统计学中有两个主要学派:频率学派和贝叶斯学派,他们之间有共同点,又有不同点。为了说清楚他们之间的差异,我们从统计推断所使用的三种信息说起。
- 总体信息
即总体分布或者总体所属分布族给我们的信息,譬如,总体是“正太分布”,那我们就知道它的密度曲线是一条钟形曲线,并且有μ和σ这两个参数,它们分别正太分布的均值和标准差(方差)。总体信息是很重要的信息,为了获取此种信息往往耗资巨大。如美国军方为了获得某种新的电子元器件的寿命分布,常常购买成千上万的个此种元器件,做大量寿命试验,获得大量数据后才能确认其寿命分布是什么。
- 样本信息
即从总体抽样的样本给我们提供的信息。这是最“新鲜”的信息,并且愈多愈好。人们希望通过对样本的加工和处理可以对总体的某些特征做出较为精准的统计推断。没有样本就没有统计学可言。
基于上述两种信息进行统计推断被称为经典统计学,也就是基于频率学派的统计学,它的基本观点是把数据(样本)看出是来自具有一定概率分布的总体,所研究的对象是这个总体而不局限于数据本身。随着经典统计学的持续发展与广泛应用,它本身的缺陷也逐渐暴露出来。
- 先验信息
即在抽样之前有关统计问题的一些信息,一般来说,先验信息主要来源于经验和历史资料,先验信息在日常生活中也经常可见,不少人在自觉地或不自觉的使用它。譬如一位常喝牛奶加茶的妇女声称,给她一杯奶茶,她能辨别出先倒进杯子里的是茶还是牛奶。对称英国统计学家做了10次试验,结果这位妇女给出的答案都是正确的。在这个试验中假如被实验者是在猜测,每次成功的概率为0.5,那么10次都猜中的概率为=0.0009766,这是一个很小的概率,几乎是不可能发生的。
基于上述三种信息(总体信息,样本信息和先验信息)进行统计推断被称为贝叶斯统计学,它与经典统计学的主要区别在于是否利用先验信息。贝叶斯学派的最基本观点是:任何一个未知变量都可以看作是一个随机变量,应该用一个概率分布去描述对
的未知状况
贝叶斯理论的数学定义

其中A,B表示事件,P(B) ≠ 0。
P(A|B):后验概率(posterior),它是一个条件概率,表示当事件B发生时事件A发生的概率。
P(B|A):似然/可能性(likelihood),它是一个条件概率,表示当事件A发生时事件B发生的概率。

P(A):先验概率(prior),它表示事件A发生的概率。
P(B):边缘概率(marginal),它表示当事件B发生的概率。
其他参考书上的贝叶斯定义,给大家参考一下:

贝叶斯定理的可视化表示:
由两个事件(A,B)的树图叠加的可视化贝叶斯定理。
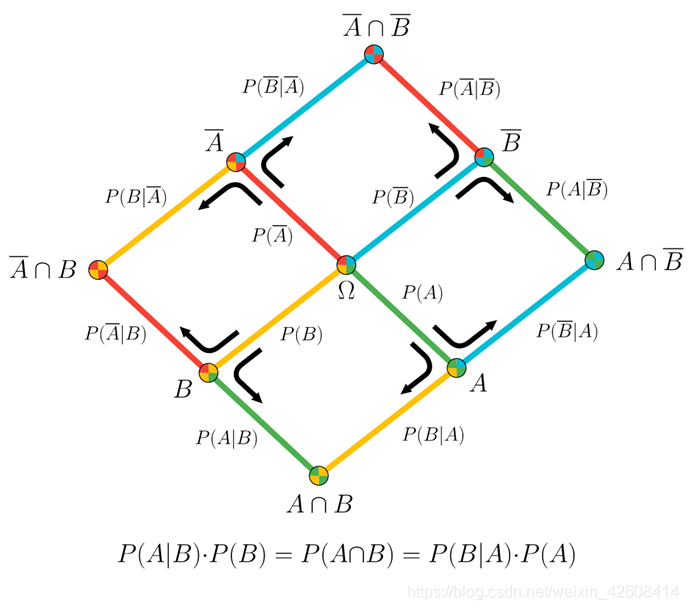
贝叶斯公式告诉我们如何计算后验概率即求P(A|B),但是在大多数场景中在计算P(A|B)之前我们已经知道了P(B|A)的值,因此这实际上就变成了:知道了似然求后验概率即P(B|A) -> P(A|B),下面我举一个用手工计算贝叶斯公式的方法,手工计算我们一般采用概率树的方法来计算。
在美国军队中早期艾滋病(HIV)检测主要通过ELISA和Western blot 这两种方法来检测,步骤如下:
- 首选进行ELISA检测
- 如果检测结果为阳性(+),再进行至少两轮的ELISA检测
- 如果出现阳性,再进行两次Western blot 检测
- 只有当两次Western blot检测结果都为阳性(+), 才最终确认感染HIV
