xml解析
切入主题之前我来回答一下为什么要解析xml?
1.可以在不同应用程序之间的通信。
2.可以在不同平台之间的通信。
3.可以在不同平台之间的数据共享。
xml的作用是什么?
“XML是被设计用来存储数据、携带数据和交换数据的,通过XML,可以在不兼容的系统之间交换数据,利用XML, 纯文本文件可以用来存储数据。在不使用XML时,HTML用于显示数据,数据必须存储在HTML文件之内。XML不是为了显示数据而设计的,主要是用于交换数据,可以从HTML中分离数据,也可以用于存储”
三种配置
*.properties (用于连接数据库)
*.xml
*.ini (也是一个配置文件 装mysql的时候见过)
做数据交换
xml
webservice(远程调用)
json :跨语言,用的多 其原因是因为json比xml代码量少xml是用标签去包的 但是做配置的话基本还是xml。
Java中配置文件的三种配置位置及读取方式
2.1 XML和*.properties(属性文件)/ini
2.2 存放位置
2.2.1 src根目录下
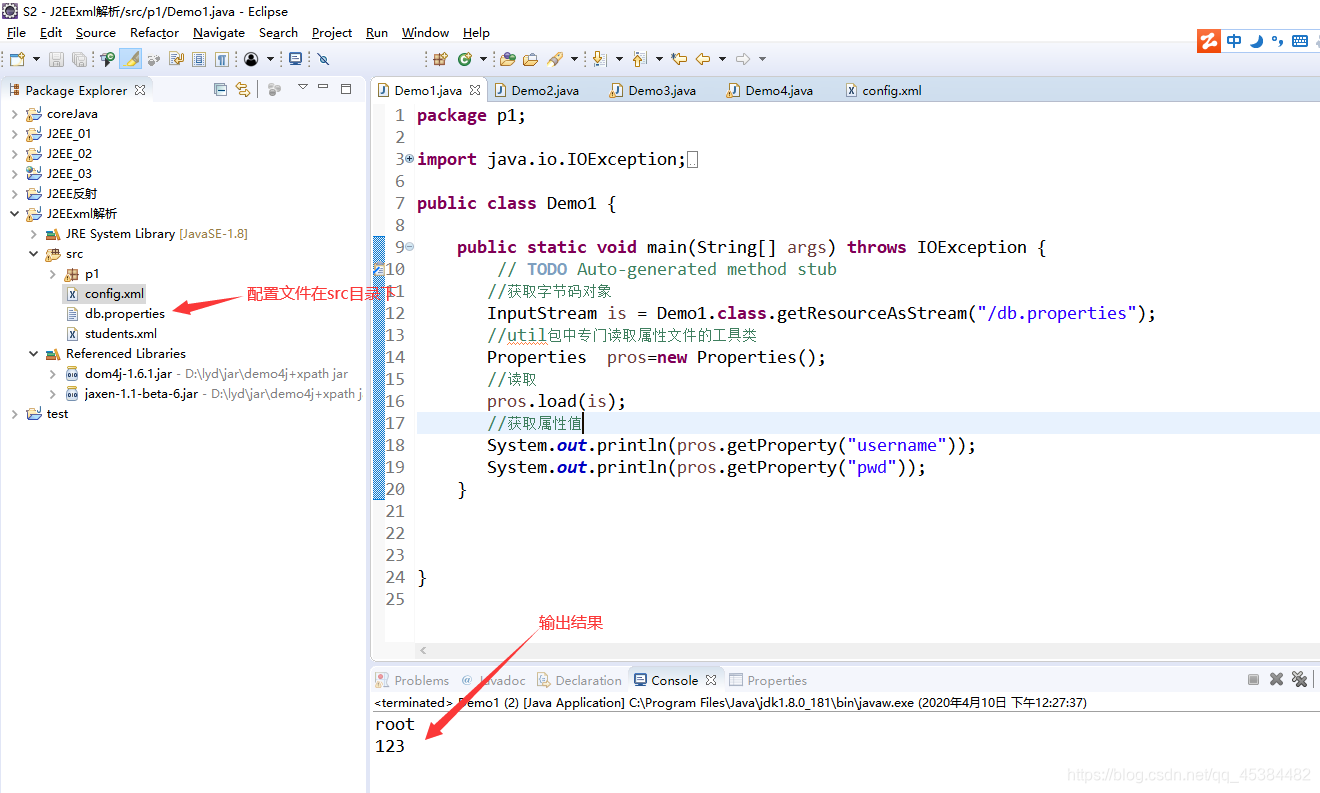
Xxx.class.getResourceAsStream("/config.properties");
2.2.2 与读取配置文件的类在同一包
Xxx.class.getResourceAsStream(“config2.properties”);
2.2.3 WEB-INF(或其子目录下)
ServletContext application = this.getServletContext();
InputStream is =
application.getResourceAsStream("/WEB-INF/config3.properties");
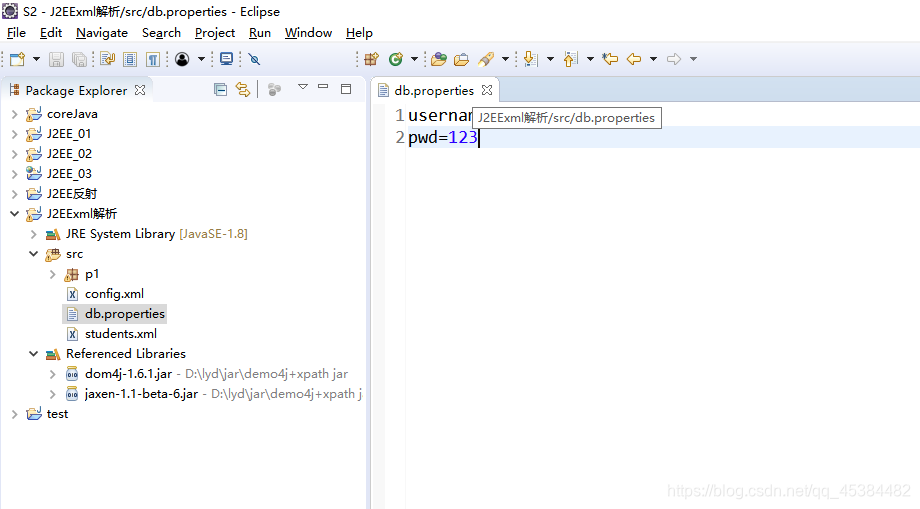
注1:*.properties文件
key=value
#注释
Properties pros = new Properties();//util包中专门读取属性文件的工具类
pros.load(is);
**举例:
接下来我们将用 dom4j+xpath解析xml文件
注:解析前一定要导入这两个jar
什么是demo4j?
