文章目录
- 一、前言
- 二、适用场景
- 三、技术架构
- 四、方案优势
- 五、自建Hadoop集群规划
- 5.1 Hadoop集群安装规划
- 5.2 创建 VPC 网络
- 5.3 批量创建 ECS 实例
- 5.4 初始化配置
- 5.5 配置hadoop各ECS之间的无密钥登录
- 5.6 loggen操作
- 5.7 Kafka操作
- 5.8 Zookeeper操作
- 5.9 Hadoop操作
- 5.10 Flume操作
- 5.11 MySQL操作
- 5.12 Hive操作
- 5.13 Hbase操作
- 5.14 Azkaban操作
- 六、创建 DataWorks 工作空间
- 七、Hive数仓迁移到MaxCompute
- 八、Hbase表数据迁移到云数据库Hbase版
- 九、数据接入组件Kafka迁移到Datahub
- 9.1 创建Datahub工程和Topic
- 9.2 在ECS loggen上启动新的Flume任务将数据发送到Datahub
- 9.3 创建DataConnector将数据从Datahub归档到MaxCompute表
- 十、Azkaban定时任务迁移和改造
一、前言
本文整理自阿里云最佳实践!方便自己学习用,侵删!

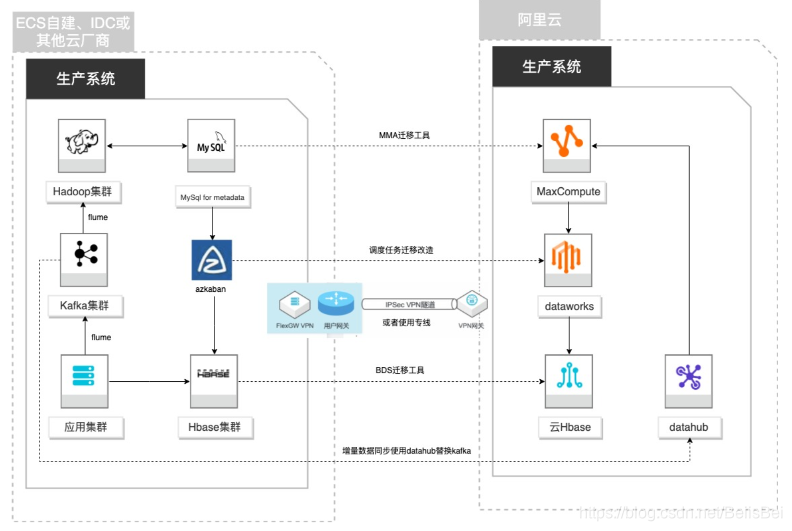
客户基于ECS、IDC自建或在友商云平台自建了大数据集群,为了降低企业大数据计算平台的成本,提高大数据应用开发效率,更有效保障数据安全,把大数据集群的数据、作业、调度任务、业务数据库整体迁移到MaxCompute和其他云产品。
二、适用场景
- 自建Hadoop集群搬迁到MaxCompute
- 自建Hbase集群搬迁到云Hbase
- 自建Kafka或应用数据准实时同步到MaxCompute
- 自建Azkaban搬迁到Dataworks
三、技术架构
四、方案优势
- 安全性:基于IPSec VPN/专线的方式进行数据安全传输。
- 大规模存储:超大规模存储自动扩容,最大可支持EB级别的数据。
- 高性能:同时性能更稳定;如1TB数据规模的TPC-DS,MaxCompute比Spark
快28%,比Hive快76%,比Impala快7%。 - 低成本:相比自建降低30%以上成本。
- 安全:原生的多租户系统,以项目进行隔离,所有计算任务在安全沙箱中运行。
五、自建Hadoop集群规划
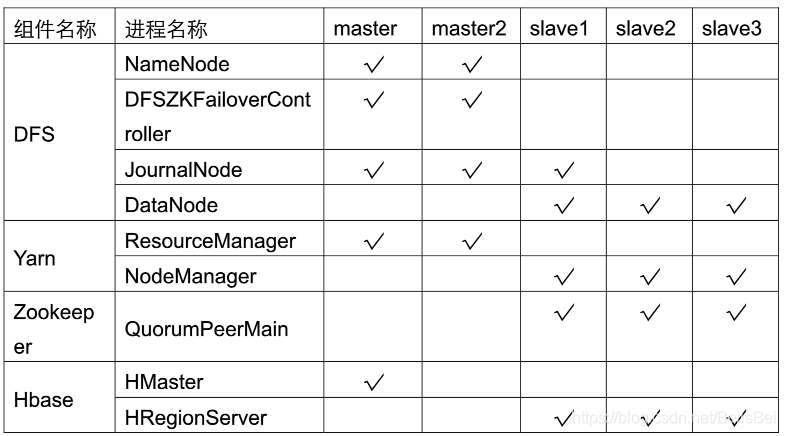
5.1 Hadoop集群安装规划
8台ECS搭建Hadoop基础环境:
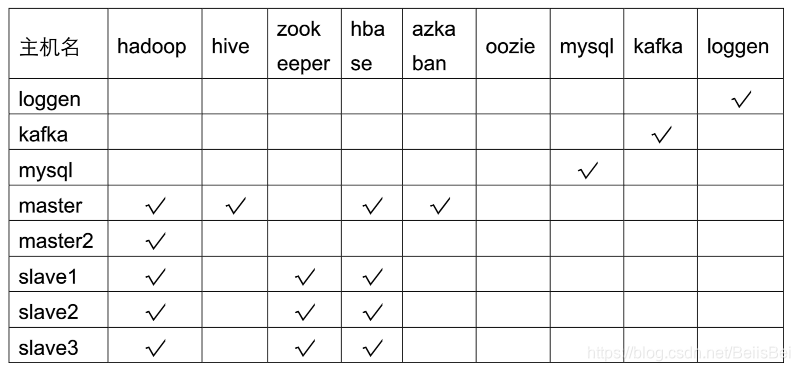
Hadoop生态组件在每台ECS上的运行规划:

5.2 创建 VPC 网络
登录专有网络VPC产品控制台,在专有网络页面,单击创建专有网络。
https://vpc.console.aliyun.com/vpc/cn-shanghai/vpcs
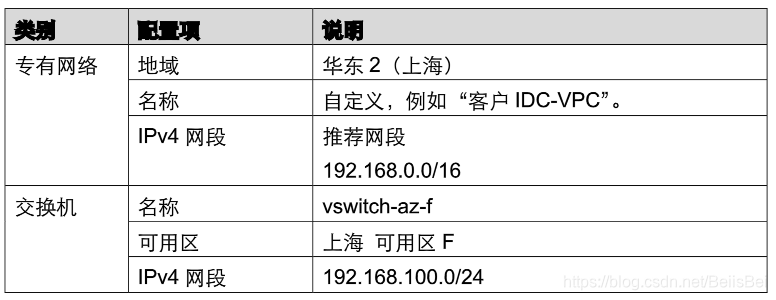
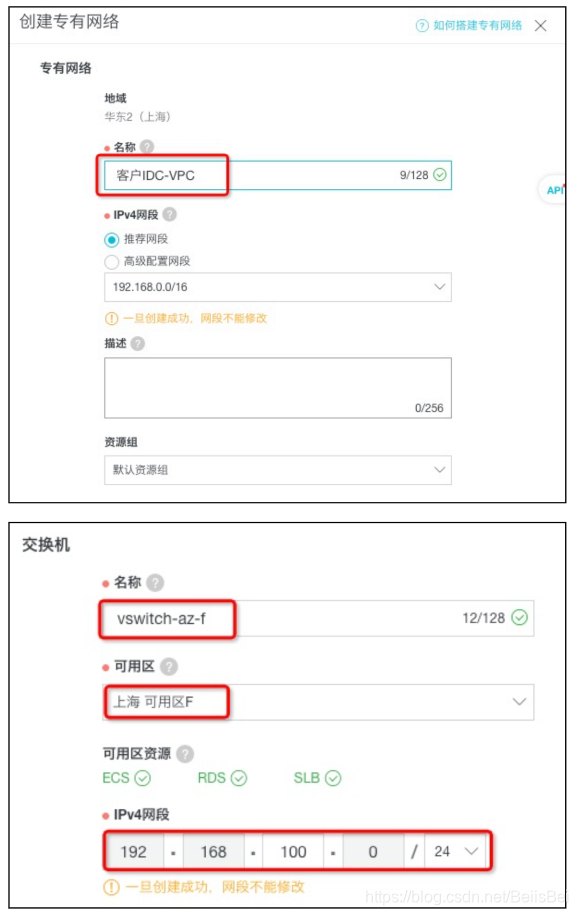
在创建专有网络页面,配置专有网络和交换机相关参数,并单击确定。
等待专有网络和交换机创建成功。
5.3 批量创建 ECS 实例
登录所建地域的ECS产品控制台。
https://ecs.console.aliyun.com/#/server/region/cn-shanghai
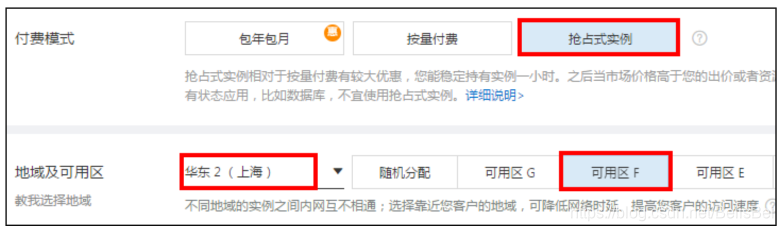
在实例列表页面,单击右上角的创建实例 (推荐:抢占式实例)。
在自定义购买模式下,配置相关参数。