注:我们用+和 - 来表示阳性和阴性的检测结果
已知数据:
当ELISA检测时我们已知我们的检测仪器对于已经感染HIV的患者,它检测准确率(精度)为:93%,对于那些没有感染HIV的人,它的检测准确率(精度)为:99% 即:
P( + | HIV ) = 0.93
P( - | No HIV ) = 0.99
当Western blot检测时我们已知我们的检测仪器对于已经感染HIV的患者,它检测准确率(精度)为:99.9%,对于那些没有患HIV的人,它的检测准确率(精度)为:99.1% 即:
P( + | HIV ) = 0.999
P( - | No HIV ) = 0.991
HIV的流行度(先验概率):1.48/1000(平均1000人中有1.48人感染HIV),即 P(HIV)=0.00148. 现在我们要求:
P( HIV | ELISA +) = ?,即如果首轮ELISA检测结果为阳性,实际患HIV的概率是多少?
这里很多人可能会混淆一个概念:既然知道了ELISA仪器检测的准确率为93%,那么检测结果为阳性的概率也应该是93%,其实这是不正确的,仪器的准确率(精度)并不能等于检测结果的准确率(概率)。
这里我们已经知道了四个似然值和一个先验值,下面我们可以通过概率树的方法来计算后验概率P( HIV | ELISA +):

P(HIV and +)=P(HIV)×P(+|HIV)=0.00148*0.93=0.001376
P(no HIV and +)=P(no HIV )×P(+|no HIV)=0.99852*0.01=0.009985
P(HIV | +)=P(HIV and +) / P(+)=0.001376/(0.001376+0.009985)=0.12
结论:首轮ELISA检测结果为阳性,实际感染艾滋病的概率仅为:12%
尽管ELISA的仪器检测精度为93%,但是当首轮检测结果为阳性时实际患HIV的概率只有12%,可见仪器的准确率并不等于检测结果的准确率即似然(likelihood) ≠ 后验概率(posterior)。
这里再说明一下,在手工计算后验概率时,似然后先验概率一般都是已知的,唯一要计算的就是边缘概率即贝叶斯公式中的分母那一项,边缘概率的计算也是贝叶斯计算中的难道和重点。对于不同类型的随机变量,边缘概率的计算也不一样,对于离散型随机变量一般可以通过画概率树然后用累加的方法来计算边缘概率,而对于连续型的随机变量(如正太分布等)就不那么简单了,一般要通过积分的形式来计算边缘概率,这里也不再展开讨论,这里我给大家推荐两本有关贝叶斯统计的书籍,一本是学院派的,一本是实战派的,仅供大家参考:

贝叶斯统计实战
下面我们进入本文的主题,贝叶斯的实战这里我们使用了两个PyMC3和 ArviZ这两个库,其中PyMC3是一个语法非常简单的用于概率编程的python库,而ArviZ则可以帮我们解释和可视化后验分布。这里我们将贝叶斯方法运用在一个实际问题上,你将会看到我是如何定义先验概率,如何创建概率模型,如何计算后验概率分布。
实现贝叶斯方法的一般步骤
- 了解数据,建立先验和似然
- 利用先验和似然在原始数据的基础上更新模型,得到后验概率分布
- 使用后验概率更新先前的先验概率,循环迭代执行第2步骤,直至后验概率趋于收敛。
数据
我们的数据来自于西班牙的高铁票价定价数据集,你可以在这里下载.