“dom4j是一个Java的XML API,是jdom的升级品,用来读写XML文件的。dom4j是一个十分优秀的JavaXML API,具有性能优异、功能强大和极其易使用的特点,它的性能超过sun公司官方的dom技术,同时它也是一个开放源代码的软件,可以在SourceForge上找到它。在IBM developerWorks上面还可以找到一篇文章,对主流的Java XML API进行的性能、功能和易用性的评测,所以可以知道dom4j无论在哪个方面都是非常出色的。如今可以看到越来越多的Java软件都在使用dom4j来读写XML,特别值得一提的是连Sun的JAXM也在用dom4j。这已经是必须使用的jar包, Hibernate也用它来读写配置文件。”
什么是xpath?
“XPath即为XML路径语言,它是一种用来确定XML(标准通用标记语言的子集)文档中某部分位置的语言。XPath基于XML的树状结构,提供在数据结构树中找寻节点的能力。起初 XPath 的提出的初衷是将其作为一个通用的、介于XPointer与XSL间的语法模型。
语法:
xpath等同数据库的select语句
document.selectNodes(xpath);//查一组
document.selectSingleNode(xpath);//查单个
DOM由节点组成
Node
元素节点
属性节点
文本节点
xpath
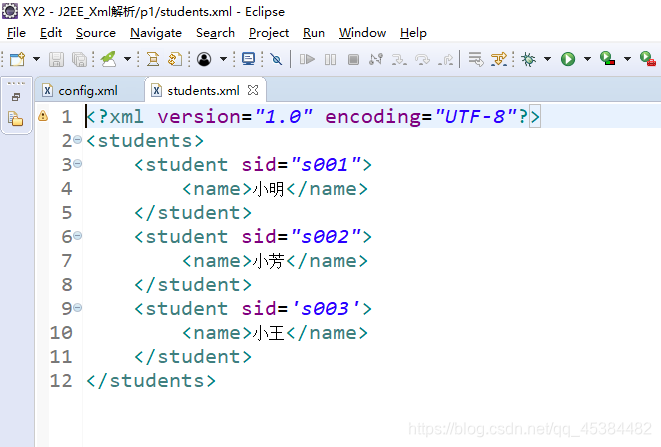
/ 定位路径 在系统中建一个文件叫document/students/student/sid|name
@ 属性 /students/student[@sid=‘s003’]
查询一组:
public class Demo3 {
public static void main(String[] args) throws DocumentException {
// TODO Auto-generated method stub
//dome4j解析xml
InputStream is = Demo3.class.getResourceAsStream("/students.xml");
SAXReader sax=new SAXReader();
Document document = sax.read(is);//得到文档对象
String xpath="/students/student";
//得到一组元素节点
List<Element> studentElements = document.selectNodes(xpath);
//遍历一组元素节点
for (Element student : studentElements) {
//根据属性名获取值
String sid = student.attributeValue("sid");
System.out.println(sid);
//获取name的文本值 得到节点 强转为元素
Element nameElement = (Element)student.selectSingleNode("name");
//通过获取文本拿到值
String name = nameElement.getText();
System.out.println(name);
}
}
}
输出结果:
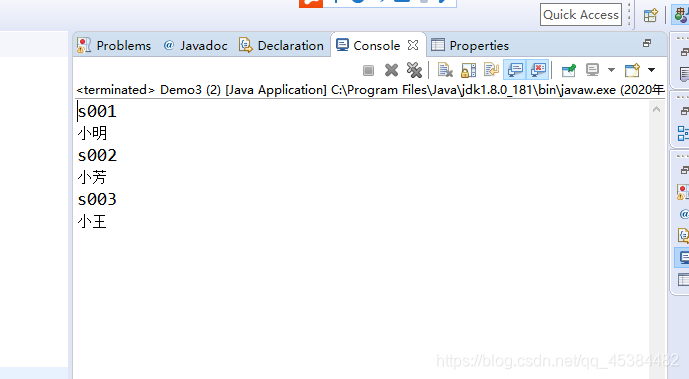
查询单个:
public class Demo4 {
public static void main(String[] args) throws DocumentException {
// TODO Auto-generated method stub
//查一个
//获取字节码对象 读取xml
InputStream is = Demo3.class.getResourceAsStream("/students.xml");
SAXReader sax=new SAXReader();
Document document = sax.read(is);//得到文档对象
//xpath定位
String xpath="/students/student[@sid='s001']";
Element studentsElement =(Element)document.selectSingleNode(xpath);
Element nameElement =(Element)studentsElement.selectSingleNode("name");
String name = nameElement.getText();
System.out.println("name:"+name);
}
}
输出结果:
