4、Lenet框架(最简单的卷积神经网络)数字分类网络

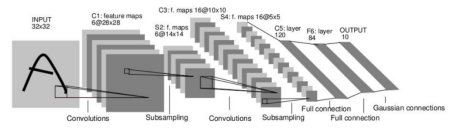
a、名词
①、comvolutions:卷积层
②、subsamping:池化层
③、full connection:全连接层
b、一个完整的CNN
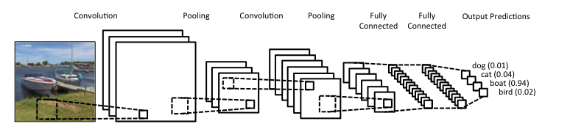

卷积层和池化层负责特征提取。
全连接层负责预测,产生一个概率。如果是单分类问题,全连接层的概率相加为1。
当该图作为输入的时候,网络正确的给船的分类赋予了最高的概率(0.94)。输出层的各个概率相加应为1。
卷积神经网络主要执行了四个操作:
①、卷积
②、激活函数(ReLU)
③、池化或下采样
④、分类(全连接层)
5、输入层:
a、图片在计算机中一般以三组二维矩阵的形式进行存储。三个矩阵分别表示R、G、B值,每个图片都可以表示为像素值组成的矩阵。
b、通道:图片的特定成分。数码相机照片有三个通道——RGB,可以想象为是三个2d矩阵叠在一起,每个矩阵的值都在0-255之间。
c、灰度图像只有单通道。矩阵中的每个像素值还是0到255,0表示白,255表示黑。
d、数据必须转为数字的形式,不能以字符的形式
6、卷积层:
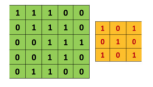
a、filter:卷积核,或者说滤波器,其值是通过网络训练得到的。初始值是随机产生的,但是会通过学习进行一个参数的调整。
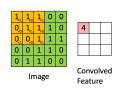
b、卷积操作:在原始图片(绿色)上从左往右、从上往下按照一定步数滑动橙色矩阵,并且在每个位置上,我们都对两个矩阵的对应元素相乘后求和得到一个整数,这就是输出矩阵(粉色)的元素。注意,3x3矩阵每次只“看见”输入图片的一部分,即局部感受野。
c、Convolved Feature:特征矩阵,在原图上滑动滤波器、点乘矩阵所得的矩阵称为“卷积特征”、“激励映射”或“特征映射”。是原始输入经过卷积核经过卷积操作之后产生的一个特征矩阵。

d、深度(Depth):深度就是卷积操作中用到的滤波器个数。这里对图片用了两个不同的滤波器,从而产生了两个特征映射。你可以认为这两个特征映射也是堆叠的2d矩阵,所以这里特征映射的“深度”就是2。有多少深度,就会产生多少个输出。
e、由于最终得到的特征需要扁平化,而且单维度不能够表达图片信息,所以一般来讲会把R、G、B三个通道的值相加。
f、步幅(Stride):步幅是每次滑过的像素数。当Stride=2的时候每次就会滑过2个像素。步幅越大,特征映射越小。
g、补零(Zero-padding):边缘补零,对图像矩阵的边缘像素也施加滤波器。补零的好处是让我们可以控制特征映射的尺寸。补零也叫宽卷积,不补零就叫窄卷积。
h、权值共享:所有的像素点共享过滤器的权值,极大地减少了网络中的参数数量。
i、局部感知:一个像素点不能表达信息,像素点与像素点之间是有关系的。通过卷积核,可以一次性采取多个像素,共同提取特征。可以更好地提取特征。
7、激活函数:
a、若不用激励函数(即f(x) = x),则每一层节点的输入都是上层输出的线性函数。无论神经网络有多少层,输出都是输入的线性组合,这种情况就是最原始的感知机了,那么网络的逼近能力就相当有限。因此我们引入非线性函数作为激励函数,这样深层神经网络表达能力就更加强大(不再是输入的线性组合,而是几乎可以逼近任意函数)。
b、常见的激活函数有:
①、Sigmoid
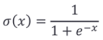
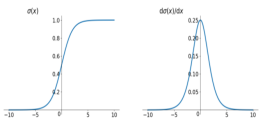 左侧分布图,右侧为导数图
左侧分布图,右侧为导数图
它能够把输入的连续实值变换为0和1之间的输出。
但是存在梯度消失问题,在-5到5之间的时候梯度是急剧变化的,但之外的情况梯度基本为0。
输出非zero-centered,是以0.5为中心而不是以0为中心的函数。
其解析式中含有幂运算,计算机求解时相对来讲比较耗时。对于规模比较大的深度网络,这会较大地增加训练时间。
最好不要在中间层使用,一般在最后一层使用,用的越少越好。
②、tanh
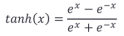
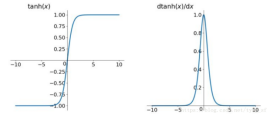
tanh解决了Sigmoid函数的不是zero-centered输出问题,然而,梯度消失问题和幂运算问题仍然存在。
③、relu
在CNN网络中用的非常多
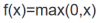

