Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例
14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性
15、Flink 的table api与sql之流式概念-详解的介绍了动态表、时间属性配置(如何处理更新结果)、时态表、流上的join、流上的确定性以及查询配置
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及FileSystem示例(1)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Elasticsearch示例(2)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Apache Kafka示例(3)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及JDBC示例(4)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Apache Hive示例(6)
20、Flink SQL之SQL Client: 不用编写代码就可以尝试 Flink SQL,可以直接提交 SQL 任务到集群上
22、Flink 的table api与sql之创建表的DDL
24、Flink 的table api与sql之Catalogs
30、Flink SQL之SQL 客户端(通过kafka和filesystem的例子介绍了配置文件使用-表、视图等)
41、Flink之Hive 方言介绍及详细示例
42、Flink 的table api与sql之Hive Catalog
43、Flink之Hive 读写及详细验证示例
本文详细的介绍了Flink 与hive的集成、通过flink sql读写hive数据。
本文依赖有hadoop、hive、kafka、flink等所有环境可用。
本分分为4个部分,即读取hive数据、时态表的应用、写入hive中数据和文件格式。
本示例中hive的版本是3.1.2
flink的验证版本是1.13.6
hadoop的版本是3.1.4
kafka的版本是2.12-3.0.0
一、Hive的读写介绍
Apache Flink 可通过 HiveCatalog对 Apache Hive 表的统一 BATCH 和 STREAM 处理。这意味着 Flink 可以用作 Hive 批处理引擎的高性能替代方案,或者连续地将数据写入和读出 Hive 表,以支持实时数据仓库应用程序。
1、读hive数据
Flink 支持在 BATCH 和 STREAMING 模式下从 Hive 读取数据。当作为 BATCH 应用程序运行时,Flink 会在执行查询的时间点对表的状态执行查询。流式读取将持续监视表,并在新数据可用时以增量方式获取新数据。Flink 将默认读取有界的表。

流式处理读取支持同时使用分区表和非分区表。对于分区表,Flink 会监控新分区的生成,并在可用时增量读取它们。对于非分区表,Flink 会监控文件夹中新文件的生成,并增量读取新文件。
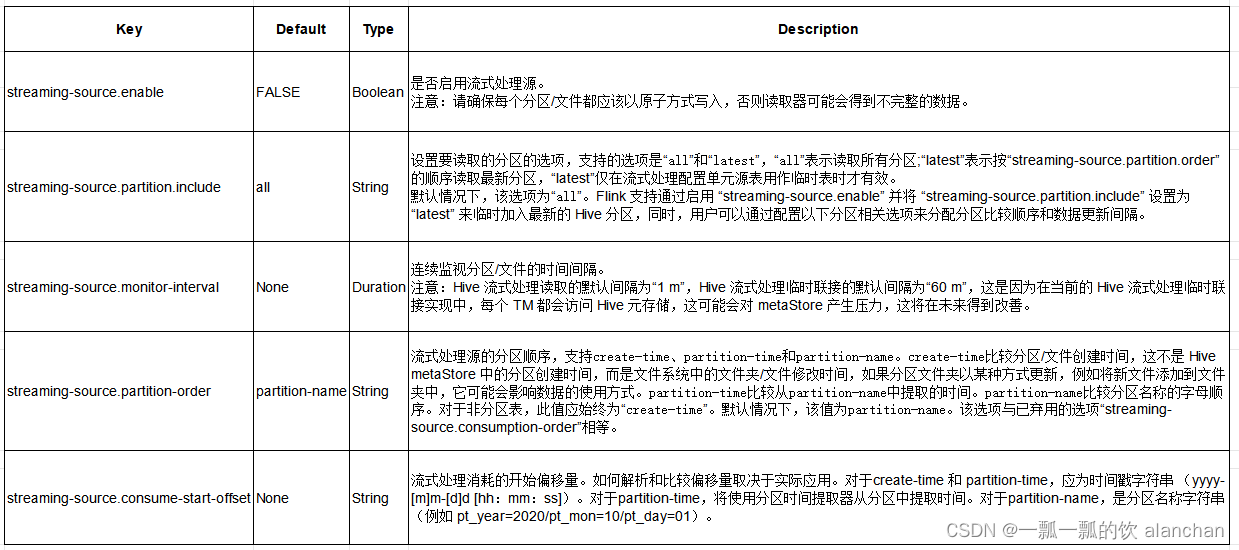
SQL Hints可用于将配置应用于 Hive 表,而无需更改其在 Hive 元存储中的定义。
示例如下:
SELECT *
FROM hive_table
/*+ OPTIONS('streaming-source.enable'='true', 'streaming-source.consume-start-offset'='2023-08-20') */;
注意:
- 监控策略是扫描当前位置路径中的所有目录/文件。许多分区可能会导致性能下降。
- 非分区表的流式读取要求以原子方式将每个文件写入目标目录。
- 分区表的流式读取要求在 Hive 元存储视图中以原子方式添加每个分区。否则,将使用添加到现有分区的新数据。
- 流式读取不支持 Flink DDL 中的水印语法。这些表不能用于窗口运算符。
1)、读取hive的视图
Flink 能够从 Hive 定义的视图中读取数据,但存在一些限制:
- 当前的catalog必须被设置为hivecatalog,设置方式有两种,即 TableAPI:tenv.useCatalog(“alan_hivecatalog”) 和SQLcli:use catalog alan_hivecatalog
- Hive 和 Flink SQL 有不同的语法,例如不同的保留关键字和文字。确保视图的查询与 Flink 语法兼容。
2)、读取时矢量化优化(Vectorized Optimization upon Read)
当满足以下条件时,Flink 将自动使用 Hive 表的矢量化读取:
- 数据格式是ORC或parquet时
- 字段没有复杂数据类型时,如List、Map、Struct和Union
默认情况下启用此功能。可以使用以下配置禁用它。
table.exec.hive.fallback-mapred-reader=true
3)、Source 并发推理(Source Parallelism Inference)
默认情况下,Flink 会根据文件数量和每个文件中的块数来推断其 Hive 读取器的最佳并行性。
Flink 允许您灵活配置并行推理的策略。您可以在 TableConfig 中配置以下参数(请注意,这些参数会影响作业的所有源):

4)、读 Hive 表时调整数据分片(Split) 大小
读 Hive 表时, 数据文件将会被切分为若干个分片(split), 每一个分片是要读取的数据的一部分。 分片是 Flink 进行任务分配和数据并行读取的基本粒度。 用户可以通过下面的参数来调整每个分片的大小来做一定的读性能调优。

为了调整数据分片的大小, Flink 首先将计算得到所有分区下的所有文件的大小。 但是这在分区数量很多的情况下会比较耗时,你可以配置作业参数 table.exec.hive.calculate-partition-size.thread-num(默认为3)为一个更大的值使用更多的线程来进行加速。
目前上述参数仅适用于 ORC 格式的 Hive 表。
5)、加载分区切片
Flink 使用多个线程并发将 Hive 分区切分成多个 split 进行读取。你可以使用 table.exec.hive.load-partition-splits.thread-num 去配置线程数。默认值是3,你配置的值应该大于0。
6)、读取带有子目录的分区
在某些情况下,或许会创建一个引用其他表的外部表,但是该表的分区列是另一张表分区字段的子集。 比如,你创建了一个分区表 fact_tz,分区字段是 day 和 hour:
CREATE TABLE fact_tz(x int) PARTITIONED BY (day STRING, hour STRING);
然后你基于 fact_tz 表创建了一个外部表 fact_daily,并使用了一个粗粒度的分区字段 day:
CREATE EXTERNAL TABLE fact_daily(x int) PARTITIONED BY (ds STRING) LOCATION '/user/hive/warehouse/test.db/fact_tz';
当读取外部表 fact_daily 时,该表的分区目录下存在子目录(hour=1 到 hour=24)。
默认情况下,可以将带有子目录的分区添加到外部表中。Flink SQL 会递归扫描所有的子目录,并获取所有子目录中数据。
ALTER TABLE fact_daily ADD PARTITION (ds='2023-08-11') location '/user/hive/warehouse/test.db/fact_tz/ds=2023-08-11';
你可以设置作业属性 table.exec.hive.read-partition-with-subdirectory.enabled (默认为 true) 为 false 以禁止 Flink 读取子目录。 如果你设置成 false 并且分区目录下不包含任何子目录,Flink 会抛出 java.io.IOException: Not a file: /path/to/data/* 异常。
2、时态表 Join
你可以使用 Hive 表作为时态表,然后一个数据流就可以使用 temporal join 关联 Hive 表。 请参照 temporal join 获取更多关于 temporal join 的信息。
Flink 支持 processing-time temporal join Hive 表,processing-time temporal join 总是关联最新版本的时态表。 Flink 支持 temporal join Hive 的分区表和非分区表,对于分区表,Flink 支持自动跟踪 Hive 表的最新分区。
注意: Flink 还不支持 event-time temporal join Hive 表。
1)、Temporal Join 最新的分区
对于随时变化的分区表,我们可以把它看作是一个无界流进行读取,如果每个分区包含完整数据,则分区可以作为时态表的一个版本,时态表的版本保存分区的数据。
Flink 支持在使用 processing time temporal join 时自动追踪最新的分区(版本),通过 streaming-source.partition-order 定义最新的分区(版本)。 用户最常使用的案例就是在 Flink 流作业中使用 Hive 表作为维度表。
注意: 该特性仅支持 Flink 流模式。
下面的案例演示了经典的业务 pipeline,使用 Hive 中的表作为维度表,它们由每天一次的批任务或者 Flink 任务来更新(为方便验证改为每小时更新一次)。 Kafka 数据流来自实时在线业务数据或者日志,该流需要关联维度表以丰富数据流。
1、代码示例
-- 假设 Hive 表中的数据每天更新, 每天包含最新和完整的维度数据
SET table.sql-dialect=hive;
CREATE TABLE alan_dim_user_table (
u_id STRING,
u_name STRING,
balance DECIMAL(10, 4),
age INT
) PARTITIONED BY (pt_year STRING, pt_month STRING, pt_day STRING) TBLPROPERTIES (
-- 使用默认的 partition-name 每12小时加载最新分区数据(推荐)
'streaming-source.enable' = 'true',
'streaming-source.partition.include' = 'latest',
'streaming-source.monitor-interval' = '12 h',
'streaming-source.partition-order' = 'partition-name', -- 有默认的配置项,可以不填。
-- 使用分区文件create-time 每12小时加载最新分区数据
'streaming-source.enable' = 'true',
'streaming-source.partition.include' = 'latest',
'streaming-source.partition-order' = 'create-time',
'streaming-source.monitor-interval' = '12 h'
-- 使用 partition-time 每12小时加载最新分区数据
'streaming-source.enable' = 'true',
'streaming-source.partition.include' = 'latest',
'streaming-source.monitor-interval' = '12 h',
'streaming-source.partition-order' = 'partition-time',
'partition.time-extractor.kind' = 'default',
'partition.time-extractor.timestamp-pattern' = '$pt_year-$pt_month-$pt_day 00:00:00'
);
SET table.sql-dialect=hive;
CREATE TABLE alan_dim_user_table (
u_id BIGINT,
u_name STRING,
balance DECIMAL(10, 4),
age INT
) PARTITIONED BY (t_year STRING, t_month STRING, t_day STRING)
row format delimited
fields terminated by ","
TBLPROPERTIES (
-- 使用默认的 partition-name 每1小时加载最新分区数据(推荐)
'streaming-source.enable' = 'true',
'streaming-source.partition.include' = 'latest',
'streaming-source.monitor-interval' = '1 h',
'streaming-source.partition-order' = 'partition-name'--默认的,可以不设置
);
-- streaming sql, kafka temporal join Hive 维度表. Flink 将在 'streaming-source.monitor-interval' 的间隔内自动加载最新分区的数据。
SELECT * FROM orders_table AS o
JOIN alan_dim_user_table FOR SYSTEM_TIME AS OF o.proctime AS u
ON o.u_id = u.u_id;
2、flink 验证步骤
-------------------------flink、kafka、hive操作示例----------------------------------
----本示例是在flink版本为1.13.6的环境验证的----------------------------------
---------1、创建flink 的维表,每小时更新一次数据----------------------------------
Flink SQL> SET table.sql-dialect=hive;
[INFO] Session property has been set.
Flink SQL> show tables;
+--------------+
| table name |
+--------------+
| alan_student |
| student_ext |
| tbl |
| test_change |
| user_dept |
+--------------+
5 rows in set
Flink SQL> CREATE TABLE alan_dim_user_table (
> u_id BIGINT,
> u_name STRING,
> balance DECIMAL(10, 4),
> age INT
> ) PARTITIONED BY (t_year STRING, t_month STRING, t_day STRING)
> row format delimited
> fields terminated by ","
> TBLPROPERTIES (
> -- 使用默认的 partition-name 每1小时加载最新分区数据(推荐)
> 'streaming-source.enable' = 'true',
> 'streaming-source.partition.include' = 'latest',
> 'streaming-source.monitor-interval' = '1 h',
> 'streaming-source.partition-order' = 'partition-name'--默认的,可以不设置
> );
[INFO] Execute statement succeed.
-----------2、hive中手动加载数据,第一次只增加一条数据----------------------------------
0: jdbc:hive2://server4:10000> show tables;
+----------------------+
| tab_name |
+----------------------+
| alan_dim_user_table |
| alan_student |
| student_ext |
| tbl |
| test_change |
| user_dept |
+----------------------+
6 rows selected (0.05 seconds)
0: jdbc:hive2://server4:10000> load data inpath '/flinktest/hivetest' into table alan_dim_user_table partition(t_year='2023',t_month='09',t_day='04');
0: jdbc:hive2://server4:10000> select * from alan_dim_user_table;
+---------------------------+-----------------------------+------------------------------+--------------------------+-----------------------------+------------------------------+----------------------------+
| alan_dim_user_table.u_id | alan_dim_user_table.u_name | alan_dim_user_table.balance | alan_dim_user_table.age | alan_dim_user_table.t_year | alan_dim_user_table.t_month | alan_dim_user_table.t_day |
+---------------------------+-----------------------------+------------------------------+--------------------------+-----------------------------+------------------------------+----------------------------+
| 1 | alan | 12.2300 | 18 | 2023 | 09 | 04 |
+---------------------------+-----------------------------+------------------------------+--------------------------+-----------------------------+------------------------------+----------------------------+
-----3、flink 创建事实表----------------------------------
Flink SQL> SET table.sql-dialect=default;
[INFO] Session property has been set.