配置完成,单击下一步:网络和安全组。
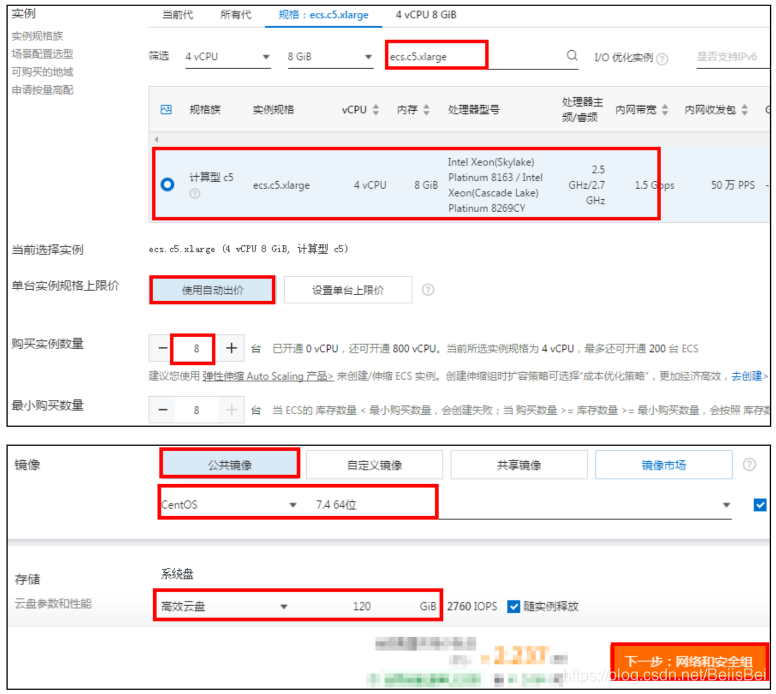
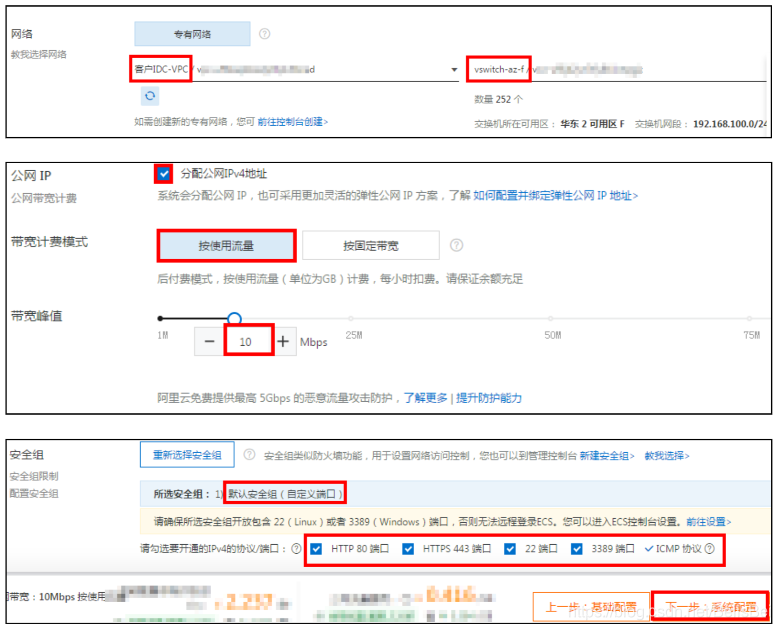
在网络和安全组页面,配置相关参数。

配置完成,单击下一步:系统配置。
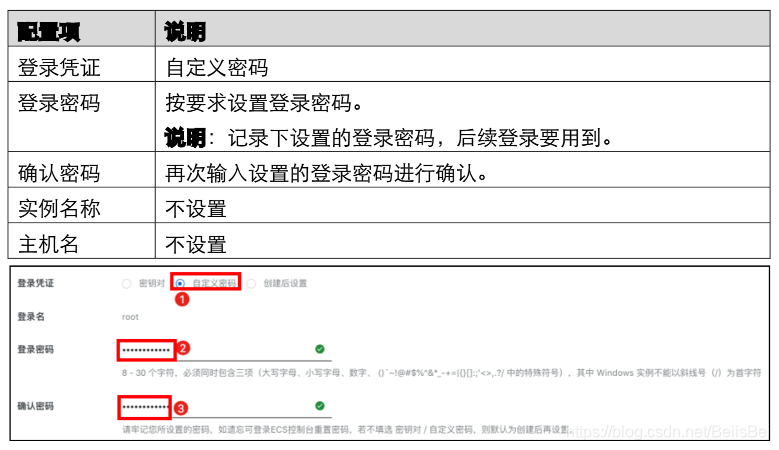
在系统配置页面,完成以下配置。
单击展开高级选项配置,在实例自定义数据处填写Cloud-init脚本,该脚本在创建ECS之后,
自动安装一些必要的组件,并从代码库下载Hadoop软件包。
#!/bin/sh
yum install -y git ruby java-1.8.0-openjdk-devel.x86_64
# for loggen
gem sources --remove https://rubygems.org/
gem sources -a https://gems.ruby-china.com/
gem install apache-loggen -v 0.0.5
mkdir -p /root/archive
# for all
cd /opt/
git clone https://code.aliyun.com/bussiness_support_yunkui/bigdata.git
cat /opt/bigdata/configs/etc-profile >> /etc/profile
source /etc/profile
# for kafka
groupadd kafka
groupadd zookeeper
useradd -g 1000 -m kafka
useradd -g 1001 -m zookeeper
cp -r /opt/bigdata/kafka-2.0.0-1 /opt/
mkdir -p /opt/kafka-2.0.0-1/kafka/tmp
mkdir -p /opt/kafka-2.0.0-1/zookeeper/tmp/
chown -R zookeeper:zookeeper /opt/kafka-2.0.0-1/zookeeper/tmp/
chown -R kafka:kafka /opt/kafka-2.0.0-1/kafka/tmp/
chown -R kafka:kafka /opt/kafka-2.0.0-1/kafka/logs/
#for hadoop
mkdir -p /usr/dfs/
# for MMA
cd /root/
yum install -y python3-pip
wget https://mma-source.oss-cn-shenzhen.aliyuncs.com/odps-data-carrier-0121.tar.gz
tar -xvf odps-data-carrier-0121.tar.gz
# for MySQL
wget https://dev.mysql.com/get/mysql57-community-release-el7-11.noarch.rpm
yum -y localinstall mysql57-community-release-el7-11.noarch.rpm
yum -y install mysql-community-server
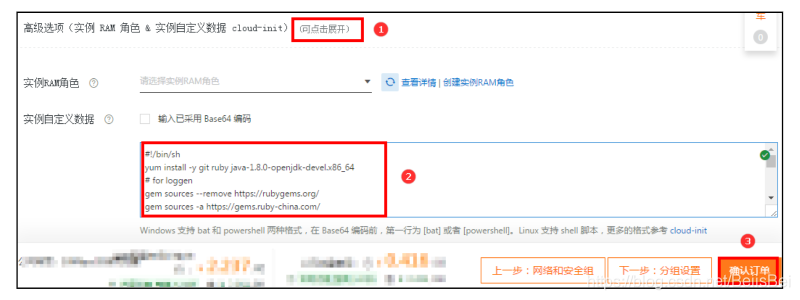
在确认订单页面,确认各项参数信息。确认无误,阅读、同意并勾选《云服务器ECS服务条款》和《镜像商品使用条款》,并单击创建实例。
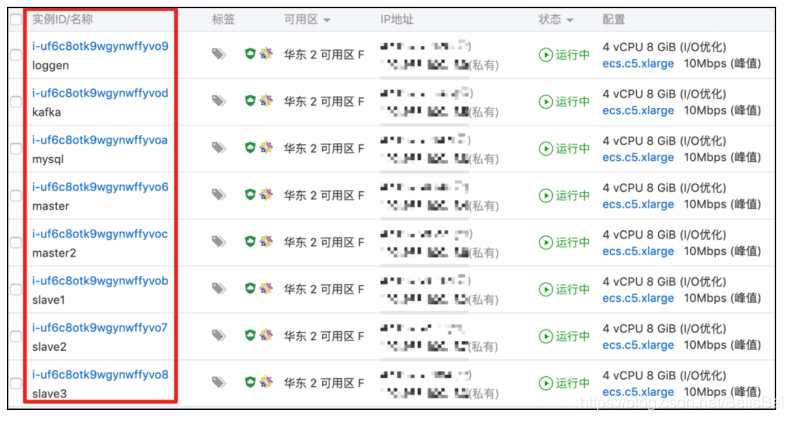
创建任务提交成功后,单击管理控制台前往ECS实例列表页面查看详情。为了在控制台便于识别ECS的用途,首先将实例名称修改为如下图所示:
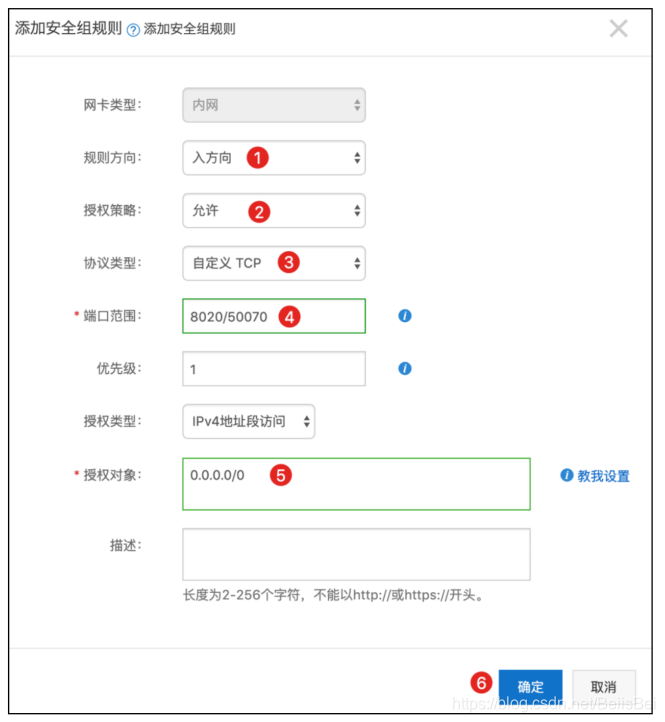
配置安全组
放通Hadoop生态组件所需要的端口:
- 8020/8020 master HA界面
- 8088/8088 yarn的界面
- 8081/8081 azkaban的界面
- 16010/16010 hbase界面
- 50070/50070 hadoop界面
步骤1 在ECS控制台,单击master实例操作列下的更多>网络和安全组>安全组配置。
单击对应安全组操作列下的配置规则。
步骤2 在入方向页签下,单击添加安全组规则。
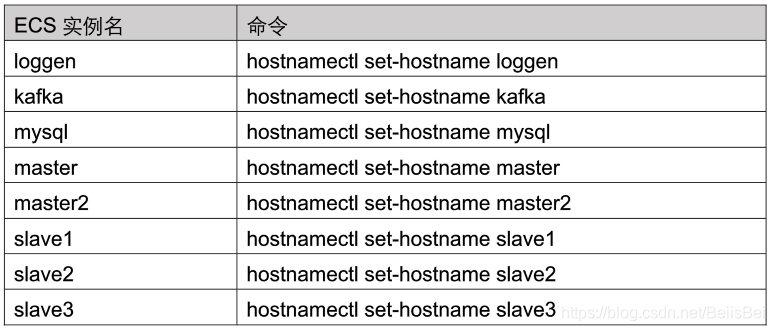
5.4 初始化配置
步骤1
通过SSH登录到各个ECS的后台,修改主机名。
主机名保持和下面的一致,这样后面hadoop软件栈的配置文件不需要修改。
修改各ECS的主机名之后,断开SSH重新连接查看效果。
各ECS节点修改/etc/hosts,加入各个IP地址和hostname的对应关系,所有节点保持一致。
vim /etc/hosts
1.首先删除默认的配置:

将下面的配置添加到/etc/hosts文件中,保存后退出:
192.168.100.147loggen
192.168.100.145kafka
192.168.100.141mysql
192.168.100.146master
192.168.100.144master2
192.168.100.143slave1
192.168.100.140slave2
192.168.100.142slave3
5.5 配置hadoop各ECS之间的无密钥登录
步骤1
hadoop各ECS节点生成密钥:master,master2,slave1,slave2,slave3。
ssh-keygen -t rsa -N '' -f /root/.ssh/id_rsa -q
master节点执行:将hadoop各节点的公钥导入到master节点的authorized_keys文件中。
cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys
ssh master2 "cat /root/.ssh/id_rsa.pub" >> /root/.ssh/authorized_keys
ssh slave1 "cat /root/.ssh/id_rsa.pub" >> /root/.ssh/authorized_keys
ssh slave2 "cat /root/.ssh/id_rsa.pub" >> /root/.ssh/authorized_keys
ssh slave3 "cat /root/.ssh/id_rsa.pub" >> /root/.ssh/authorized_keys
cat /root/.ssh/authorized_keys
master节点执行:将master节点的authorized_keys分发到其他hadoop节点。
scp /root/.ssh/authorized_keys root@master2:/root/.ssh/
scp /root/.ssh/authorized_keys root@slave1:/root/.ssh/
scp /root/.ssh/authorized_keys root@slave2:/root/.ssh/
scp /root/.ssh/authorized_keys root@slave3:/root/.ssh/
master节点执行:验证无密钥登录并设置hadoop各节点的主机名。
ssh master2
exit
ssh slave1
exit
ssh slave2
exit
ssh slave3
exit
5.6 loggen操作
步骤1通过SSH登录ECS,启动日志发生器。
cd /opt/bigdata/loggen
./start_log_generator.sh
验证日志生成情况:
./view_access_log_records.sh
Ctrl+C退出。
添加定时任务:该定时任务将重启日志发生器,并将滚动的日志移动到归档目录。
crontab -e
59 23 * * * mv /root/access*.log /root/archive/
0 */2 * * * /opt/bigdata/loggen/stop_log_generator.sh
1 */2 * * * /opt/bigdata/loggen/start_log_generator.sh
5.7 Kafka操作
步骤1通过SSH登录ECSKafka节点,启动Kafka。
ctlscript.sh start
ctlscript.sh status

5.8 Zookeeper操作
步骤1通过SSH登录到Slave实例节点,在slave1,2,3分别添加myid文件。
slave1节点: echo 1 >/opt/bigdata/zookeeper/data/myid
slave2节点: echo 2 >/opt/bigdata/zookeeper/data/myid
slave3节点: echo 3 >/opt/bigdata/zookeeper/data/myid
5.9 Hadoop操作
首次启动严格按照下列顺序进行。
步骤1在slave1,2,3节点分别启动zookeeper。
zkServer.sh start
在slave1,2,3节点分别检查zookeeper的状态。
zkServer.sh status
有两个节点的Mode是follower,一个节点的Mode是leader。

在master,master2,slave1分别启动JournalNode。
hadoop-daemon.sh start journalnode
在master节点格式化namenode。
hdfs namenode -format
在master节点将name文件夹拷贝到master2节点。
scp -r /usr/dfs/name master2:/usr/dfs/
在master节点格式化zkfc。
hdfs zkfc -formatZK
在master节点启动hadoop集群。
start-all.sh
master2节点上查看ResourceManager是否已经启动。
jps |grep -i resourcemanager
如果没有的话执行:
yarn-daemon.sh start resourcemanager
将master节点设置为namenode的active节点:
在master2节点执行:
hdfs haadmin -getServiceState nn1 //查看master节点对应的状态
hdfs haadmin -getServiceState nn2 //查看master2节点对应的状态

说明:如果nn1的状态为standby,则登录到master2节点,
kill -9 <pid_of_namenode_on_master2>
此时将自动failover到master节点作为active节点。
验证:在master节点上传一个文件到HDFS文件系统。
cd /opt/bigdata
hadoop fs -put version.txt /
hadoop fs -ls -R /

5.10 Flume操作
步骤1ECS loggen节点:启动Flume,日志信息将从loggen节点发送到Kafka节点中的
Topic。
cd /opt/bigdata/flume
nohup flume-ng agent --conf conf/ --name a1 --conf-file job_test/flume-
kafka.conf &
ECS kafka节点:检查topic中的信息:界面上需要有日志消息刷新。
kafka-console-consumer.sh --bootstrap-server kafka:9092 --topic log-
generator-topic
Ctrl+C退出执行。
步骤2ECS kafka节点:启动Flume,日志信息将从kafka节点发送到hadoop的HDFS中。
cd /opt/bigdata/flume
nohup flume-ng agent --conf conf/ --name agent --conf-file job_test/flume-
kafka2hdfs.conf &
ECS master节点:查看HDFS上检查是否生成文件。
hadoop fs -ls -R /

每10分钟进行一次日志文件滚动,未滚动时HDFS上以*.tmp后缀显示。
5.11 MySQL操作
步骤1 SSH登录到MySQL后台,启动MySQL:
systemctl start mysqld
步骤2 查看初始密码。
grep 'temporary password' /var/log/mysqld.log

步骤3 修改密码。
mysql -uroot -p
输入初始密码后,进入mysql命令行,修改密码为Test@1234
set password = password('Test@1234');
创建用户:其中红色IP地址段为vswitch网段,密码为Test@1234
create user 'root'@'192.168.100.%' identified by 'Test@1234';
grant all on *.* to 'root'@'192.168.100.%';
exit
5.12 Hive操作
步骤1 master节点执行下列命令初始化Hive元数据库。
schematool -dbType mysql -initSchema -verbose
启动MetaStore服务。
nohup hive --service metastore &
创建Hive数据仓库。
hive
create database log_data_warehouse;
use log_data_warehouse;
创建表:该表用于保存从HDFS加载的原始日志文件。
CREATE TABLE apache_logs(
ipaddr STRING,
identity STRING,
username STRING,
accesstime STRING,
request STRING,
status STRING,
size STRING,
referer STRING,
agent STRING)
PARTITIONED BY (dsstring)
ROW FORMAT SERDE 'org.apache.hadoop.hive.contrib.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
"input.regex" = "([^ ]*) ([^ ]*) ([^ ]*) (\\[.*\\]) (\".*?\") (-|[0-9]*) (-|[0-9]*) (\".*?\") (\".*?\")",
"output.format.string" = "%1$s %2$s %3$s %4$s %5$s %6$s %7$s %8$s %9$s"
)
STORED AS TEXTFILE;
退出hive。
exit;
5.13 Hbase操作
步骤1master节点执行命令,启动hbase。
start-hbase.sh
master节点执行,创建hbase表。
hbase shell
create 'job99_ip_statics','cf1'
create 'job98_user_detail','cf1'
exit
master节点执行,创建hive外部表关联hbase表。
hive
use log_data_warehouse;
CREATE EXTERNAL TABLE hbase_external_table_job99_ip_statics(
key String,
log_record_date string,
ipaddr string,
ip_count_value String,
process_date string
)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES (
"hbase.columns.mapping" = ":key, cf1:log_record_date, cf1:ipaddr,
cf1:ip_count_value, cf1:process_date")
TBLPROPERTIES (
"hbase.table.name" = "job99_ip_statics",
"hbase.mapred.output.outputtable" = "job99_ip_statics"
);
CREATE EXTERNAL TABLE hbase_external_table_job98_user_detail
(
key String,
request_ipaddr string,
request_accesstime string,
request_method String,
request_url string,
response_status string,
response_size string,
user_device_type string,
user_type string,
request_referer string,
request_agent string,
process_date string
)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES (
"
hbase.columns.mapping" =
":key,
cf1:request_ipaddr, cf1:request_accesstime, cf1:request_method, cf1:request_url,
cf1:response_status,
cf1:response_size, cf1:user_device_type, cf1:user_type, cf1:request_referer,
cf1:request_agent, cf1:process_date"
)
TBLPROPERTIES (
"hbase.table.name" = "job98_user_detail",
"hbase.mapred.output.outputtable" = "job98_user_detail"
);
exit;
5.14 Azkaban操作
步骤1在mysql节点执行下面命令,创建azkaban需要使用的数据库和数据表。
cd /opt/bigdata/azkaban/azkaban-db-0.1.0-SNAPSHOT
mysql -uroot -p
输入密码Test@1234后执行以下命令:
mysql> CREATE DATABASE IF NOT EXISTS azkaban;
mysql> use azkaban;
mysql> alter database azkaban character set Latin1;
mysql> source create-all-sql-0.1.0-SNAPSHOT.sql;
mysql> show tables;
mysql> exit
在master节点启动Azkaban。
cd /opt/bigdata/azkaban/exec-server/bin
./start-exec.sh
curl -G "localhost:$(<./executor.port)/executor?action=activate" && echo
cd /opt/bigdata/azkaban/web-server/bin
/start-web.sh
验证:
jps |grep Azkaban

