项目背景:
为保证二手手机的质量,转转对二手手机提供验机服务,用户将手机寄到验机中心,工作人员会对二手手机进行拆机验机,然后根据验机结果,提供一个这款手机可能售出的价格,这个价格有主要有三个用途:
- 验机后给用户提供验机证明和一个参考定价,用户可以在网上自定义价格售卖;
- 用户委托公司在竞拍卖场进行竞拍,该价格乘以一个小于1的系数(如:0.9)得到竞拍的起拍价;
- 竞拍时VIP用户可以自定义起拍价,但我们会将该价格乘以一个大于1的系数(如:1.1)作为自定义起拍价的上限。
之前的二手手机的定价是靠有定价能力的回收商人工进行定价,费时费力,而且参考的维度较少,难以全面、客观、及时的反映二手手机的价格。所以我们的任务就是通过机器学习的方法,利用历史成交的数据(已验机手机的特征数据与手机成交价格)训练一个模型,当工作人员的再次给出验机的数据时,我们能预测一个该手机可能售出的价格。很明显,这是一个回归问题。
项目方案:
这个项目,我们的工作大概可以分为以下四个部分
- 评估指标
- 数据分析及预处理
- 特征工程
- 模型选择
1. 评估指标:
在对问题进行建模之前,我们首先需要选择合适的评估指标、根据评估指标的反馈进行模型调整。一般的机器学习比赛都会给定一个问题和一个固定的评估指标,我们的任务就是构造特征或者堆叠模型,最小化这个评估指标。然而,在实际工作中单一指标并不能完全真实的反应业务诉求,模型的好坏是相对的,大部分评估指标只能片面地反映模型的一部分性能,如果不能合理地运用评估指标,不仅不能发现模型本身的问题,而且会得出错误的结论。
比如:我们以只MSE作为评估指标,MSE评估的是预测误差的均值,它对离群点敏感,即使少量离群点,也会让MSE指标变得很差;只以MAE作为评估指标,我们无法知道模型预测的内部信息,如无法知道我们的模型的预测值比真实价格偏高,还是比真实价格偏低,什么价格段偏高,什么价格段会偏低,这些对于我们的工作都是非常重要的,因为这会严重影响我们的用户体验和用户利益,比如用户拿两千块钱的手机在我们这拍卖或者回收,我们给出的预测价格只有1500元,那么我们很可能会丢掉这个客户,给用户非常不好的体验,留下不好的口碑。
为了在准确预测手机价格的同时,使我们的模型更加鲁棒以及考虑到用户的使用体验,我们综合考虑了MAE、RMSE、RMSLE、预测比真实值大与预测比真实值小的比例、误差绝对值在50/100/150/200/250的比例、误差百分比在2.5%,5%、10%、20%的比例等多个指标,以快速地发现模型选择或训练过程中出现的问题,迭代地对模型进行优化。
2. 数据分析及预处理:
选择2019-01-01 至 2019-04-01这三个月成交且有验机报告的手机作为训练数据,共计361208条数据。将倒数第二个星期的样本作为验证集,倒数第一个星期的样本作为测试集,其余数据作为训练集,原始数据共有72个特征,其中有65个离散特征,7个连续特征,有8个特征缺失值达到50%以上。
对离散特征进行序号编码,统计数据各项指标以及数据可视化,对数据进行初步分析,发现存在价格有极低或者极高的异常数据,如:有的手机只有几块钱,有的手机却上万元;邮费也存在一些异常,对于手机邮费,我们的常识是邮费在几元到二十几元不等,但通过分析发现,有部分数据的邮费达到了数百元。结合生活经验,我们认为这可能是因为我们在浏览商品时,一般会选择销量或者价格进行排序,一些客户为了让自己的手机排名更靠前,于是将手机价格设置的很低,然后将邮费设置的很高,这样当其他用户用价格进行排序时,排名就会很靠前,所以我们将预测目标更正为手机售价加邮费,其实这才是该手机真正的销售价格。对于价格极高极低的情况,我们咨询了优品部门的同事,她们说价格极高可能是一些用户通过自定义价格进行进行信用卡套现;价格极低的情况,可能是平台的一些活动,比如秒杀,代金券等。所以,我们采取了一些规则对这些异常数据进行了过滤,过滤的方式为:如果该手机的售价大于该款手机一个月平均售价的3倍或者小于其五分之一,则判定位异常数据。这些数据并不是太多,我们选择了直接将其删除。
然后综合考虑特征与目标值相关性系数与随机森林、Adaboost,GBDT,XGBoost,LightGBM等模型的特征重要性排序,得到了一些重要特征和非重要特征:
重要特征:手机型号id、手机品牌、手机内存、维修痕迹、颜色、显示异常、购买渠道、保修期、运存、指纹识别、划痕、碎裂。
非重要特征:蓝牙、指南针、重力感应、音量键、电源键、进灰、按压异响、数据接口、振动功能、耳机接口、闪光灯。
3. 特征工程:
由于我们有69项验机特征,而且这些特征是有非常明确的含义和解释性的,可以对二手手机进行非常精准的刻画,所以我们没有像比赛那样针对一些特征进行特征间的两两组合,构造一些复杂组合特征。但为了发现特征间的内在联系,得到一些不易于被发现的重要特征,我们选用了一些可以自动进行特征组合的模型,比如以决策树为基模型的集成类模型或者神经网络模型,所以特征工程我们主要是构造了一些简单的统计特征、对缺失值进行填充,对长尾数据进行处理,对离散特征进行序号编码和独热编码,对连续特征进行归一化。
构造特征:
统计特征:过去一周、两周、三周、一个月售价、出售数、卖出周期的均值和标准差等。特征选择主要是使用前向搜索的贪心算法进行筛选,若加入该特征后模型的综合评估指标有提高,则选择加入特征,若没有提高则不添加该特征。
缺失值处理:
分别尝试了零,均值,众数,中位数,最近邻等不同的填充方式,通过试验离散特征进行众数填充,连续特征进行均值填充效果较好。
长尾数据处理:
因为现实生活中,数据基本上都是满足正太分布的,所以为了更好的描述未知数据,我们对一些长尾型连续特征进行了log(1+x)变换,将其转换为正太分布型数据。
对于类别型特征分别采用序号编码和独热编码:类别间具有大小关系的特征进行序号编码;类别间不具有大小关系的特征进行独热编码。
对连续特征进行归一化:
后边尝试了不同模型,为了消除不同连续特征之间的量纲影响,我们对数值型特征进行归一化处理,使其处于同一数量级,不同特征之间具有可比性。但如果我们只使用以决策树为基学习器的集成模型,其实完全可以不进行归一化,因为决策树在进行节点分裂时主要依据数据集D关于特征x的信息增益比,而信息增益比跟特征是否经过归一化是无关的,归一化并不会改变样本在特征x上的信息增益。但通过梯度下降法求解的模型通常是需要归一化的,归一化后不同特征的参数更新速度变得更为一致,容易更快地通过梯度下降找到最优解。如:线性回归、逻辑回归、支持向量机、神经网络等模型。
4. 模型选择:
GBDT,Lightgbm,Xgboost,MLP。
自定义损失函数:
使用MSE作为损失函数相当于对数据分布的均值进行拟合,它在极值点有着良好的特性,梯度随着损失函数的减小而减小,即使在固定学习率下也能收敛到比较精确的结果,但它对离群点敏感,即使少量离群点,也会让MSE指标变得很差。使用MAE作为损失函数相当于对数据分布的中值进行拟合,对离群点有更好的鲁棒性,但MAE的梯度在极值点处不可导,有一个很大的跃变,即使很小的损失值也会产生很大的误差,不利于模型参数的学习。为了解决这个问题,需要在解决极值点的过程中动态减小学习率,但这会降低模型的收敛速度。
所以我们尝试使用Huber Loss,它结合了MAE和MSE的优点,使用超参数δ来调节误差的阈值,当预测误差大于阈值时采用线性误差,预测误差小于阈值时采用平方误差,对异常值不敏感且在极值点处连续且可导,是一种鲁棒的回归损失函数,我们的预测误差得到了明显的改观。
均方根对数误差RMSLE是对RMLE的一个优化变体,对预测目标进行对数变换![]() ,使用RMSE作为损失函数,最后预测值再还原,这样可以缓解RMSE会被一些较大误差主导的问题,同时它还有另一个优点对预测值偏小样本的惩罚比对预测值偏大样本的惩罚大,如二手手机真实售价是2000元,预测成1800元的惩罚会比预测成2200元的大,这正符合我们最初的不希望预测值偏小的设计目标,所以我们对预测目标进行对数变换,使用Huber Loss作为损失函数,最后预测值再还原。这样我们针对MSE对异常值敏感,MAE不易收敛的情况,结合RMSLE与Huber loss的优点自定义的损失函数,在保证模型具有比较好的收敛能力的同时也有非常好的异常值抵抗能力。
,使用RMSE作为损失函数,最后预测值再还原,这样可以缓解RMSE会被一些较大误差主导的问题,同时它还有另一个优点对预测值偏小样本的惩罚比对预测值偏大样本的惩罚大,如二手手机真实售价是2000元,预测成1800元的惩罚会比预测成2200元的大,这正符合我们最初的不希望预测值偏小的设计目标,所以我们对预测目标进行对数变换,使用Huber Loss作为损失函数,最后预测值再还原。这样我们针对MSE对异常值敏感,MAE不易收敛的情况,结合RMSLE与Huber loss的优点自定义的损失函数,在保证模型具有比较好的收敛能力的同时也有非常好的异常值抵抗能力。
模型评估:
刚开始时我们使用的留出法进行模型评估,我们把样本按比例分成两部分,70% 的样本用于模型训练;30% 的样本用于模型验证,
模型在95%的区间内的预测误差都小于5%,这说明,在大部分时间区间内,模型的预测效果都是非常优秀的。然而,RMSE却一直很差,这很可能是由于在其他的5%时间区间内存在非常严重的离群点。
针对这个问题,可以从三个角度来思考。第一,如果我们认定这些离群点是“噪声点”的话,就需要在数据预处理的阶段把这些噪声点过滤掉。第二,如果不认为这些离群点是“噪声点”的话,就需要进一步提高模型的预测能力,将离群点产生的机制建模进去。第三,可以找一个更合适的指标来评估该模型。关于评估指标,其实是存在比RMSE的鲁棒性更好的指标,比如平均绝对百分比误差MAPE,它定义为
相比RMSE,MAPE相当于把每个点的误差进行了归一化,降低了个别离群点带来的绝对误差的影响。
在实际的实验中:某些特征单独加入后都会使模型效果提升,但是同时加入后效果反而下降,因为,某些特征自身可以单独占据特征空间的某一维度,但是当特征之间可能具有相关关系,且对低分样本人群区别不够好,从而使模型效果降低,可以采取不同的特征组合方式构建多样性的模型
当选择的特征与目标值相关性较强,但是放入同一模型中效果不好时,可能是因为特征相关性较强,产生了特征冗余,可以将这些特征放入不同的模型当中,通过属性扰动构造一些差异化较大的模型 最终进行融合
对于取值较多的数据进行分箱,因为树模型偏向于取值较多的特征不进行处理的话可能会产生过拟合

https://www.zhihu.com/question/295475618
整体业务描述
背景:定价产品需求
需求1:竞拍卖场【起拍价】&【成交价】预估
1)产品需求
- 普通C用户的商品验机后,平台给出【起拍价】&【竞拍成交价】;其中【起拍价】的定义是有两种情况:一是有定价能力的回收商给出报价, 二是平台在【竞拍成交价】的基础上乘以系数得来,给不能定价的回收商使用,最终多个回收商价格取最大值作为起拍价
- 有的商品起拍价低,卖家担心卖不上好价格、缺乏安全感,因此提供VIP服务可以支持自定义起拍价,需要平台给出【起拍价上限】&【竞拍成交价】;其中【起拍价上限】在【竞拍成交价】的基础上乘以较大的系数得来的
- 目前使用的【竞拍成交价】是取 历史30天成交最高值。
需求2:已验机【成交价】预估
1)产品需求
- 普通C用户的商品验机后,平台提供【已验机成交价*售出率】【已验机成交价*预计售出时间】给用户作为定价参考、后期价格运营指导
- 竞拍卖场拍下后,可以直接加价进入已验机卖场,此时平台给出【已验机成交价*售出率】【已验机成交价*预计售出时间】给用户作为定价参考、后期价格运营指导
- 平台对于已经定价的商品做价格运营,根据【已验机成交价】与用户定价的价格差制定运营策略
目前使用的【已验机成交价】是取自第一版定价结果,主要存在以下问题:
- 价格区间范围过大;价格区间偏低
需求5:查成交功能,作为定价参考
1)产品需求
- 用户发布一个手机商品,需要在填写信息后给出【成交价区间】和已成交商品信息,作为用户定价的参考
2)技术能力:给出【成交价区间】
实现对商品的价格进行预测,对比与实际交易的价格之间的波动。
数据收集
手机售价及销售量数据
按品牌型号(三级类)统计手机销售数据, 每天更新过去7天的手机销售量, 平均售价及均方差。
数据来源:hdp_zhuanzhuan_dw_global.dw_mysql_order_1d, 该表每日更新全量商品数据,只需取最后分区即可
表名:hdp_zhuanzhuan_dm_algo.dm_algo_phone_price_stat_1d
字段:
| 字段名 |
字段中文名 |
字段类型 |
|
|---|---|---|---|
| 1 | cate_third_id | 三级分类id | bigint |
| 2 | cate_third_name | 三级分类名称 | string |
| 3 | sale_volume_1w | 一周销量 | int |
| 4 | avg_price_1w | 平均价格 | double |
| 5 | stdev_price_1w | 价格标准差 | double |
| 6 | dt | 日期(yyyy-MM-dd) | string |
sql语句:
|
|
优品销售数据:
获取所有质检机售价,质检码等信息
数据来源:hdp_zhuanzhuan_rawdb_global.raw_youpin_t_checked_info_new 和 hdp_zhuanzhuan_rawdb_global.raw_youpin_qc_order
- 已售出手机id,手机型号,info_id, 每日全量更新.
status为1是已售出,可作为训练数据,status=0 OR (status=3 and source in (1,4)) 为未售手机,需要进行价格预测。
|
|
2. 验机质检码,验机时间
|
|
验机报告数据:
验机报告全量更新至2019-02-16,之后为每日增量更新。每行为一项验机项,is_normal 字段为0时该项目异常。
数据源:hdp_zhuanzhuan_rawdb_global.raw_youpin_t_qc_result_analyze 和 hdp_zhuanzhuan_rawdb_global.raw_youpin_t_qc_result_analyze_inc_1d
HIVE表内容是从优品的SQL库抽取的,mysql_db.db58_youpin_qc_qc_result_analyze每天凌晨1点更新。HIVE表2点50抽取。
|
|
枚举类数据编码
手机品牌和型号,验机报告项均为枚举类数据。需要对数据进行编码。首先通过查表拿到枚举类型数据的所有可能取值,再用sklearn.LabelEncoder对取值进行编码
在验机报告中,每个验机项对应一个item_id, 验机项的取值对应一个item_value_id。验机项和取值的全量信息每天会被同步到Hive表中。(http://58dp.58corp.com/scheduler/task/detail?schedulerId=67549 和 http://58dp.58corp.com/scheduler/task/detail?schedulerId=67545)
从Hive表中抽取验机报告内容项的可能取值
验机报告内容项
|
|
手机品牌型号,颜色和容量编码没有同步到Hive表中,目前使用云窗API直接从源sql数据库中查询
手机品牌型号
|
|
手机颜色容量
|
|
手机预估价格监控:
- abs(手机卖价 - 模型预估价) 在各个区间占比, 柱状图为当日销售量(仅限已验机):
- 预估价过低和过高比例:
- 预估价过低单量,预估价低于售价超过20%,且手机售价高于1000元。预估价过低
2月16日 - 3月14日 已验机手机 预估价和成交价对比
结论:
1. 预估价和手机销量强相关,对于训练数据量较大的手机型号,模型预估价较准
2. 发现一些bad case: a. vivo 双屏版预估价普遍过低,b. 同一款手机对应两个不同型号名称,导致训练数据分散。
- 手机销量
2. 销售量排名前20位, 中20位,后20位手机 价差 / 成交价均值 (%)
3.Bad case
标准:
- abs(预估价 - 售价)< thr 占比
- abs(预估价 - 售价)/ 售价 < thr % 占比
离线评测
新旧模型在各自测试集上的表现。
新模型
| thr |
pct |
|---|---|
| 50 | 54.6% |
| 150 | 87.9% |
| 250 | 95.1% |
| <2.5% | 28.5% |
| <10% | 75.9% |
| <20% | 92.1% |
旧模型
| thr |
pct |
|---|---|
| 2.5% | 24.43% |
| 10% | 69.70% |
| 20% | 88.89% |
上线评测
新模型第1-5天的数据(新模型每周更新)
| Day1 |
Day2 |
Day3 |
Day4 |
Day5 |
|
|---|---|---|---|---|---|
| <50 | |
|
|
|
|
| <150 | |
|
|
|
|
| <250 | |
|
|
|
|
| <2.5% | |
|
|
|
|
| <10% | |
|
|
|
|
| <20% | |
|
|
|
|
旧模型第1-5天的数据
| Day1 |
Day2 |
Day3 |
Day4 |
Day5 |
|
|---|---|---|---|---|---|
| Day1 |
Day2 |
Day3 |
Day4 |
Day5 |
|
| <50 | |
|
|
|
|
| <150 | |
|
|
|
|
| <250 | |
|
|
|
|
| <2.5% | 17.4 |
17.8 | 17.1 | 16.8 | 17.7 |
| <10% | |
|
|
|
|
| <20% | |
|
|
|
|
1背景:
参见:手机定价服务
2.项目调研:
一期,以实现对商品的价格进行预测,对比与实际交易的价格之间的波动。
1.数据源
1)类目手机,选择有验机报告且最近一个月的成交手机数据进行调研,时间:2018-11-09 至 2018-12-07 的数据,时间范围30天,共计121208条商品数据
2)按照手机品牌进行数据分布的调研。存在异常数据,如价格极低的现象,需要针对上下x%的值进行过滤异常值。
注:图1:横坐标:价格;纵坐标:数据量
图2:横坐标:价格对数;纵坐标:数据量
2.特征数据
1)时间类特征:这里未直接使用,只是在时间上进行了统计特征的覆盖。(统计周期:7天,15天,30天的平均售价,出售数,卖出周期)
2)验机属性类:基于拿到的验机报告数据作为特征。(注:这类特征主要是类别型,使用了大部分商品都能覆盖到的69个检验项,其中有一个IMIE的值是每一个手机都不相同的,所以去掉该项,留下检验项68个),这类特征基本上依赖业务,不随时间发生较大变化。
特征补充:
| 序号 |
特征名 |
重要性 |
备注 |
|---|---|---|---|
| 1 | 型号(三级类) | 1027 | |
| 2 | 型号 | 570 | |
| 3 | 容量 | 416 | |
| 4 | 用户标识 | 282 | |
| 5 | 维修痕迹 | 278 | |
| 6 | 颜色 | 253 | |
| 7 | 7天平均交易价(统计到三级类下) | 192 | |
| 8 | 显示异常 | 175 | |
| 9 | 7天价格标准差 | 169 | |
| 10 | 15天内出售商品的平均交易周期 | 165 | |
| 11 | 7天交易价格中位数 | 156 | |
| 12 | 30天内出售商品的平均交易周期 | 151 | |
| 13 | 购买渠道 | 141 | |
| 14 | 7天内出售商品的平均交易周期 | 140 | |
| 15 | 30天价格标准差 | 138 | |
| 16 | 7天销售量(三级类) | 136 | |
| 17 | 保修期 | 134 | |
| 18 | 运存 | 134 | |
| 19 | 15天价格标准差 | 125 | |
| 20 | 是否是商家 | 118 | |
| 21 | 30天平均交易价(统计到三级类下) | 118 | |
| 22 | 15天平均交易价(统计到三级类下) | 117 | |
| 23 | 15天销售量(三级类) | 115 | |
| 24 | 指纹识别 | 110 | |
| 25 | 划痕 | 101 | |
| 26 | 碎裂 | 94 | |
| 27 | 老化发黄 | 92 | |
| 28 | 15天交易价格中位数 | 82 | |
| 29 | 二级类(品牌) | 81 | |
| 30 | 30天销售量(三级类) | 81 | |
| 31 | 储存卡识别 | 81 | |
| 32 | 面部识别 | 78 | |
| 33 | 30天交易价格中位数 | 77 | |
| 34 | 磕碰 | 77 | |
| 35 | 划痕 | 77 | |
| 36 | NFC | 75 | |
| 37 | 红外 | 74 | |
| 38 | 掉漆 | 71 | |