Flink SQL> CREATE TABLE alan_fact_order_table (
> o_id STRING,
> o_amount DOUBLE,
> u_id BIGINT, -- 用户id
> item_id BIGINT, -- 商品id
> action STRING, -- 用户行为
> ts BIGINT, -- 用户行为发生的时间戳
> proctime as PROCTIME(), -- 通过计算列产生一个处理时间列
> `event_time` TIMESTAMP(3) METADATA FROM 'timestamp',-- 事件时间
> WATERMARK FOR event_time as event_time - INTERVAL '5' SECOND -- 在eventTime上定义watermark
> ) WITH (
> 'connector' = 'kafka',
> 'topic' = 'test_hive_topic',
> 'properties.bootstrap.servers' = '192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092',
> 'properties.group.id' = 'testhivegroup',
> 'scan.startup.mode' = 'earliest-offset',
> 'format' = 'csv'
> );
[INFO] Execute statement succeed.
---------4、创建kafka 主题、发送消息(发送消息是在flink流式查询语句后)----------------------------------
[alanchan@server2 bin]$ kafka-topics.sh --delete --topic test_hive_topic --bootstrap-server server1:9092
[alanchan@server2 bin]$ kafka-topics.sh --create --bootstrap-server server1:9092 --topic test_hive_topic --partitions 1 --replication-factor 1
Created topic test_hive_topic.
[alanchan@server2 bin]$ kafka-console-producer.sh --broker-list server1:9092 --topic test_hive_topic
>1,123.34,1,8001,'b',1693874219248
----------5、flink 流式查询(观察维表是否加载出来数据)----------------------------------
Flink SQL> SELECT
> o.o_id,
> o.u_id,
> o.action,
> o.ts,
> o.event_time,
> u.u_name,
> u.t_year,
> u.t_month,
> u.t_day
> FROM alan_fact_order_table AS o
> JOIN alan_dim_user_table FOR SYSTEM_TIME AS OF o.proctime AS u ON o.u_id = u.u_id;
+----+--------------------------------+----------------------+--------------------------------+----------------------+-------------------------+--------------------------------+--------------------------------+--------------------------------+--------------------------------+
| op | o_id | u_id | action | ts | event_time | u_name | t_year | t_month | t_day |
+----+--------------------------------+----------------------+--------------------------------+----------------------+-------------------------+--------------------------------+--------------------------------+--------------------------------+--------------------------------+
| +I | 1 | 1 | 'b' | 1693874219248 | 2023-09-05 00:51:28.407 | alan | 2023 | 09 | 04 |
-------6、hive中加载更多的维度表数据(验证维度表是否1小时更新一次)----------------------------------
0: jdbc:hive2://server4:10000> load data inpath '/flinktest/hivetest2' into table alan_dim_user_table partition(t_year='2023',t_month='09',t_day='05');
No rows affected (0.194 seconds)
0: jdbc:hive2://server4:10000> select * from alan_dim_user_table;
+---------------------------+-----------------------------+------------------------------+--------------------------+-----------------------------+------------------------------+----------------------------+
| alan_dim_user_table.u_id | alan_dim_user_table.u_name | alan_dim_user_table.balance | alan_dim_user_table.age | alan_dim_user_table.t_year | alan_dim_user_table.t_month | alan_dim_user_table.t_day |
+---------------------------+-----------------------------+------------------------------+--------------------------+-----------------------------+------------------------------+----------------------------+
| 1 | alan | 12.2300 | 18 | 2023 | 09 | 04 |
| 2 | alanchan | 22.2300 | 10 | 2023 | 09 | 05 |
| 3 | alanchanchn | 32.2300 | 28 | 2023 | 09 | 05 |
| 4 | alan_chan | 12.4300 | 29 | 2023 | 09 | 05 |
| 5 | alan_chan_chn | 52.2300 | 38 | 2023 | 09 | 05 |
+---------------------------+-----------------------------+------------------------------+--------------------------+-----------------------------+------------------------------+----------------------------+
5 rows selected (0.143 seconds)
--------------7、kafka中继续发送消息,然后观察flink流式查询结果的变化----------------------------------
[alanchan@server2 bin]$ kafka-console-producer.sh --broker-list server1:9092 --topic test_hive_topic
>1,123.34,1,8001,'b',1693874219248-----------该数据上文中已经发送过,为了表示数据的连续性,没有删除
>20,321.34,3,9001,'a',1693874222274
>30,41.34,5,7001,'c',1693874223285
>50,666.66,2,3001,'d',1693875816640
--------------8、kafka发送消息后,flink流式查询结果----------------------------------
Flink SQL> SELECT
> o.o_id,
> o.u_id,
> o.action,
> o.ts,
> o.event_time,
> u.u_name,
> u.t_year,
> u.t_month,
> u.t_day
> FROM alan_fact_order_table AS o
> JOIN alan_dim_user_table FOR SYSTEM_TIME AS OF o.proctime AS u ON o.u_id = u.u_id;
+----+--------------------------------+----------------------+--------------------------------+----------------------+-------------------------+--------------------------------+--------------------------------+--------------------------------+--------------------------------+
| op | o_id | u_id | action | ts | event_time | u_name | t_year | t_month | t_day |
+----+--------------------------------+----------------------+--------------------------------+----------------------+-------------------------+--------------------------------+--------------------------------+--------------------------------+--------------------------------+
| +I | 20 | 3 | 'a' | 1693874222274 | 2023-09-05 00:54:49.526 | alanchanchn | 2023 | 09 | 05 |
| +I | 30 | 5 | 'c' | 1693874223285 | 2023-09-05 00:55:55.461 | alan_chan_chn | 2023 | 09 | 05 |
| +I | 50 | 2 | 'd' | 1693875816640 | 2023-09-05 01:07:23.891 | alanchan | 2023 | 09 | 05 |
--------------9、hive维表数据不变化,kafka再次发送消息,观察flink流式查询结果----------------------------------
[alanchan@server2 bin]$ kafka-console-producer.sh --broker-list server1:9092 --topic test_hive_topic
>1,123.34,1,8001,'b',1693874219248
>20,321.34,3,9001,'a',1693874222274
>30,41.34,5,7001,'c',1693874223285
>50,666.66,2,3001,'d',1693875816640
>60,666.66,4,3001,'e',1693880868579
>
