@Hadoop伪分布搭建
你好! 本篇文章主要对伪分布式Hadoop集群环境的安装与配置步骤进行介绍。
本文章的特点是:建立在虚拟机里安装并配置好Linux下搭建伪分布式搭建,安装完可用继续对高可用平台搭建。具体详见下章节。
下面是需要的一些安装文件,需要者自取
[ 提取码:657t ] xftp、测试文件、xshell
1、Xftp软件安装使用
1、 安装好xshell之后需要下载Xftp4(用于传文件,链接中有下载文件xshell、Xftp4哦)
2、 如何传文件?
(1)打开到传输界面
(2)传输文件
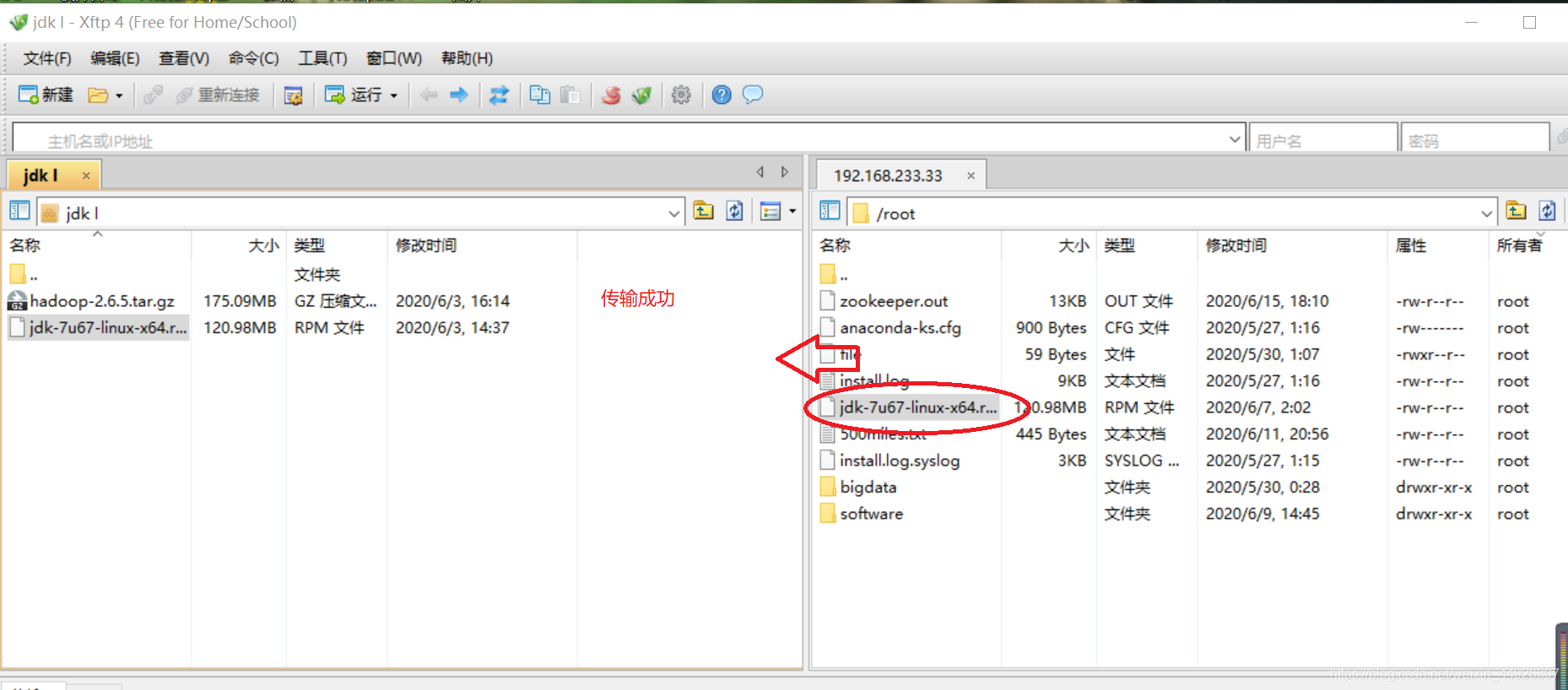
(3)传输成功界面
3、用rpm装jdk
1、 在根目录下,输入安装命令
rpm -i jdk-7u67-linux-x64.rpmwhereis java
安装后,出现如下: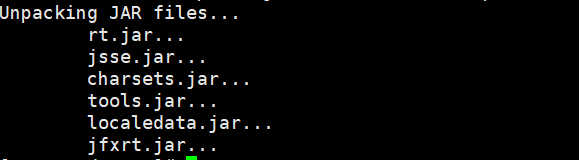
2、配置文件
目录: vi + /etc/profile
export JAVA_HOME=/usr/bin/java
