1:架构
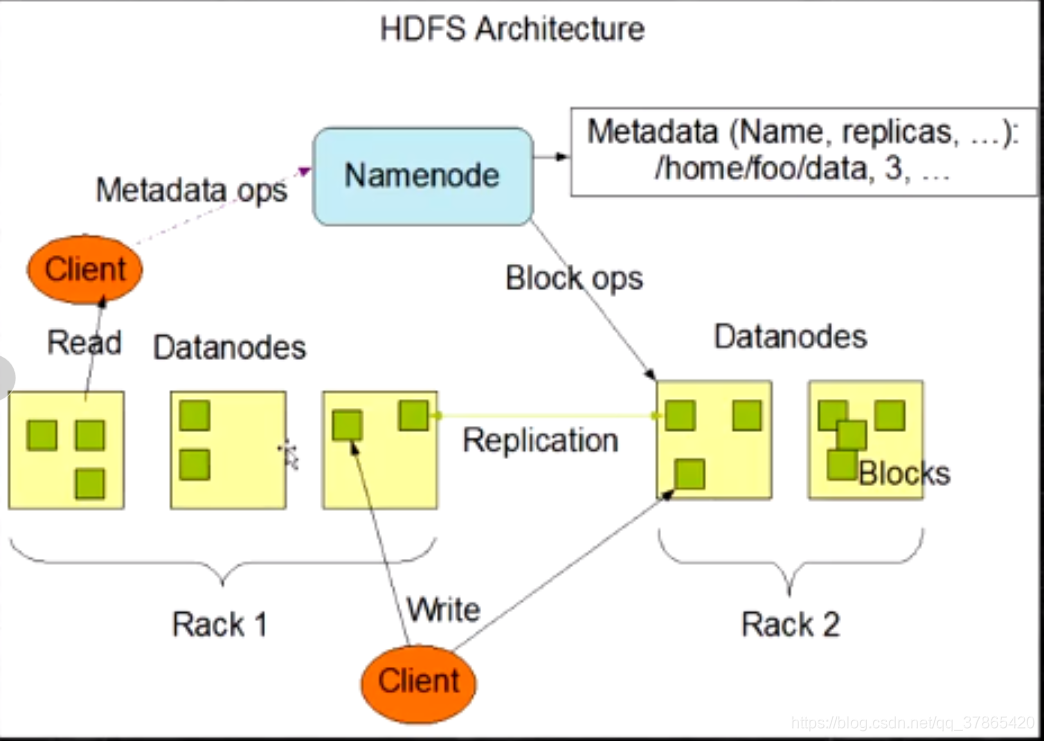
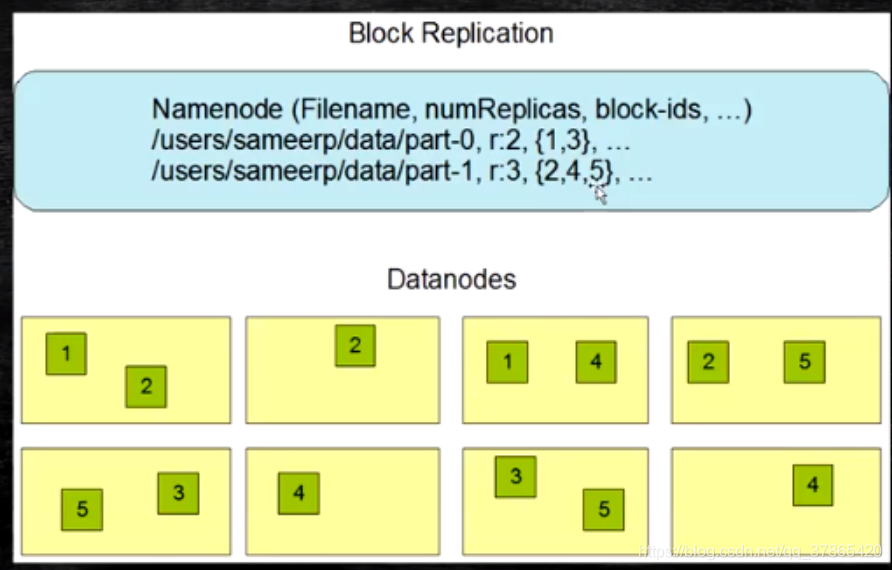
2:角色功能
2.1:Namenode
- 完全基于内存存储元数据、目录结构、文件block的映射
- 需要持久化方案来保证数据可靠性
- 提供副本放置策略
2.2:Datandode
- 基于本地磁盘存储block(文件的形式)
- 并保存block的校验和数据,保证block的可靠性
- 与NameNode保持心跳,汇报block列表状态
注意
- 一个文件上传完后块的大小不能改变,但是副本数可以改变
- 阿里的推荐:一个集群最好不要超过5k台–网络通信会不好管
- 往内存放的存储组件:hbase、namenode、elasticsearch、redis;这些都需要持久化- 方案保存数据可靠性
- hdfs并没有帮我们存数据,而是起到一个管理映射的作用
- block的校验和 是用来算文件是否完整,是否被破坏
- hashcode,md5,crc—算法都是映射算法
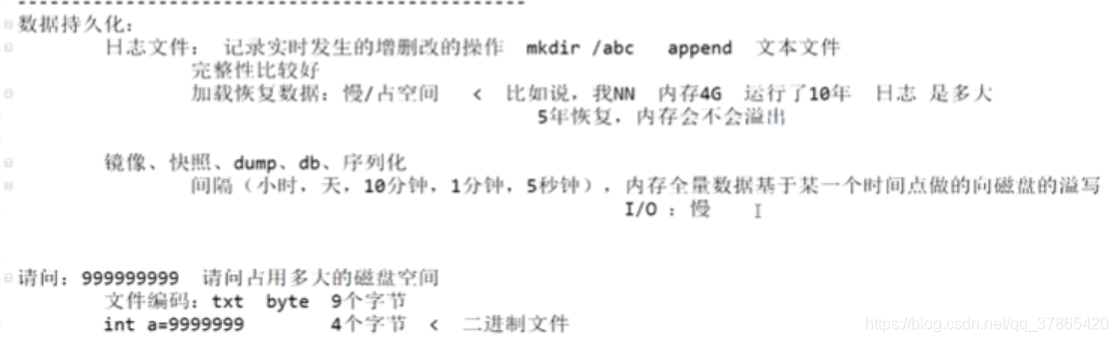
3:元数据的持久化
- 任何对HDFS元数据产生修改的操作,NameNode都会使用一种称为EditLog的事务日志记录下来
- 使用FSImage存储内存所有的元数据状态
- 使用本地磁盘保存EditLog和FSImage
- EditLog具有完整性,数据丢失少,但恢复速度慢,并有体积膨胀风险
- FSImage具有恢复速度快,体积与内存数据相当,但不能实时保存,数据丢失多
- NameNode使用了FSImage+Editlog整合的方案;
滚动的将增量的EditLog更新到FSImage,以保证更近时点的FSImage和更小的EditLog体积
如下图

