什么是YARN?
Apache Hadoop YARN (Yet Another Resource Negotiator,另一种资源协调者)是一种新的Hadoop资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,其基本思想是将JobTracker的两个主要功能(资源管理和作业调度/监控)分离,主要方法是创建一个全局的ResourceManager(RM)和若干个针对应用程序的ApplicationMaster(AM)。ResourceManager负责整个集群的资源管理和调度。ApplicationMaster负责应用程序相关的事务,比如任务调度、任务监控和容错等。
YARN的由来
MapReduce 的第一个版本既有优点也有缺点(参考MapReduce任务调度和资源管理)。MRv1 使用标准的大数据处理系统。但是这种架构存在不足,主要表现在大型集群上。当集群包含的节点超过 4,000 个时(其中每个节点可能是多核的),就会表现出一定的不可预测性。其中一个最大的问题是级联故障,由于要尝试复制数据和重载活动的节点,所以一个故障会通过网络泛洪形式导致整个集群严重恶化。
从业界使用分布式系统的变化趋势和 hadoop 框架的长远发展来看,MapReduce的 JobTracker/TaskTracker 机制需要大规模的调整来修复它在可扩展性,内存消耗,线程模型,可靠性和性能上的缺陷。在过去的几年中,hadoop 开发团队做了一些 bug 的修复,但是这些修复的成本越来越高,这表明对原框架做出改变的难度越来越大。为从根本上解决旧MapReduce框架的性能瓶颈,促进 Hadoop 框架的更长远发展,从 0.23.0 版本开始,Hadoop 的 MapReduce 框架完全重构,发生了根本的变化。新的 Hadoop MapReduce 框架命名为 MapReduceV2 或者叫YARN。
为什么要使用YARN?
这个问题主要从两个方面来回答,一是MapReduce1.0的缺陷,二是YARN解决了MapReduce的哪些问题。
- MapReduce1.0版本的缺陷
- 单点故障:单点故障是所有主从模型都面临的问题,JobTracker只有一个,一旦挂了,那么整个计算任务就会失败。
- 压力过大:JobTracker既要进行任务调度又要进行资源管理,如果有多个
JobClient向JobTracker提交任务,那么JobTracker就会比较忙,可能导致无法及时处理那么多任务。 - 框架无法复用,资源争抢:如果要执行不同类型的计算任务,那么就得实现新的框架,新的框架必须自己重新实现资源管理和任务调度功能(重复造轮子),又因为这两套框架是隔离的,互相无法感知到,就可能造成资源争抢。
- YARN解决了MapReduce的哪些问题
- 提出了HDFS Federation,它让多个NameNode分管不同的目录进而实现访问隔离和横向扩展。对于运行中NameNode的单点故障,通过 NameNode热备方案(NameNode HA)实现。
- YARN通过将资源管理和应用程序管理两部分分剥离开,分别由
ResouceManager和ApplicationMaster负责,其中,ResouceManager专管资源管理和调度,而ApplicationMaster则负责与具体应用程序相关的任务切分、任务调度和容错等,每个应用程序对应一个ApplicationMaster。 - YARN具有向后兼容性,用户在MRv1上运行的作业,无需任何修改即可运行在YARN之上。
