前言
python是当前数据分析最流行的工具之一,在做数据分析的时候我们经常会用到一些统计学的基础知识和概念,如概率,分布,直方图,箱体图,分位数等等。不可否认的是R语言及其工具是统计分析最专业的武器,正因为它太过专业(使用者需要具备统计学的专业知识),使得它的受众局限于特定领域的专业人士,而python是后起之秀,它瑞士军刀般的灵活性正被越来越多的IT从业人员所使用,同时python也包含了很多第三方的数据分析工具库,今天我们就来使用python对真实房屋销售数据进行分析,同时还会对其中涉及到的一些统计学的基础概念进行讲解,希望我分享的东西对那些想成为数据科学家和机器学习工程师的朋友们带来一定帮助, 好了,废话少说,让我们撸起袖子,干起来吧!
数据
我们的数据来自于kaggle,它是关于房屋的销售数据,你可以点击这里进行下载。下面是数据字段的含义在下载页面中有介绍,我就不一一说明了。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from plotly.offline import init_notebook_mode, iplot
import plotly.figure_factory as ff
import cufflinks
cufflinks.go_offline()
cufflinks.set_config_file(world_readable=True, theme='pearl')
import plotly.graph_objs as go
import plotly.plotly as py
import plotly
from plotly import tools
plotly.tools.set_credentials_file(username='XXX', api_key='XXXX')#需要注册自己的账号
init_notebook_mode(connected=True)
pd.set_option('display.max_columns', 100)在这里我们用到了plotly库,plotly是开挂的作图神器,可以供js, python, R, DB等使用,我们用它来进行一些交互式的可视化操作如画直方图、箱线图等,但是使用plotly需要在它网站上注册一个账号,否则无法使用。朋友们可以在这里点击这里进行注册。
df = pd.read_csv('./data/house_train.csv')
df.drop('Id', axis=1, inplace=True)
df.head() 
单变量分析
在统计学中,我们把变量一般分为两类:分类型变量和数值型变量。数值型变量又可分为连续型和离散型,分类型变量又可分为普通型分类变量和有序型分类变量:

我们使用describe()命令可以查看数据中说有数值型变量的分布情况:

同样我们可以使用describe(include=['0'])命令来查看数据中的所有分类型变量的分布情况:
table_cat = ff.create_table(df.describe(include=['O']).T, index=True, index_title='Categorical columns')
iplot(table_cat)
直方图
对于数值型变量,我们一般会用直方图来展示其数据的分布,下面我们画一下房屋销售价格(SalePrice)的直方图,其中参数bins表示X轴被划分若干区间的数量,y轴表示对应的价格区间在数据中出现的数量(频率)
df['SalePrice'].iplot(
kind='hist',
bins=50,
xTitle='price',
linecolor='black',
yTitle='count',
title='销售价格直方图')
箱线图
箱线图并不显示数据分布的形状,但它可以让我们更好地了解数据分布的中心位置和扩散程度以及可能存在的任何潜在异常值。 箱线图和直方图通常互为补充,有助于我们更好地了解数据,下面我们解释一下箱线图,箱线图是描述数据值与数据数量之间的关系:

我们将一组样本数据进行排序,然后我们观察数据值与数据数量之间的关系,我们就可以画出所谓的箱线图,如上图所示Q1表示第一四分位数,Q3表示第三四分位数,IQR表示四分位数间距,任何落在上边缘和下边缘范围之外的数据我们称为潜在异常值,即 异常值<(Q1-1.5×IQR) 或者 异常值>(Q3+1.5×IQR).

最大值的上限位置位于Q3+1.5×IQR。最大值上限位置以外的数据,我们称为潜在的异常值。
下面我们查看房屋销售价格的箱线图,从图中我们可以看到数据的最小值,最大值,第一四分位数(Q1),第三四分位数(Q3),中位数(median)。

