介绍
为了更好地利用目标语言单语语料, Improving Neural Machine Translation Models with Monolingual Data 提出了两种方式
- 假如有目标语言句子y, 将源语言对应的句子设置为空, 得到句对 (dummy, y), 加入到平行语料中进行训练. 这样在有平行句对和(dummy, y)句对的情况下, 训练翻译系统可以想想成翻译和语言模型多任务训练, 因为输入dummy, 使得y的概率最大, 实际上等价于训练一个语言模型.
- 反向翻译: 有了目标语言句子y, 用训练好的目标语言到源语言的翻译模型得到伪句对(x’, y), 加入到平行句对中一起训练. 因为y是高质量的单语语料, x‘可能包含一些UNK, 或者错误的句法等, 质量较差. 这样训练可以想像成去噪声训练的形式. 在有噪声的情况下, 训练x->y方向的翻译模型尽量能还能翻译好, 提升泛化性能.
- 使用时机: 一般先用高质量的句对训练好初始模型后, 然后将反向翻译的句对(x’,y)和训练语料混合, 再次训练.
实验文章
Understanding Back-Translation at Scale
实验性文章, 分析了在不同场景下反向翻译的表现
一般结论
- 反向翻译平均来讲能提升~2BLEU
- 在低资源情况下, 因为翻译模型的性能较差, 因此得到的句对(x’, y) 质量较差, 可能需要过滤一下才行
- 如果有跨领域的单语语料, 用反向翻译进行训练一下, 得到的模型跨领域表现会提升.
不同的采样方法的影响
得到句对(x’, y)可以有不同的采样方式
- sampling: 直接从翻译模型中输入y, 采样得到一个x’
- beam search: 根据beam search得到x‘, 这样x’的质量较高
- beam + noise: 在beam search的过程中, 添加给token添加随机噪声
- greedy: 根据输入y, 翻译时每一步采用最好的一个token, 翻译得到x’
- top10: 根据输入y, 翻译时每一个在前10个最可能的token中采样得到下一个token
不同采样方式下, 平行语料较多的情况下, 反向翻译的效果如下图:
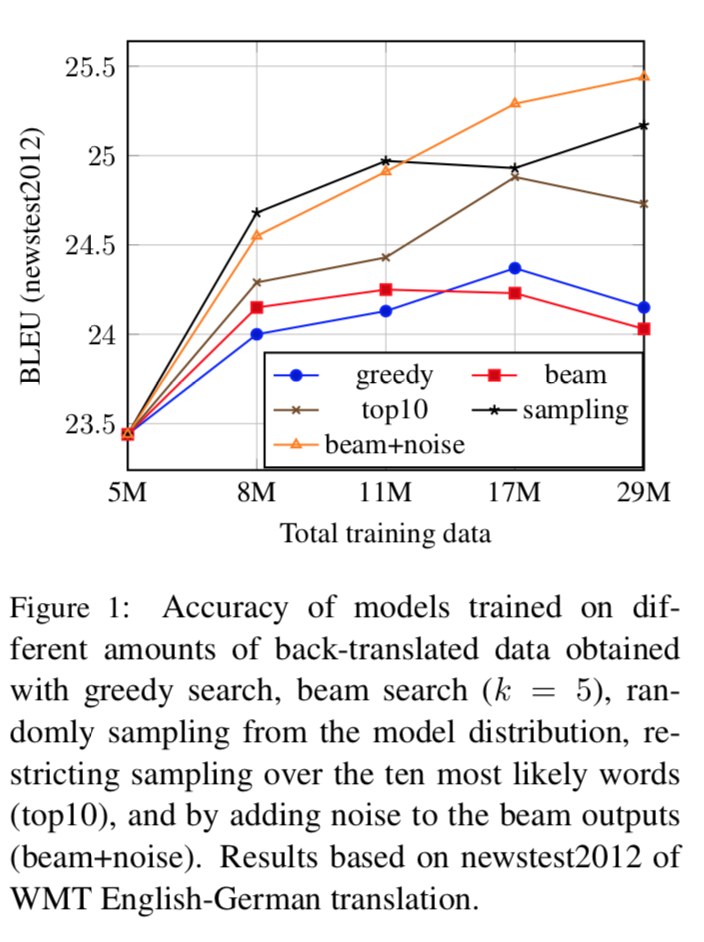
可以看出
- 反向翻译句对量增加的时候, 对最终翻译的效果有提升
- 带有噪音的采样方法效果好一些(beam+noise, sampling), 原因大致可以解释为去噪的影响, 噪声多了, 效果会好一些
注: 这是平行语料多的情况, 如果平行语料较少, 由于翻译模型的效果还不好, 得到的句对(x’, y)质量不高, 这时使用beam的方式反向翻译效果最好. 实际使用的时候, 可以结合过滤策略过滤掉一些质量不高的句对, 在保证noise较多的情况, 也保证质量不太差, 效果会更显著.