- 支持多个框架, YARN不再是一个单纯的计算框架,而是一个框架管理器,用户可以将各种各样的计算框架移植到YARN之上,由YARN进行统一管理和资源分配。目前可以支持多种计算框架运行在YARN上面,比如MapReduce、Storm、Spark、Flink等
- 框架升级更容易, 在YARN中,各种计算框架不再是作为一个服务部署到集群的各个节点上(比如MapReduce框架,不再需要部署JobTracler、 TaskTracker等服务),而是被封装成一个用户程序库(lib)存放在客户端,当需要对计算框架进行升级时,只需升级用户程序库即可。
YARN的基础架构和主要角色
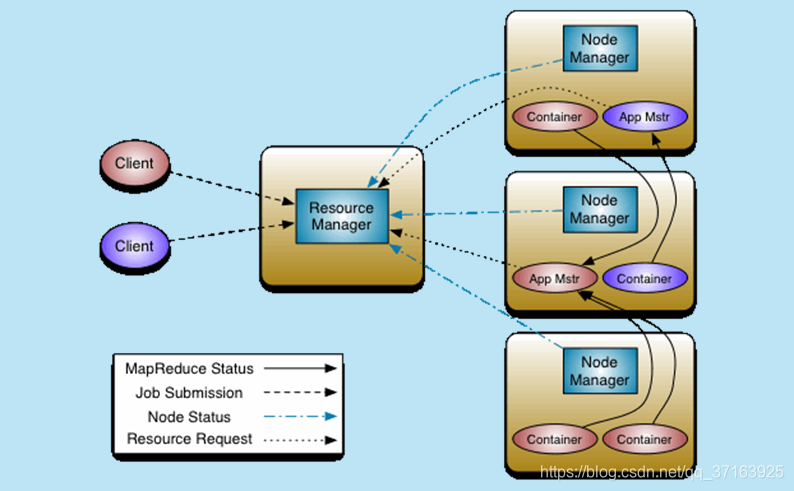
主要由ResourceManager和ApplicationMaster、NodeManager、ApplicationMaster和Container等组件组成。
ResourceManager(RM)
RM是整个集群的资源管理者,负责整个集群的资源管理和任务分配,它又由两个组件构成,分别是调度器(Scheduler)和应用程序管理器(Application Manager)。Scheduler负责将系统资源分配给各个正在运行的应用程序,它不参与任何与具体应用相关的工作,如监控应用或跟踪其执行状态,也不负责重启失败的任务,仅根据各个应用程序的资源需求进行资源分配。Application Manager负责管理整个集群中的所有应用程序,包括应用程序提交、与Scheduler协商资源以启动Application Master,监控Application Master的状态以及在任务失败时重新启动Application Master。
Application Master(AM)
用户提交的每一个应用程序都包含一个Application Master,它负责协调来自RM的资源,将得到的任务进一步分配给内部的任务(资源的二次分配),并通过 NodeManager 监视容器的执行和资源使用(CPU、内存等的资源分配),与NodeManager通信以启动或停止任务,在任务失败时负责重启任务。
注: RM只负责监控AM,在AM运行失败时候启动它,RM并不负责AM内部任务的容错,这由AM来完成。
NodeManager(NM)
NM是每个节点上的资源和任务管理器,一方面,它会定时地向RM汇报本节点上的资源使用情况和各个Container的运行状态;另一方面,它接收并处理来自AM的Container启动/停止等各种请求。
Container
Container是YARN中的资源抽象,它封装了某个节点上的多维度资源,如内存、CPU、磁盘、网络等,当AM向RM申请资源时,RM为AM返回的资源便是用Container表示。YARN会为每个任务分配一个Container,且该任务只能使用该Container中描述的资源。
MapReduce on YARN
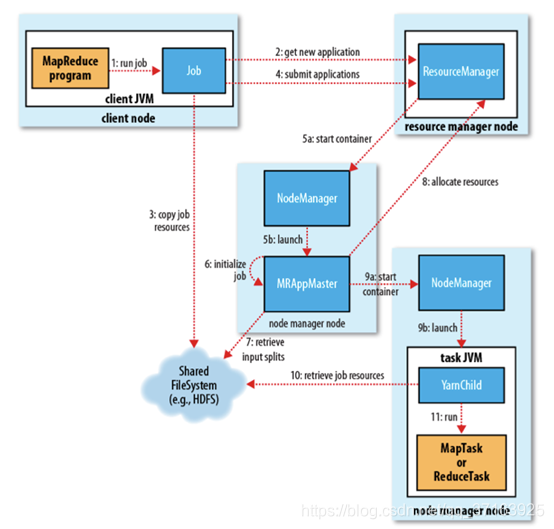
一个MapReduce作业在YARN上运行主要经历以下几个过程:
- 资源上传(作业提交)
MR-Cli向整个集群提交MapReduce作业,将切片清单、Job.xml,Job.split文件上传到HDFS,然后向RM申请一个AM。
- 作业初始化
RM接收到请求后,将请求发送给Scheduler,Scheduler选择一台不忙的节点,通知NameNode启动一个Container,并通过反射创建一个Application Master(AM)。
