| SST | 总平方和 |
| SSE | 误差平方和 |
| SSR | 回归平方和 |
| R2 | 判定系数 |
| R | 多重相关系数 |
| MSE | 均方误差 |
| RMSE | 均方根误差 |
| MAE | 平均绝对误差 |
| MAPE | 平均绝对百分误差 |
| count | 行数 |
| yMean | 原始因变量的均值 |
| predictionMean | 预测结果的均值 |
R2 判定系数
一般来说,R2在0到1的闭区间上取值,但在实验中,有时会遇到R2为inf(无穷大)的情况,这时我们会用到R2的计算公式:
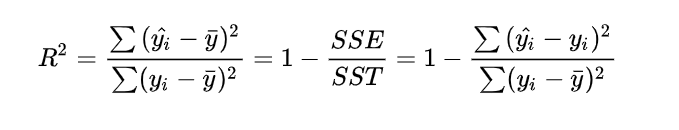
是反映评价拟合好坏的指标。R2是最常用于评价回归模型优劣程度的指标,R2越大(接近于1),所拟合的回归方程越优
R多重相关系数
相关系数是一个评价两个变量线性相关度的指标。在线性拟合中可以通过拟合结果和实测值得相关系数来反应拟合结果和实测结果线性相关度。但是如果本来就用的非线性拟合(多项式、曲线),那这个指标对于评估拟合没有任何意义。
表示原回归值,
表示原回归值的平均值,
表示预测回归值
总平方和,表示变量 相对于中心
的异动;它表征了观测数据总的波动程度
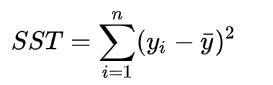
回归平方和,表示估计值 相对于中心
的异动;
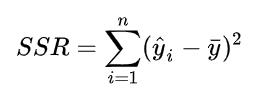
误差平方和,表示变量 相对于估计值
的异动。
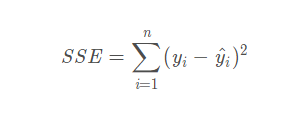
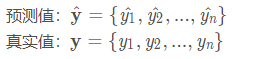
MSE
均方误差(Mean Square Error)

当预测值与真实值完全吻合时等于0,即完美模型;误差越大,该值越大。
RMSE
均方根误差(Root Mean Square Error),其实就是MSE加了个根号,这样数量级上比较直观,比如RMSE=10,可以认为回归效果相比真实值平均相差10。
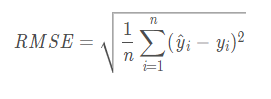
MAE
平均绝对误差(Mean Absolute Error)MAE虽能较好衡量回归模型的好坏,但是绝对值的存在导致函数不光滑,在某些点上不能求导,可以考虑将绝对值改为残差的平方,这就是均方误差。

MAPE
平均绝对百分比误差(Mean Absolute Percentage Error)
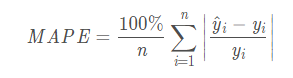
MAPE 为0%表示完美模型,MAPE 大于 100 %则表示劣质模型。
可以看到,MAPE跟MAE很像,就是多了个分母。
注意点:当真实值有数据等于0时,存在分母0除问题,该公式不可用!
def regression_assessment(original_regression_val, prediction_regression_val, input1, output1):
df = pd.read_csv(input1, header=None)
y_actual = df.iloc[:, original_regression_val]
y_predicted = df.iloc[:, prediction_regression_val]
mae = mean_absolute_error(y_actual, y_predicted)
mape = np.mean(np.abs((y_predicted - y_actual) / y_actual)) * 100
mse = mean_squared_error(y_actual, y_predicted)
sse = np.sum((y_actual - y_predicted) ** 2)
ssr = np.sum((y_predicted - np.mean(y_actual)) ** 2)
sst = np.sum((y_actual - np.mean(y_actual)) ** 2)
r2 = 1 - sse / sst # r2_score(y_actual, y_predicted, multioutput='raw_values')
rmse = np.sqrt(mean_squared_error(y_actual, y_predicted))
count = np.size(y_predicted)
predictionMean = np.mean(y_predicted)
yMean = np.mean(y_actual)
try:
r = math.sqrt(r2)
except ValueError:
r = np.nan
print('mae:', mae)
print('mape:', mape)
print('mse:', mse)
print('r:', r)
print('r2:', r2)
print('rmse:', rmse)
print('sse:', sse)
print('ssr:', ssr)
print('sst:', sst)
print('count:', count)
print('predictionMean:', predictionMean)
print('yMean:', yMean)
if __name__ == '__main__':
regression_assessment(original_regression_val=2, prediction_regression_val=1, input1="../data_source/price_pai.csv",
output1="")
输出结果:
mae: 359.2171428571428
mape: 109.14431827903451
mse: 193251.1310857142
r: nan
r2: -9.395675629275434
rmse: 439.60337929287374
sse: 12174821.258399995
ssr: 15998947.858399985
sst: 1171142.8571428566
count: 63
predictionMean: 690.1595238095236
yMean: 330.94238095238126
和阿里pai平台上计算结果一致

参考:
https://zhuanlan.zhihu.com/p/37605060
https://help.aliyun.com/document_detail/42745.html#h2-u4E8Cu5206u7C7Bu8BC4u4F3015