export PATH=$PATH:$JAVA_HOME/bin
3. 更新一下文件
source /etc/profile
4、输入jps,结果出现 xxxx jps,说明安装成功
注意:出现 command not find
<1>、查看是否输入正确,source必须执行,否则修改无效
<2>、更改绝对路径
export JAVA_HOME=/usr/bin/java
export PATH=$PATH:/usr/java/jdk1.7.0_67/bin
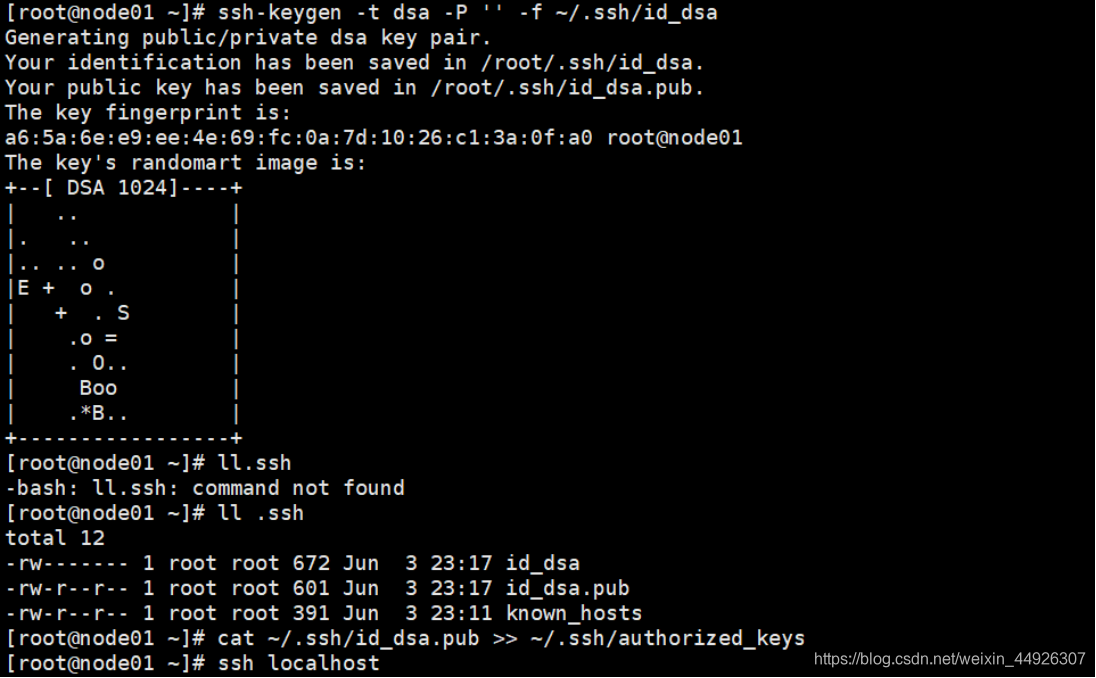
2、免秘钥
2.1如何给每台虚拟机免秘钥
1、在家目录下ll -a:查看有无.ssh文件,如果没有就ssh localhost
ssh localhost 之后一定要exit退出,不然出大问题哦
2、cd .ssh ,并ll 查看当前文件
3、 免秘钥操作:
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_key
验证:
ssh localhost 看看需不需要输入密码
一定要exit哦
补充说明:

3、安装hadoop2.6.5
3.1如何安装Hadoop
先在node01中安装,后面传输一下即可,传文件方法前面已介绍(这里传输路径为software文件夹)
1、 利用tar 命令直接解压安装包
(1)存放安装软件 mkdir software
(2)在opt目录中建立gy 文件夹cd /opt
mkdir gy
-tar xf hadoop-2.6.5.tar.gz -C /opt/gy (注:-C的C 是大写)

到/opt/gy目录下看是否解压好 cd /opt/gy/hadoop-2.6.5

2、 想要实现任意目录下均可启动hadoop
在目录:cd /opt/gy/hadoop-2.6.5/etc/hadoop/
vi + /etc/profile
export JAVA_HOME=/usr/bin/java
export HADOOP_HOME=/opt/ldy/hadoop-2.6.5
export PATH=$PATH:/usr/java/jdk1.7.0_67/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
(1)在指定目录下,修改profile文
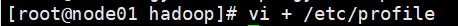
(2)进入文件内修改(修改完 !wq 保存退出)

(3)修改完成一定要source

验证:
输入hd按Tab键可以联想出hdfs
输入start-d按Tab键可以联想出start-dfs.
就表示配置成功了
不要忘记source,更改会不生效哦
3.2修改Hadoop配置文件
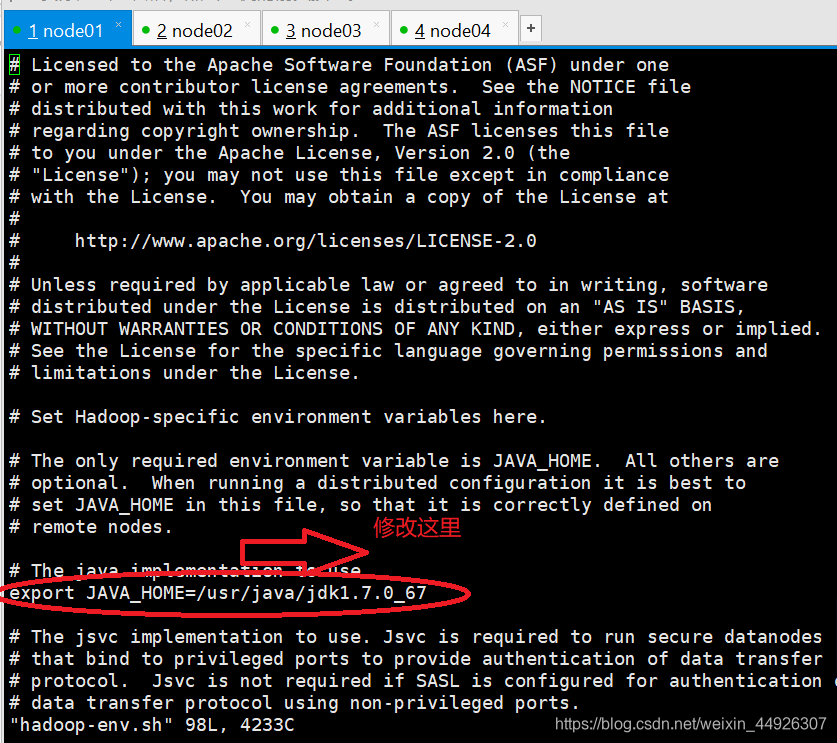
1、在etc目录中修改:cd /opt/gy/hadoop-2.6.5/etc/hadoop
以上路径的etc不是根目录的etc
vi hadoop-env.sh
vi mapred-env.sh
vi yarn-env.sh
给这三个文件夹的JAVA_HOME改成绝对路径:/usr/java/jdk1.7.0_67
如下图所示修改
修改的那句如果有#须要去除
2、配置vi core-site.xml文件(添加)
<property>
<name>fs.defaultFS</name>
<value>hdfs://node01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/var/gy/hadoop/pseudo</value>
</property>
在两个configuration中间添加
两个configuration之间空间留大一点,如果看不到下方,用键盘的上下键
3、 配置vi hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node01:50090</value>
</property>
注意:
在两个configuration中间添加
两个configuration之间空间留大一点,如果看不到下方,用键盘的上下键

gy文件夹,改成之前自己设置的文件夹
4、配置slaves
路径是:cd /opt/gy/hadoop-2.6.5/etc/hadoop/
修改slaves文件: vi slaves
node01
(1)到Hadoop路径下查看

(2)进入此文件夹,显示的localhost

(2)删除localhost,添加node01
5、格式化hdfs
hdfs namenode -format
只能格式化一次,再次启动集群不要执行,否则clusterID变了
(1)看到下面这句说明成功了

(2)格式化后/var/gy/hadoop/pseudo就存在了,检查一下看存在没

6、启动集群
start-dfs.sh
jps后出现以下,即为成功

如果缺少了
1、首先看日志文件
2、配置文件3.2里面的3节,检查一遍
7、在浏览器里打开node01:50070(别用360浏览器!)

8、创建目录:hdfs dfs -mkdir -p /user/root
9、 如何停止集群:stop-dfs.sh
4、跑一个wordcount程序
集群起起来了
1、在hdfs里建立输入目录与输出目录
hdfs dfs -mkdir -p /data/input
hdfs dfs -mkdir -p /data/output
2、将要统计数据的文件上传到输入目录,并查看
(将500miles.txt上传到根目录下,从Windows传到Linux传文件方法,前面介绍的)
hdfs dfs -put 500miles.txt /data/input
hdfs dfs -put -ls /data/input
3、进入MapReduce目录
cd /opt/gy/hadoop-2.6.5/share/hadoop/mapreduce/
4、运行wordcount
hadoop jar hadoop-mapreduce-examples-2.6.5.jar wordcount /data/input /data/output/result

5、查看结果
hdfs dfs -ls /data/output/result
hdfs dfs -cat /data/output/result/part-r-00000

6、如何查询错误
(1)通过查询日志,如何查日志呢?找到日志文件
路径:
cd /opt/gy/hadoop-2.6.5
查看hadoop-2.6.5有什么:
ll

到log里面文件里面
cd logs
查看
ll

看的是.log文件
(2)查看末尾一百行
tail -100 hadoop-root-journalnode-node01.log

5、问题小结
- 网络连接出现错误,找不到网页
1、换一个浏览器试试,不要QQ、360浏览器
2、配置文件时修改处#没有删除