- 任务分配
AM启动后,从HDFS中下载切片清单,并向RM申请资源,RM会根据自己掌握的资源情况,得到一个新的任务清单,并通知NM启动Container
- 任务运行
启动的Container向AM反向注册(只有反向注册之后AM才能知道有多少资源可供自己调度),AM最终将Task发送给Container,Container通过反射相应的Task类为对象,调用方法执行任务,其业务就是我们的逻辑代码。
- 进度和状态更新
YARN中的任务将其进度和状态(包括counter)返回给AM,客户端每秒(通过mapreduce.client.progressmonitor.pollinterval设置)向AM请求进度更新,展示给用户。
- 作业完成
除了向AM请求作业进度外,客户端每5分钟都会检查作业是否完成。时间间隔可以通过mapreduce.client.completion. pollinterval来设置。作业完成之后, AM和container会清理工作状态。作业的信息会被作业历史服务器存储以备之后用户核查。
YARN高可用机制
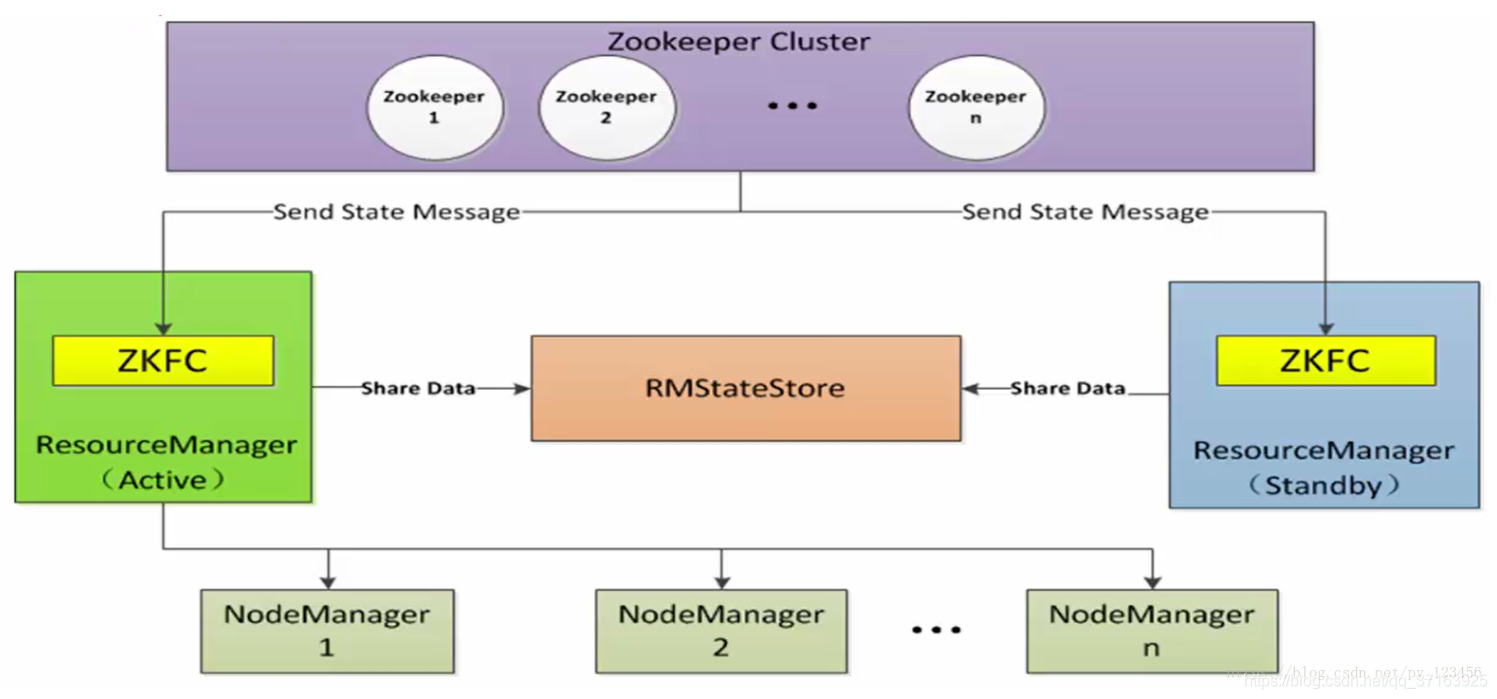
ResourceManager由一对分别处于Active和Standby状态的ResourceManager组成,它使用基于Zookeeper的选举算法来决定ResourceManager的状态。其中,ZKFC仅为ResourceManager的一个进程服务,不是单独存在的(区别于HDFS,它是独立存在的进程),负责监控ResourceManager的健康状况并定期向Zookeeper发送心跳。ResourceManager通过RMStateStore(目前有基于内存的、基于文件系统的和基于Zookeeper的等,此处使用后者)来存储内部数据、主要应用数据和标记等。
YARN容错机制
- 单点故障:每一个Application都有自己的
Application Master,一个计算程序失败不会影响到另一个计算程序(曾经的MapReduce1.0中,JobTracker挂掉,则所有的计算程序都失败),且YARN支持Application Master失败重试。 - 压力过大:YARN中每一个Application都有自己的Application Master,每个Application Master只负责自己的资源调度,减轻了压力,且每个Application Master是启动在不忙的节点上,而不是全部启动在一台节点,降低了任务执行失败的风险【从中可以看到负载均衡的思想】。
- 集成耦合度:YARN只负责资源管理,不负责具体的任务调度,只要计算框架继承了YARN的Application Master,大家都可以使用一个统一资源的视图层(即大家都能看到资源的使用情况)。
总结
MapReduce1.0版本时,JobTacke,TaskTracker都是作为常服务存在于MapReduce中,即使当前没有任务运行,JobTacke,TaskTracker也必须保持运行状态,MapReduce2.0版本时,没有了这些服务,相对的,MR的客户端服务、调度都变成了临时服务,即只有当任务提交时才会执行运行。且YARN将资源管理和任务调度分开,支持更多的资源调度和控制,为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