from scipy import stats
import arviz as az
import numpy as np
import matplotlib.pyplot as plt
import pymc3 as pm
import seaborn as sns
import pandas as pd
from theano import shared
from sklearn import preprocessing
print('Running on PyMC3 v{}'.format(pm.__version__))
df = pd.read_csv('./data/renfe.csv')
df.drop('Unnamed: 0', axis = 1, inplace=True)
df = df.sample(frac=0.01, random_state=99)
df.head(3)
我们查看一下数据集中各个变量的类型:

我们看到start_date和end_date都是字符串类型(object),这是不正确的,我们需要将 start_date和end_date转换成datetime类型。
for i in ['start_date', 'end_date']:
df[i] = pd.to_datetime(df[i])下面我们查看数据中是否存在缺失值的情况:
df.isnull().sum()/len(df)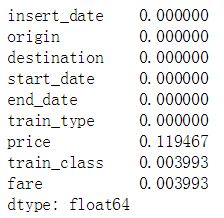
我们看到price、train_class、和fare这三个变量存在缺失值。因此我们需要对缺失值进行填充。方法是对于分类型变量(object)我们用最频繁出现的值(mode)来填充缺失值 , 对于float类型的变量price我们用其对应的票价类型(fare)的均值来填充缺失值:
df['train_class'] = df['train_class'].fillna(df['train_class'].mode().iloc[0])
df['fare'] = df['fare'].fillna(df['fare'].mode().iloc[0])