分组查看箱线图和直方图
对变量CentralAir进行分组查看它们对销售价格的影响
我们想通过分组的方式查看当分类型变量取不同的值时它对房屋销售价格有什么影响,如带有空调的房子和不带空调的房子,它们的销售价格会有差异吗?房屋的车库面积(1车位,2车位...)对房屋销售价格会有什么影响吗?
trace0 = go.Box(
y=df.loc[df['CentralAir'] == 'Y']['SalePrice'],
name = '带空调',
marker = dict(color = 'rgb(214, 12, 140)',
)
)
trace1 = go.Box(
y=df.loc[df['CentralAir'] == 'N']['SalePrice'],
name = '不带空调',
marker = dict(color = 'rgb(0, 128, 128)',
)
)
data = [trace0, trace1]
layout = go.Layout(
title = "销售价格箱体图"
)
fig = go.Figure(data=data,layout=layout)
py.iplot(fig)
从上面的箱线图中我们可以看见带空调的房屋销售价格的中位数(median)比不带空调的价格要高。
带中央空调与不带中央空调的房子它们的房屋销售价格是否存在差异? 从下面的直方图中我可以发现带空调的房屋销售价格与不带空调的房屋销售价格相比整体往右边偏移,说明有空调的房屋销售价格的均值要高于不带空调的价格。
trace0 = go.Histogram(
x=df.loc[df['CentralAir'] == 'Y']['SalePrice'], name='带中央空调',
opacity=0.75
)
trace1 = go.Histogram(
x=df.loc[df['CentralAir'] == 'N']['SalePrice'], name='不带中央空调',
opacity=0.75
)
data = [trace0, trace1]
layout = go.Layout(barmode='overlay', title='中央空调与销售价格的关系直方图')
fig = go.Figure(data=data, layout=layout)
py.iplot(fig) 
同样我们可以使用pandas的groupby方法对相关变量进行分组统计:

我们看到有空调的房屋销售价格的均值(mean)明显高于不带空调的房屋销售价格。
对车库面积进行分组查看它们对销售价格的影响
trace0 = go.Box(
y=df.loc[df['GarageCars'] == 0]['SalePrice'],
name = 'no garage',
marker = dict(
color = 'rgb(214, 12, 140)',
)
)
trace1 = go.Box(
y=df.loc[df['GarageCars'] == 1]['SalePrice'],
name = '1-car garage',
marker = dict(
color = 'rgb(0, 128, 128)',
)
)
trace2 = go.Box(
y=df.loc[df['GarageCars'] == 2]['SalePrice'],
name = '2-cars garage',
marker = dict(
color = 'rgb(12, 102, 14)',
)
)
trace3 = go.Box(
y=df.loc[df['GarageCars'] == 3]['SalePrice'],
name = '3-cars garage',
marker = dict(
color = 'rgb(10, 0, 100)',
)
)
trace4 = go.Box(
y=df.loc[df['GarageCars'] == 4]['SalePrice'],
name = '4-cars garage',
marker = dict(
color = 'rgb(100, 0, 10)',
)
)
data = [trace0, trace1, trace2, trace3, trace4]
layout = go.Layout(
title = "车库大小与销售价格箱体图"
)
fig = go.Figure(data=data,layout=layout)
py.iplot(fig)
我们看到3车位的房屋销售价格的中位数最高其次是4车位,2车位的,不带车库房屋的销售价格中位数最低。从一般常识来说车库面积越大房屋价格也应该越高,可是从数据的分析中我们发现3车位的价格要高于4车位的价格。这可能和家庭的人口结构有关,所以有时候不能完全相信常识。
不带车库的房屋销售价格的直方图
df.loc[df['GarageCars'] == 0]['SalePrice'].iplot(
kind='hist',
bins=50,
xTitle='price',
linecolor='black',
yTitle='count',
title='不带车库的房屋销售价格直方图')
带1个车位的房屋销售价格直方图
df.loc[df['GarageCars'] == 1]['SalePrice'].iplot(
kind='hist',
bins=50,
xTitle='price',
linecolor='black',
yTitle='count',
title='房屋销售价格直方图-带1个车位的车库') 
带2个车位的房屋销售价格直方图
df.loc[df['GarageCars'] == 2]['SalePrice'].iplot(
kind='hist',
bins=50,
xTitle='price',
linecolor='black',
yTitle='count',
title='房屋销售价格直方图-带2个车位的车库')
带3个车位的房屋销售价格直方图
df.loc[df['GarageCars'] == 3]['SalePrice'].iplot(
kind='hist',
bins=50,
xTitle='price',
linecolor='black',
yTitle='count',
title='房屋销售价格直方图-带3个车位的车库')
带4个车位的房屋销售价格直方图
df.loc[df['GarageCars'] == 4]['SalePrice'].iplot(
kind='hist',
bins=10,
xTitle='price',
linecolor='black',
yTitle='count',
title='Histogram of Sale Price of houses with 4-car garage') 
频率分析
频率会告诉我们事情发生的频率。 频率表为我们提供了数据的快照,以便我们能从中找出数据中潜在的模式。
Overall Quality 频率表
OverallQual变量表示“整体材料和成品质量”,它的值取自1-10中任意一个数,下面我们查看不同成品质量值所占的比重:
GarageCars(车库面积) 频率表
GarageCars变量表示车库中的车位数,它的值取自0-4中任意一个数,下面我们查看不同车位数所占的比重:
是否带空调 频率表
CentralAir变量房屋是否带有中央空调,它的值取自Y,N中任意一个数,下面我们查看Y和N所占的比重:

数值型变量的整体摘要
我们可以通过describe()方法对数值型变量进行整体性摘要,下面我们获取销售价格的整体摘要:

我们也可以单独计算销售价格的各个单项的统计摘要:
print("销售价格均值, - Pandas方法: ", df.SalePrice.mean())
print("销售价格均值, - Numpy方法: ", np.mean(df.SalePrice))
print("价格中位数: - Pandas方法", df.SalePrice.median())
print("50th 分位数,等同于中位数 - Numpy方法: ", np.percentile(df.SalePrice, 50))
print("75th 分位数 - Numpy方法:: ", np.percentile(df.SalePrice, 75))
print("75th 分位数 - Pandas方法: ", df.SalePrice.quantile(0.75))
接下来我们使用2种方法来计算IQR所占比例:
print('SalePrice的IQR(Q3-Q1)所占比例: ', np.mean((df.SalePrice >= 129975) & (df.SalePrice <= 214000)))
print("SalePrice的IQR(Q3-Q1)所占比例:",len(df[(df.SalePrice>=129975)&(df.SalePrice<=214000)])/len(df))
我们看到两种方法计算SalePrice的IQR的结果都是一样的,IQR占了50%的数据量。
下面我计算地下室面积的IQR所占比例,同样我们用两种方法来计算:

print('地下室面积(TotalBsmtSF)的IQR(Q3-Q1)所占比例:',np.mean((df.TotalBsmtSF >= 795.75) & (df.TotalBsmtSF <= 1298.25)))
print('地下室面积(TotalBsmtSF)的IQR(Q3-Q1)所占比例:',len(df[(df.TotalBsmtSF>=795.75)&(df.TotalBsmtSF<=1298.25)])/len(df))
下面我们想看一下销售价格IQR区间内的数据和地下室面积IQRQ区间内的数据是否有重合,我们将销售价格的IQR和地下室面积的IQR做一个并集,如果他们之间没有重合,那么并集所占比例正好为1,因为它正好覆盖整个数据集,如果他们之间有重合,那么并集所占比例将大于0.5且小于1.
sprice_q1= 129975
sprice_q3=214000
a = (df.SalePrice >= sprice_q1) & (df.SalePrice <= sprice_q3)
tbs_q1=795.75
tbs_q3 = 1298.25
b = (df.TotalBsmtSF >= tbs_q1) & (df.TotalBsmtSF <= tbs_q3)
print(np.mean(a | b))![]()
下面我们计算房屋带空调和不带空调的IQR:

分层
分层是一种从数据集中获取更多信息的方法,它将数据集划分为更小,更均匀的子集,通过分层我们可以创建新的特征。下面我们来创建一个新的特征:“房龄”

