MapReduce是hadoop的核心组件之一,hadoop要分布式包括两部分,一是分布式文件系统hdfs,一部是分布式计算框,就是mapreduce,缺一不可,也就是说,可以通过mapreduce很容易在hadoop平台上进行分布式的计算编程。
1:MR工作原理
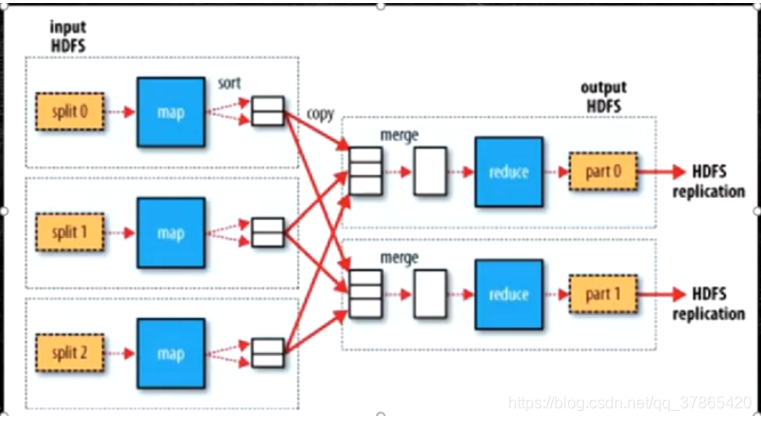

1.1:工作原理流程
流程大致如:split---->map---->分区(k,v序列化;P到环形缓冲区)---->map输出溢写---->排序(合并)---->溢写到磁盘
1.2:Split切片->Map
- 每个输入分片(input split)针对一个map任务,输入分片(input split)存储的并非数据本身,而是一个分片长度和一个记录数据的位置的数组。每个输入分片会让一个map任务来处理,默认情况下,以HDFS的一个块的大小(默认为64M)为一个分片,当然我们也可以设置块的大小(想要详细了解split切片的知识请看我的专栏 《MapReduce源码解析》 )。map输出的结果会暂且放在一个环形内存缓冲区中(该缓冲区的大小默认为100M,由io.sort.mb属性控制),当该缓冲区快要溢出时(默认为缓冲区大小的80%,由io.sort.spill.percent属性控制),会在本地文件系统中创建一个溢出文件,将该缓冲区中的数据写入这个文件,这个过程叫spill,另外的20%内存可以继续写入要写进磁盘的数据,写入磁盘和写入内存操作是互不干扰的,如果缓存区被撑满了,那么map就会阻塞写入内存的操作,让写入磁盘操作完成后再继续执行写入内存操作。
1.3:Shuffle阶段
MapReduce计算模型主要由三个阶段构成:Map、Shuffle、Reduce。
Map是映射,负责数据的过滤分类,将原始数据转化为键值对;
Reduce是合并,将具有相同key值的value进行处理后再输出新的键值对作为最终结果;
为了让Reduce可以并行处理Map的结果,必须对Map的输出进行一定的排序与分割,然后再交给对应的Reduce,这个过程就是Shuffle。
Shuffle过程包含Map Shuffle和Reduce Shuffle。
在Map端的shuffle过程就是对Map的结果进行分区、排序、分割,然后将属于同一个分区的输出合并在一起并写在磁盘上,最终得到一个分区有序的文件。
-
【Partitioner】
上面中每次spill操作也就是写入磁盘操作时候就会写一个溢出文件,也就是说在做map输出有几次spill就会产生多少个溢出文件,等map输出全部做完后,map会合并这些输出文件。这个过程里还会有一个Partitioner操作,对于这个操作很多人都很迷糊,其实Partitioner操作和map阶段的输入分片(Input split)很像,只不过分区就是对数据进行hash的过程。一个Partitioner对应一个reduce作业,如果我们mapreduce操作只有一个reduce操作,那么Partitioner就只有一个,如果我们有多个reduce操作,那么Partitioner对应的就会有多个,Partitioner因此就是reduce的输入分片,这个程序员可以编程控制,主要是根据实际key和value的值,根据实际业务类型或者为了更好的reduce负载均衡要求(避免有些reduce任务分配到大量数据,而有些reduce任务却分到很少数据,甚至没有分到数据的尴尬局面)进行,这是提高reduce效率的一个关键所在。 -
【Combiner&Sort】
当map任务输出最后一个记录时,可能会有很多的溢出文件,这时需要将这些文件合并。合并的过程中会不断地进行排序和combine操作,目的有两个:1.尽量减少每次写入磁盘的数据量;2.尽量减少下一复制阶段网络传输的数据量。最后合并成了一个已分区且已排序的文件。为了减少网络传输的数据量,这里可以将数据压缩,只要将mapred.compress.map.out设置为true就可以了。combiner阶段是程序员可以选择的,combiner其实也是一种reduce操作,因此我们看见WordCount类里是用reduce进行加载的。Combiner是一个本地化的reduce操作,它是map运算的后续操作,主要是在map计算出中间文件前做一个简单的合并重复key值的操作,例如我们对文件里的单词频率做统计,map计算时候如果碰到一个hadoop的单词就会记录为1,但是这篇文章里hadoop可能会出现n多次,那么map输出文件冗余就会很多,因此在reduce计算前对相同的key做一个合并操作,那么文件会变小,这样就提高了宽带的传输效率,毕竟hadoop计算力宽带资源往往是计算的瓶颈也是最为宝贵的资源,但是combiner操作是有风险的,使用它的原则是combiner的输入不会影响到reduce计算的最终输入,例如:如果计算只是求总数,最大值,最小值可以使用combiner,但是做平均值计算使用combiner的话,最终的reduce计算结果就会出错