df['price'] = df.groupby('fare').transform(lambda x: x.fillna(x.mean()))
df.shape![]()
高斯推断
票价price是我们的目标变量,这里我们要对price变量进行建模,首先我们要查看price分布,我们使用ArviZ的kde图查看price的分布和密度情况:
az.plot_kde(df['price'].values, rug=True)
plt.yticks([0], alpha=0);
我们看到price呈现出类似正太分布(高斯分布)的形状,大部分数据集中在0-100这个区间,少量的极端数据的price大于150 .
正太分布有两个参数均值()和标准差(
),假如我们的kde图对price的描述是正确的,那么price中也包含了这
和
这两个参数。下面我们要做的就是要想办法找出
和
这两个参数的值。所使用的方法就是前面所接受的贝叶斯公式,首先我们要设置
和
的先验概率分布。
模型
我们将使用PyMC3库在price变量上实现一个高斯推断,因为不知道和
的值,所以我们要设置
和
的先验概率以及似然函数。
- 均值
的先验概率:
- 标准差
的先验概率:
- 似然函数的选择: y是一个观测变量,表示由参数为μ和σ的正态分布所产生的数据。
- 使用NUTS抽样,抽样1000个后验样本。
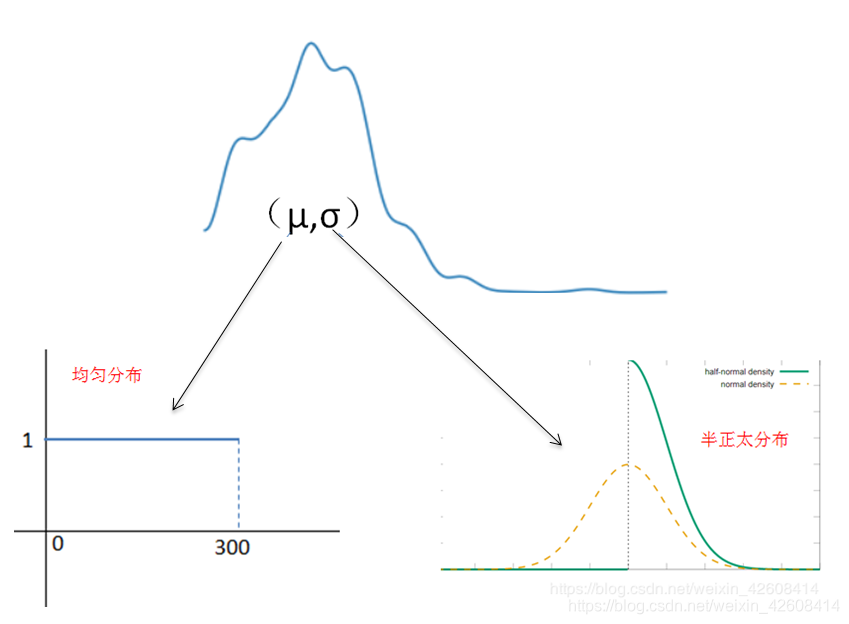
接下来我们使用PyMC3来创建一个设置了上述初始条件的贝叶斯模型:
with pm.Model() as model_g:
μ = pm.Uniform('μ', lower=0, upper=300)#设置μ的先验概率服从均匀分布
σ = pm.HalfNormal('σ', sd=10)#设置σ的先验概率服从半正太分布
y = pm.Normal('y', mu=μ, sd=σ, observed=df['price'].values) #设置似然y,表示由参数为μ和σ的正态分布所产生的数据。
trace_g = pm.sample(1000, tune=1000)#抽样1000个后验样本。
这里说明一下抽样的过程所做的工作就是“实现贝叶斯方法的一般步骤”中的第二步和第三步。通过先验概率和数据得到后验概率,再通过后验概率来更新先验概率,如此循环往复,直至后验概率收敛。