登录web界面:http://master节点的ip地址:8081
输入默认用户名azkaban 和默认密码azkaban 进入管理界面。
将测试工程下载到本地电脑:
单击AzkabanWeb界面右上角的CreateProject,填写参数。
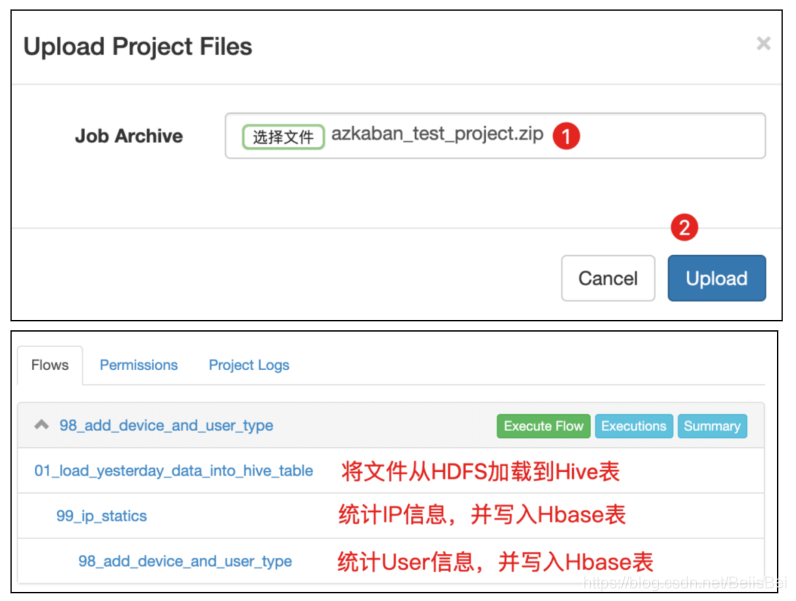
上传测试工程包。
设置定时任务,每天凌晨1点执行。
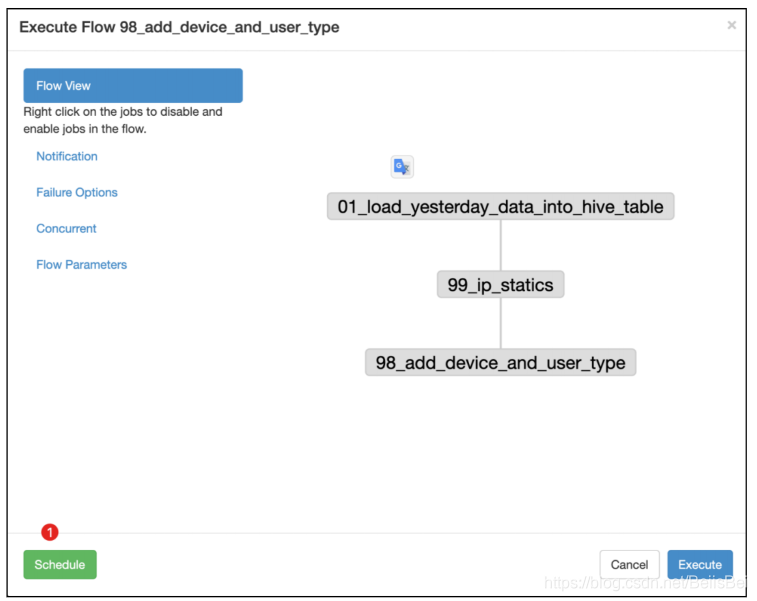
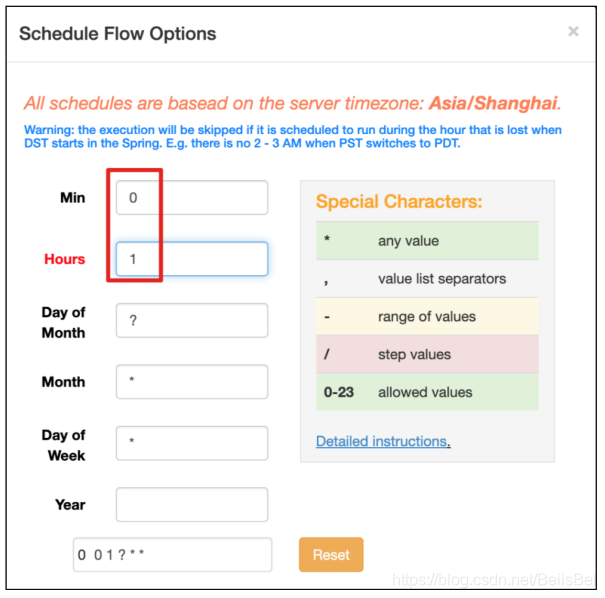
单击界面上的Schedule按钮,完成定时任务的创建。
第二天通过history查看执行结果。
六、创建 DataWorks 工作空间
步骤1 通过主账号登录到Dataworks控制台。https://workbench.data.aliyun.com/#/projectlist
步骤2 切换到上海地域,并单击创建工作空间按钮。

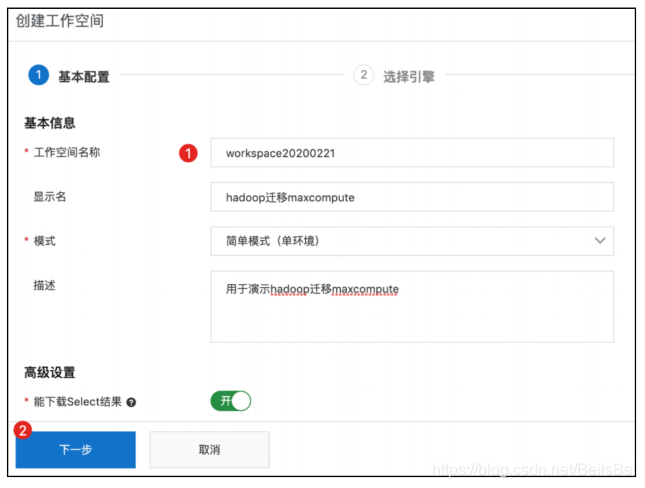
步骤3 在基本配置页面,设置工作空间名称,并单击下一步。
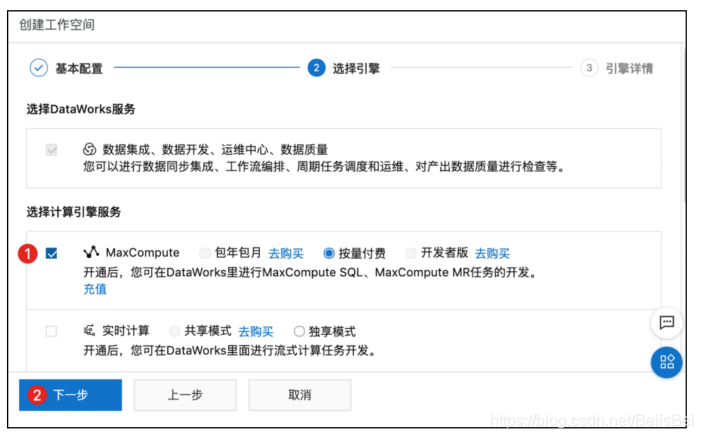
步骤4 选择MaxCompute按量付费模式,单击下一步。
步骤5 设置实例显示名称,单击创建工作空间。
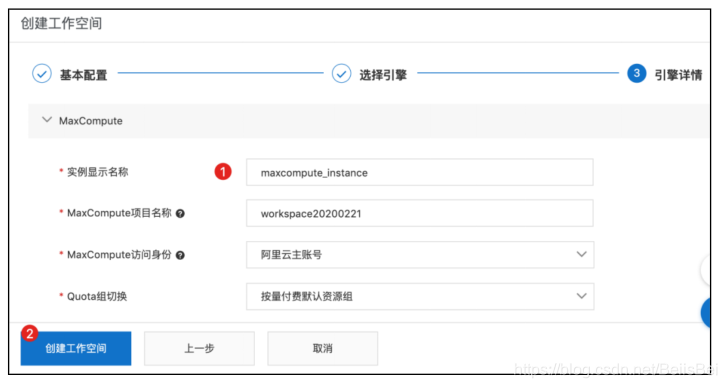
完成后在工作空间列表可看到创建的工作空间。

七、Hive数仓迁移到MaxCompute
本章主要介绍Hive数仓数据如何迁移到MaxCompute。
7.1 配置MMA迁移工具
在创建各个ECS时,已经通过Cloud-init脚本下载了需要使用的MMA(MaxCompute Migration Assist)数据迁移工具。

关于MMA工具的详细用法说明,请查看:
https://help.aliyun.com/document_detail/149668.html
步骤1 在master2节点上查看工具。
cd /root/
ls -l
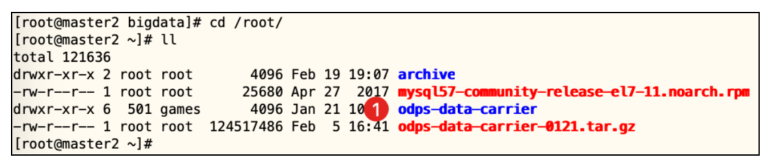
步骤2 配置odps_config.ini文件。
cd /root/odps-data-carrier
vimodps_config.ini
编辑文件中对应的参数,保存后退出:
project_name=workspace20200221
access_id=LTAI********MxGo//替换为您的AK
access_key=J1***********eU8//替换为您的SK
end_point=http://service.cn-shanghai.maxcompute.aliyun-inc.com/api
关于end_point,本方案使用VPC网络下上海地域的Endpoint地址,详细信息请查
看:https://help.aliyun.com/document_detail/34951.html

准备Hive到MaxCompute表的映射文件。
文件格式为:
<hive db>.<hive table>:<maxcompute project>.<maxcompute table>
本实践方案中:
hivedb: log_data_warehouse
hive table: apache_logs
maxcompute project: workspace20200221
maxcompute table: odps_apache_logs
步骤3 通过下面命令生成mapping文件:
cd /root/odps-data-carrier
vimhive_maxcompute_tables_mapping.ini
将下列内容粘贴到文件中,保存后退出:
log_data_warehouse.apache_logs:workspace20200221.odps_apache_logs
如果你有多个表,请依次添加:

7.2 启动MMA工具进行数据迁移
步骤1 执行如下命令启动数据迁移。
cd /root/odps-data-carrier
python3 ./bin/run.py --mode BATCH --hms_thrift_addr thrift://master:9083 --
table_mapping hive_maxcompute_tables_mapping.ini
步骤2 执行结果如下图所示。
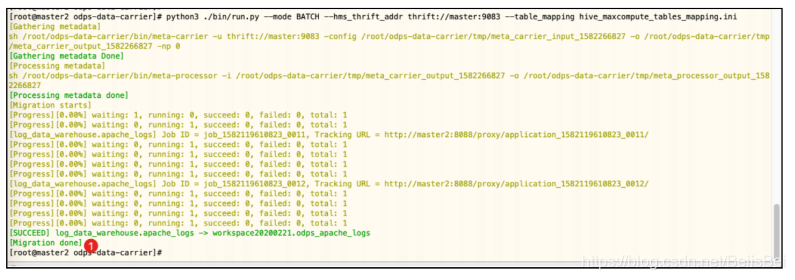
7.3 在MaxCompute查看对应表
步骤1 登录到Dataworks控制台。(https://workbench.data.aliyun.com/?#/)
选择工作空间,进入数据开发。
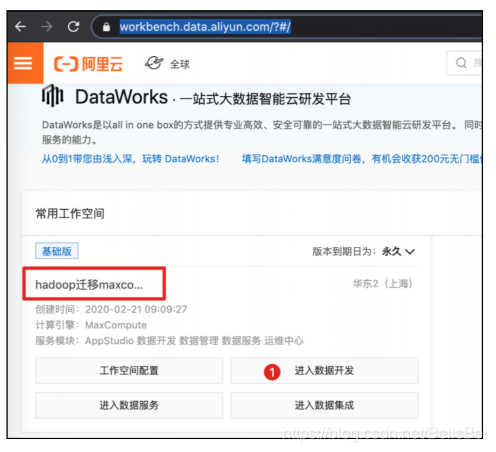
步骤2 按下图所示操作,可以看到odps_apache_logs相关信息。
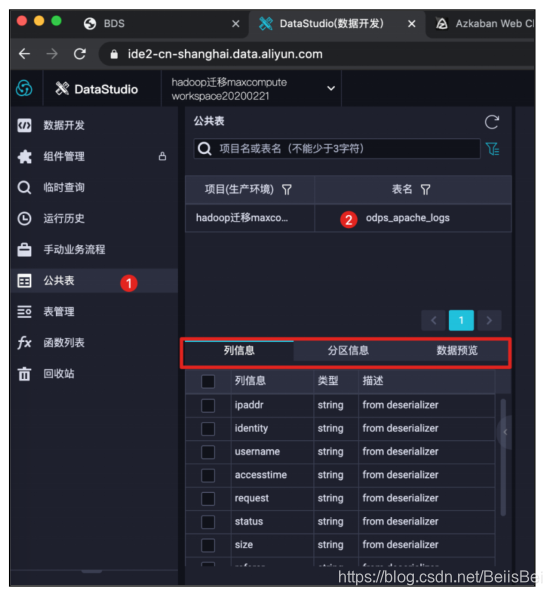
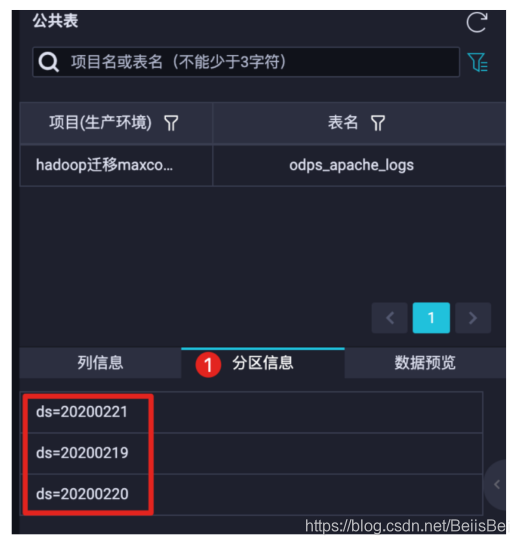
查看表的分区信息,该分区字段和分区信息是从Hive表中自动同步的。
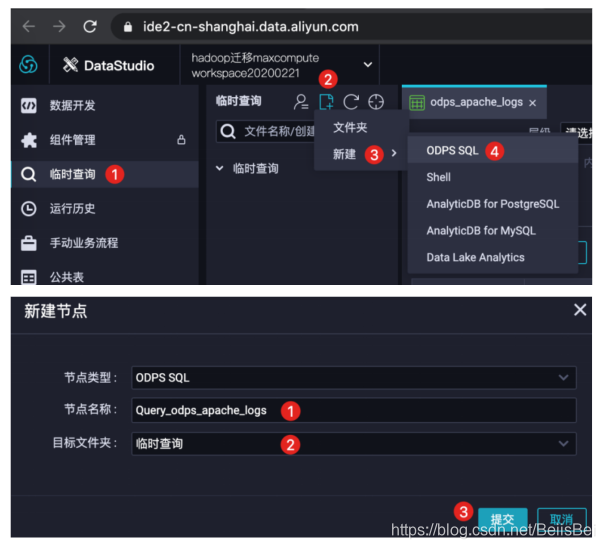
创建临时查询。
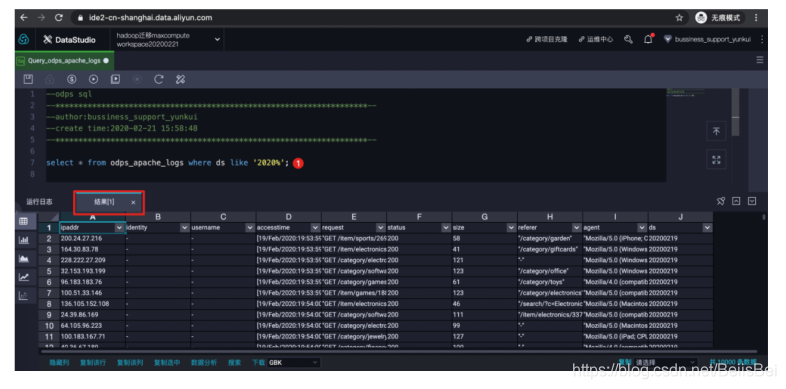
通过SQL语句查看表数据。
select * from odps_apache_logswhere ds like '2020%';
八、Hbase表数据迁移到云数据库Hbase版
Hive数仓中的数据,通过Azkaban定时任务处理后,将结果数据保存到了两张Hbase表。本章介绍如何将Hbase表中的数据迁移到云数据库Hbase版实例。
8.1 创建云Hbase实例
步骤1 通过以下链接登录到云数据库Hbase版上海地域控制台。
https://hbase.console.aliyun.com/hbase/cn-shanghai/clusters
我们将Hbase实例规划在上海地域的可用区B,请参考1.2章节,在同一VPC下的可用区B创建虚拟交换机。
返回云数据库Hbase版控制台,在集群列表页面单击创建Hbase集群。
选择按量计费模式,完成以下配置,并单击立即购买。
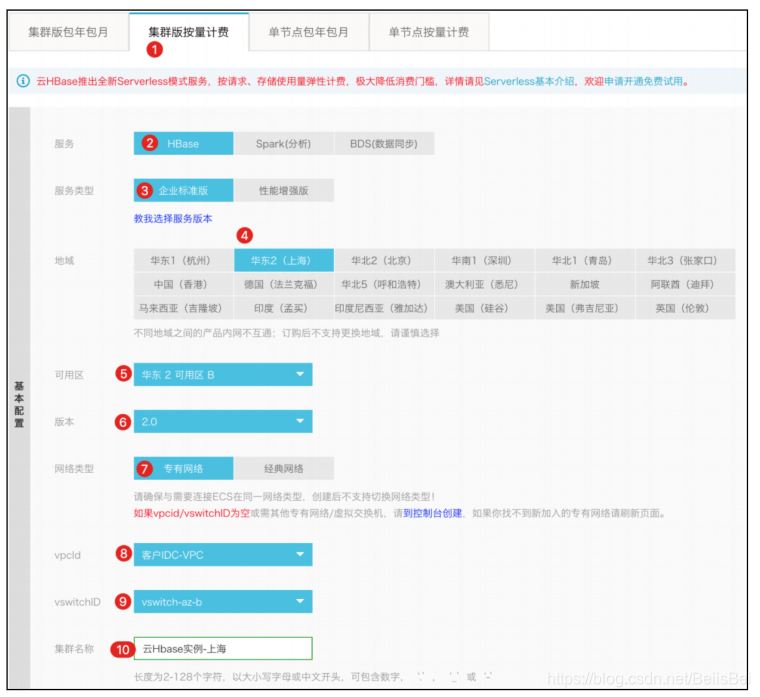
说明:下面截图中的配置规格仅为演示使用。
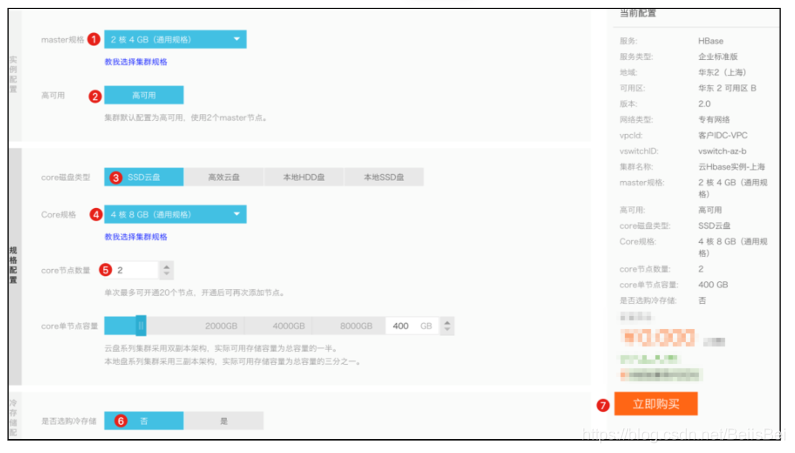
步骤2 约15~20分钟完成创建。
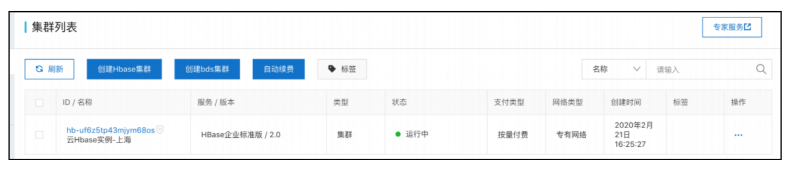
8.2 创建BDS集群
BDS 是阿里云针对HBase自主研发的一套迁移同步服务,主要帮助云上的客户进行自建HBase、云HBase集群的数据导入和导出。
步骤1 通过以下链接登录到云数据库Hbase版控制台。
https://hbase.console.aliyun.com/hbase/cn-shanghai/clusters
在集群列表页面,单击创建BDS集群。
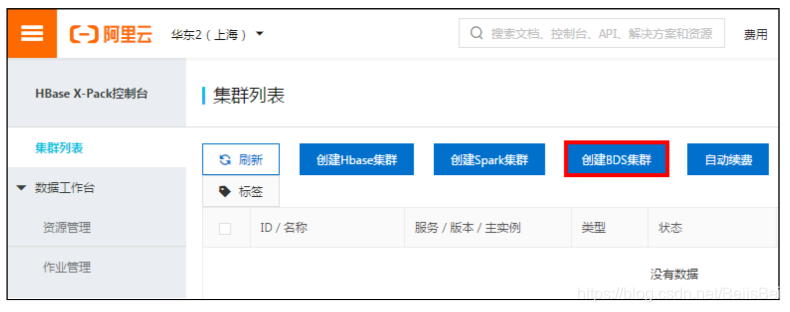
步骤2 选择按量计费模式,完成以下配置,并单击立即购买。