| 39 | 配件是否齐全 | 64 | |
| 40 | 主返回键 | 56 | |
| 41 | 虹膜识别 | 51 | |
| 42 | 后置摄像头 | 43 | |
| 43 | 3D-Touch | 42 | |
| 44 | 卡1 | 41 | |
| 45 | 联通制式 | 35 | |
| 46 | 卡2 | 33 | |
| 47 | 电信制式 | 27 | |
| 48 | 无线充电 | 25 | |
| 49 | 触摸键 | 24 | |
| 50 | 移动制式 | 23 | |
| 51 | ID锁 | 23 | |
| 52 | 听筒 | 20 | |
| 53 | 系统版本 | 19 | |
| 54 | 红屏 | 18 | |
| 55 | 缝隙 | 17 | |
| 56 | 弯曲变形 | 15 | |
| 57 | 闪光灯 | 15 | |
| 58 | WIFI | 14 | |
| 59 | 前置摄像头 | 14 | |
| 60 | 光线感应 | 12 | |
| 61 | 浸液痕迹 | 12 | |
| 62 | 耳机接口 | 11 | |
| 63 | 距离感应 | 10 | |
| 64 | 异常状况 | 8 | |
| 65 | 其他按键 | 6 | |
| 66 | 组件架构 | 5 | |
| 67 | 屏幕触控 | 5 | |
| 68 | 系统 | 5 | |
| 69 | 扬声器 | 4 | |
| 70 | 麦克风 | 4 | |
| 71 | 电池寿命 | 4 | |
| 72 | 亮点坏点 | 3 | |
| 73 | 振动功能 | 3 | |
| 74 | 魅族SN | 1 | |
| 75 | 静音按钮 | 1 | |
| 76 | 数据接口 | 1 | |
| 77 | 电池充电 | 1 | |
| 78 | 按压异响 | 0 | |
| 79 | 卡槽外观 | 0 | |
| 80 | 进灰 | 0 | |
| 81 | 气泡 | 0 | |
| 82 | 电源键 | 0 | |
| 83 | 音量增键 | 0 | |
| 84 | 音量减键 | 0 | |
| 85 | 重力感应 | 0 | |
| 86 | 指南针 | 0 | |
| 87 | 蓝牙 | 0 |
3.模型选择
1)初选模型是常见的gbdt的模型,使用回归方式进行拟合。
实验数据集按照6:4的方式进行拆分。
使用60%的数据进行训练集约72725条,40%的数据进行测试集约48483条。
2)目标:直接对成交的价格进行回归。
3)使用的损失:RMSE 或者 RMSLE
最终确定使用gbdt的方式进行拟合。
4.调研结果
1)结果:
对比gbdt下,RMSE 与RMSLE的差异:
约束限定在价格差值在 2.5% (产品侧要求),实验准则卡到10%;
在测试集上的效果:
| 阈值 | gbdt |
| 2.5% | 24.43% |
| 5% | 44.69% |
| 10% | 69.70% |
| 20% | 88.89% |
结果:大部分在10%的差异以内,在10%到20%的偏差数据占到了近20%。
badcase的分析:
1.首先针对偏差在10%到30%的数据(占据了80%的异常数据),优先对这部分数据进行优化。
| 区间 | 数量 | 占比 |
| [1.1,1.2) | 22961 | 0.627624098 |
| [1.2,1.3) | 7061 | 0.193007872 |
| [1.3,1.4) | 2732 | 0.074677455 |
| [1.4,1.5) | 1212 | 0.033129237 |
| [1.5,1.6) | 691 | 0.018888038 |
| [1.6,1.7) | 371 | 0.010141045 |
| [1.7,1.8) | 275 | 0.007516947 |
| [1.8,1.9) | 182 | 0.004974852 |
| [1.9,2) | 141 | 0.003854144 |
| [2,3) | 481 | 0.013147824 |
| [3,4) | 149 | 0.004072819 |
| [4,5) | 60 | 0.001640061 |
| [5,6) | 66 | 0.001804067 |
| [6,7) | 34 | 0.000929368 |
| [7,8) | 33 | 0.000902034 |
| [8,9) | 9 | 0.000246009 |
| [9,10) | 4 | 0.000109337 |
| [10,*) | 122 | 0.003334791 |
注:横坐标:区间;纵坐标:占比。
2.针对问题进行拆解,针对预测价值差在10%以上的数据。
其中
价格偏高的占60%(实际价格小于预测价格)
价格偏低的占40%(实际价格大于预测价格)
根据生成树的叶子节点进行调节,但是可能会对后期的预测值产生影响,但是要根据判定这些数据是不是要固定。
针对树模型的调整:
方法1:使用6个月的数据作为base model的训练,将只使用验机报告作为特征。使用最近一个月的数据作为微调的数据,(验机特征+统计特征)
方法2:使用最近一个月的数据直接训练模型,(验机特征+统计特征)
方法3:使用最近一个月的数据在已有的base model之上进行微调(使用历史30天的热门商品top100的机型)
上述三种方式计算之后;进行按天切分的测试集上进行对比:
| base+finetuning | |||||||||||||||||||||||||
| 阈值|日期 | 2018/12/21 | 2018/12/22 | 2018/12/23 | 2018/12/24 | 2018/12/25 | 2018/12/26 | 2018/12/27 | ||||||||||||||||||
| <=2.5% | 13.22% | 14.02% | 13.61% | 14.40% | 14.29% | 13.24% | 11.17% | ||||||||||||||||||
| <=5% | 26.51% | 27.75% | 25.57% | 25.21% | 26.44% | 25.55% | 23.38% | ||||||||||||||||||
| <=10% | 50.34% | 50.55% | 47.22% | 49.11% | 47.43% | 48.36% | 45.64% | ||||||||||||||||||
| <=20% | 72.88% | 72.18% | 69.48% | 73.85% | 71.51% | 71.96% | 71.32% | ||||||||||||||||||
| >20% | 27.12% | 27.82% | 30.52% | 26.15% | 28.49% | 28.04% | 28.68% | ||||||||||||||||||
| all train | |||||||||||||||||||||||||
| 阈值|日期 | 2018/12/21 | 2018/12/22 | 2018/12/23 | 2018/12/24 | 2018/12/25 | 2018/12/26 | 2018/12/27 | ||||||||||||||||||
| <=2.5% | 15.66% | 13.06% | 12.92% | 13.85% | 13.58% | 13.71% | 11.57% | ||||||||||||||||||