接下来我们ArviZ来可视化模型的抽样过程,我们使用arviz跟踪图来实现可视化:
az.plot_trace(trace_g); 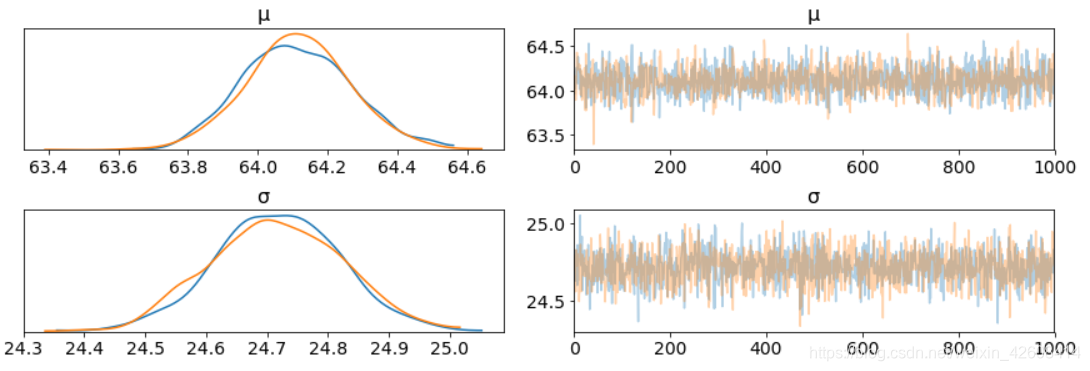
这里我们要注意两点:
- 上面左边的KDE图中,X轴表示我们的参数
- 上面右边的图中,在采样期间的每个步骤中获得单独的采样值。 从跟踪图中,我们可以直观地从后验得到合理的值。
- 我们对各个参数(左)的采样过程似乎很好地收敛(没有大的漂移)。
- 每个变量的最大后验估计(左侧分布中的峰值)非常接近真实参数。
下面我们可以画出参数的联合概率分布图:
az.plot_joint(trace_g, kind='kde', fill_last=False);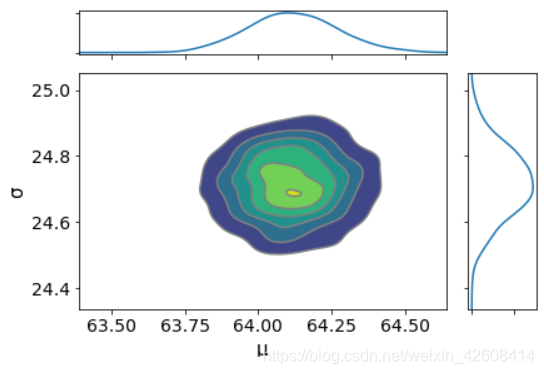
从上图中我们可以看出参数和
不存在任何相关性。这非常好,说明这两个参数是相互独立的,不存在线性相关。
下面我们还可以看一下每个参数的后验分布的摘要信息:
az.summary(trace_g)
根据上面的摘要信息,我们来看一下 参数和
的后验分布的最高后验密度(HDP)图
az.plot_posterior(trace_g);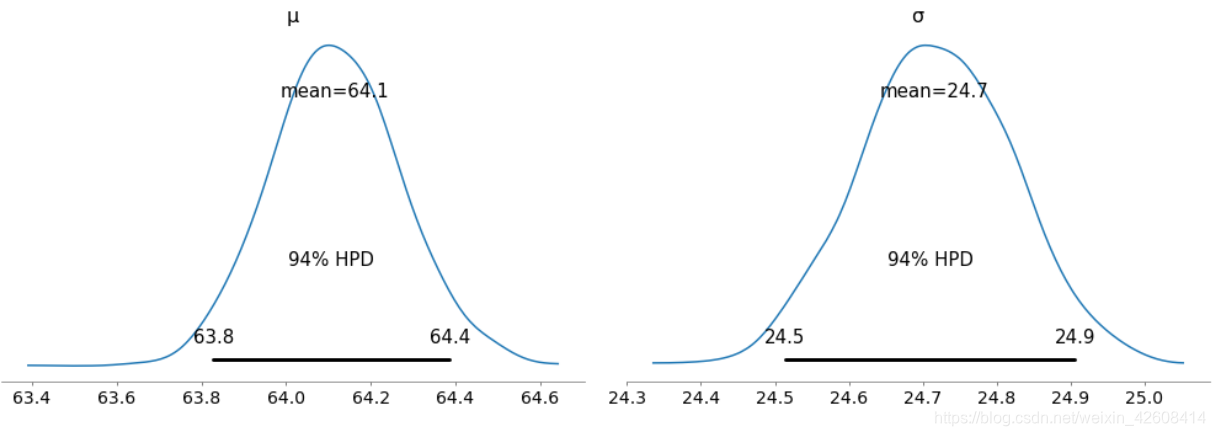
- 与经典统计学的统计推断不同,在贝叶斯推断中我们会得到参数的整个概率分布。而基于频率派的经典统计学则认为参数的概率要么是0,要么是1,只有这两种可能性,参数不存在概率分布。
- ArviZ画的参数的后验分布图中HPD的默认值是94%。
- 请注意,最高后验密度(HPD)可信区间与置信区间不同.
- 当均值位于63.8至64.4的区间内时获得了94%的概率,当标准差位于24.5至24.9时获得了94%的概率。
我们可以使用Gelman Rubin测试来验证后验概率是否收敛性。 当接近1.0的时意味着收敛。

计算遗漏信息(BFMI)的估计贝叶斯分数。关于BFMI可以参考这篇论文. 如果BFMI的值小于0.2则表示采样不良。 但是,此阈值是临时的,可能会发生变化。如果想更深入了解请看这篇文章 .