完成创建后状态为运行中:
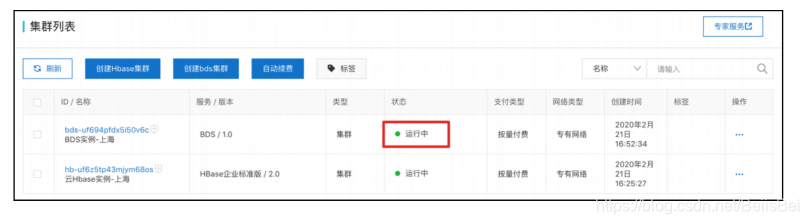
单击上面截图中BDS实例ID链接。
将云数据库Hbase实例添加为目标数据库
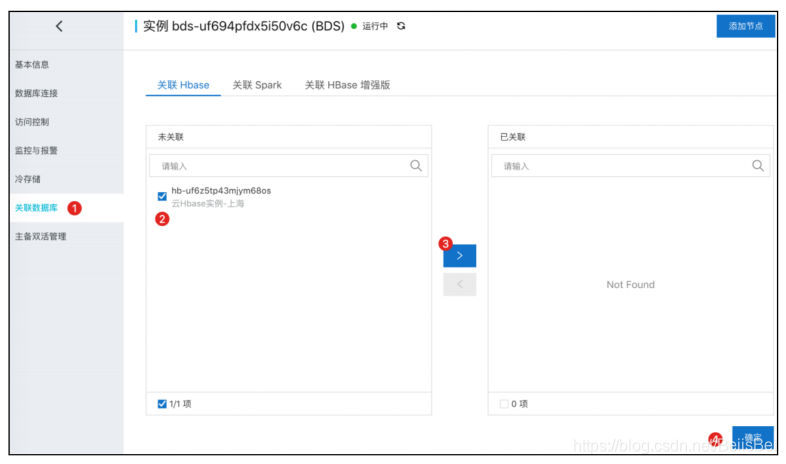
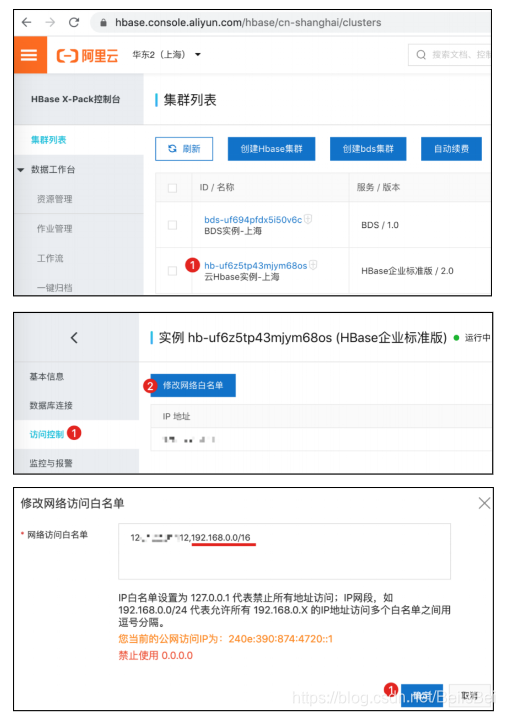
修改访问白名单。

填写您电脑的公网IP地址:

步骤3 设置BDSUI的访问密码。
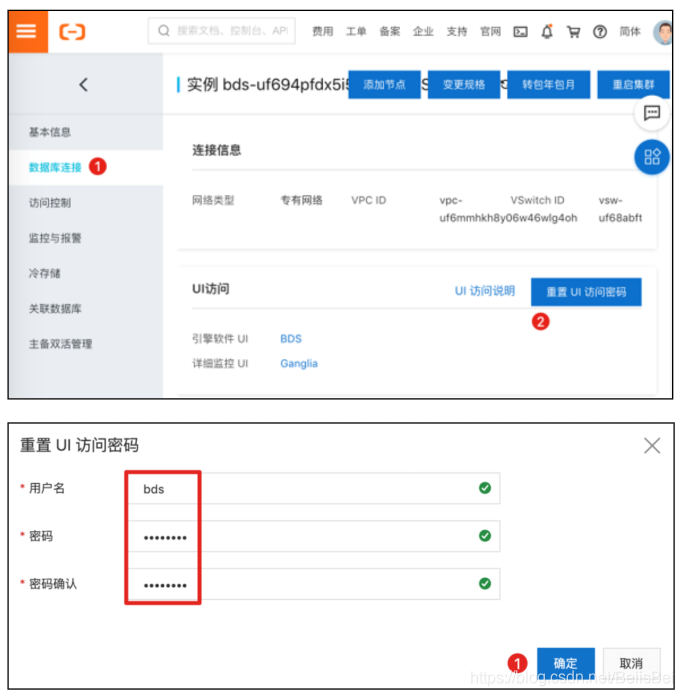
本例中设置密码为Test1234
访问BDSUI。
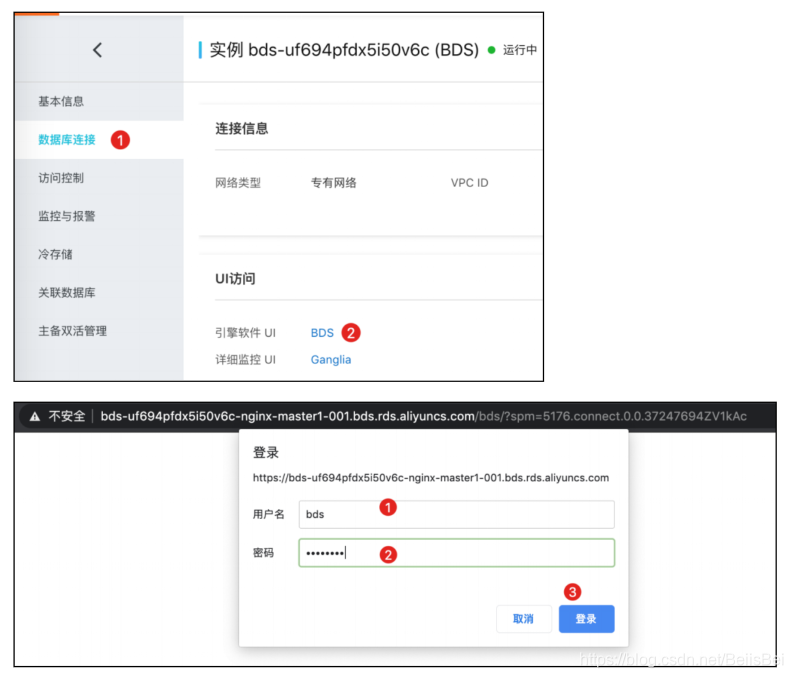
8.3 配置Hbase迁移相关配置
步骤1 将BDS所在网段(192.168.20.0/24)添加到自建HbaseECS(192.168.100.0/24)所在安全组,放开所有端口。
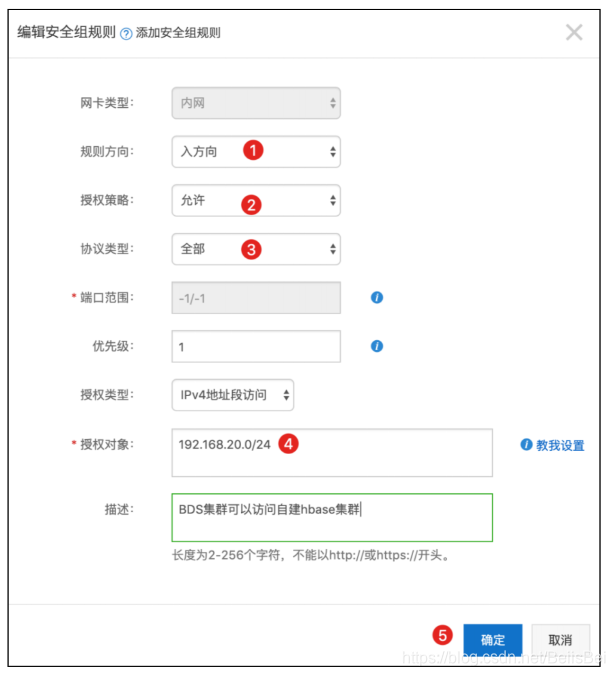
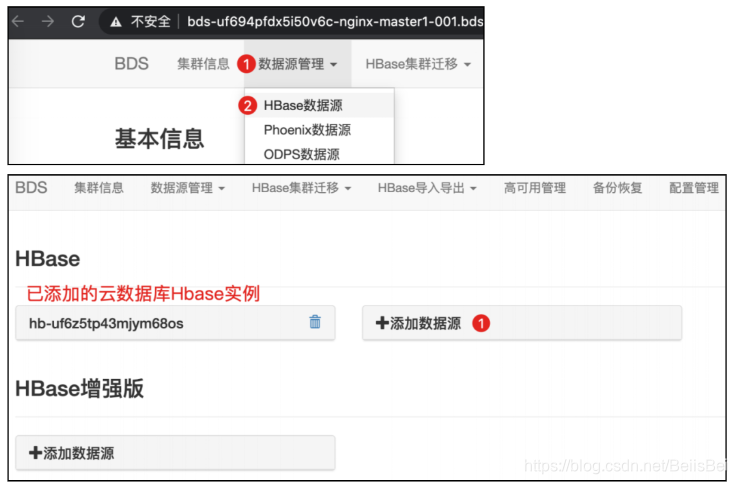
步骤2 将自建Hbase添加为源数据库。

