darknet 框架中YOLO权重文件的种类及存储结构
在darknet框架中YOLO权重文件用于存储神经网络中的各种权重,是二进制文件。
文件类型
该类型文件后缀有3类,一类是“.weight”,一类是“.backup”,还有一类是数字(文件名如“darknet53.conv.74”、“yolov3-tiny.conv.15”)。
第一类:后缀“.weight”和“.backup”文件
它们其实是一类文件,由于都是二进制文件,后缀只是用于起到一个区分的作用。
文件的生成参考detector.c文件train_detector函数中的代码:
//每100批次保存一次weight,保存成“.backup"文件,每1000次更新一次
if(i%100==0){
#ifdef GPU
if(ngpus != 1) sync_nets(nets, ngpus, 0);
#endif
char buff[256];
sprintf(buff, "%s/%s.backup", backup_directory, base);
save_weights(net, buff);//将net中更新的weight存在backup文件中
}
//当训练批次是10000的整数倍或者1000以内的100的整数倍时,生成一个后缀为“.weight”的文件,文件标注训练次数累积保存,但是第1000就只能保存成“.backup"文件了,并且每100批次更新一遍,直到第10000次
if(i%10000==0 || (i < 1000 && i%100 == 0)){
#ifdef GPU
if(ngpus != 1) sync_nets(nets, ngpus, 0);
#endif
char buff[256];
sprintf(buff, "%s/%s_%d.weights", backup_directory, base, i);
save_weights(net, buff);
}
第二类:预训练权重模型文件
这类权重文件就是“darknet53.conv.74”等文件,又称为backbone文件。“darknet53”代表采用了(实际拥有52层卷基层的)darknet53结构。“conv”表示这是一个卷积权重文件,其实对于YOLO模型来说,权重全部都是卷基层的权重,全连接也是通过卷积实现的。“74”表示骨干网络实际有74层,包括卷基层,池化层,shortcut层(用于构成残差结构)。
区别
这两类文件区别在于第二类仅保留了第一类的backbone结构,用于各类模型的迁移学习。Backbone结构决定你的模型是YOLOv1,YOLOv2,还是YOLOv3的结构,是大(作)家(者)公(研)认(究)的成熟模型。第二类文件可以由darknet.c文件中的partial函数实现,以YOLOv3 tiny模型为例,使用“yolov3-tiny.conv.15.weight”生成“yolov3-tiny.conv.15”,它的命令行操作是(文件路径自行确定):
beimingke@beimingke:~/darknet_captcha$ ./darknet/darknet partial yolov3-tiny.cfg yolov3-tiny.conv.15.weight yolov3-tiny.conv.15 15
注意:结构是:
darknet partial [cfg] [.weight] [outputfile] [layernumber]
partial函数的源代码是:
void partial(char *cfgfile, char *weightfile, char *outfile, int max)
{
gpu_index = -1;
network *net = load_network(cfgfile, weightfile, 1);
save_weights_upto(net, outfile, max);
}
其中max表示截取的层数,在save_weights_upto函数(parse.c)中对应cutoff参数。 load_network函数(network.c)中的参数“1”对应原函数中clear形参,用于清除原来训练的yolov3-tiny.conv.15.weight文件中的seen参数,将其设置为0,这个参数表示训练这个权重文件使用过的图片数(含循环使用)。
当需要使用自己的数据集训练一个权重模型时,就可以使用backbone,同时还可以在“.cfg”配置文件任意修改backbone以外的设置。
你可能会问了,backbone既然是从原来的“.weight”文件中截取的,那训练时load权重时会不会参数不够?不会的,因为load“.weight”文件时,是依据“.cfg”文件的格式,当“.weight”数据流读取完还不够时,就在接续的内存中按照相应的格式继续读取随机数字,正好可以很好的作为权重初始值。如果没有weight文件也不要紧,只要是一个比backbone大的weight文件甚至是按照相应格式存储的随机数字文件都可以胜任,因为你给每个权重位置上都赋了一个不对称的初始值,只不过要训练的时间长一点罢了。
文件结构
说了半天,“.weight”文件都是怎么组成的呢?结构如下:
版本号参数major(int型,4字节)
版本号参数minor(int型,4字节)
版本号参数revision(int型,4字节)
