逻辑回归又称logistic回归分析,是一种广义的线性回归分析模型,常用于数据挖掘,疾病自动诊断,经济预测等领域。逻辑回归从本质来说属于二分类问题。
二分类问题是指预测的y值只有两个取值(0或1),二分类问题可以扩展到多分类问题。例如:我们要做一个垃圾邮件过滤系统,x是邮件的特征,预测的y值就是邮件的类别,是垃圾邮件还是正常邮件。对于类别我们通常称为正类(positive class)和负类(negative class),垃圾邮件的例子中,正类就是正常邮件,负类就是垃圾邮件。
在二分类的问题中经常还会遇到不平衡类的分类问题,例如在异常值检测的应用中异常值的数量要远远小于正常值的数量、在信用卡欺诈检测的应用中涉嫌欺诈的信用卡用户数量要远远小于正常用户的数量、在用户流失预测的应用中等流失用户的数量要远远小于未流失的用户数量。在这些不平衡的二分类问题中我们所关注的重点或者说我们所需要预测的往往是那些占比教小的分类,比如
- 我们只需要能准确识别出哪些是异常值而不需要去关心正常值
- 我们只需要识别出哪些是涉嫌欺诈的信用卡用户而不用去关心正常的信用卡用户
- 我们只需要预测出哪些用将会流失而不用去关心正常用户。
在这些不平衡类的分类问题中,预测的准确率(accuracy)已经不是一个很好的评估指标,因为它会忽视小类(负类)的预测准确率,但是小类(负类)往往是我们关注的重点。此时我们应该借助于其他的评估指标如:查准率、查全率、F1等。
数据
我们的数据来自于葡萄牙银行机构的营销活动数据,该营销活动通过向用户打电话来推销银行的理财产品, 你可以在这里下载,数据中包含了41188条银行客户信息和21个字段:
- 1 - age :客户年龄(numeric)
- 2 - job : 工作类型 (分类型变量: 'admin.','blue-collar','entrepreneur','housemaid','management','retired','self-employed','services','student','technician','unemployed','unknown')
- 3 - marital : 婚姻状态 (分类型变量: 'divorced','married','single','unknown'; note: 'divorced' means divorced or widowed)
- 4 - education 文化程度(分类型变量: 'basic.4y','basic.6y','basic.9y','high.school','illiterate','professional.course','university.degree','unknown')
- 5 - default: has credit in default? (categorical: 'no','yes','unknown')
- 6 - housing: 是否有住房贷款 (分类型变量: 'no','yes','unknown')
- 7 - loan: 是否有个人贷款? (分类型变量: 'no','yes','unknown')
与打电话相关的变量:
- 8 - contact: 联系类型 (分类型变量: 'cellular','telephone')
- 9 - month: 最后一次联系的月份 (分类型变量: 'jan', 'feb', 'mar', ..., 'nov', 'dec')
- 10 - day_of_week: 最后一次联系所在的星期 (分类型变量: 'mon','tue','wed','thu','fri')
- 11 - duration: 最后一次联系的持续时间, 以秒为单位(数字)。 重要提示:此变量会严重影响输出目标变量(例如,如果持续时间= 0,则y ='否')。 然而,在电话呼叫之前不知道持续时间。 此外,在通话结束后,显然已知y。 因此,此输入仅应包括在基准目的中,如果打算采用现实的预测模型,则应将其丢弃。
其他属性:
- 12 - campaign: 与用户电话联系的次数 (numeric, 包含最后一次联系)
- 13 - pdays: 最后一次联系与前一次联系之间间隔的天数 (numeric; 999 表示之前从未联系过该客户)
- 14 - previous: 在该次营销活动之前与客户联系的次数 (numeric)
- 15 - poutcome: 上一次营销活动的结果 (categorical: 'failure','nonexistent','success')
社会和经济背景属性
- 16 - emp.var.rate: 就业变化率 - 季度指标 (numeric)
- 17 - cons.price.idx: 消费者价格指数 - 月度指标 (numeric)
- 18 - cons.conf.idx: 消费信心指数 - 月度指标 (numeric)
- 19 - euribor3m: 欧洲银行同业拆借利率3个月-每日指标(numeric)
- 20 - nr.employed: 员工人数 - 季度指标 (numeric)
输出变量 (目标变量):
- 21 - y - 客户是否订购理财产品? (0:'no',1:'yes')
%matplotlib inline