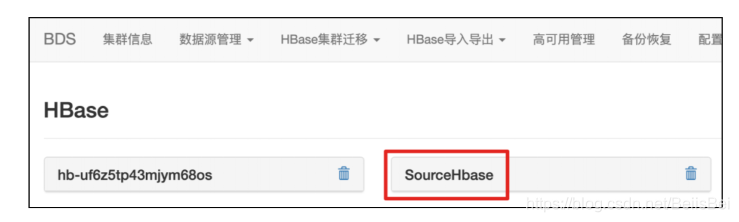
完成后效果如下所示:
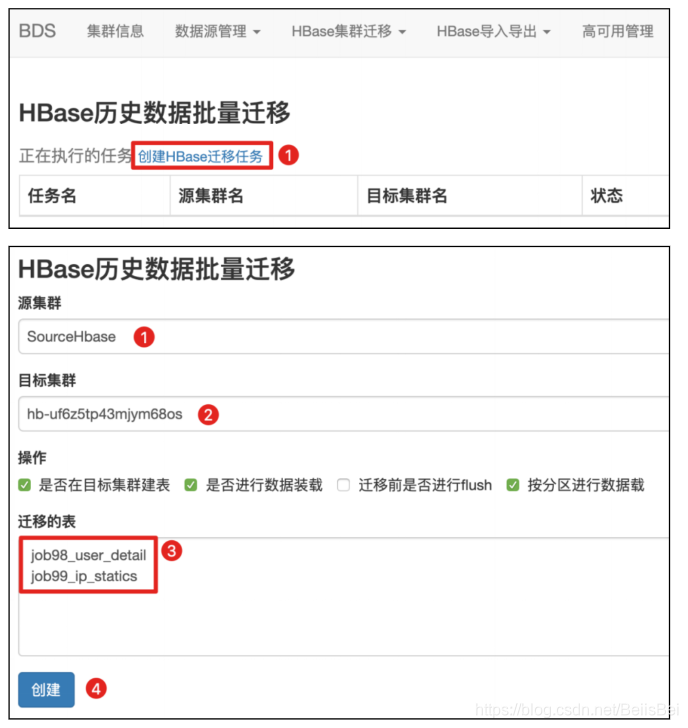
8.4 启动Hbase历史数据迁移
步骤1 进入历史数据迁移界面。

创建Hbase迁移任务。
查看迁移进程。

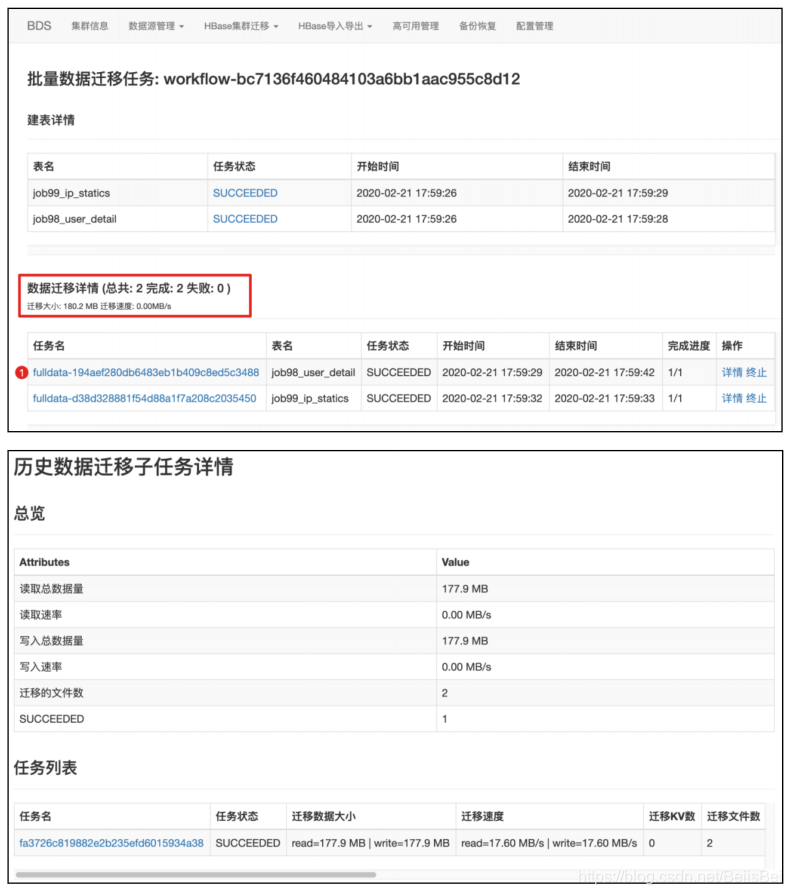
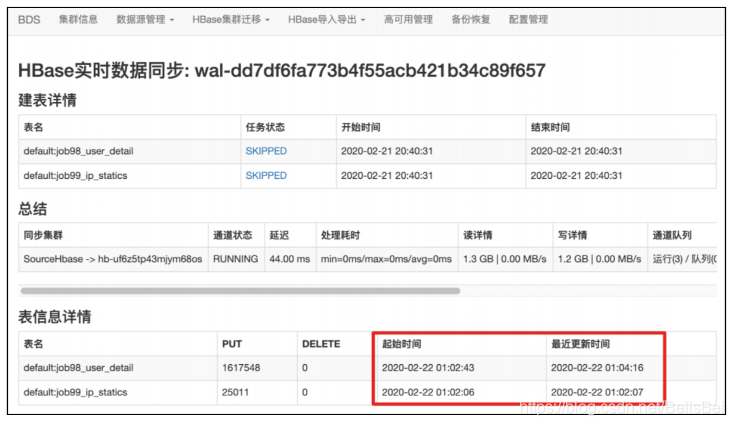
8.5 启动Hbase实时数据同步
如果要进行一段时间的Hbase实时数据同步,则可以启动该任务。本实践方案中,自建Hbase的表数据是在每天凌晨1点钟通过定时任务插入的,4.4节已经迁移了历史数据,这里演示如何创建和启动实时数据同步任务。
步骤1 登录到BDS控制台。
步骤2 选择创建Hbase实时数据同步任务。
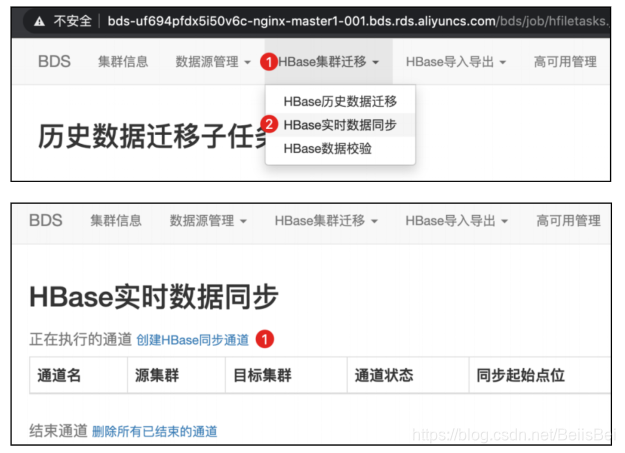
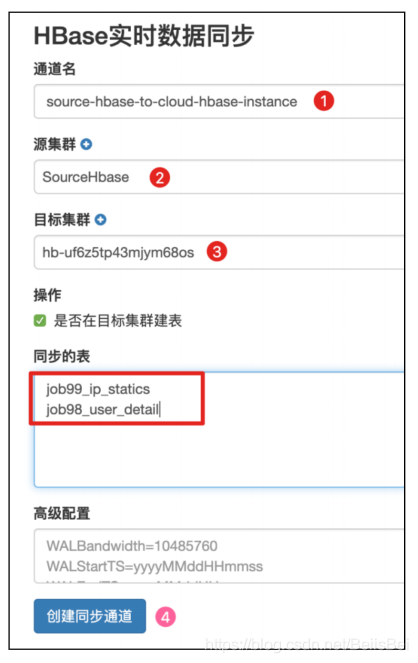
步骤3 查看创建完成的数据同步通道。
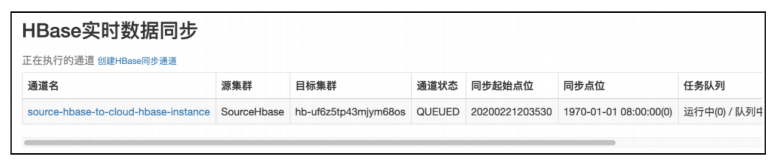
步骤4 第二天白天查看数据同步进展。
- 查看Azkaban任务的执行状态,可以看到在凌晨1点成功执行了定时任务,结果是将HiveSQL的查询结果写入到了Hbase表。

- 通过BDS查看数据实时同步通道的状态。
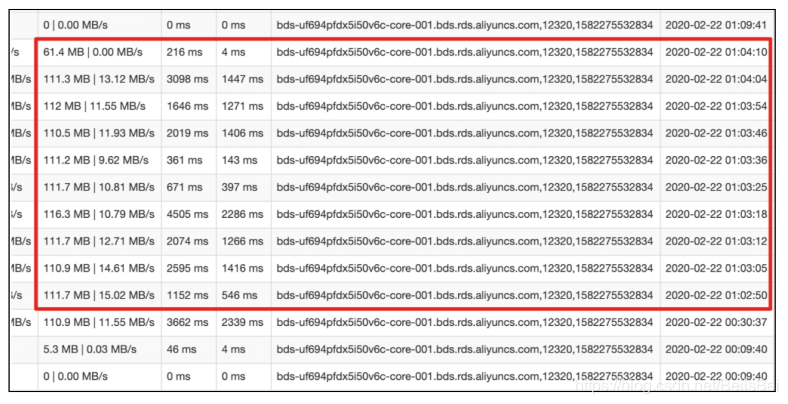
在下面的日志详细信息页面也可以看到对应时间段的同步记录:
九、数据接入组件Kafka迁移到Datahub
自建Hadoop系统中使用Kafka作为数据接入组件,接收来自日志发生器ECS上的Flume发送的数据,Kafka的数据将发送到HDFS,最终由定时任务将数据加载到Hive数据仓库。
在将数据仓库从Hive迁移到MaxCompute之后,用户可以根据实际需要,选择Datahub作为数据接入组件,并通过Datahub的DataConnector将数据准实时同步到MaxCompute数据残酷。客户也可以根据自己的需求,使用阿里云Kafka和阿里云日志服务作为数据接入组件。
本最佳实践的数据流为:日志发生器àDatahubàMaxCompute;使用阿里云Kafka的数据流为:日志发生器àKafkaàMaxCompute;使用SLS日志服务的数据流为Logtail(或LogSDK)àSLSàMaxCompute。
9.1 创建Datahub工程和Topic
步骤1 登录到Datahub控制台并选择上海地域:
https://datahub.console.aliyun.com/datahub
单击右上角的创建Project。
步骤2 设置名称和描述,单击创建。