bfmi = pm.bfmi(trace_g)
max_gr = max(np.max(gr_stats) for gr_stats in pm.gelman_rubin(trace_g).values())
(pm.energyplot(trace_g, legend=False, figsize=(6, 4)).set_title("BFMI = {}\nGelman-Rubin = {}".format(bfmi, max_gr)));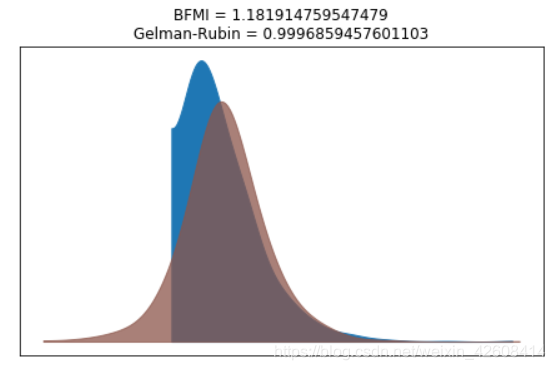
我们的模型收敛的很好,Gelman Rubin值为0.999非常接近1,这非常好。
后验预测的检验
- 后验预测的检验是验证模型的好方法。我们的想法是让我们的模型使用来自于后验的参数,然后产生数据。
- 现在我们已经计算了后验,我们将说明如何使用模拟结果来推导预测结果。
- 下面我们要从trace中做1000次随机抽样,每个样本将由7259个随机数生成一个正太分布,所以总共有1000个正太分布。每个正太分布的参数来自于该样本中指定的μ和σ。
ppc = pm.sample_posterior_predictive(trace_g, samples=1000, model=model_g)
np.asarray(ppc['y']).shape
现在ppc中包含了1000个正太分布,每个正太分布来自于后验中的不同参数。
_, ax = plt.subplots(figsize=(10, 5))
ax.hist([y.mean() for y in ppc['y']], bins=19, alpha=0.5)
ax.axvline(df.price.mean())
ax.set(title='Posterior predictive of the mean', xlabel='mean(x)', ylabel='Frequency');
推断出来的均值非常接近实际铁路票价(price)平均值。
组间的均值差异比较
我们可能对不同票价类型(fare)的车票价格比较感兴趣。 接下来我们将研究不同票价类型的车票价格之间的差异。 为了比较票价类别,我们要研究一下每种票价类型的均值。 由于我们使用的是贝叶斯模型,我们可以获得票价类别之间均值差异的后验分布。为此我们要创建3个变量
- price,代表车票价格
- idx,表示经过编码后的票价类型(fare)
- groups,表示6个不同的票价类型(fare)。

我们看一下每种票价类型的价格分布:
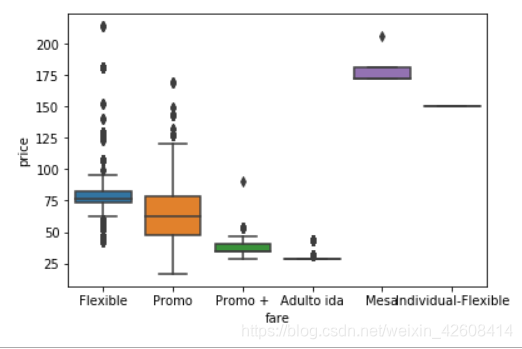
接下来我们创建3个变量
price = df['price'].values
idx = pd.Categorical(df['fare'],
categories=['Flexible', 'Promo', 'Promo +', 'Adulto ida', 'Mesa', 'Individual-Flexible']).codes
groups = len(np.unique(idx))我们看到票价类型一共有6种,接下来我们要一个组模型来比较各组的price的均值差异,这个组模型和我们之前创建的贝叶斯模型类似,只不过这里需要抽样的和
是两组向量,其中的值代表了6组票价类型的均值和标准差,这个之前的模型有点差异,之前的
和
是2个标量,表示price的均值和标准差。
with pm.Model() as comparing_groups:
μ = pm.Normal('μ', mu=0, sd=10, shape=groups) #设置μ的初始先验分布为正太分布
σ = pm.HalfNormal('σ', sd=10, shape=groups) )#设置σ的初始先验分布为正太分布
y = pm.Normal('y', mu=μ[idx], sd=σ[idx], observed=price) #设置似然变量y
trace_groups = pm.sample(5000, tune=5000)
az.plot_trace(trace_groups);
我们产生了6组的后验参数,受到本文篇幅的限制就不再这里展示6组后验的分布了,下面我们对这6组后验参数创建一个摘要:
flat_fares = az.from_pymc3(trace=trace_groups)
fares_gaussian = az.summary(flat_fares)
fares_gaussian
这里我们可以看到各组的和
的均值的差异还是非常明显的。为了更加清晰的展示差异,我们需要对差异的分布进行可视化,这里我们将
两两之间的差和
两两之间的差定义我它们的差异。
- 对于两组均值的比较我们一般用效应量(cohen'd)指标来比较均值间的差异。
- 优势概率(probability of superiority/ps)定义为从一个组中随机获取的数据的值大于从另一个组中随机获取的数据的概率。