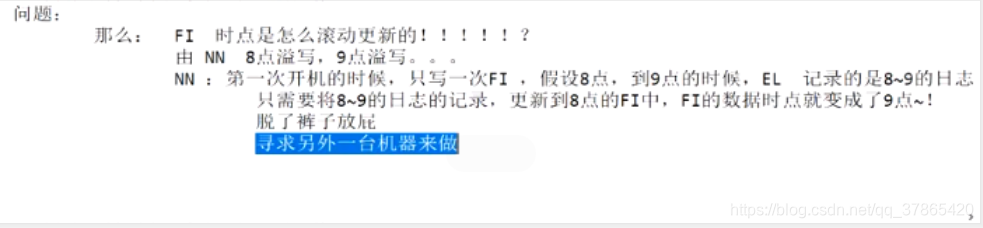
问题
那么,FSImage时点是怎么滚动更新的!?
如果由NN,8点溢写,9点溢写。。。。太耗NN的CPU/IO了
寻求办法就是找一台机子来做 -----SNN(SecondaryNameNode)
4:安全模式
NN存元数据有文件的属性、每个块存在哪个DN上
在持久化的时候,文件属性会持久化,但是文件的每一个块位置信息不会持久化 ,如果持久化了的话,下次服务重启恢复数据的时候,DN挂掉就会造成块的位置信息错误,从而丢失数据。那么应该怎么办呢?
分布式时代讲究的就是数据一致性!!
NN会等,等DN,因为DN会与他建立心跳,汇报块信息!!从而保证块位置信息等是最新的,这个等的过程NN会进入安全模式