--------------10、hive维表数据不变化,kafka再次发送消息后,观察flink流式查询结果(还是原来的查询界面)---------------
Flink SQL> SELECT
> o.o_id,
> o.u_id,
> o.action,
> o.ts,
> o.event_time,
> u.u_name,
> u.t_year,
> u.t_month,
> u.t_day
> FROM alan_fact_order_table AS o
> JOIN alan_dim_user_table FOR SYSTEM_TIME AS OF o.proctime AS u ON o.u_id = u.u_id;
+----+--------------------------------+----------------------+--------------------------------+----------------------+-------------------------+--------------------------------+--------------------------------+--------------------------------+--------------------------------+
| op | o_id | u_id | action | ts | event_time | u_name | t_year | t_month | t_day |
+----+--------------------------------+----------------------+--------------------------------+----------------------+-------------------------+--------------------------------+--------------------------------+--------------------------------+--------------------------------+
| +I | 20 | 3 | 'a' | 1693874222274 | 2023-09-05 00:54:49.526 | alanchanchn | 2023 | 09 | 05 |
| +I | 30 | 5 | 'c' | 1693874223285 | 2023-09-05 00:55:55.461 | alan_chan_chn | 2023 | 09 | 05 |
| +I | 50 | 2 | 'd' | 1693875816640 | 2023-09-05 01:07:23.891 | alanchan | 2023 | 09 | 05 |
| +I | 60 | 4 | 'e' | 1693880868579 | 2023-09-05 02:30:58.368 | alan_chan | 2023 | 09 | 05 |
---及时查出了数据的变化-------------------
2)、Temporal Join 最新的表
对于 Hive 表,我们可以把它看作是一个无界流进行读取,在这个案例中,当我们查询时只能去追踪最新的版本。 最新版本的表保留了 Hive 表的所有数据。
当 temporal join 最新的 Hive 表,Hive 表会缓存到 Slot 内存中,并且数据流中的每条记录通过 key 去关联表找到对应的匹配项。 使用最新的 Hive 表作为时态表不需要额外的配置。作为可选项,您可以使用以下配置项配置 Hive 表缓存的 TTL。当缓存失效,Hive 表会重新扫描并加载最新的数据。

下面的案例演示加载 Hive 表的所有数据作为时态表。
1、代码示例
-- 假设 Hive 表中的数据被批处理 pipeline 覆盖。
SET table.sql-dialect=hive;
CREATE TABLE alan_dim_user_table2 (
u_id BIGINT,
u_name STRING,
balance DECIMAL(10, 4),
age INT
)
row format delimited
fields terminated by ","
TBLPROPERTIES (
'streaming-source.enable' = 'false', -- 有默认的配置项,可以不填。
'streaming-source.partition.include' = 'all', -- 有默认的配置项,可以不填。
'lookup.join.cache.ttl' = '1 h'
);
SET table.sql-dialect=default;
CREATE TABLE alan_fact_order_table2 (
o_id STRING,
o_amount DOUBLE,
u_id BIGINT, -- 用户id
item_id BIGINT, -- 商品id
action STRING, -- 用户行为
ts BIGINT, -- 用户行为发生的时间戳
proctime as PROCTIME() -- 通过计算列产生一个处理时间列
) WITH (
'connector' = 'kafka',
'topic' = 'test_hive2_topic',
'properties.bootstrap.servers' = '192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092',
'properties.group.id' = 'testhivegroup',
'scan.startup.mode' = 'earliest-offset',
'format' = 'csv'
);
-- streaming sql, kafka join Hive 维度表. 当缓存失效时 Flink 会加载维度表的所有数据。
SELECT
o.o_id,
o.u_id,
o.action,
o.ts,
o.proctime,
dim.u_name,
dim.age,
dim.balance
FROM alan_fact_order_table2 AS o
JOIN alan_dim_user_table2 FOR SYSTEM_TIME AS OF o.proctime AS dim
ON o.u_id = dim.u_id;
2、flink验证步骤
----本示例是在flink版本为1.13.6的环境验证的----------------------------------
----本示例ttl设置为1小时,方便验证----------------------------------
----1、flink创建维表----------------------------------
Flink SQL> show tables;
+-----------------------+
| table name |
+-----------------------+
| alan_dim_user_table |
| alan_fact_order_table |
| alan_student |
| student_ext |
| tbl |
| test_change |
| user_dept |
+-----------------------+
7 rows in set
Flink SQL> SET table.sql-dialect=hive;
[INFO] Session property has been set.
Flink SQL> CREATE TABLE alan_dim_user_table2 (
> u_id BIGINT,
> u_name STRING,
> balance DECIMAL(10, 4),
> age INT
> )
> row format delimited
> fields terminated by ","
> TBLPROPERTIES (
> 'streaming-source.enable' = 'false', -- 有默认的配置项,可以不填。
> 'streaming-source.partition.include' = 'all', -- 有默认的配置项,可以不填。
> 'lookup.join.cache.ttl' = '1 h'
> );
[INFO] Execute statement succeed.
----2、hive中对维表插入数据----------------------------------
0: jdbc:hive2://server4:10000> load data inpath '/flinktest/hivetest' into table alan_dim_user_table2;
No rows affected (0.139 seconds)
0: jdbc:hive2://server4:10000> select * from alan_dim_user_table2;
+----------------------------+------------------------------+-------------------------------+---------------------------+
| alan_dim_user_table2.u_id | alan_dim_user_table2.u_name | alan_dim_user_table2.balance | alan_dim_user_table2.age |
+----------------------------+------------------------------+-------------------------------+---------------------------+
| 1 | alan | 12.2300 | 18 |
| 2 | alanchan | 22.2300 | 10 |
| 3 | alanchanchn | 32.2300 | 28 |
+----------------------------+------------------------------+-------------------------------+---------------------------+
3 rows selected (0.124 seconds)
----3、flink中创建事实表----------------------------------
Flink SQL> SET table.sql-dialect=default;
Hive Session ID = 4d502166-65b7-4079-af12-35919101ed8d
[INFO] Session property has been set.
Flink SQL> CREATE TABLE alan_fact_order_table2 (
> o_id STRING,
> o_amount DOUBLE,
> u_id BIGINT, -- 用户id
> item_id BIGINT, -- 商品id
> action STRING, -- 用户行为
> ts BIGINT, -- 用户行为发生的时间戳
> proctime as PROCTIME() -- 通过计算列产生一个处理时间列
> ) WITH (
> 'connector' = 'kafka',
> 'topic' = 'test_hive2_topic',
> 'properties.bootstrap.servers' = '192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092',
> 'properties.group.id' = 'testhivegroup',
> 'scan.startup.mode' = 'earliest-offset',
> 'format' = 'csv'
> );
[INFO] Execute statement succeed.
----4、创建kafka topic,并发送数据----------------------------------
[alanchan@server2 bin]$ kafka-topics.sh --create --bootstrap-server server1:9092 --topic test_hive2_topic --partitions 1 --replication-factor 1
WARNING: Due to limitations in metric names, topics with a period ('.') or underscore ('_') could collide. To avoid issues it is best to use either, but not both.
Created topic test_hive2_topic.