| <=5% | 27.65% | 27.01% | 26.87% | 27.16% | 25.49% | 26.32% | 23.53% | ||||||||||||||||||
| <=10% | 52.79% | 51.22% | 49.97% | 51.91% | 49.96% | 50.55% | 48.97% | ||||||||||||||||||
| <=20% | 78.30% | 76.68% | 76.36% | 77.67% | 76.16% | 79.21% | 77.42% | ||||||||||||||||||
| >20% | 21.70% | 23.32% | 23.64% | 22.33% | 23.84% | 20.79% | 22.58% | ||||||||||||||||||
| 样本覆盖数 | 0.77463713 | 0.76236162 | 0.74914089 | 0.77354086 | 0.77742699 | 0.78816199 | 0.78684628 | 样本覆盖数 | 0.857142857 | 0.84501845 | 0.821993127 | 0.854474708 | 0.850039463 | 0.864485981 | 0.858954041 | ||||||||||
| 当天的总交易数 | 1309 | 1355 | 1455 | 1285 | 1267 | 1284 | 1262 | 当天的总交易数 | 1309 | 1355 | 1455 | 1285 | 1267 | 1284 | 1262 | ||||||||||
| 使用top100手机进行(训练) | top100 | 1014 | 1033 | 1090 | 994 | 985 | 1012 | 993 | top100 | 1122 | 1145 | 1196 | 1098 | 1077 | 1110 | 1084 | |||||||||
| 阈值|日期 | 2018/12/21 | 2018/12/22 | 2018/12/23 | 2018/12/24 | 2018/12/25 | 2018/12/26 | 2018/12/27 | 阈值|日期 | 2018/12/21 | 2018/12/22 | 2018/12/23 | 2018/12/24 | 2018/12/25 | 2018/12/26 | 2018/12/27 | 阈值|日期 | 2018/12/21 | 2018/12/22 | 2018/12/23 | 2018/12/24 | 2018/12/25 | 2018/12/26 | 2018/12/27 | ||
| <=2.5% | 11.69% | 12.55% | 10.03% | 11.36% | 11.84% | 11.14% | 11.25% | <=2.5% | 14.60% | 15.30% | 12.39% | 13.88% | 14.42% | 13.04% | 12.89% | <=2.5% | 15.33% | 14.32% | 15.13% | 14.57% | 14.48% | 12.43% | 13.75% | ||
| <=5% | 24.37% | 24.43% | 22.47% | 22.96% | 22.65% | 22.59% | 21.00% | <=5% | 30.08% | 29.91% | 28.17% | 28.07% | 27.72% | 27.37% | 24.67% | <=5% | 31.46% | 28.56% | 29.60% | 30.42% | 28.04% | 26.94% | 26.48% | ||
| <=10% | 46.14% | 45.98% | 43.09% | 45.53% | 44.91% | 45.40% | 41.44% | <=10% | 56.31% | 55.95% | 53.67% | 55.33% | 54.52% | 54.84% | 48.84% | <=10% | 56.33% | 54.76% | 55.35% | 55.56% | 53.85% | 54.86% | 53.78% | ||
| <=20% | 69.14% | 68.78% | 65.22% | 68.95% | 67.72% | 69.31% | 66.56% | <=20% | 82.45% | 82.38% | 79.27% | 82.29% | 81.22% | 81.62% | 77.54% | <=20% | 80.75% | 81.48% | 80.77% | 82.15% | 80.87% | 82.34% | 79.43% | ||
| >20% | 30.86% | 31.22% | 34.78% | 31.05% | 32.28% | 30.69% | 33.44% | >20% | 17.55% | 17.62% | 20.73% | 17.71% | 18.78% | 18.38% | 22.46% | >20% | 19.25% | 18.52% | 19.23% | 17.85% | 19.13% | 17.66% | 20.57% | ||
| 使用top100手机进行调整(all) | 使用top100手机进行调整(all) | 使用top100手机进行调整(all) | |||||||||||||||||||||||
| 阈值|日期 | 2018/12/21 | 2018/12/22 | 2018/12/23 | 2018/12/24 | 2018/12/25 | 2018/12/26 | 2018/12/27 | 阈值|日期 | 2018/12/21 | 2018/12/22 | 2018/12/23 | 2018/12/24 | 2018/12/25 | 2018/12/26 | 2018/12/27 | 阈值|日期 | 2018/12/21 | 2018/12/22 | 2018/12/23 | 2018/12/24 | 2018/12/25 | 2018/12/26 | 2018/12/27 | ||
| <=2.5% | 15.58% | 12.99% | 13.54% | 13.23% | 13.81% | 13.24% | 11.17% | <=2.5% | 16.86% | 14.52% | 14.86% | 15.59% | 14.21% | 14.72% | 12.69% | <=2.5% | 16.31% | 14.15% | 14.46% | 15.57% | 14.39% | 13.96% | 12.27% | ||
| <=5% | 27.50% | 26.86% | 27.08% | 27.08% | 26.05% | 26.17% | 23.22% | <=5% | 30.57% | 29.91% | 30.64% | 30.99% | 27.51% | 28.46% | 25.68% | <=5% | 29.68% | 29.00% | 29.35% | 30.33% | 27.48% | 27.66% | 24.72% | ||
| <=10% | 53.40% | 50.48% | 49.83% | 51.83% | 50.12% | 50.78% | 48.34% | <=10% | 60.26% | 57.50% | 56.24% | 57.04% | 55.43% | 54.74% | 53.37% | <=10% | 57.40% | 55.37% | 55.02% | 56.01% | 54.04% | 52.97% | 51.94% | ||
