前言
(1)Mahout框架中cf.taste包实现了推荐算法引擎,它提供了一套完整的推荐算法工具集,同时规范了数据结构,并标准化了程序开发过程。
并且,通过使用 Apache Hadoop 库,Mahout 可以有效地扩展到Hadoop 集群 。
(2)Mahout是用来干嘛的?
- 推荐引擎
服务商或网站会根据你过去的行为为你推荐书籍、电影或文章。 - 聚类
Google news使用聚类技术通过标题把新闻文章进行分组,从而按照逻辑线索来显示新闻,而并非给出所有新闻的原始列表。 - 分类
雅虎邮箱基于用户以前对正常邮件和垃圾邮件的报告,以及电子邮件自身的特征,来判别到来的消息是否是垃圾邮件。
Mahout推荐引擎的packages
common: 公共类包括,异常,数据刷新接口,权重常量
eval: 定义构造器接口,类似于工厂模式
model: 定义数据模型接口
neighborhood: 定义近邻算法的接口
recommender: 定义推荐算法的接口
similarity: 定义相似度算法的接口
transforms: 定义数据转换的接口
hadoop: 基于hadoop的分步式算法的实现类
impl: 单机内存算法实现类
从上面的package情况,我可以粗略地看出推荐引擎分为5个主要部分组成:数据模型,相似度算法,近邻算法,推荐算法,算法评分器。
从数据处理能力上,算法可以分为:单机内存算法,基于hadoop的分步式算法。
前期我准备使用基于单机内存的算法,后期可能会尝试进行分布式的部署
开发过程

我们调用算法的程序,要用到4个对象:DataModel, UserSimilarity, NearestNUserNeighborhood, Recommender。
(1)DataModel 是用户喜好信息的抽象接口,它的具体实现支持从任意类型的数据源抽取用户喜好信息。Taste 默认提供 JDBCDataModel 和 FileDataModel,分别支持从数据库和文件中读取用户的喜好信息。
(2)UserSimilarity 和 ItemSimilarity 。UserSimilarity 用于定义两个用户间的相似度,它是基于协同过滤的推荐引擎的核心部分,可以用来计算用户的“邻居”,这里我们将与当前用户口味相似的用户称为他的邻居。 ItemSimilarity 类似的,计算Item之间的相似度。
(3)UserNeighborhood 用于基于用户相似度的推荐方法中,推荐的内容是基于找到与当前用户喜好相似的邻居用户的方式产生的。UserNeighborhood 定义了确定邻居用户的方法,具体实现一般是基于 UserSimilarity 计算得到的。
(4)Recommender 是推荐引擎的抽象接口,Taste 中的核心组件。程序中,为它提供一个 DataModel ,它可以计算出对不同用户的推荐内容。实际应用中,主要使用它的实现类 GenericUserBasedRecommender 或者 GenericItemBasedRecommender ,分别实现基于用户相似度的推荐引擎或者基于内容的推荐引擎。
(5)RecommenderEvaluator :评分器。
(6) RecommenderIRStatsEvaluator :搜集推荐性能相关的指标,包括准确率、召回率等等。
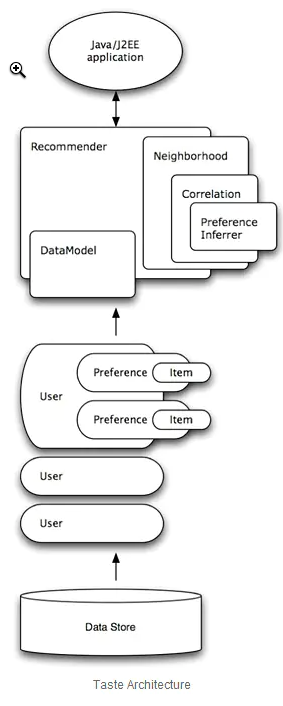
数据模型DataModel
Mahout的推荐引擎的数据模型,以DataModel接口为父类。
通过“策略模式”匹配不同的数据源,支持File, JDBC(MySQL, PostgreSQL), NoSQL(Cassandra, HBase, MongoDB)。

在这里,我昨天实现好了数据的抽取,提前已经实现了第一种的数据模型,存入了csv文件中,可以直接通过DataModel接口进行模型的建立。
相似度算法工具集
相似度算法分为2种
(1)基于用户(UserCF)的相似度算法
基于用户的协同过滤,通过不同用户对物品的评分来评测用户之间的相似性,基于用户之间的相似性做出推荐。简单来讲就是:给用户推荐和他兴趣相似的其他用户喜欢的物品。

基于用户的 CF 的基本思想相当简单,基于用户对物品的偏好找到相邻邻居用户,然后将邻居用户喜欢的推荐给当前用户。计算上,就是将一个用户对所有物品的偏好作为一个向量 来计算用户之间的相似度,找到 K 邻居后,根据邻居的相似度权重以及他们对物品的偏好,预测当前用户没有偏好的未涉及物品,计算得到一个排序的物品列表作为推荐。图 2 给出了一个例子,对于用户 A,根据用户的历史偏好,这里只计算得到一个邻居 – 用户 C,然后将用户 C 喜欢的物品 D 推荐给用户 A。
*对应到我们的系统:可以根据用户对标签或者分类的点击次数,进行建模,计算用户之间的相似度,找到K个邻居后,根据邻居的相似度权重以及他们对标签或者分类的偏好,预测当前用户没有偏好的未涉及标签或者分类,计算得到一个排序作为推荐。