我们将房龄划分成若干个区间,然后我们查看房龄的箱线图:
df["AgeGrp"] = pd.cut(df.HouseAge, [9, 20, 40, 60, 80, 100, 147])
plt.figure(figsize=(12, 5))
sns.boxplot(x="AgeGrp", y="SalePrice", data=df); 
我们看到房龄越小,价格中位数越高,这也是合理的因为新房子的价格应该要比老房子的价格高。房价似乎随着房龄的增加而最近减小,但是一个有趣的现象是房龄超过100岁的房屋销售价格似乎略微高于之前的(80,100)的房龄的房价。
下面我们在房龄的基础上加入空调变量,我们想看看不同的房龄区间和房屋是否带空调对房价的影响:
plt.figure(figsize=(12, 5))
sns.boxplot(x="AgeGrp", y="SalePrice", hue="CentralAir", data=df)
plt.show();
上图中我们可以发现,小于40年房龄的房子都带有空调,大于40年房龄的房子开始出现不带空调的情况,这也应该是合理的,40年以上房龄的老房子,那个年底空调不知道发明了没有,即便已经发明了也应该是没有普及,所以不带空调的房子还是比较普遍。
同样我们也可以在空调变量的基础上加上房龄变量,然后我查看它们与房价之间的关系:
plt.figure(figsize=(12, 5))
sns.boxplot(x="CentralAir", y="SalePrice", hue="AgeGrp", data=df)
plt.show();
我们发现在带有空调的房屋中,房价的变化趋势随着房龄的增加而减少,这个情况类似与之前单独展示房龄和房价的箱线图的情形一样,在不带空调的房屋中房龄都大于40年,100年以上房龄的房价似乎是最高的。
接下来我们按照房龄和空调变量进行分组,然后统计住宅类型(BldgType)的数量分布情况:
df1 = df.groupby(["AgeGrp", "CentralAir"])["BldgType"]
df1 = df1.value_counts()
df1 = df1.unstack()
df1 = df1.apply(lambda x: x/x.sum(), axis=1) # 标准化处理(归一化)
print(df1.to_string(float_format="%.3f"))
我们发现在所有的房屋中(不管房龄大小)住宅类型为"1Fam"的所占比重最大,房龄越大住宅类型越少, 80年以上的房龄大部分只有“1Fam”和“2fmCon”两种住宅类型。越古老的房子越趋向于没有空调。
多变量分析
前面我们所做的分析都是基于单个变量的分析,接下来我们要进行多个变量同时进行分析。
散点图
我们首先画一下居住面积(GrLivArea)和房屋销售价格的散点图,从散点图中我们发现房屋居住面积和销售价格呈现正相关趋势。
df.iplot(
x='GrLivArea',
y='SalePrice',
xTitle='地上居住面积',
yTitle='销售价格',
mode='markers',
title='房屋价格与居住面积散点分布')
2D密度联合图
接下来我们要画2D密度联合图,我们要在在散点图的基础上画热力图,在顶部和右侧分布画对应热力图的居住面积和销售价格的密度图
trace1 = go.Scatter(
x=df['GrLivArea'], y=df['SalePrice'], mode='markers', name='points',
marker=dict(color='rgb(102,0,0)', size=2, opacity=0.4)
)
trace2 = go.Histogram2dContour(
x=df['GrLivArea'], y=df['SalePrice'], name='密度', ncontours=20,
colorscale='Hot', reversescale=True, showscale=False
)
trace3 = go.Histogram(
x=df['GrLivArea'], name='地面居住面积密度',
marker=dict(color='rgb(102,0,0)'),
yaxis='y2'
)
trace4 = go.Histogram(
y=df['SalePrice'], name='价格密度', marker=dict(color='rgb(102,0,0)'),
xaxis='x2'
)
data = [trace1, trace2, trace3, trace4]
layout = go.Layout(
showlegend=False,
autosize=False,
width=600,
height=550,
xaxis=dict(
domain=[0, 0.85],
showgrid=False,
zeroline=False
),
yaxis=dict(
domain=[0, 0.85],
showgrid=False,
zeroline=False
),
margin=dict(
t=50
),
hovermode='closest',
bargap=0,
xaxis2=dict(