| <=20% | 78.07% | 76.16% | 75.46% | 77.67% | 76.09% | 79.44% | 77.50% | <=20% | 84.62% | 81.12% | 83.39% | 83.70% | 81.32% | 83.50% | 81.97% | <=20% | 82.98% | 79.48% | 81.94% | 82.79% | 80.32% | 82.25% | 81.18% | ||
| >20% | 21.93% | 23.84% | 24.54% | 22.33% | 23.91% | 20.56% | 22.50% | >20% | 15.38% | 18.88% | 16.61% | 16.30% | 18.68% | 16.50% | 18.03% | >20% | 17.02% | 20.52% | 18.06% | 17.21% | 19.68% | 17.75% | 18.82% | ||
| 使用top100手机进行调整(base+finetune) | 使用top100手机进行调整(base+finetune) | 使用top100手机进行调整(base+finetune) | |||||||||||||||||||||||
| 阈值|日期 | 2018/12/21 | 2018/12/22 | 2018/12/23 | 2018/12/24 | 2018/12/25 | 2018/12/26 | 2018/12/27 | 阈值|日期 | 2018/12/21 | 2018/12/22 | 2018/12/23 | 2018/12/24 | 2018/12/25 | 2018/12/26 | 2018/12/27 | 阈值|日期 | 2018/12/21 | 2018/12/22 | 2018/12/23 | 2018/12/24 | 2018/12/25 | 2018/12/26 | 2018/12/27 | ||
| <=2.5% | 13.75% | 16.01% | 13.95% | 13.70% | 12.15% | 12.93% | 11.17% | <=2.5% | 14.10% | 17.23% | 15.87% | 14.49% | 13.50% | 13.44% | 13.19% | <=2.5% | 14.08% | 15.98% | 15.22% | 13.93% | 13.09% | 13.60% | 12.73% | ||
| <=5% | 27.96% | 29.59% | 26.60% | 27.32% | 25.26% | 26.32% | 23.06% | <=5% | 29.88% | 31.85% | 29.08% | 28.37% | 27.61% | 27.87% | 25.48% | <=5% | 28.88% | 30.92% | 27.68% | 28.32% | 26.46% | 27.66% | 25.00% | ||
| <=10% | 52.25% | 52.25% | 47.84% | 49.73% | 48.22% | 49.92% | 45.56% | <=10% | 55.42% | 58.37% | 53.76% | 53.92% | 54.11% | 53.95% | 49.14% | <=10% | 54.19% | 57.12% | 51.17% | 52.28% | 52.27% | 52.61% | 48.06% | ||
| <=20% | 74.71% | 75.20% | 71.34% | 73.70% | 72.69% | 76.40% | 72.98% | <=20% | 80.08% | 81.90% | 78.35% | 80.78% | 78.48% | 80.73% | 78.75% | <=20% | 78.88% | 80.44% | 76.92% | 79.33% | 77.16% | 79.28% | 77.21% | ||
| >20% | 25.29% | 24.80% | 28.66% | 26.30% | 27.31% | 23.60% | 27.02% | >20% | 19.92% | 18.10% | 21.65% | 19.22% | 21.52% | 19.27% | 21.25% | >20% | 21.12% | 19.56% | 23.08% | 20.67% | 22.84% | 20.72% | 22.79% | ||
结论是:
在使用历史的样本集上需要考虑到时间因素才行,不然学习到的误差还是挺大,不能直接使用。
在使用的近一个月的数据进行学习中效果少一些。
然后统计之后每天的交易数据来看,在含有的统计特征的数据上进行微调热门机型获取的效果要稍微好一些。
将模型拆成两块:
1.价格预测模型,就是使用历史数据进行价格的预测。
2.售出模型,就是针对商品的售出情况进行调整售出率,调节价格因素来控制。(分类模型)(将价格作为一种修正方式)
2018-12-29调节售出模型(classification model)
上述方式存在问题,在使用售出模型时,发现价格只是其中一个重要因子,在调节该因子的时候发现并不能很好的以人的认知让其一起变化,最后此方案先停下。在后面接入规则先试探。
下面对模型的价格进行平衡调整:
对之前直接预测价格调整为预测价格对数值,在使用是将预测值在进行价格还原。
下面是相同数据上进行测试:
| 样本覆盖数 | 0.774637128 | 0.762361624 | 0.749140893 | 0.773540856 | 0.777426993 | 0.788161994 | 0.786846276 | 样本覆盖数 | 0.857142857 | 0.84501845 | 0.821993127 | 0.854474708 | 0.850039463 | 0.864485981 | 0.858954041 | ||||||||||
| 当天的总交易数 | 1309 | 1355 | 1455 | 1285 | 1267 | 1284 | 1262 | 当天的总交易数 | 1309 | 1355 | 1455 | 1285 | 1267 | 1284 | 1262 | ||||||||||
| top100 | 1014 | 1033 | 1090 | 994 | 985 | 1012 | 993 | top100 | 1122 | 1145 | 1196 | 1098 | 1077 | 1110 | 1084 | ||||||||||
| 使用top100手机进行调整(all) | 使用top100手机进行调整(all) | 使用top100手机进行调整(all) | |||||||||||||||||||||||
| 阈值|日期 | 2018/12/21 | 2018/12/22 | 2018/12/23 | 2018/12/24 | 2018/12/25 | 2018/12/26 | 2018/12/27 | 阈值|日期 | 2018/12/21 | 2018/12/22 | 2018/12/23 | 2018/12/24 | 2018/12/25 | 2018/12/26 | 2018/12/27 | 阈值|日期 | 2018/12/21 | 2018/12/22 | 2018/12/23 | 2018/12/24 | 2018/12/25 | 2018/12/26 | 2018/12/27 | ||