-
【reduce读取】
将分区中的数据拷贝给相对应的reduce任务。那么,分区中的数据怎么知道它对应的reduce是哪个呢?我们下面会讲到Hadoop1.0中MR有两个组件JobTracker与TaskTracker。TaskTracker分布在DataNode中会执行map与reduce任务,TaskTracker与JobTracker保持通信,而JobTracker掌握着整个集群的宏观信息,它会告诉TaskTracker应该在哪里计算Reduce任务,只要reduce任务向JobTracker获取对应的map输出位置就ok了哦。
2:MR调度原理
这块稍微扯远点
首先Hadoop分为存储模型与计算模型
HDFS
- 是存储模型
他有切块(block),目的就是分布式计算 - 实现 ---->框架
其角色有 NN,DN
MapReduce
- 是计算模型
- 2个阶段:map和reduce是阻塞的关系,必须map执行完才能执行reduce
- map阶段
- 单条记录加工和处理
- reduce阶段
- 按组,多条记录加工处理
- map阶段
- 2个阶段:map和reduce是阻塞的关系,必须map执行完才能执行reduce
- 实现:----->框架
- 计算向数据移动:
- hdfs暴露数据的位置
- 1)资源管理
- 2)任务调度
- 角色进程
- JobTracker工作内容
- 1.资源管理
- 2.任务调度
- TaskTracker工作内容
- 任务管理
- 资源汇报
- client工作内容
- 1.会根据每次的计算数据,咨询NameNode元数据(block)算出split大小,得到一个切片清单。
这样map的数量就有了
split是逻辑的,block是物理的,block身上有(偏移量offset,副本所在机器locations),split和block是有映射关系(默认的关系是1:1)
客户端通过NN算出的split清单可得到一个结果就是:split包含偏移量(offset),以及split对应的map任务应该移动到哪些节点(从block的locations获取)
split例如:split01 A 0 500 n1 n3 n5
表示有一个A文件的一个块对应偏移量0~500的切片是split01,这个块位置在n1,n3,n5三个节点上
这样子就支持计算向数据移动了 - 2.生成计算程序未来运行时相关【配置文件】:--------> xml
- 3.未来移动应该相对可靠
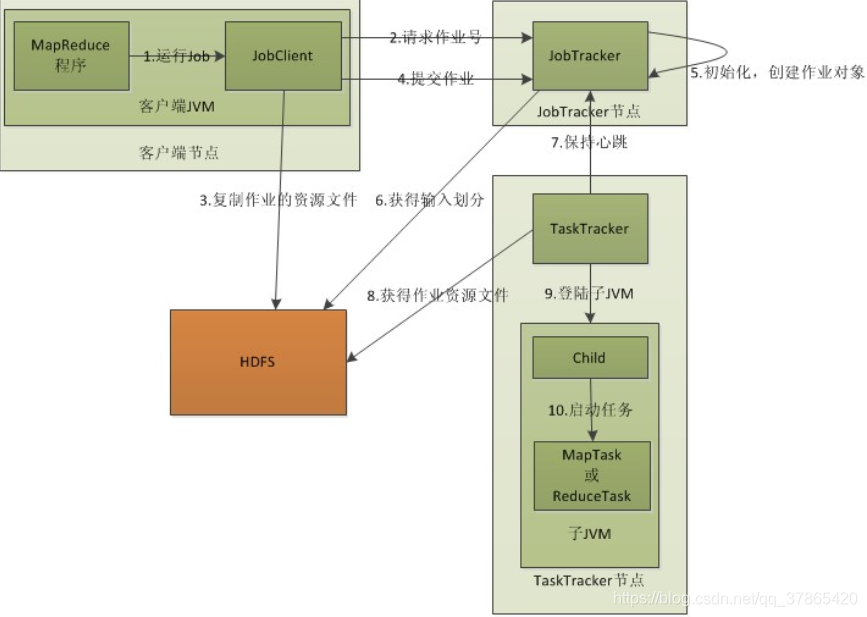
- client会将jar,split清单,配置xml 上传到hdfs的目录中(上传的数据,副本数10) - 4.client会调用JobTracker,通知要启动一个计算程序了,并且告知文件都放在了hdfs的那些地方
- JobTracker收到启动程序后:
- 1.从HDFS中取回【split清单】
- 2.根据自己收到的TaskTracker汇报的资源,最终确定每一个split对应的map应该去哪一个节点执行【确定清单】
- 3.未来,TaskTracker再心跳的时候就会取回分配给自己的任务信息~!
- TaskTracker
- 1.在心跳取回任务后
- 2.从hdfs中下载jar,xml等文件,取回TT所在本机
- 3.最终启动任务描述中的MapTask、ReduceTask(最终,代码在某个节点被启动,是通过,client上传,TaskTracker下载这样的方式,也是计算向数据移动的一个体现)
- 1.会根据每次的计算数据,咨询NameNode元数据(block)算出split大小,得到一个切片清单。
- JobTracker工作内容
- 计算向数据移动:
但是
这里有JobTracker的三个问题:
- 单点故障
- 压力过大(多客户端调用忙不过来)
- 继承了【资源管理和任务调度】,两者过于紧密,耦合度高。这样的弊端就是,未来的新计算框架不能复用资源管理
多计算程序因为各自实现资源管理,但是他们部署在同一批硬件上,因为隔离,所以不能感知对方的使用,所以,会产生资源的争抢
这些问题在Hadoop2.0中解决了,一个新的名为Yarn的资源调度框架解决了这些问题