domain=[0.85, 1],
showgrid=False,
zeroline=False
),
yaxis2=dict(
domain=[0.85, 1],
showgrid=False,
zeroline=False
)
)
fig = go.Figure(data=data, layout=layout)
py.iplot(fig)
分类变量的分层探索
我们将继续探索居住面积(GrLivArea)和销售价格之间的关系,不过这次我们住宅类型(BldgType)分层的方式来研究,我们要按5种住宅类型,分别画出5个居住面积和销售价格的散点图。
trace0 = go.Scatter(x=df.loc[df['BldgType'] == '1Fam']['GrLivArea'], y=df.loc[df['BldgType'] == '1Fam']['SalePrice'], mode='markers', name='1Fam')
trace1 = go.Scatter(x=df.loc[df['BldgType'] == 'TwnhsE']['GrLivArea'], y=df.loc[df['BldgType'] == 'TwnhsE']['SalePrice'], mode='markers', name='TwnhsE')
trace2 = go.Scatter(x=df.loc[df['BldgType'] == 'Duplex']['GrLivArea'], y=df.loc[df['BldgType'] == 'Duplex']['SalePrice'], mode='markers', name='Duplex')
trace3 = go.Scatter(x=df.loc[df['BldgType'] == 'Twnhs']['GrLivArea'], y=df.loc[df['BldgType'] == 'Twnhs']['SalePrice'], mode='markers', name='Twnhs')
trace4 = go.Scatter(x=df.loc[df['BldgType'] == '2fmCon']['GrLivArea'], y=df.loc[df['BldgType'] == '2fmCon']['SalePrice'], mode='markers', name='2fmCon')
fig = tools.make_subplots(rows=2, cols=3)
fig.append_trace(trace0, 1, 1)
fig.append_trace(trace1, 1, 2)
fig.append_trace(trace2, 1, 3)
fig.append_trace(trace3, 2, 1)
fig.append_trace(trace4, 2, 2)
fig['layout'].update(height=400, width=800, title='按住宅类型分组查看居住面积与房屋销售价格散点')
py.iplot(fig)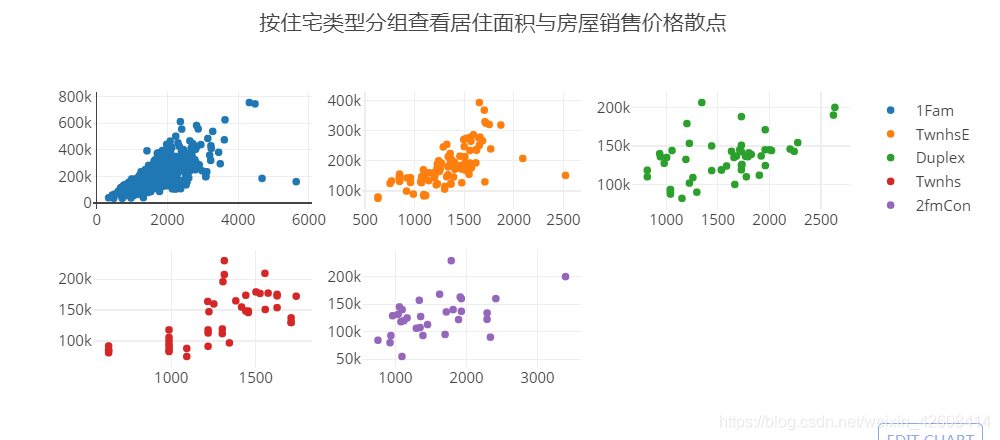
在上图中我们发现,在5种住宅类型的散点图中,居住面积都与销售价格成正相关趋势。
下面我们任然按5种住宅类型分层的方式来计算居住面积和销售价格的相关系数:
print(df.loc[df.BldgType=="1Fam", ["GrLivArea", "SalePrice"]].corr())
print('-----------------------------------')
print(df.loc[df.BldgType=="TwnhsE", ["GrLivArea", "SalePrice"]].corr())
print('-----------------------------------')
print(df.loc[df.BldgType=='Duplex', ["GrLivArea", "SalePrice"]].corr())
print('-----------------------------------')
print(df.loc[df.BldgType=="Twnhs", ["GrLivArea", "SalePrice"]].corr())
print('-----------------------------------')
print(df.loc[df.BldgType=="2fmCon", ["GrLivArea", "SalePrice"]].corr()) 
两个分类变量的交叉分析
下面我们要对MSZoning(区域分类)和BldgType(住宅类型)这两个分类变量,进行交叉分析。首先我们统计它们的同现次数:
x = pd.crosstab(df.MSZoning, df.BldgType)
x 
按列归一化
我们按列来进行归一化,这样我们就可以看到MSZoning的值对应各个不同的BldgType值所占比重是多少
x.apply(lambda z: z/z.sum(), axis=1) 
按行归一化
我们按行来进行归一化,这样我们就可以看到BldgType的值对应各个不同的MSZoning值所占比重是多少