| <=2.5% | 15.58% | 12.99% | 13.54% | 13.23% | 13.81% | 13.24% | 11.17% | <=2.5% | 16.86% | 14.52% | 14.86% | 15.59% | 14.21% | 14.72% | 12.69% | <=2.5% | 16.31% | 14.15% | 14.46% | 15.57% | 14.39% | 13.96% | 12.27% | ||
| <=5% | 27.50% | 26.86% | 27.08% | 27.08% | 26.05% | 26.17% | 23.22% | <=5% | 30.57% | 29.91% | 30.64% | 30.99% | 27.51% | 28.46% | 25.68% | <=5% | 29.68% | 29.00% | 29.35% | 30.33% | 27.48% | 27.66% | 24.72% | ||
| <=10% | 53.40% | 50.48% | 49.83% | 51.83% | 50.12% | 50.78% | 48.34% | <=10% | 60.26% | 57.50% | 56.24% | 57.04% | 55.43% | 54.74% | 53.37% | <=10% | 57.40% | 55.37% | 55.02% | 56.01% | 54.04% | 52.97% | 51.94% | ||
| <=20% | 78.07% | 76.16% | 75.46% | 77.67% | 76.09% | 79.44% | 77.50% | <=20% | 84.62% | 81.12% | 83.39% | 83.70% | 81.32% | 83.50% | 81.97% | <=20% | 82.98% | 79.48% | 81.94% | 82.79% | 80.32% | 82.25% | 81.18% | ||
| >20% | 21.93% | 23.84% | 24.54% | 22.33% | 23.91% | 20.56% | 22.50% | >20% | 15.38% | 18.88% | 16.61% | 16.30% | 18.68% | 16.50% | 18.03% | >20% | 17.02% | 20.52% | 18.06% | 17.21% | 19.68% | 17.75% | 18.82% | ||
| 在全连数据上测试 (训练使用的未取top的tf) |
对比1(使用全量的数据) | 对比1(使用全量的数据) | |||||||||||||||||||||||
| 阈值|日期 | 2018/12/21 | 2018/12/22 | 2018/12/23 | 2018/12/24 | 2018/12/25 | 2018/12/26 | 2018/12/27 | 阈值|日期 | 2018/12/21 | 2018/12/22 | 2018/12/23 | 2018/12/24 | 2018/12/25 | 2018/12/26 | 2018/12/27 | 阈值|日期 | 2018/12/21 | 2018/12/22 | 2018/12/23 | 2018/12/24 | 2018/12/25 | 2018/12/26 | 2018/12/27 | ||
| <=2.5% | 16.44% | 15.73% | 15.77% | 18.08% | 17.05% | 16.20% | 15.06% | <=2.5% | 17.75% | 16.65% | 17.34% | 20.32% | 19.70% | 16.80% | 16.82% | <=2.5% | 17.56% | 16.68% | 16.39% | 19.03% | 18.48% | 16.58% | 16.14% | ||
| <=5% | 32.65% | 30.87% | 29.82% | 32.19% | 28.97% | 31.54% | 29.00% | <=5% | 35.80% | 33.79% | 33.30% | 34.31% | 32.79% | 32.81% | 32.33% | <=5% | 35.12% | 33.36% | 31.86% | 33.42% | 31.20% | 32.16% | 31.37% | ||
| <=10% | 56.04% | 55.39% | 53.37% | 55.73% | 51.07% | 55.37% | 55.63% | <=10% | 60.75% | 60.31% | 58.26% | 58.65% | 56.55% | 58.79% | 59.92% | <=10% | 59.63% | 59.56% | 56.44% | 57.56% | 54.69% | 57.39% | 58.67% | ||
| <=20% | 81.27% | 82.13% | 81.06% | 82.46% | 79.01% | 81.39% | 79.56% | <=20% | 84.71% | 86.16% | 83.94% | 86.22% | 83.35% | 84.68% | 84.09% | <=20% | 84.22% | 85.76% | 83.11% | 85.06% | 82.54% | 84.05% | 82.93% | ||
| >20% | 18.73% | 17.87% | 18.94% | 17.54% | 20.99% | 18.61% | 20.44% | >20% | 15.29% | 13.84% | 16.06% | 13.78% | 16.65% | 15.32% | 15.91% | >20% | 15.78% | 14.24% | 16.89% | 14.94% | 17.46% | 15.95% | 17.07% | ||
| 在全连数据上测试 (训练使用的未取top的tf) |
对比2(使用top数据进行ft) | 对比2(使用top数据进行ft) | |||||||||||||||||||||||
| 阈值|日期 | 2018/12/21 | 2018/12/22 | 2018/12/23 | 2018/12/24 | 2018/12/25 | 2018/12/26 | 2018/12/27 | 阈值|日期 | 2018/12/21 | 2018/12/22 | 2018/12/23 | 2018/12/24 | 2018/12/25 | 2018/12/26 | 2018/12/27 | 阈值|日期 | 2018/12/21 | 2018/12/22 | 2018/12/23 | 2018/12/24 | 2018/12/25 | 2018/12/26 | 2018/12/27 | ||
| <=2.5% | 16.59% | 16.84% | 16.67% | 17.77% | 16.34% | 15.11% | 14.90% | <=2.5% | 19.43% | 20.04% | 20.18% | 20.32% | 18.68% | 17.00% | 17.82% | <=2.5% | 18.98% | 19.04% | 19.65% | 19.40% | 18.01% | 16.94% | 17.07% | ||