import pandas as pd
import numpy as np
from sklearn import preprocessing
import matplotlib.pyplot as plt
plt.rc("font", size=14)
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
import seaborn as sns
sns.set(style="white")
sns.set(style="whitegrid", color_codes=True)
df = pd.read_csv('./data/banking.csv', header=0)
df = df.dropna()
print(df.shape)
print(list(df.columns))
data.head()
在文化程度(education)这列中包含了很多的类别,我们需要对其进行整理,我们要将其中的basic.4y,basic.6y,basic.9y这三个类别合并为basic:
数据分析
y是我们的目标变量,当y为0时表示用户没有订购了银行的理财产品,当y为1表示用户订购了银行的理财产品。接下来我们要查看一下y的数据分布
print(df['y'].value_counts())
print(df['y'].value_counts()/len(df))
从上面的统计结果中我们看到没有订购理财产品的人数为36548,占比为88.73%,而订购理财产品的人数为4640,占比为11.2%,很明显这是一个不平衡的二分类,未订购人数远大于订购人数,但是我们需要关注的重点却是那些占比较小的未订购人数,我们的模型需要能准确预测出未订购的客户。下面我们队目标变量进行可视化。
sns.countplot(x='y',data=df, palette='hls')
plt.show()
下面我们对目标变量进行更深入的探索:
df.groupby('y').mean()
从上面的结果中我们发现:
- 购买理财商品的用户平均年龄(age)要高于未购买的用户的平均年龄
- 购买理财商品的用户的最后一次联系的平均持续时间(duration)要明显高于未购买的用户的平均持续时间
- 购买理财商品的用户的平均pdays(自上次联系客户以来的日子)要小于未购买的用户的平均pdays, 这是合理的,因为pdays越小,最后一次通话的日子越近,用户对理财产品的记忆越强,因此销售的机会就越大。
- 令人奇怪的是购买理财商品的用户的平均campaign(与用户电话联系的次数)要是小于未购买的用户的平均campaign。
接下来我们查看一些分类型变量如:job(职业),marita(婚姻),education(文化程度):


对分类型变量进行可视化
pd.crosstab(df.job,df.y).plot(kind='bar')
plt.title('购买理财产品和工作岗位分布')
plt.xlabel('Job')
plt.ylabel('数量')
我们看到不同的职业购买理财产品的数量是不一样的,admin,blue-collar,technician等职业购买的数量较多
table=pd.crosstab(df.marital,df.y)
print(table)
table.div(table.sum(1).astype(float), axis=0).plot(kind='bar', stacked=True)
plt.title('购买理财产品和婚姻状况的堆积图')
plt.xlabel('Marital Status(婚姻状态)')
plt.ylabel('客户比例') 
婚姻状态似乎和是否购买理财产品没有太大的关联
table=pd.crosstab(df.education,df.y)
print(table)
table.div(table.sum(1).astype(float), axis=0).plot(kind='bar', stacked=True)
plt.title('购买理财产品和文化程度的堆积图')
plt.xlabel('Education')
plt.ylabel('客户比例')
文化程度中illiterate的购买比例较高,但是购买人数相对较少
print(pd.crosstab(df.day_of_week,df.y))
pd.crosstab(df.day_of_week,df.y).plot(kind='bar')
plt.title('购买理财产品和星期的分布')
plt.xlabel('星期')
plt.ylabel('数量') 
星期似乎和购买理财产品没有太大的关系
print(pd.crosstab(df.month,df.y))
pd.crosstab(df.month,df.y).plot(kind='bar')
plt.title('购买理财产品和月份的分布')
plt.xlabel('月份')
plt.ylabel('数量') 
月份似乎和购买理财产品有些关联
df.age.hist()
plt.title('年龄直方图')
plt.xlabel('年龄(Age)')
plt.ylabel('频率')