(2)基于物品(ItemCF)的相似度算法
于item的协同过滤,通过用户对不同item的评分来评测item之间的相似性,基于item之间的相似性做出推荐。简单来讲就是:给用户推荐和他之前喜欢的物品相似的物品。

基于物品的 CF 的原理和基于用户的 CF 类似,只是在计算邻居时采用物品本身,而不是从用户的角度,即基于用户对物品的偏好找到相似的物品,然后根据用户的历史偏好,推荐相似的物品给他。从计算 的角度看,就是将所有用户对某个物品的偏好作为一个向量来计算物品之间的相似度,得到物品的相似物品后,根据用户历史的偏好预测当前用户还没有表示偏好的 物品,计算得到一个排序的物品列表作为推荐。图 3 给出了一个例子,对于物品 A,根据所有用户的历史偏好,喜欢物品 A 的用户都喜欢物品 C,得出物品 A 和物品 C 比较相似,而用户 C 喜欢物品 A,那么可以推断出用户 C 可能也喜欢物品 C。
*对应到我们的系统:从标签或者分类的角度出发,将用户对于标签或者分类的偏好作为一个向量来计算标签或者分类之间的相似度,得到相似度后,根据用户历史的点击数据预测当前用户还没有太多点击的标签或分类。

相似度计算
(1)EuclideanDistanceSimilarity: 欧氏距离相似度
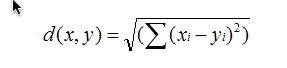
原理:利用欧式距离d定义的相似度s,s=1 / (1+d)。
范围:[0,1],值越大,说明d越小,也就是距离越近,则相似度越大。
说明:同皮尔森相似度一样,该相似度也没有考虑重叠数对结果的影响,同样地,Mahout通过增加一个枚举类型(Weighting)的参数来使得重叠数也成为计算相似度的影响因子。
(2)PearsonCorrelationSimilarity: 皮尔森相似度
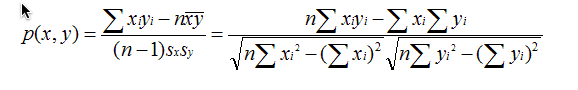

(3)UncenteredCosineSimilarity: 余弦相似度
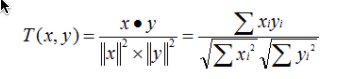
原理:多维空间两点与所设定的点形成夹角的余弦值。
范围:[-1,1],值越大,说明夹角越大,两点相距就越远,相似度就越小。
说明:在数学表达中,如果对两个项的属性进行了数据中心化,计算出来的余弦相似度和皮尔森相似度是一样的,在mahout中,实现了数据中心化的过程,所以皮尔森相似度值也是数据中心化后的余弦相似度。另外在新版本中,Mahout提供了UncenteredCosineSimilarity类作为计算非中心化数据的余弦相似度。
(4)TanimotoCoefficientSimilarity: Tanimoto系数相似度
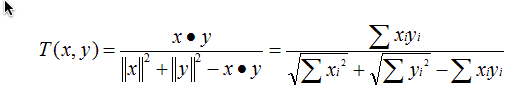
原理:又名广义Jaccard系数,是对Jaccard系数的扩展,等式为
范围:[0,1],完全重叠时为1,无重叠项时为0,越接近1说明越相似。
说明:处理无打分的偏好数据。
相似度算法介绍,摘自
http://www.cnblogs.com/dlts26/archive/2012/06/20/2555772.html
近邻算法工具集
近邻算法只对于UserCF适用,通过近邻算法给相似的用户进行排序,选出前N个最相似的,作为最终推荐的参考的用户。

近邻算法分为2种:
NearestNUserNeighborhood:指定N的个数,比如,选出前10最相似的用户。
ThresholdUserNeighborhood:指定比例,比如,选择前10%最相似的用户。
推荐算法工具集
(1)Recommender接口中的方法解释:
recommend(long userID, int howMany): 获得推荐结果,给userID推荐howMany个Item
recommend(long userID, int howMany, IDRescorer rescorer): 获得推荐结果,给userID推荐howMany个Item,可以根据rescorer对结构重新排序。
estimatePreference(long userID, long itemID): 当打分为空,估计用户对物品的打分
setPreference(long userID, long itemID, float value): 赋值用户,物品,打分
removePreference(long userID, long itemID): 删除用户对物品的打分
getDataModel(): 提取推荐数据
(2)通过继承关系到Recommender接口的子类:
GenericUserBasedRecommender: 基于用户的推荐算法
GenericItemBasedRecommender: 基于物品的推荐算法
KnnItemBasedRecommender: 基于物品的KNN推荐算法
SlopeOneRecommender: Slope推荐算法
SVDRecommender: SVD推荐算法
TreeClusteringRecommender:TreeCluster推荐算法
了解到SlopeOneRecommender与TreeCluster推荐算法已经在新版本中删除了,系统只用了前两个推荐算法
总结
有了这些类之后,就可以进行一些推荐算法的尝试了。
先构造数据集,然后计算相似度,然后找到相似的topk,最后进行推荐。