| <=5% | 33.03% | 30.50% | 32.09% | 32.03% | 31.25% | 28.89% | 28.37% | <=5% | 39.05% | 35.62% | 38.07% | 36.62% | 35.94% | 32.31% | 33.84% | <=5% | 37.97% | 34.41% | 37.54% | 35.52% | 34.82% | 32.16% | 32.38% | ||
| <=10% | 55.58% | 54.36% | 53.93% | 54.87% | 54.22% | 56.00% | 52.46% | <=10% | 64.40% | 63.70% | 63.30% | 62.17% | 62.23% | 62.45% | 61.23% | <=10% | 63.19% | 61.31% | 62.71% | 61.02% | 60.72% | 62.07% | 59.32% | ||
| <=20% | 77.60% | 77.55% | 76.93% | 77.71% | 76.48% | 78.27% | 75.44% | <=20% | 86.49% | 87.12% | 87.80% | 85.81% | 85.08% | 86.56% | 84.19% | <=20% | 86.01% | 86.29% | 87.63% | 85.06% | 84.40% | 85.86% | 83.49% | ||
| >20% | 22.40% | 22.45% | 23.07% | 22.29% | 23.52% | 21.73% | 24.56% | >20% | 13.51% | 12.88% | 12.20% | 14.19% | 14.92% | 13.44% | 15.81% | >20% | 13.99% | 13.71% | 12.37% | 14.94% | 15.60% | 14.14% | 16.51% | ||
结果:
调整之后价格差的上下浮动基本平衡了,目前是各占50%左右(预测价格高于实际价格,预测价格低于实际价格的比例目前接近1:1)
在效果上是存在2-3%的提升。
1,手机价格模型
1.1 特征提取
基本特征,品牌、型号等
质检特征,成色、屏幕信息等
文本特征,从title或者content中提取的特征
1.2 分类
分析出哪些特征对价格影响较大,然后以这些特征为基准,将手机分成多个类别
1.3 模型
在每个类别的商品中,用统计的方法得到价格区间
后续用线性模型、xgboost等机器学习模型对每个类别的商品做回归
2,标品价格模型
手机也是一种标品,区别在于其他标品没有质检特征
2.1 特征提取
基本特征
文本特征
2.2 分类
分析出哪些特征对价格影响较大,然后以这些特征为基准,将商品分成多个类别
2.3 模型
在每个类别的商品中,用统计的方法得到价格区间
后续用线性模型、xgboost等机器学习模型对每个类别的商品做回归
3,非标品价格模型
非标品的数据是没有sku,分类粒度不如标品那么细
3.1 特征提取
基本特征
文本特征
3.2 分类
先按照类别、品牌等维度将商品分类
3.2 模型
分类力度可能不够,用统计方法去算价格区间需要调研
用线性模型、xgboost等机器学习方法进行回归
4,计划
目前在做手机的价格模型,先会用统计的方法做一版价格区间,后续会用线性模型、xgboost等机器学习方法进一步预估价格。手机价格模型完成后,会做标品价格模型,最后做非标品价格模型。
5,难点
难点:一是文本特征的提取,这后续会用nlp的一些方法进行分析调研;二是怎么选取特征,模型训练效果到底怎么样,是否会用到组合模型也需要后续调研。
6,质检手机价格模型
6.1 特征提取
基本特征,质检特征
6.2 特征选择
分类:按照品牌、型号和容量进行划分
秩和检验:每个类,特征的不同特征值之间用秩和检验算出检验值,选取最大的检验值作为该特征的特征值的最终结果
选取特征:特质值检验值,去除小于0.1的,并进行从小到大排序,选择检验值前十小的所包含的特征作为最终特征
6.3 数据分类
“品牌+型号+容量+选取的质检特征“对数据进行分类
6.4 价格区间
对分类数据用Box-cox变换求价格区间







证明线性交叉验证是可靠的

用于不同的模型 增加模型差异性

树模型 偏向于取值较多的特征 不进行处理的话可能会产生过拟合





使用Huber loss时下降的可能更快
2.2 高阶环境特征
特种工程中一种思想是利用已有特征的组合,计算其高阶特征, 经过特征选择我们发现 ‘板温’,‘现场温度’,‘光照强度’,‘风速’,‘风向’ 即环境因素的两两之间的2阶交互项可以提供较好的预测效果。
2.3 特征选择
在比赛中,我们的基本思路是,不同模型使用不同的特征。这是由于在比赛过程中,我们发现在某个模型上十分有效的特征在另外一个模型上并不一定能够得到很好的结果。
此外,我们在比赛中使用了“前向特征选择”的方法。这种方法基本的过程是,先选择一个预测性能最好参数,然后在剩下的特征中继续选择一个与已有的特征一起作为特征集,使得分最高。以此类推,直到达到预先设定的最大特征数量或者全部特征集。
图13绘制了前向特征选择过程中,陆续加入特征,模型的得分情况。测试过程使用的是LightGBM模型(详细参数见所提交的代码)。

前向特征选择得分曲线
3.2 基于LightGBM与XGBoost的构建与调试
在本问题中,一个严重的问题是过拟合,我们发现模型在训练样本中表现优越,但是在验证数据集以及测试数据集中表现不佳,在采取了特征,样本抽样进入训练,减少树深度和正则化参数后等有效方法后,我们发现和验证以下创新的方法可以进一步减少过拟合。
重复使用部分特征
在Light GBM模型中,我们对于环境特征(板温,现场温度,光照强度,风速,风向)执行了一次复制,即这些特征会在训练中出现两次,结果显示训练集误差几乎一致,但是线上线下验证集误差都更小,也就是说,使用重复特征,减少了过拟合的程度,使得模型的泛化,预测效果更佳。
对比加入重复特征的训练集与普通训练集的训练曲线,如图15,可见使用重复特征的模型验证误差小于不使用重复特征的模型,而两者的训练误差几乎相同的
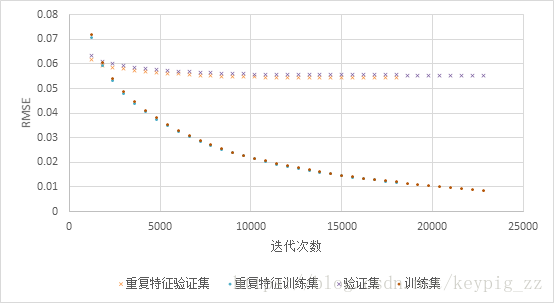
图15 重复特征下的交叉验证误差曲线
很多文献和实验[5]表明特征选择时去除相关性高的特征是有利的,但是在本问题中我们发现重复特征虽然和已有特征的相关性很高,但是这种做法是可以提高预测准确度的,我们认为这有可能与单个树模型在抽样特征的时候,重复特征会有更大的机率被抽到有关。
关于这一点发现是否具有通用性,需要其他数据集的实验验证。
2.在每折交叉验证后进行预测
单模型的参数调整对于模型的表现有很大的影响,我们使用了网格搜索,交叉验证的方法,获得规定参数范围内最优的参数组合,在确定参数后,对于单模型再次在训练中使用交叉验证,一方面是可以对比不同模型的效果,一方面是我们在4折交叉验证中,每折训练结束后,都对测试集用本折交叉验证得到的模型进行一次预测。具体的说,比如对Xgboost模型,4折交叉验证,得到4个不同的“Xgboost模型”,用这4个模型分别对测试集做一次预测,最后Xgboost的预测结果是4次预测结果的平均值,这个过程可以看作是对于训练集合的一次抽样,Xgboost最终结果实际上是4个子模型结果的融合,抽样和融合可以减少过拟合,我们发现这样的处理对于本题目的预测精度有提高。
3.每个单模型所使用的特征都不同
合理的数据预处理
我们观察到了数据中的异常点,并将训练数据和测试数据使用相同的方式进行异常值修复(前值填充)
使用了较为科学的特征选择方法——前向特征选择。