- NN启动后会进入一个称为安全模式的特殊状态
- 处于安全模式的NN是不会进行数据块的复制的
- NN从所有DN接受心跳信号和块状态报告
- 每当NN检测确认某个block的副本数目达到这个最小值,那么该数据块就会被认为是副本安全的(safely replicated)
- 在一定百分比(参数可配置)的数据块被NN检测确认安全之后(加上一个额外的30s等待时间),NN就会退出安全模式
- 接下来NN会确定哪些数据块的副本没有达到指定数目,并将这些数据块复制到其他的DN上
5:SecondaryNameNode
- 在非HA模式下,SNN一般是独立的节点,周期完成对NN的EL向FI合并,减少EL大小,减少NN启动时间
- 根据配置文件设置的时间间隔fs.checkpoint.period默认3600秒
- 根据配置文件设置EL的大小fs.checkpoint.size,规定EL文件的最大默认值为64M
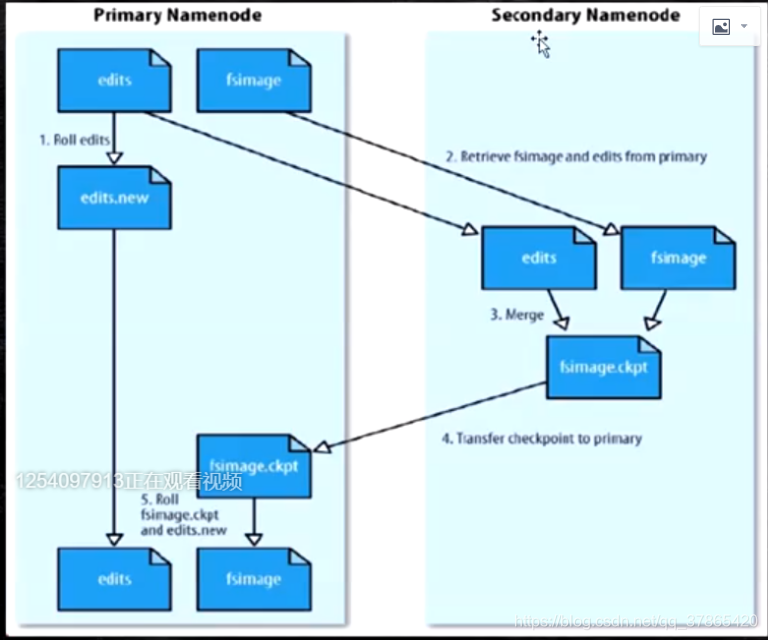
他的出现解决了3中的问题!
6:副本放置策略

Hadoop2.x中放置策略如下

- 第二个副本放在与第一个副本不同机架中的服务器上,(而Hadoop1.x中第二个副本默认放在第一个副本同机架上了,2.x为了防止副本数为2而导致副本丢失的情况,特意将第二个机架做如此调整)
- 第三个副本放在与第二个副本在一块的机架下
因为在同一个交换机中,网速快。
放在其他机架,就会有网络资源消耗
7:写流程
如下图是某一时间点,客户端在传某一文件的一个块的三个副本的时刻

- Client和NN连接创建文件元数据
- NN会判定元数据是否有效,比如文件目录是否存在等等
- NN给Client发送副本放置策略,返回一个有序的DN列表
- Client跟DN通信,建立PipeLine连接
- Client将块切分成packet(64KB),并使用chunk(512B)+chunksum(4B)填充
- Client将packet放入发送队列dataqueue中,并向第一个DN发送
- 第一个DN收到packet后本地保存并发送给第二个DN
- 第二个DN收到packet后本地保存并发送给第三个DN
- 这一过程中,上游节点同时发送下一个packet
- 生活中类比工厂的流水线,结论:流式其实也是变种的并行计算
- HDFS用这种传输方式,副本数对于Client是透明的
- 当block传输完成,DN们各自向NN汇报,同事Clietn继续传输下一个block
- 所以Client的传输和block块的汇报也是并行的
8:读流程
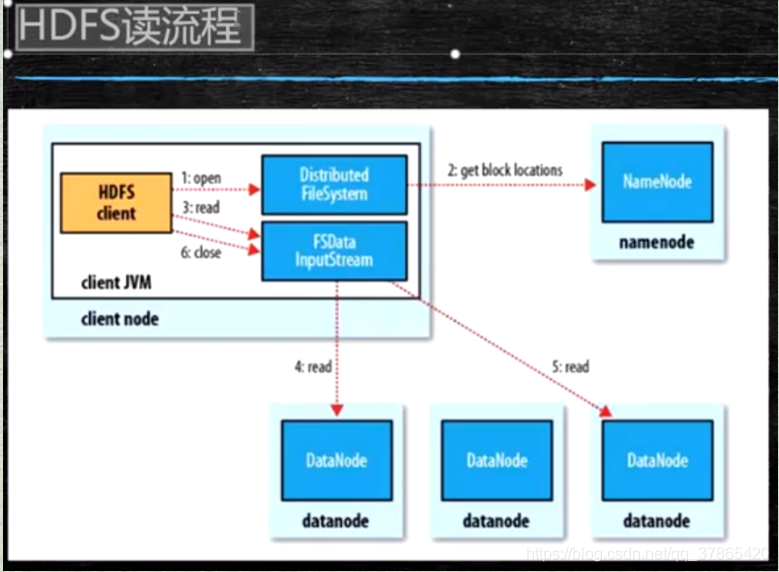
- 为了降低整体的带款消耗和读取延时,HDFS会尽量让读取程序读取离他最近的副本
- 如果在读取程序的同一个机架上有一个副本,那么就读取该副本
- 如果一个HDFS集群跨越多个数据中心,那么客户端也将首先读取本地数据中心的数据
- 语义:下载一个文件:
- Client 和NN交互文件元数据信息来获取fileBlockLocation
- NN会按距离策略排序返回
- Client尝试下载block并校验数据完整性 - 语义:下载一个文件其实是获取文件的所有block元数据,那么获取某些block也应该成立的(是子集操作)
- HDFS支持Client输出文件的offset自定义连接哪些block的DN,自定义来获取某些数据
- 这个是支持计算层的分治思想,并行计算的核心