前言:中秋节有事外加休息了一天,今天晚上重新拾起Hadoop,但感觉自己有点烦躁,不知后续怎么选择学习Hadoop的方法。
干脆打开电脑,决定:
1、先将Hadoop的MapReduce和Yarn基本原理打扎实了再说,网上说的边画图边记得效果好点;
2、有时间就多看看Java和Python的基础知识,牢固牢固;
3、开始学习hive以及spark
正文:
MapReduce如何分而治之?
Map阶段:
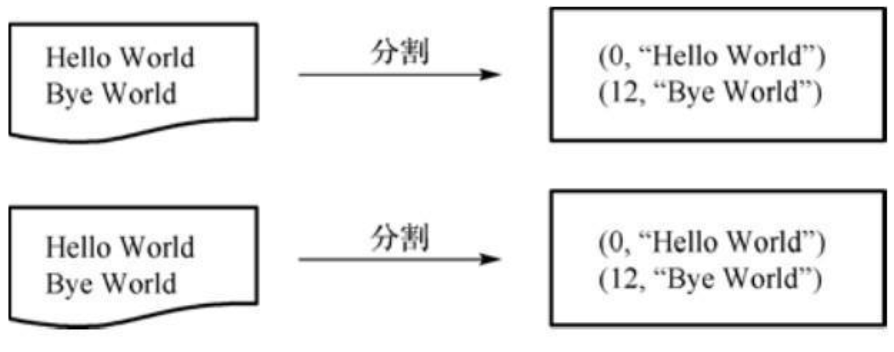
a.拆分输入数据(Split):逐行读取数据,得到一系列(key/value)
注:Split个数根据文件多少来分配,key值包括回车符
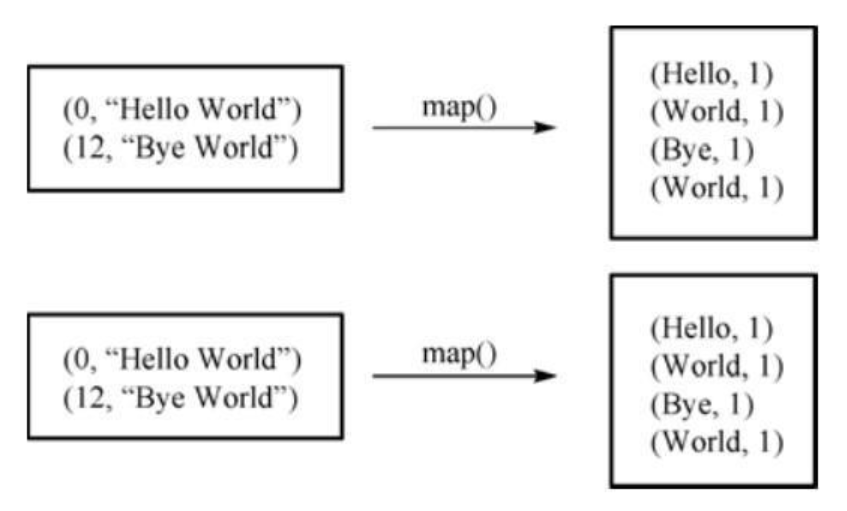
b.执行用户自定义的Map方法
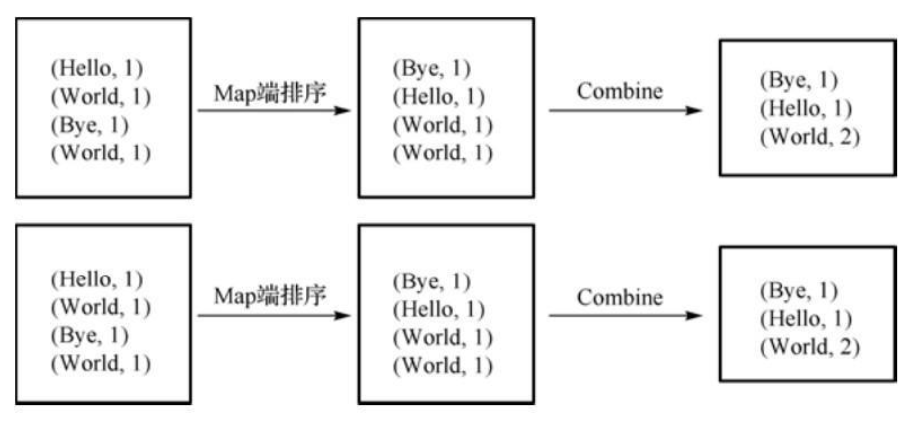
c.Mapper按输出的key值对输出的(key,value)进行排序,并执行combine过程,将key值相同的value累加
注1:combine不能取代reduce,但combine可以减少map和reduce之间数据传输量
注2:在map和cobine之间还有两个过程:collect和spill
collect:是map方法处理完数据后,一般调用OutputCollector。collect()收集结果,并在该内部形成(key/value)分片,并写入一个环形缓冲区
spill:当环形缓冲区填满后,MapReduce会将数据写入本地磁盘,生成临时文件
Reduce阶段:
对Map阶段输出的值进行自定义的reduce函数处理,并输出新的(key/value),并作为结果输出。
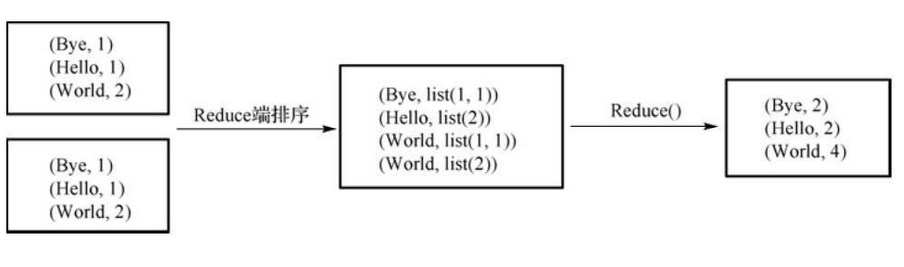
Reduce阶段分5个步骤:shuffle(复制)——merge(合并)——sort(排序)——reduce(执行函数)——write(写入结果)