大部分接受电话访问的客户的年龄分布在30-40岁之间。
print(pd.crosstab(df.poutcome,df.y))
pd.crosstab(df.poutcome,df.y).plot(kind='bar')
plt.title('购买理财产品和上一次营销活动的结果分布')
plt.xlabel('上一次营销活动的结果(Poutcome)')
plt.ylabel('数量') 
上一次营销活动的结果(Poutcome)似乎和是否购买理财产品有较强的相关性。
对分类型变量进行one-hot编码
下面我们要对数据集中的分类型变量进行one-hot编码,首先我们查看一下数据集中所有变量的信息:
df.info()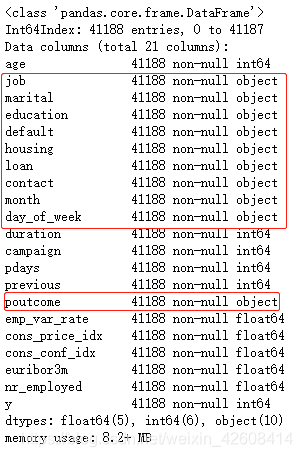
我们看到所有的object变量就是我们需要转换的分类型变量。
cat_vars=['job','marital','education','default','housing','loan','contact','month','day_of_week','poutcome']
for var in cat_vars:
cat_list='var'+'_'+var
cat_list = pd.get_dummies(df[var], prefix=var)
df=df.join(cat_list)
cat_vars=['job','marital','education','default','housing','loan','contact','month','day_of_week','poutcome']
df_vars=df.columns.values.tolist()
to_keep=[i for i in df_vars if i not in cat_vars]
df_final=df[to_keep]
print(df_final.columns.values)
df_final.head()
利用SMOTE算法进行过采用
SMOTE(Synthetic Minority Oversampling Technique),合成少数类过采样技术.它是基于随机过采样算法的一种改进方案,由于随机过采样采取简单复制样本的策略来增加少数类样本,这样容易产生模型过拟合的问题,即使得模型学习到的信息过于特别(Specific)而不够泛化(General),SMOTE算法的基本思想是对少数类样本进行分析并根据少数类样本人工合成新样本添加到数据集中。
对于不平衡类的问题,我们一般采样上采样(过采样)或下采样(负采样)策略是解决类别不平衡问题的基本方法之一。上采样即增加少数类样本的数量,下采样即减少多数类样本以获取相对平衡的数据集。大家还可以参考这篇博客(https://blog.csdn.net/nlpuser/article/details/81265614 )
想进一步了解SMOTE可以参考这篇论文(https://arxiv.org/pdf/1106.1813.pdf ),这里我们将使用python的imblearn库中的SMOTE算法(http://imbalanced-learn.org/en/stable/over_sampling.html#smote-variants )来实现过采样。
首先我们从数据集中分离出特征和标签,然后我们通过随机抽样创建训练集合测试集
X = df_final.loc[:, df_final.columns != 'y']
y = df_final.loc[:, df_final.columns == 'y']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
columns = X_train.columns接下来我们利用SMOTE算法对训练集进行过采样,采样的结果将使正样本合负样本的数量达到平衡。
算法流程如下。
(1)对于少数类中每一个样本x,以欧氏距离为标准计算它到少数类样本集中所有样本的距离,得到其k近邻。
(2)根据样本不平衡比例设置一个采样比例以确定采样倍率N,对于每一个少数类样本x,从其k近邻中随机选择若干个样本,假设选择的近邻为xn。
(3)对于每一个随机选出的近邻xn,分别与原样本按照如下的公式构建新的样本。

print('过采样之前训练集中正负样本的比例分布:')
print(y_train['y'].value_counts())
print(y_train['y'].value_counts()/len(y_train))
os = SMOTE(random_state=0)
os_data_X,os_data_y=os.fit_sample(X_train, y_train.values.ravel())
os_data_X = pd.DataFrame(data=os_data_X,columns=columns )
os_data_y= pd.DataFrame(data=os_data_y,columns=['y'])
print('-------------------------------------------')
print('过采样之后训练集中正负样本的比例分布:')
