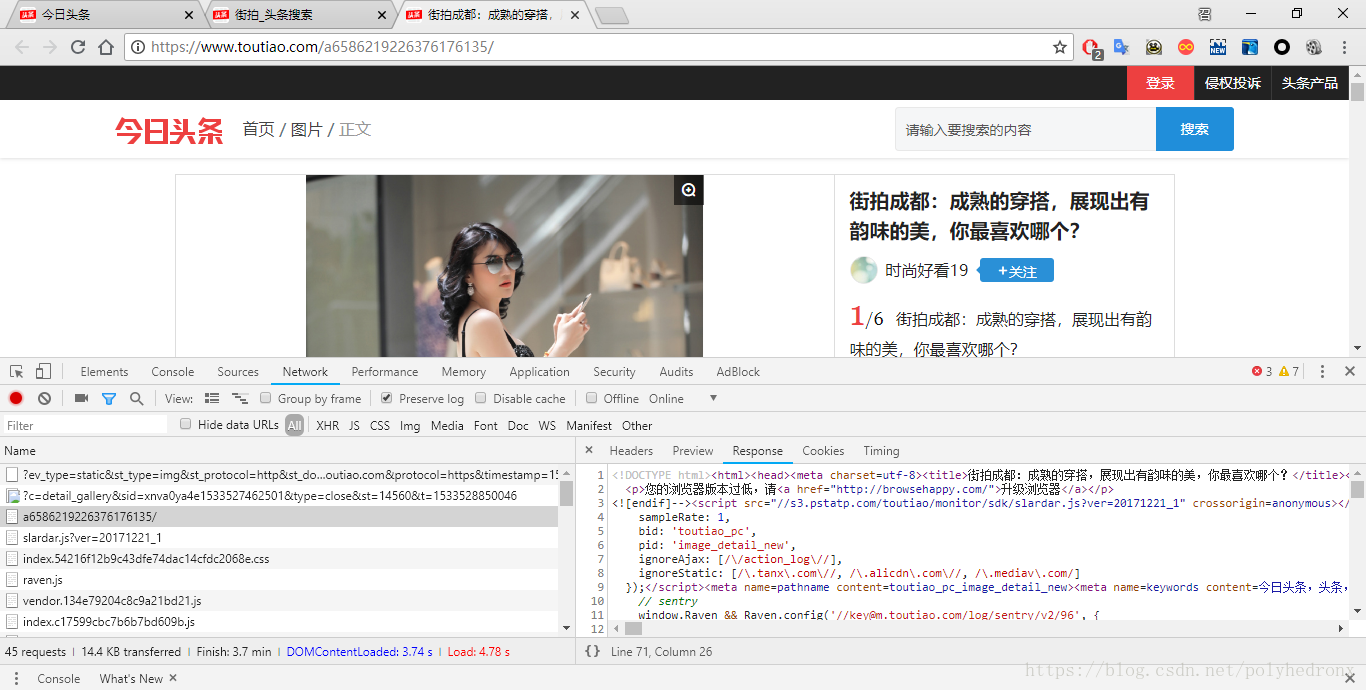
打开第一张图片,可以看到它的url:
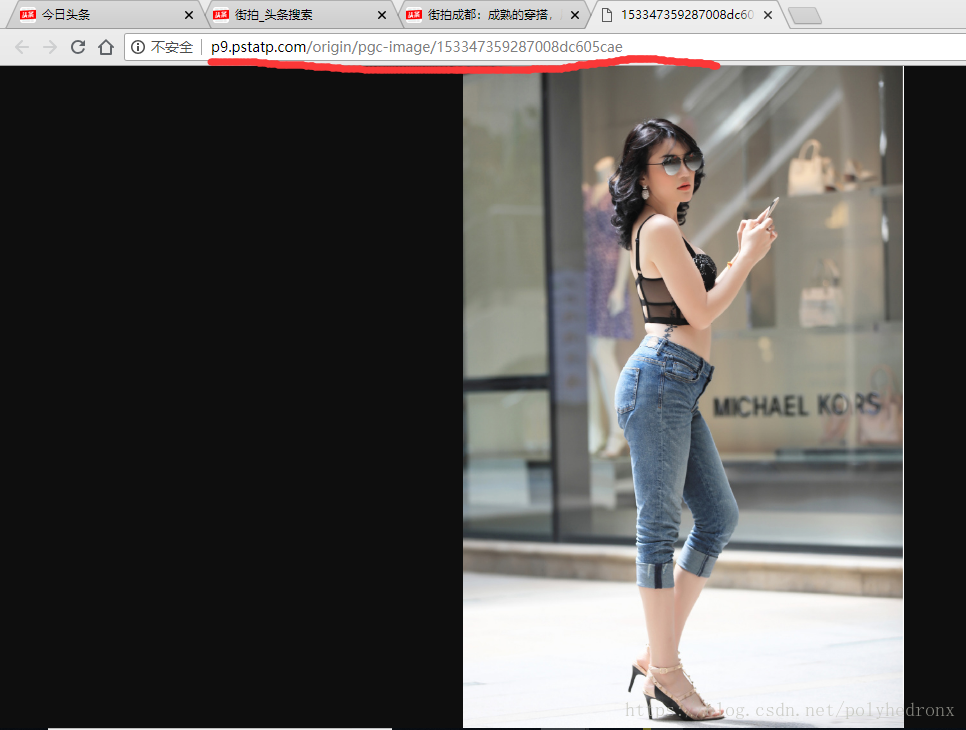
我们在Response中同样发现了这个地址:
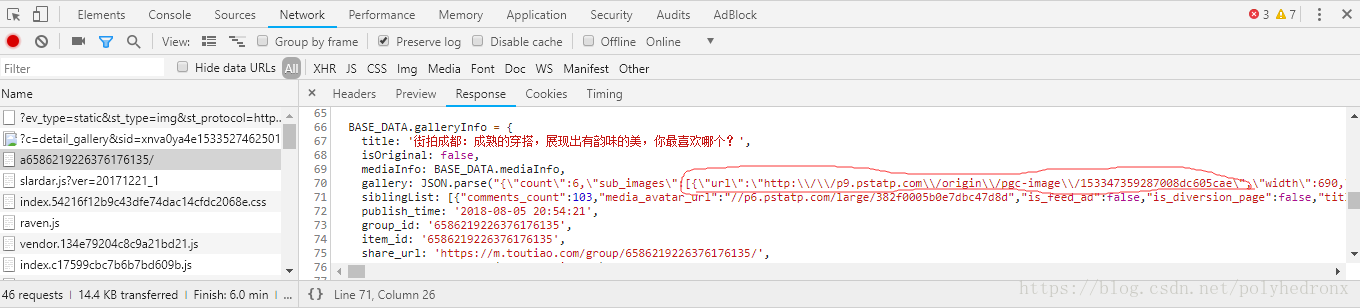
这说明组图中每张图片的信息不再是通过Ajax加载,而是在原始请求文档的js里面。我们现在要做的就是把gallery解析出来,由于gallery不是隐藏在html里面的,就不能用BeautifulSoup、PyQuery这样的库进行解析,所以比较简单的方法就是用正则表达式进行解析。
(2)流程框架
1.抓取索引页内容
利用requests请求目标站点,得到索引页HTML代码,返回结果。
2.抓取详情页内容
解析返回结果,得到详情页的链接,并进一步抓取详情页的信息。
3.下载图片与保存数据库
将图片下载到本地,并把页面信息和图片URL保存至MongoDB。
4.开启循环及多进程
对多页内容遍历,开启多线程提高抓取速度。
(3)爬虫代码
# jiepai.py
import codecs
import os
import re
from _md5 import md5
from json import JSONDecodeError
import pymongo as pymongo
import requests
from urllib.parse import urlencode
from bs4 import BeautifulSoup
from requests.exceptions import RequestException
import json
from config import *
from multiprocessing import Pool
client = pymongo.MongoClient(MONGO_URL, connect=False)
db = client[MONGO_DB]
def get_page_index(offset, keyword):
data = {
'offset': offset,
'format': 'json',
'keyword': keyword,
'autoload': 'true',
'count': '20',
'cur_tab': 3,
'from': 'gallery'
}
url = 'https://www.toutiao.com/search_content/?' + urlencode(data)
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
+ 'Chrome/67.0.3396.99 Safari/537.36'
}
response = requests.get(url, headers=headers) # 模拟成浏览器
if response.status_code == 200:
return response.text
return None
except RequestException:
print('请求索引页出错')
return None
def parse_page_index(html):
try:
data = json.loads(html) # 将json格式的字符串转化为字典
if data and 'data' in data.keys():
for item in data.get('data'):
yield item.get('article_url')
except JSONDecodeError:
pass
def get_page_detail(url):
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
+ 'Chrome/67.0.3396.99 Safari/537.36'
}
response = requests.get(url, headers=headers) # 模拟成浏览器
if response.status_code == 200:
return response.text
return None
except RequestException:
print('请求详情页出错', url)
return None
def parse_page_detail(html, url):
soup = BeautifulSoup(html, 'lxml')
title = soup.select('title')[0].get_text()
'''
# 判断title是否存在
if soup.select('title'):
title = soup.select('title')[0].get_text()
else:
title = 'None'
'''
images_pattern = re.compile('gallery.*?"(.*?)"\)', re.S)
result = re.search(images_pattern, html)
if result:
# codecs: 使不具有转义的反斜杠具有转义功能
data_str = codecs.getdecoder('unicode_escape')(result.group(1))[0]
json_data = json.loads(data_str) # 转化为字典
if json_data and 'sub_images' in json_data.keys():
sub_images = json_data.get('sub_images')
images = [item.get('url') for item in sub_images]
# 下载图片
for image in images:
download_image(image)
return {
'title': title,
'url:': url,
'images': images
}
def save_to_mongo(result):
if db[MONGO_DB].insert(result):
print('成功存储到MongoDB', result)
return True
return False
def download_image(url):
print('正在下载', url)
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
+ 'Chrome/67.0.3396.99 Safari/537.36'
}
response = requests.get(url, headers=headers) # 模拟成浏览器
if response.status_code == 200:
save_iamge(response.content)
return None
except RequestException:
print('请求图片出错', url)
return None
def save_iamge(content):
file_path = '{0}/{1}.{2}'.format('E:/PycharmProjects/jiepai_img', md5(content).hexdigest(), 'jpg')
if not os.path.exists(file_path):
with open(file_path, 'wb') as f:
f.write(content)
f.close()
def main(offset):
html = get_page_index(offset, KEYWORD)
for url in parse_page_index(html):
if url:
html_sub = get_page_detail(url)
if html_sub:
result = parse_page_detail(html_sub, url)
if result:
save_to_mongo(result)
if __name__ == '__main__':
groups = [x*20 for x in range(GROUP_START, GROUP_END)]
pool = Pool()
pool.map(main, groups)
# config.py
MONGO_URL = 'localhost'
MONGO_DB = 'toutiao'
MONGO_TABLE = 'toutiao'
GROUP_START = 0
GROUP_END = 20
KEYWORD = '街拍'