dist = stats.norm()
_, ax = plt.subplots(5, 2, figsize=(20, 12), constrained_layout=True)
comparisons = [(i, j) for i in range(6) for j in range(i+1, 6)]
pos = [(k, l) for k in range(5) for l in (0, 1)]
for (i, j), (k, l) in zip(comparisons, pos):
means_diff = trace_groups['μ'][:, i] - trace_groups['μ'][:, j]
d_cohen = (means_diff / np.sqrt((trace_groups['σ'][:, i]**2 + trace_groups['σ'][:, j]**2) / 2)).mean()
ps = dist.cdf(d_cohen/(2**0.5))
az.plot_posterior(means_diff, ref_val=0, ax=ax[k, l])
ax[k, l].set_title(f'$\mu_{i}-\mu_{j}$')
ax[k, l].plot(
0, label=f"Cohen's d = {d_cohen:.2f}\nProb sup = {ps:.2f}", alpha=0)
ax[k, l].legend();
从上图我们可以看到的两两之间的差异的分布,我们看到所有差异的94%HPD的差异的均值都不包含0,差异的均值最小是6.1,最大是63.5,这说明不能类型(fare)票价price均值的差异是显著的,且不是由于偶然性造成的。反过来说,假如有两个
的差异的94%HPD包含了0值,这说明这两个
的差异是由偶然性造成的,它们的均值存在相等可能性。对于上述所有示例,我们可以排除零差异,这可以证明客户是根据不同的票价类别(fare)来购买车票的。
贝叶斯分层线性回归
我们想建立一个模型来估算每种票价类型的铁路车票价格,同时估算所有票价类型的价格。 这种类型的模型称为分层模型或多级模型。首先我们要对分类型变量车票类型(fare)以及火车类型(train_type)进行编码,因为我们认为除了车票类型(fare)之外,火车类型(train_type)也可能对price产生影响。因此我们的模型中也需要加入火车类型(train_type)这个变量。
def replace_fare(fare):
if fare == 'Adulto ida':
return 1
elif fare == 'Promo +':
return 2
elif fare == 'Promo':
return 3
elif fare == 'Flexible':
return 4
elif fare == 'Individual-Flexible':
return 5
elif fare == 'Mesa':
return 6
df['fare_encode'] = df['fare'].apply(lambda x: replace_fare(x))
label_encoder = preprocessing.LabelEncoder()
df['train_type_encode']= label_encoder.fit_transform(df['train_type'])
train_type_names = df.train_type.unique()
train_type_idx = df.train_type_encode.values
n_train_types = len(df.train_type.unique())
df[['train_type', 'price', 'fare_encode']].head()
分层模型
下面我们要使用上面这些变量来建立贝叶斯的线性回归模型:
with pm.Model() as hierarchical_model:
# 指定初始的模型参数的先验概率分布
α_μ_tmp = pm.Normal('α_μ_tmp', mu=0., sd=100)
α_σ_tmp = pm.HalfNormal('α_σ_tmp', 5.)
β_μ = pm.Normal('β_μ', mu=0., sd=100)
β_σ = pm.HalfNormal('β_σ', 5.)
# 列车类型特定的模型参数
α_tmp = pm.Normal('α_tmp', mu=α_μ_tmp, sd=α_σ_tmp, shape=n_train_types)
β = pm.Normal('β', mu=β_μ, sd=β_σ, shape=n_train_types)
# 模型误差先验,半柯西分布
eps = pm.HalfCauchy('eps', 5.)