[alanchan@server2 bin]$ kafka-console-producer.sh --broker-list server1:9092 --topic test_hive2_topic
>1,123.34,1,8001,'b',1693887925763
>30,41.34,5,7001,'c',1693874222274
>30,41.34,5,7001,'c',1693887926780
>20,321.34,3,9001,'a',1693887928801
>50,666.66,2,3001,'d',1693887927790
----5、flink中查询,观察查询结果----------------------------------
Flink SQL> SELECT
> o.o_id,
> o.u_id,
> o.action,
> o.ts,
> o.proctime,
> dim.u_name,
> dim.age,
> dim.balance
> FROM alan_fact_order_table2 AS o
> JOIN alan_dim_user_table2 FOR SYSTEM_TIME AS OF o.proctime AS dim
> ON o.u_id = dim.u_id;
+----+--------------------------------+----------------------+--------------------------------+----------------------+-------------------------+--------------------------------+-------------+--------------+
| op | o_id | u_id | action | ts | proctime | u_name | age | balance |
+----+--------------------------------+----------------------+--------------------------------+----------------------+-------------------------+--------------------------------+-------------+--------------+
| +I | 1 | 1 | 'b' | 1693887925763 | 2023-09-05 04:24:47.825 | alan | 18 | 12.2300 |
| +I | 20 | 3 | 'a' | 1693887928801 | 2023-09-05 04:26:06.437 | alanchanchn | 28 | 32.2300 |
| +I | 50 | 2 | 'd' | 1693887927790 | 2023-09-05 04:26:46.404 | alanchan | 10 | 22.2300 |
----6、在hive中加载新的数据,kafka中发送新的消息,观察flink的查询结果----------------------------------
0: jdbc:hive2://server4:10000> load data inpath '/flinktest/hivetest' into table alan_dim_user_table2;
No rows affected (0.129 seconds)
0: jdbc:hive2://server4:10000> select * from alan_dim_user_table2;
+----------------------------+------------------------------+-------------------------------+---------------------------+
| alan_dim_user_table2.u_id | alan_dim_user_table2.u_name | alan_dim_user_table2.balance | alan_dim_user_table2.age |
+----------------------------+------------------------------+-------------------------------+---------------------------+
| 1 | alan | 12.2300 | 18 |
| 2 | alanchan | 22.2300 | 10 |
| 3 | alanchanchn | 32.2300 | 28 |
| 4 | alan_chan | 12.4300 | 29 |
| 5 | alan_chan_chn | 52.2300 | 38 |
+----------------------------+------------------------------+-------------------------------+---------------------------+
[alanchan@server2 bin]$ kafka-console-producer.sh --broker-list server1:9092 --topic test_hive2_topic
>1,123.34,1,8001,'b',1693887925763
>30,41.34,5,7001,'c',1693874222274
>30,41.34,5,7001,'c',1693887926780
>20,321.34,3,9001,'a',1693887928801
>50,666.66,2,3001,'d',1693887927790
>30,41.34,5,7001,'c',1693887926780-----该条数据在flink的查询结果中没有显示
Flink SQL> SELECT
> o.o_id,
> o.u_id,
> o.action,
> o.ts,
> o.proctime,
> dim.u_name,
> dim.age,
> dim.balance
> FROM alan_fact_order_table2 AS o
> JOIN alan_dim_user_table2 FOR SYSTEM_TIME AS OF o.proctime AS dim
> ON o.u_id = dim.u_id;
+----+--------------------------------+----------------------+--------------------------------+----------------------+-------------------------+--------------------------------+-------------+--------------+
| op | o_id | u_id | action | ts | proctime | u_name | age | balance |
+----+--------------------------------+----------------------+--------------------------------+----------------------+-------------------------+--------------------------------+-------------+--------------+
| +I | 1 | 1 | 'b' | 1693887925763 | 2023-09-05 04:24:47.825 | alan | 18 | 12.2300 |
| +I | 20 | 3 | 'a' | 1693887928801 | 2023-09-05 04:26:06.437 | alanchanchn | 28 | 32.2300 |
| +I | 50 | 2 | 'd' | 1693887927790 | 2023-09-05 04:26:46.404 | alanchan | 10 | 22.2300 |
----7、ttl过期后,再在kafka中发送新的消息,观察flink的查询结果----------------------------------
[alanchan@server2 bin]$ kafka-console-producer.sh --broker-list server1:9092 --topic test_hive2_topic
...,下面2条数据是TTL过期后发送的,如预期一样查出来了结果
>30,41.34,5,7001,'c',1693893016308
>1,123.34,1,8001,'b',1693893020334
Flink SQL> SELECT
> o.o_id,
> o.u_id,
> o.action,
> o.ts,
> o.proctime,
> dim.u_name,
> dim.age,
> dim.balance
> FROM alan_fact_order_table2 AS o
> JOIN alan_dim_user_table2 FOR SYSTEM_TIME AS OF o.proctime AS dim
> ON o.u_id = dim.u_id;
+----+--------------------------------+----------------------+--------------------------------+----------------------+-------------------------+--------------------------------+-------------+--------------+
| op | o_id | u_id | action | ts | proctime | u_name | age | balance |
+----+--------------------------------+----------------------+--------------------------------+----------------------+-------------------------+--------------------------------+-------------+--------------+
| +I | 1 | 1 | 'b' | 1693887925763 | 2023-09-05 04:24:47.825 | alan | 18 | 12.2300 |
| +I | 20 | 3 | 'a' | 1693887928801 | 2023-09-05 04:26:06.437 | alanchanchn | 28 | 32.2300 |
| +I | 50 | 2 | 'd' | 1693887927790 | 2023-09-05 04:26:46.404 | alanchan | 10 | 22.2300 |
| +I | 30 | 5 | 'c' | 1693893016308 | 2023-09-05 05:49:47.984 | alan_chan_chn | 38 | 52.2300 |
| +I | 1 | 1 | 'b' | 1693893020334 | 2023-09-05 05:50:23.696 | alan | 18 | 12.2300 |
------以上,完成了验证
每个参与 join 的 subtask 需要在他们的缓存中保留 Hive 表。请确保 Hive 表可以放到 TM task slot 中。
建议把这两个选项配置成较大的值 streaming-source.monitor-interval(最新的分区作为时态表) 和 lookup.join.cache.ttl(所有的分区作为时态表)。否则,任务会频繁更新和加载表,容易出现性能问题。
目前(截至flink 1.17版本),缓存刷新的时候会重新加载整个 Hive 表,所以没有办法区分数据是新数据还是旧数据。
3、写入hive数据
Flink 支持批和流两种模式往 Hive 中写入数据,当作为批程序,只有当作业完成时,Flink 写入 Hive 表的数据才能被看见。批模式写入支持追加到现有的表或者覆盖现有的表。
1)、代码示例1
# ------ INSERT INTO 将追加到表或者分区,保证数据的完整性 ------
Flink SQL> INSERT INTO mytable SELECT 'Tom', 25;
# ------ INSERT OVERWRITE 将覆盖表或者分区中所有已经存在的数据 ------
Flink SQL> INSERT OVERWRITE mytable SELECT 'Tom', 25;
2)、flink验证步骤
-------------flink 1.13.6环境中操作示例---------
Flink SQL> CREATE TABLE alan_w_user_table (
> u_id BIGINT,
> u_name STRING,
> balance DECIMAL(10, 4),
> age INT
> )
> row format delimited
> fields terminated by ","
> ;
Hive Session ID = 30451c4a-5ca9-470c-9274-9ecf5330c76d
[INFO] Execute statement succeed.