print(os_data_y['y'].value_counts())
print(os_data_y['y'].value_counts()/len(os_data_y)) 
经过SMOTE算法过采样以后,我们看法正样本合负样本的数量都已经一致了,正负样本的比例达到了平衡
特征筛选-递归特征消除
递归特征消除(Recursive Feature Elimination,RFE)(https://scikit-learn.org/stable/modules/generated/sklearn.feature_selection.RFE.html ),此算法是用来进行特征选择,RFE基于重复构建模型并选择表现最好或最差特征,并将它们放在一边,然后对剩下的特征重复这样的过程,直到所有的特征都被用完。RFE的目标是通过递归地考虑越来越小的特征集来选择特征。
df_final_vars=df_final.columns.values.tolist()
y=['y']
X=[i for i in df_final_vars if i not in y]from sklearn import datasets
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
logreg = LogisticRegression(solver='liblinear')
rfe = RFE(logreg, 20)#选择20个特征
rfe = rfe.fit(os_data_X.values, os_data_y.values.ravel())
features = list(os_data_X.columns[rfe.support_])
print('原特征数量:',os_data_X.shape[1])
print()
print('经过模型筛选后的20个特征:')
print(features)
print()
print('特征排名:')
print(rfe.ranking_)
逻辑回归
到目前为止我们有了平衡的二分类训练集,以及经过RFE筛选过的特征,接下来我们要用sklearn的逻辑回归模型来拟合我们的数据:
X=os_data_X[features]
y=os_data_y['y']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
logreg = LogisticRegression(solver='liblinear')
logreg.fit(X_train, y_train)
#在测试集上进行预测
y_pred = logreg.predict(X_test)
print('在测试集上预测的准确率: {:.2f}'.format(logreg.score(X_test, y_test)))![]()
混淆矩阵
confusion_matrix = confusion_matrix(y_test, y_pred)
sns.heatmap(confusion_matrix, annot=True, fmt='d')
F1 分数

ROC曲线
logit_roc_auc = roc_auc_score(y_test, logreg.predict(X_test))
fpr, tpr, thresholds = roc_curve(y_test, logreg.predict_proba(X_test)[:,1])
plt.figure()
plt.plot(fpr, tpr, label='Logistic Regression (area = %0.2f)' % logit_roc_auc)
plt.plot([0, 1], [0, 1],'r--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver operating characteristic')
plt.legend(loc="lower right")
plt.savefig('Log_ROC')
plt.show()
关于评估指标混淆矩阵、F1分数、ROC曲线在我之前多篇博客中都有说明,大家也可以参考这篇(https://blog.csdn.net/weixin_42608414/article/details/88344263)
本文完整代码可以在这里下载:
总结
今天我们学习了在二分类问题中如何对数据进行分析,对于分类型变量我们可以使用堆积图和柱状图来进行分析,对于数值型变量我们可以用直方图来进行分析,对于分类型变量我们还需要进行one-hot编码。对于one-hot编码也有好多种方法,今天只使用了其中的一种,但今天使用的这种one-hot方法是有点缺陷的,缺陷在于它无法适应新数据,之所以适应它是因为它写起来比较方便,便于演示。今天我们还学习了两个重要的技术:SMOTE和RFE,前者是用来平衡二分类数据集的,它通过过采样的方法来增加较小分类的样本数量,从而使正负样本数量可以达到平衡,后者是通过递归特征消除的方法来从特征集中提炼有价值的特征。最后我们通过sklearn的逻辑回归模型来拟合训练集,并使用了混淆矩阵,F1分数,ROC曲线等评估指标来评估我们的模型,好了,今天就到这吧,祝大家中秋节快乐!