#模型定义
fare_est = α_tmp[train_type_idx] + β[train_type_idx]*df.fare_encode.values
# 数据似然
fare_like = pm.Normal('fare_like', mu=fare_est, sd=eps, observed=df.price)
hierarchical_trace = pm.sample(2000, tune=2000, target_accept=.9)
pm.traceplot(hierarchical_trace, var_names=['α_μ_tmp', 'β_μ', 'α_σ_tmp', 'β_σ', 'eps']); 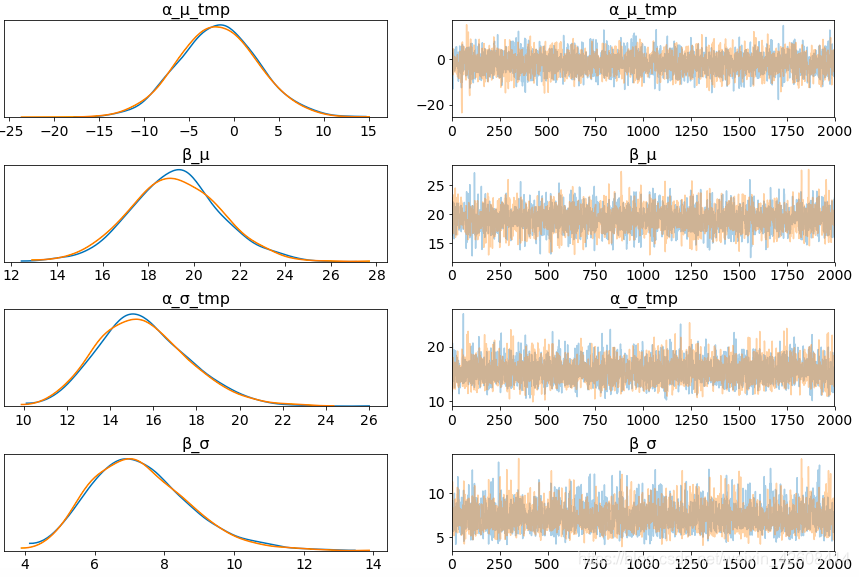

上图中左边一列中α_μ_tmp表示火车类型(train_type)权重均值分布,β_μ表示各个不同票价类型(fare)的价格变化的分布。由于火车类型(train_type)有16种,我们查看前5种火车类型在模型中的权重分布。


从上图可知火车类型之间的价格存在很大差异; 分布的宽度与我们在每个参数估计中的置信度有关 - 每种火车类型的观察值越多,我们的置信度就越高。
将参数的不确定性的量化,是贝叶斯模型最擅长做的, 对于不同火车类型的票价,我们有一个贝叶斯置信区间。
az.plot_forest(hierarchical_trace, var_names=['α_tmp', 'β'], combined=True);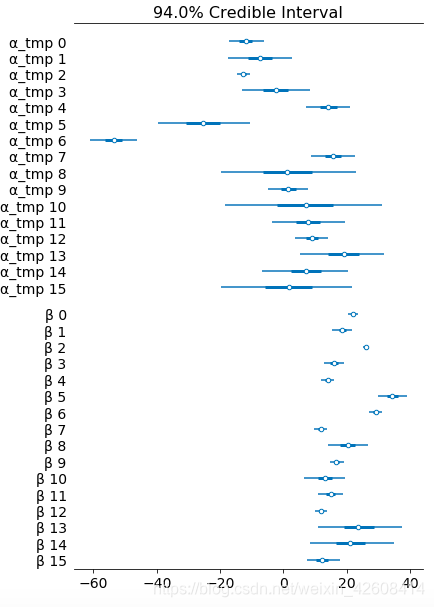
最后我们计算一下R^2
ppc = pm.sample_posterior_predictive(hierarchical_trace, samples=2000, model=hierarchical_model)
az.r2_score(df.price.values, ppc['fare_like'])
总结
本文对经典统计学和贝叶斯统计做了介绍,并简略说明的他们之间的差异,并通过一个例子来向大家介绍如何通过概率树的方法来手工计算贝叶斯公式的后验概率。最后我通过一个实战项目来对火车票价进行价格贝叶斯建模估算了价格的均值和标准差,并且我们还对组间价格均值差异进行了分析和比较,最后我们还对票价类型创建贝叶斯的线性规格模型。说真的贝叶斯统计要比经典统计学更加复杂,不易理解,想要搞明白贝叶斯统计需要下一番功夫才行,最后我给大家分享一些统计学和贝叶斯统计学的资源,以供大家学习。
资源分享
我非常喜欢的一门课:Statistics with R.
Probabilistic Programming & Bayesian Methods for Hackers
你可以在这里下载本文的源代码:
https://github.com/tongzm/ml-python/blob/master/Bayesian%20Statistics.ipynb