Flink SQL> show tables;
Hive Session ID = 8c5f20ac-989e-423c-b936-d8274ceff5b1
+------------------------+
| table name |
+------------------------+
| alan_dim_user_table |
| alan_dim_user_table2 |
| alan_fact_order_table |
| alan_fact_order_table2 |
| alan_student |
| alan_w_user_table |
| student_ext |
| tbl |
| test_change |
| user_dept |
+------------------------+
10 rows in set
Flink SQL> INSERT INTO alan_w_user_table values (1,'alan',12.4,18);
Job ID: ea03b7c37aca92197c608da292cbb8f3
Flink SQL> select * from alan_w_user_table;
+----+----------------------+--------------------------------+--------------+-------------+
| op | u_id | u_name | balance | age |
+----+----------------------+--------------------------------+--------------+-------------+
| +I | 1 | alan | 12.4000 | 18 |
+----+----------------------+--------------------------------+--------------+-------------+
Received a total of 1 row
-----flink streaming模式下是不支持insert overwrite的,需要设置为batch模式
Flink SQL> INSERT OVERWRITE alan_w_user_table values (1,'alanchan',22.4,19);
Hive Session ID = 58ec8fbd-aa1b-40c1-ab09-6da083e6327e
[INFO] Submitting SQL update statement to the cluster...
[ERROR] Could not execute SQL statement. Reason:
java.lang.IllegalStateException: Streaming mode not support overwrite.
-----默认为streaming模式,设置为batch模式
Flink SQL> SET execution.runtime-mode = batch;
Hive Session ID = 3eb977f9-1036-42e3-8b0f-22c2357706fc
[INFO] Session property has been set.
------flink batch模式下,不能开启checkpoint,需要关闭checkpoint才能支持batch job,
Flink SQL> INSERT OVERWRITE alan_w_user_table values (1,'alanchan',22.4,19);
Hive Session ID = 5b2db357-5c12-44a0-8159-f6f18ba5fbea
[INFO] Submitting SQL update statement to the cluster...
[ERROR] Could not execute SQL statement. Reason:
java.lang.IllegalArgumentException: Checkpoint is not supported for batch jobs.
----------此处只是为了演示insert into与insert overwrite的区别,此区别与hive中的一致,此处不再赘述,详见hive专栏的部分
还可以将数据插入到特定的分区中。
3)、代码示例2
# ------ 插入静态分区 ------
Flink SQL> INSERT OVERWRITE myparttable PARTITION (my_type='type_1', my_date='2019-08-08') SELECT 'Tom', 25;
# ------ 插入动态分区 ------
Flink SQL> INSERT OVERWRITE myparttable SELECT 'Tom', 25, 'type_1', '2019-08-08';
# ------ 插入静态(my_type)和动态(my_date)分区 ------
Flink SQL> INSERT OVERWRITE myparttable PARTITION (my_type='type_1') SELECT 'Tom', 25, '2019-08-08';
4)、flink验证步骤
------------------------flink 1.13.6环境中操作示例---------------------------------------------
----------静态分区,插入数据----------
Flink SQL> SET table.sql-dialect=hive;
[INFO] Session property has been set.
Flink SQL> CREATE TABLE alan_wp_user_table (
> u_id BIGINT,
> u_name STRING,
> balance DECIMAL(10, 4),
> age INT
> ) PARTITIONED BY (dt STRING,hr STRING)
> row format delimited
> fields terminated by ","
> TBLPROPERTIES (
> 'partition.time-extractor.timestamp-pattern'='$dt $hr:00:00',
> 'sink.partition-commit.trigger'='partition-time',
> 'sink.partition-commit.delay'='10 s',
> 'sink.partition-commit.policy.kind'='metastore,success-file'
> );
[INFO] Execute statement succeed.
Flink SQL> INSERT into alan_wp_user_table PARTITION (dt='2023-09-05', hr = '05') values (1,'alan',12.4,18);
Job ID: 8b88ccfb6e6e47a79334e79bbc946389
Flink SQL> select * from alan_wp_user_table;
+----+----------------------+--------------------------------+--------------+-------------+--------------------------------+--------------------------------+
| op | u_id | u_name | balance | age | dt | hr |
+----+----------------------+--------------------------------+--------------+-------------+--------------------------------+--------------------------------+
| +I | 1 | alan | 12.4000 | 18 | 2023-09-05 | 05 |
+----+----------------------+--------------------------------+--------------+-------------+--------------------------------+--------------------------------+
Received a total of 1 row
---------另外一种插入方式----------
Flink SQL> INSERT into alan_wp_user_table PARTITION (dt='2023-09-05', hr = '05') SELECT 2,'alanchan', 25.8,19;
Job ID: 93dbf92c01e41c245a38fb5776eb7d59
Flink SQL> select * from alan_wp_user_table;
+----+----------------------+--------------------------------+--------------+-------------+--------------------------------+--------------------------------+
| op | u_id | u_name | balance | age | dt | hr |
+----+----------------------+--------------------------------+--------------+-------------+--------------------------------+--------------------------------+
| +I | 2 | alanchan | 25.8000 | 19 | 2023-09-05 | 05 |
| +I | 1 | alan | 12.4000 | 18 | 2023-09-05 | 05 |
+----+----------------------+--------------------------------+--------------+-------------+--------------------------------+--------------------------------+
------ 插入动态分区 ------
INSERT into alan_wp_user_table SELECT 3,'alanchanchn', 35.8,29, '2023-09-05', '05';
Flink SQL> INSERT into alan_wp_user_table PARTITION (dt='2023-09-05', hr = '05') values (1,'alan',12.4,18);
------如果hive中查得到数据,flink sql中查不到数据,flink sql cli 中执行 SET table.sql-dialect=hive;命令再查即可
Flink SQL> select * from alan_wp_user_table;
+----+----------------------+--------------------------------+--------------+-------------+--------------------------------+--------------------------------+
| op | u_id | u_name | balance | age | dt | hr |
+----+----------------------+--------------------------------+--------------+-------------+--------------------------------+--------------------------------+
| +I | 1 | alan | 12.4000 | 18 | 2023-09-05 | 05 |
| +I | 2 | alanchan | 25.8000 | 19 | 2023-09-05 | 05 |
| +I | 3 | alanchanchn | 35.8000 | 29 | 2023-09-05 | 05 |
+----+----------------------+--------------------------------+--------------+-------------+--------------------------------+--------------------------------+
------ 插入静态(my_type)和动态(my_date)分区 ------
------该种插入方式需要是batch模式,batch模式不支持checkpoint ,该种情况没有进一步验证
Flink SQL> SET execution.runtime-mode = batch;
[INFO] Session property has been set.
Flink SQL> INSERT OVERWRITE alan_wp_user_table PARTITION (dt='2023-09-05') SELECT 4,'alan_chanchn', 45.8,39, '06';
Hive Session ID = 26829c28-8581-4bf4-b4f7-bea17042e6de
[INFO] Submitting SQL update statement to the cluster...
[ERROR] Could not execute SQL statement. Reason:
java.lang.IllegalArgumentException: Checkpoint is not supported for batch jobs.