训练过的图片个数seen(size_t型,64位操作系统下8字节)
卷积层的参数:卷积权重(float型,单个参数4字节),每层中包括:
偏置参数l.biases,这个偏置包含卷基层本身的偏置的成分,也包含归一化的偏置的成分,个数l.n,即卷积核或特征提取映射层(feature map)个数;
归一化尺度变换系数l.scales,个数l.n;
每层滚动均值l.rolling_mean,个数l.n和每层滚动方差l.rolling_variance,个数l.n。这个滚动均值和滚动方差利用batchnorm_layer.c中的forward_batchnorm_layer计算。之所以叫“滚动”(rolling)是因为在计算的时候,weight文件中上一次训练的参数值×0.99+新计算的均值或权重×0.01进行滚动更新。
个数为l.cl.nl.size.l.size+4l.n,占存储空间(l.cl.nl.size.l.size+4l.n)*4字节。
对于YOLOv3,无论是tiny还是完整还是voc(只说官方软件包中的),都是卷基层,所以weight文件结构后面就顺序按照卷基层的参数进行排列,没有任何表示格式、间隔、标记等的符号,所有的标记都在cfg文件中读取。当然其他类型的网络根据实际情况进行判断,大体原理差不多,通过分析parse.c中的save_weights_upto或load_weights_upto根据层的类型进行分析,这里因为不需要不逐一讨论。
我们使用.darknet partial [cfg] [.weight] [outputfile] [layernumber]命令,将[layernumber]设置为1,利用自己yolov3-tiny.conv.15.weight(自训练的weight,具体数值和网站直接下载的不一样)生成一个只有1层文件,这个文件系统查询为2004字节。
使用.darknet print[cfg] [.weight] [layerindex] 读取一下,采用二进制文件16进制显示截取如下:
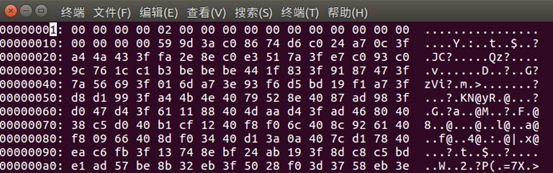
可见,头四个字节为00000000,表示major=0,。接着是02000000,这个根据parse.c中的save_weights_upto函数代码,minor设置为2。
void save_weights_upto(network *net, char *filename, int cutoff)
{
.......
fprintf(stderr, "Saving weights to %s\n", filename);
FILE *fp = fopen(filename, "wb");
if(!fp) file_error(filename);
int major = 0;//版本号,同时还用于区分网络类型,是否需要转置
int minor = 2;
int revision = 0;
fwrite(&major, sizeof(int), 1, fp);//4字节
fwrite(&minor, sizeof(int), 1, fp);//4字节
fwrite(&revision, sizeof(int), 1, fp);//4字节
fwrite(net->seen, sizeof(size_t), 1, fp);//8字节
int i;
for(i = 0; i < net->n && i < cutoff; ++i){
layer l = net->layers[i];
if (l.dontsave) continue;
if(l.type == CONVOLUTIONAL || l.type == DECONVOLUTIONAL){
save_convolutional_weights(l, fp);
........
}
}
fclose(fp);
}
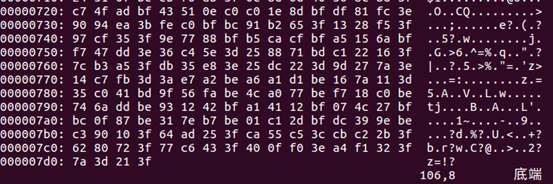
注意,这个二进制文件是低位在前(Little Endian),因为我可耻的使用了Intel处理器,如果你用的是其他类型处理器估计是高位在前(Big Endian)的存储顺序,再接下来00000000表示revision,再接下来0000000000000000,表示截取一个预训练模型时将你的seen参数重新设置为0。最后接下来是参数。文件在第2000(0x07d0)后有4个字节,一共2004字节。
将l.c = 3, l.n = 16, l.size = 3带入34Byte+8Byte+(l.cl.nl.size.l.size+4l.n)4Byte,得2004Byte。对于完整的weight二进制文件,你可以参考cfg配置。
需要注意的是,下一层的l.c等于上一层的l.n,我们根据cfg文件截取3层(选3层是因为第2层为maxpool层没有weight)验证一下,这里第3层而配置为filters=32,size=3,得到的二进制文件为20948Byte,减去前面的2004Byte,得到18994Byte,就是第3层的存储空间。如果将l.c = 3, l.n = 16, l.size = 3带入34Byte+8Byte+(l.cl.nl.size.l.size+4*l.n)*4Byte,得18994Byte。
以上就是关于weight文件结构的讨论,看似神秘,其实很单纯哦!