解决了梯度消失问题 (在正区间)。
计算速度非常快,只需要判断输入是否大于0。
收敛速度远快于sigmoid和tanh
ReLU的输出不是zero-centered
Dead ReLU Problem,指的是某些神经元可能永远不会被激活,导致相应的参数永远不能被更新。当某些神经元的输出值为负值的时候,这些神经元就不会被激活。
他有很多变种:
Leaky ReLU
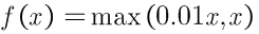
理论上来说,Leaky ReLU拥有ReLU的所有优点,外加不会有Dead ReLU problem,但是在实际操作中,并没有完全证明Leaky ReLU总是好于ReLU。
有些研究者的论文指出这个激活函数表现很不错,但是其效果并不是很稳定。
Parametric ReLU
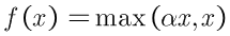
PReLU是ReLU和LReLU的改进版本,具有非饱和性。
与LReLU相比,PReLU中的负半轴斜率a由back propagation学习而非固定。原文献建议初始化a为0.25。
Randomized Leaky ReLU
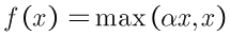
数学形式与PReLU类似,但RReLU是一种非确定性激活函数,其参数是随机的。这种随机性类似于一种噪声,能够在一定程度上起到正则效果。
8、池化层:
a、空间池化,也叫亚采样或下采样,降低了每个特征映射的维度,但是保留了最重要的信息。实际上就是降低纬度。
b、空间池化可以有很多种形式:最大(Max),平均(Average),求和(Sum)等等。最大池化成效最好。选择最大值、平均值、和等等
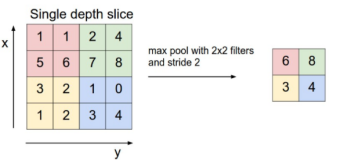
c、池化层的功能
①、减少网络中的参数计算数量,从而遏制过拟合
②、增强网络对输入图像中的小变形、扭曲、平移的鲁棒性(输入里的微小扭曲不会改变池化输出——因为我们在局部邻域已经取了最大值/平均值)。
③、帮助我们获得不因尺寸而改变的等效图片表征。这非常有用,因为这样我们就可以探测到图片里的物体,不论那个物体在哪。
可能会降低清晰度,但可以在降低图片维度的情况下保留信息。
9、全连接层:
a、使用softmax激励函数作为输出层的多层感知机。与sigmoid相似。
b、卷积层和池化层得到的数据一般是二维特征,无法直接给全连接层,需要将二维矩阵通过拼接转换成一维向量形式。然后再给全连接层进行分类。
c、全连接表示上一层的每一个神经元,都和下一层的每一个神经元是相互连接的。
d、卷积层和池化层的输出代表了输入图像的高级特征,全连接层的目的就是类别基于训练集用这些特征进行分类。
e、除了分类以外,加入全连接层也是学习特征之间非线性组合的有效办法。
f、一般来讲只有2-3层,以免时间过长
机器智能-高频问题:Lenet框架&卷积神经网络概念
猜你喜欢
转载自blog.csdn.net/qq_40851744/article/details/106604864
今日推荐
周排行