流写会不断的往 Hive 中添加新数据,提交记录使它们可见。用户可以通过几个属性控制如何触发提交。
流写不支持 Insert overwrite
5)、代码示例3
下面的案例演示如何流式地从 Kafka 写入 Hive 表并执行分区提交,然后运行一个批处理查询将数据读出来。
---创建hive表
SET table.sql-dialect=hive;
CREATE TABLE alan_hive_user_table (
u_id BIGINT,
u_name STRING,
balance DECIMAL(10, 4),
age INT
) PARTITIONED BY (dt STRING,hr STRING)
row format delimited
fields terminated by ","
TBLPROPERTIES (
'partition.time-extractor.timestamp-pattern'='$dt $hr:00:00',
'sink.partition-commit.trigger'='partition-time',
'sink.partition-commit.delay'='10 s',
'sink.partition-commit.policy.kind'='metastore,success-file',
'sink.rolling-policy.rollover-interval'='5s',
'sink.partition-commit.watermark-time-zone'='Asia/Shanghai' -- 假设用户配置的时区为 'Asia/Shanghai',
);
---创建kafka表
SET table.sql-dialect=default;
CREATE TABLE alan_kafka_table (
u_id BIGINT,
u_name STRING,
balance DECIMAL(10, 4),
age INT,
`event_time` TIMESTAMP(3) METADATA FROM 'timestamp',-- 事件时间
WATERMARK FOR event_time as event_time - INTERVAL '5' SECOND -- 在eventTime上定义watermark
) WITH (
'connector' = 'kafka',
'topic' = 'alan_kafka_hive_topic',
'properties.bootstrap.servers' = '192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'earliest-offset',
'format' = 'csv'
);
-- 流式sql 插入hive数据库
INSERT INTO alan_hive_user_table
SELECT u_id, u_name,balance,age, DATE_FORMAT(`event_time`, 'yyyy-MM-dd'), DATE_FORMAT(`event_time`, 'HH')
FROM alan_kafka_table;
-- 批处理sql ,按照分区查询
SELECT * FROM alan_hive_user_table WHERE dt='2023-09-05' and hr='07';
6)、flink验证步骤
-----设置运行环境
Flink SQL> SET execution.runtime-mode = streaming;
[INFO] Session property has been set.
----设置hive方言
Flink SQL> SET table.sql-dialect=hive;
Hive Session ID = b64d5e77-1f0e-4480-a680-0f7ebf7e34c4
[INFO] Session property has been set.
-----创建hive表
Flink SQL> CREATE TABLE alan_hive_user_table (
> u_id BIGINT,
> u_name STRING,
> balance DECIMAL(10, 4),
> age INT
> ) PARTITIONED BY (dt STRING,hr STRING)
> row format delimited
> fields terminated by ","
> TBLPROPERTIES (
> 'partition.time-extractor.timestamp-pattern'='$dt $hr:00:00',
> 'sink.partition-commit.trigger'='partition-time',
> 'sink.partition-commit.delay'='10 s',
> 'sink.partition-commit.policy.kind'='metastore,success-file',
> 'sink.rolling-policy.rollover-interval'='5s',
> 'sink.partition-commit.watermark-time-zone'='Asia/Shanghai' -- 假设用户配置的时区为 'Asia/Shanghai',
> );
[INFO] Execute statement succeed.
----设置flink 默认方言
Flink SQL> SET table.sql-dialect=default;
[INFO] Session property has been set.
------创建kafka表
Flink SQL> CREATE TABLE alan_kafka_table (
> u_id BIGINT,
> u_name STRING,
> balance DECIMAL(10, 4),
> age INT,
> `event_time` TIMESTAMP(3) METADATA FROM 'timestamp',-- 事件时间
> WATERMARK FOR event_time as event_time - INTERVAL '5' SECOND -- 在eventTime上定义watermark
> ) WITH (
> 'connector' = 'kafka',
> 'topic' = 'alan_kafka_hive_topic',
> 'properties.bootstrap.servers' = '192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092',
> 'properties.group.id' = 'testGroup',
> 'scan.startup.mode' = 'earliest-offset',
> 'format' = 'csv'
> );
------流式sql ,按照分区流式插入数据,也即flink的一个任务
Flink SQL> INSERT INTO alan_hive_user_table
> SELECT u_id, u_name,balance,age, DATE_FORMAT(`event_time`, 'yyyy-MM-dd'), DATE_FORMAT(`event_time`, 'HH')
> FROM alan_kafka_table;
Job ID: 95fceba5540315957ed7d0b873461e43
-----kafka 发送数据
[alanchan@server2 bin]$ kafka-console-producer.sh --broker-list server1:9092 --topic alan_kafka_hive_topic
>1,'alan',123.34,18
>2,'alanchan',223.34,28
>
---flink sql 查询数据,kafka发送一次查询一次
Flink SQL> select * from alan_hive_user_table where dt='2023-09-05' and hr='07';
+----+----------------------+--------------------------------+--------------+-------------+--------------------------------+--------------------------------+
| op | u_id | u_name | balance | age | dt | hr |
+----+----------------------+--------------------------------+--------------+-------------+--------------------------------+--------------------------------+
| +I | 1 | 'alan' | 123.3400 | 18 | 2023-09-05 | 07 |
+----+----------------------+--------------------------------+--------------+-------------+--------------------------------+--------------------------------+
Received a total of 1 row
Flink SQL> select * from alan_hive_user_table where dt='2023-09-05' and hr='07';
+----+----------------------+--------------------------------+--------------+-------------+--------------------------------+--------------------------------+
| op | u_id | u_name | balance | age | dt | hr |
