方法一:python-docx模块
使用python-docx模块,通过其中的Document函数可以读取word文档,然后可以借助document对象的相关属性、方法来获取文档中想要的信息或者编辑文档。
‘add_heading’,
‘add_page_break’,
‘add_paragraph’,
‘add_picture’,
‘add_section’,
‘add_table’,
‘core_properties’,
‘element’,
‘inline_shapes’,
‘paragraphs’,
‘part’,
‘save’,
‘sections’,
‘settings’,
‘styles’,
‘tables’
简单示例
from docx import Document
input_document = Document(filename) #读取word文件
tables = input_document.tables # 获取文件中的所有表格
读取文件时可能存在的错误
错误信息
KeyError: “There is no item named ‘word/NULL’ in the archive”
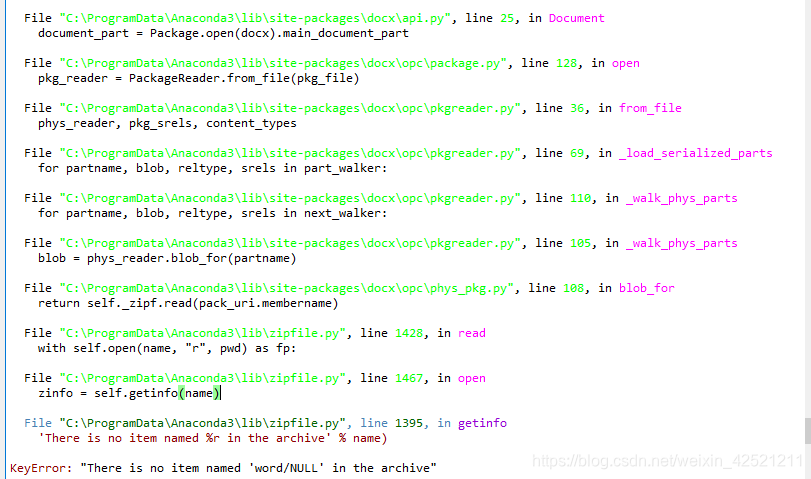
对于上述错误信息,今天又查找了下错误原因和解决方式,突然发现网上几乎没有人搜索这个报错信息,今天看到一条信息是关于word文档的简述:
大约在2008年以前,Office产品中Word用.doc文件格式,这种二进制格式很难与其他软件兼容。
为了跟上时代,微软采用类XML格式标准定义其新版Word文件.docx。
.docx实际上是一个zip的压缩文件
方法二:解压-解析的方式
根据对上述word的简述, 根据word(.docx)文件的格式,因此我们可以通过遵循如下步骤进行正文信息的提取:
- 解压.docx文件
- 用BeautifulSoup解析word/document.xml提取正文信息
代码示例如下:
from zipfile import ZipFile
from bs4 import BeautifulSoup
document=ZipFile(r'test.docx')
xml=document.read("word/document.xml")
wordObj=BeautifulSoup(xml.decode("utf-8"))
texts=wordObj.findAll("w:t")
for text in texts:
print(text.text)
后记
还有什么新的方法,评论区欢迎探讨互动学习。