对三个分类变量分组统计
下面我要对"CentralAir", "BldgType", "MSZoning"这三个分类变量进行分组统计它们的同现次数,并进行归一化。
df.groupby(["CentralAir", "BldgType", "MSZoning"]).size().unstack().fillna(0).apply(lambda x: x/x.sum(), axis=1) 
我们看到变量MSZoning的“RL”列所占比重是最大的,其中有空调的里面1Fam,RL所占比重最大为86.4%,没空调的里面,Duplex,RL所占比重最大为75%。
分类型和数值型混合变量分析
下面我们要画一个小提琴图,用以显示在不同的住宅类型的情况下销售价格的分布情况:
data = []
for i in range(0,len(pd.unique(df['BldgType']))):
trace = {
"type": 'violin',
"x": df['BldgType'][df['BldgType'] == pd.unique(df['BldgType'])[i]],
"y": df['SalePrice'][df['BldgType'] == pd.unique(df['BldgType'])[i]],
"name": pd.unique(df['BldgType'])[i],
"box": {
"visible": True
},
"meanline": {
"visible": True
}
}
data.append(trace)
fig = {
"data": data,
"layout" : {
"title": "",
"yaxis": {
"zeroline": False,
}
}
}
py.iplot(fig)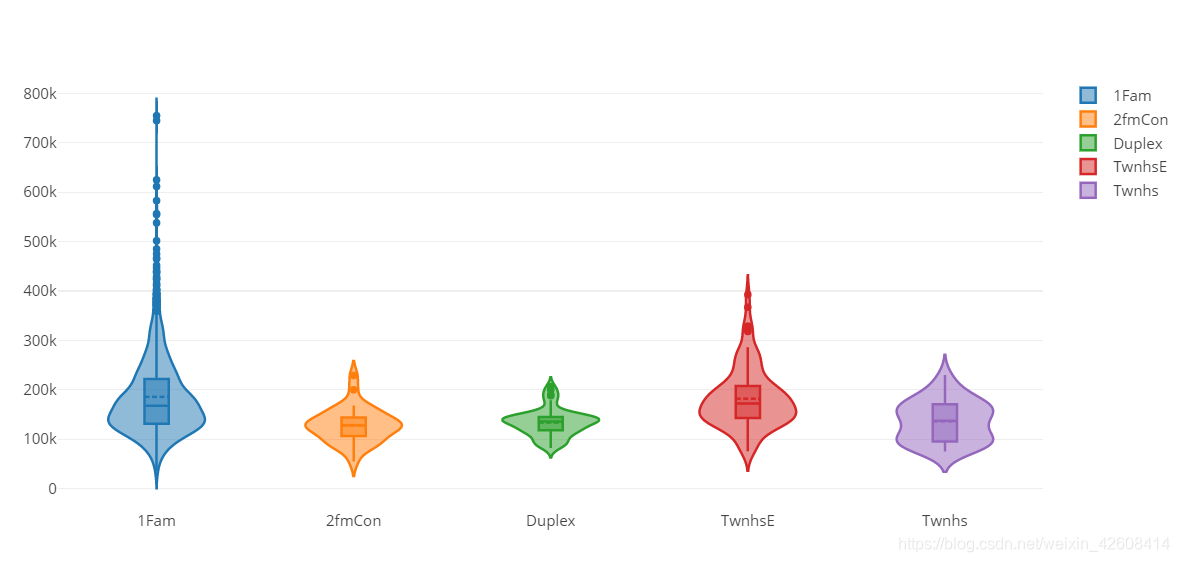
我们可以看到1Fam住宅类型的SalesPrice分布略微右偏,而对于其他住宅类型,SalePrice分布接近正太分布。
完整代码在此下载:
交互式可视化效果展示(需梯子):