+----+----------------------+--------------------------------+--------------+-------------+--------------------------------+--------------------------------+
| +I | 1 | 'alan' | 123.3400 | 18 | 2023-09-05 | 07 |
| +I | 2 | 'alanchan' | 223.3400 | 28 | 2023-09-05 | 07 |
+----+----------------------+--------------------------------+--------------+-------------+--------------------------------+--------------------------------+
Received a total of 2 rows
如果在 TIMESTAMP_LTZ 列定义了 watermark 并且使用 partition-time 提交,需要对 sink.partition-commit.watermark-time-zone 设置会话时区,否则分区提交会发生在几个小时后。
下面的示例可以参考16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及FileSystem示例(1)中的示例,区别在于connector不同,实际设置一样,不再赘述。
SET table.sql-dialect=hive;
CREATE TABLE hive_table (
user_id STRING,
order_amount DOUBLE
) PARTITIONED BY (dt STRING, hr STRING) STORED AS parquet TBLPROPERTIES (
'partition.time-extractor.timestamp-pattern'='$dt $hr:00:00',
'sink.partition-commit.trigger'='partition-time',
'sink.partition-commit.delay'='1 h',
'sink.partition-commit.watermark-time-zone'='Asia/Shanghai', -- 假设用户配置的时区是 'Asia/Shanghai'。
'sink.partition-commit.policy.kind'='metastore,success-file'
);
SET table.sql-dialect=default;
CREATE TABLE kafka_table (
user_id STRING,
order_amount DOUBLE,
ts BIGINT, -- time in epoch milliseconds
ts_ltz AS TO_TIMESTAMP_LTZ(ts, 3),
WATERMARK FOR ts_ltz AS ts_ltz - INTERVAL '5' SECOND -- 在 TIMESTAMP_LTZ 列声明 watermark。
) WITH (...);
-- streaming sql, insert into hive table
INSERT INTO TABLE hive_table
SELECT user_id, order_amount, DATE_FORMAT(ts_ltz, 'yyyy-MM-dd'), DATE_FORMAT(ts_ltz, 'HH')
FROM kafka_table;
-- batch sql, select with partition pruning
SELECT * FROM hive_table WHERE dt='2020-05-20' and hr='12';
默认情况下,对于流,Flink 仅支持重命名 committers,对于 S3 文件系统不支持流写的 exactly-once 语义。 通过将以下参数设置为 false,可以实现 exactly-once 写入 S3。 这会调用 Flink 原生的 writer ,但是仅针对 parquet 和 orc 文件类型有效。 这个配置项可以在 TableConfig 中配置,该配置项对作业的所有 sink 都生效。

7)、动态分区的写入
不同于静态分区的写入总是需要用户指定分区列的值,动态分区允许用户在写入数据的时候不指定分区列的值。 比如,有这样一个分区表:
CREATE TABLE alan_wp_user_table (
u_id BIGINT,
u_name STRING,
balance DECIMAL(10, 4),
age INT
) PARTITIONED BY (dt STRING,hr STRING)
row format delimited
fields terminated by ","
TBLPROPERTIES (
'partition.time-extractor.timestamp-pattern'='$dt $hr:00:00',
'sink.partition-commit.trigger'='partition-time',
'sink.partition-commit.delay'='10 s',
'sink.partition-commit.policy.kind'='metastore,success-file'
);
用户可以使用如下的 SQL 语句向该分区表写入数据:
INSERT into alan_wp_user_table SELECT 3,'alanchanchn', 35.8,29, '2023-09-05', '05';
在该 SQL 语句中,用户没有指定分区列的值,这就是一个典型的动态分区写入的例子。
默认情况下, 如果是动态分区的写入, 在实际写入目标表之前,Flink 将额外对数据按照动态分区列进行排序。 这就意味着 sink 节点收到的数据都是按分区排序的,即首先收到一个分区的数据,然后收到另一个分区的数据,不同分区的数据不会混在一起。 这样 Hive sink 节点就可以一次只维护一个分区的 writer,否则,Hive sink 需要维护收到的数据对应的所有分区的 writer,如果分区的 writer 过多的话,则可能会导致内存溢出(OutOfMemory)异常。
为了避免额外的排序,你可以将作业的配置项 table.exec.hive.sink.sort-by-dynamic-partition.enable(默认是 true)设置为 false。 但是这种配置下,如之前所述,如果单个 sink 节点收到的动态分区数过多的话,则有可能会出现内存溢出的异常。
如果数据倾斜不严重的话,你可以在 SQL 语句中添加 DISTRIBUTED BY <partition_field> 将相同分区的数据分布到到相同的 sink 节点上来缓解单个 sink 节点的分区 writer 过多的问题。
此外,你也可以在 SQL 语句中添加 DISTRIBUTED BY <partition_field> 来达到将 table.exec.hive.sink.sort-by-dynamic-partition.enable 设置为 false 的效果。
该配置项 table.exec.hive.sink.sort-by-dynamic-partition.enable 只在批模式下生效。
目前(截至1.17版本),只有在 Flink 批模式下使用了 Hive 方言,才可以使用 DISTRIBUTED BY 和 SORTED BY。
8)、自动收集统计信息
在使用 Flink 写入 Hive 表的时候,Flink 将默认自动收集写入数据的统计信息然后将其提交至 Hive metastore 中。 但在某些情况下,你可能不想自动收集统计信息,因为收集这些统计信息可能会花费一定的时间。 为了避免 Flink 自动收集统计信息,你可以设置作业参数 table.exec.hive.sink.statistic-auto-gather.enable (默认是 true) 为 false。
如果写入的 Hive 表是以 Parquet 或者 ORC 格式存储的时候,numFiles/totalSize/numRows/rawDataSize 这些统计信息可以被 Flink 收集到。 否则, 只有 numFiles/totalSize 可以被收集到。
对于 Parquet 或者 ORC 格式的表,为了快速收集到统计信息 numRows/rawDataSize, Flink 只会读取文件的 footer。但是在文件数量很多的情况下,这可能也会比较耗时,你可以通过 设置作业参数 table.exec.hive.sink.statistic-auto-gather.thread-num(默认是 3)为一个更大的值来加快统计信息的收集。
只有批模式才支持自动收集统计信息,流模式目前还不支持自动收集统计信息。
9)、文件合并
在使用 Flink 写 Hive 表的时候,Flink 也支持自动对小文件进行合并以减少小文件的数量。
-
Stream Mode
流模式下,合并小文件的行为与写 文件系统 一样,更多细节请参考 16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及FileSystem示例(1) -
Batch Mode
在批模式,并且自动合并小文件已经开启的情况下,在结束写 Hive 表后,Flink 会计算每个分区下文件的平均大小,如果文件的平均大小小于用户指定的一个阈值,Flink 则会将这些文件合并成指定大小的文件。下面是文件合并涉及到的参数:
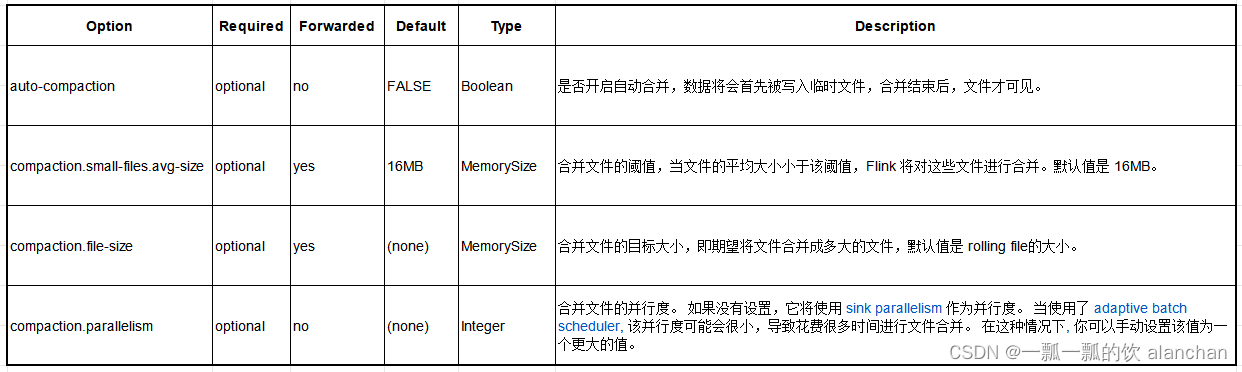
4、格式
Flink 对 Hive 的集成已经在如下的文件格式进行了测试:
- Text
- CSV
- SequenceFile
- ORC
- Parquet
hive的文件格式的设置方式与直接在hive中设置方式一样,不再赘述。具体可以参考
3、hive的使用示例详解-建表、数据类型详解、内部外部表、分区表、分桶表
4、hive的使用示例详解-事务表、视图、物化视图、DDL(数据库、表以及分区)管理详细操作
以上,详细的介绍了Flink 与hive的集成、通过flink sql读写hive数据。