创建Topic。
单击新建project操作列下的查看。

步骤3 单击右上角的创建Topic。
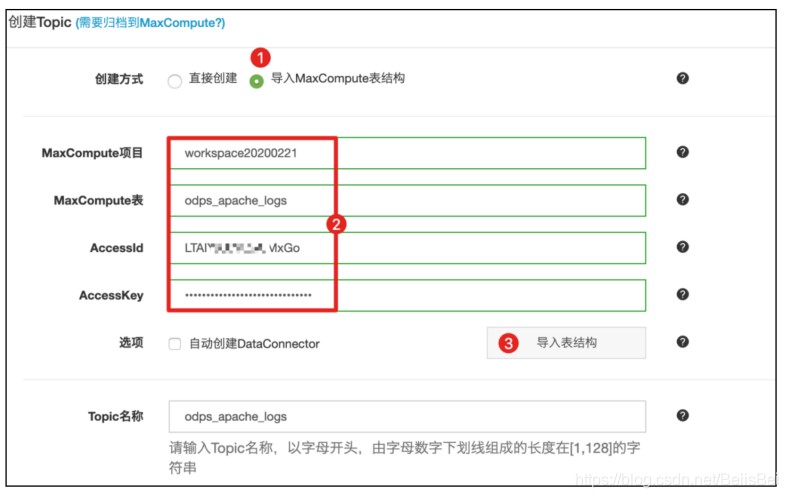
步骤4 在创建Topic对话框中,完成以下配置,并单击创建。
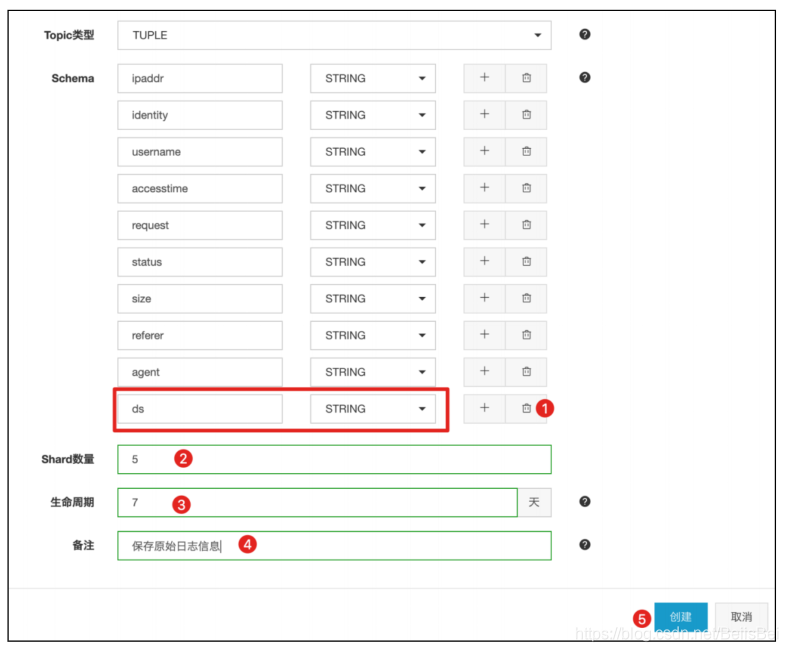
9.2 在ECS loggen上启动新的Flume任务将数据发送到Datahub
本实践方案中,已经将FlumeDatahub插件和配置文件flume-datahub.conf提前准备好,并在cloud-init脚本上下载到/opt/bigdata/flume的对应目录下。
关于FlumeDatahub插件,请查阅以下文档:
https://help.aliyun.com/document_detail/143572.html
步骤1 替换flume-datahub.conf文件中的AK和SK,下面红色部分内容:
cd /opt/bigdata/flume/job_test
sed -i s/YourAccessKeyID/LTAIK****rdA/g flume-datahub.conf
sed -i s/YourAccessKeySecret/DywK********9I0TD/g flume-datahub.conf
其他关键配置如下,使用者根据需要自行修改:
- Datahub项目所在区域的EndPoint。
a1.sinks.k1.datahub.endPoint = http://dh-cn-shanghai-int-vpc.aliyuncs.com
说明:详情请查阅 https://help.aliyun.com/document_detail/47446.html
- Datahub项目名称。
a1.sinks.k1.datahub.project = log_records_project
- Datahub项目中Topic名称。
a1.sinks.k1.datahub.topic = odps_apache_logs
步骤2 启动Flume,将日志数据发送到Datahub的Topic。
cd /opt/bigdata/flume
nohupflume-ng agent --conf conf/ --name a1 --conf-file job_test/flume-datahub.conf &
说明:如果产生日志的应用有多个的话,需要逐个ECS执行步骤1和步骤2. 在Datahub控制台查看日志接收情况。
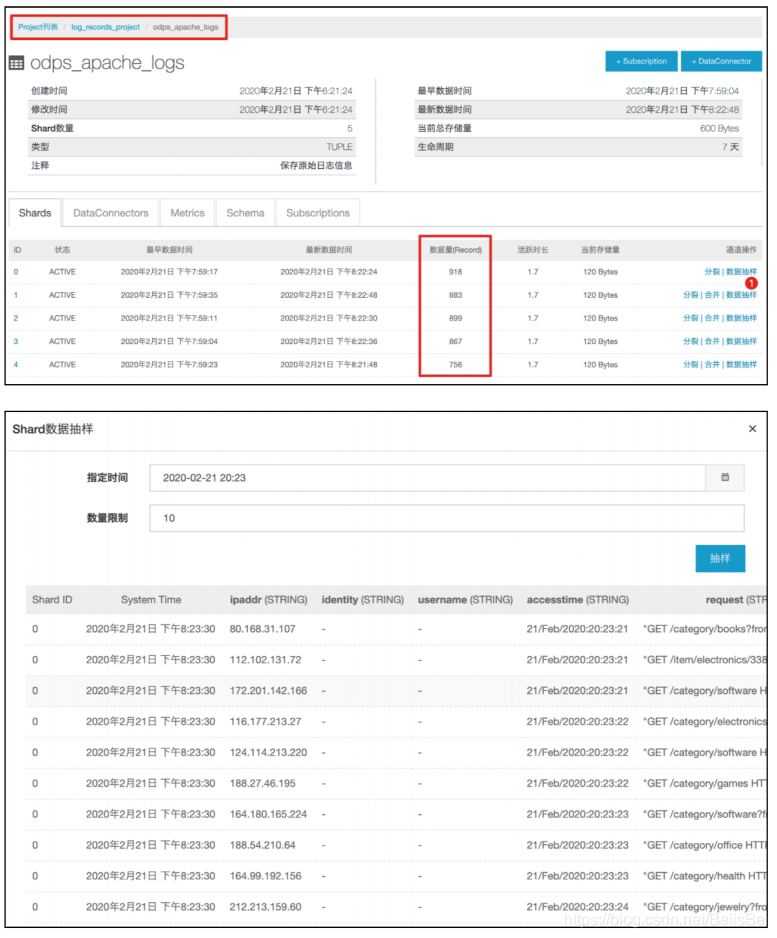
说明:此时,ECS loggen生成的日志数据,将同时发向Kafka和Datahub。使用者选择合适的时机,停止数据发送到Kafka,完成数据接入组件的迁移。
9.3 创建DataConnector将数据从Datahub归档到MaxCompute表
关于DataConnector详细信息,请查阅:
https://help.aliyun.com/document_detail/47453.html
步骤1打开临时查询框:通过以下SQL语句创建MaxCompute表。
CREATE TABLE `datahub_dataconnector_apache_logs` (
`ipaddr` string COMMENT 'from deserializer',
`identity` string COMMENT 'from deserializer',
`username` string COMMENT 'from deserializer',
`accesstime` string COMMENT 'from deserializer',
`request` string COMMENT 'from deserializer',
`status` string COMMENT 'from deserializer',
`size` string COMMENT 'from deserializer',
`referer` string COMMENT 'from deserializer',
`agent` string COMMENT 'from deserializer'
) PARTITIONED BY (ds string, hh string, mm string);
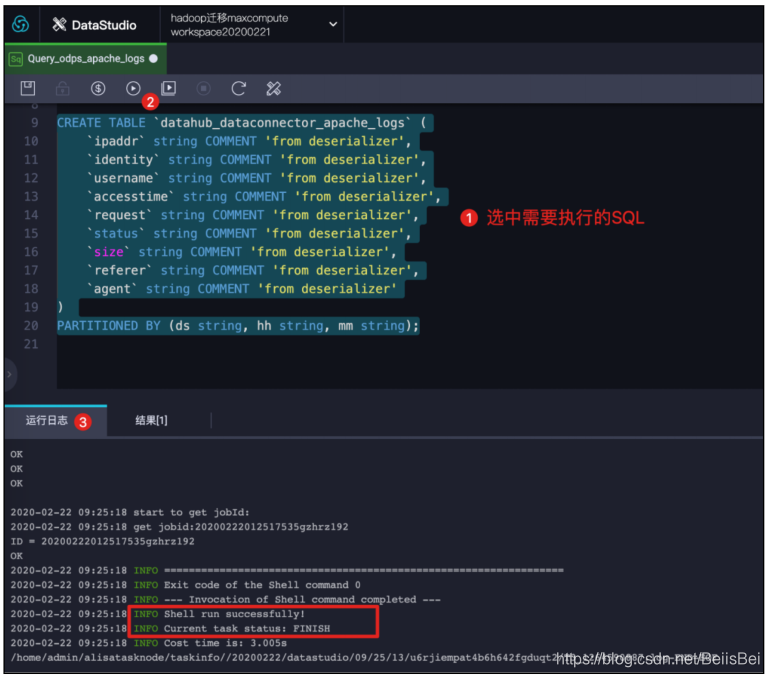
步骤2 为DatahubTopic创建DataConnector。

等待约10-15分钟,查看DataConnector的同步状态。
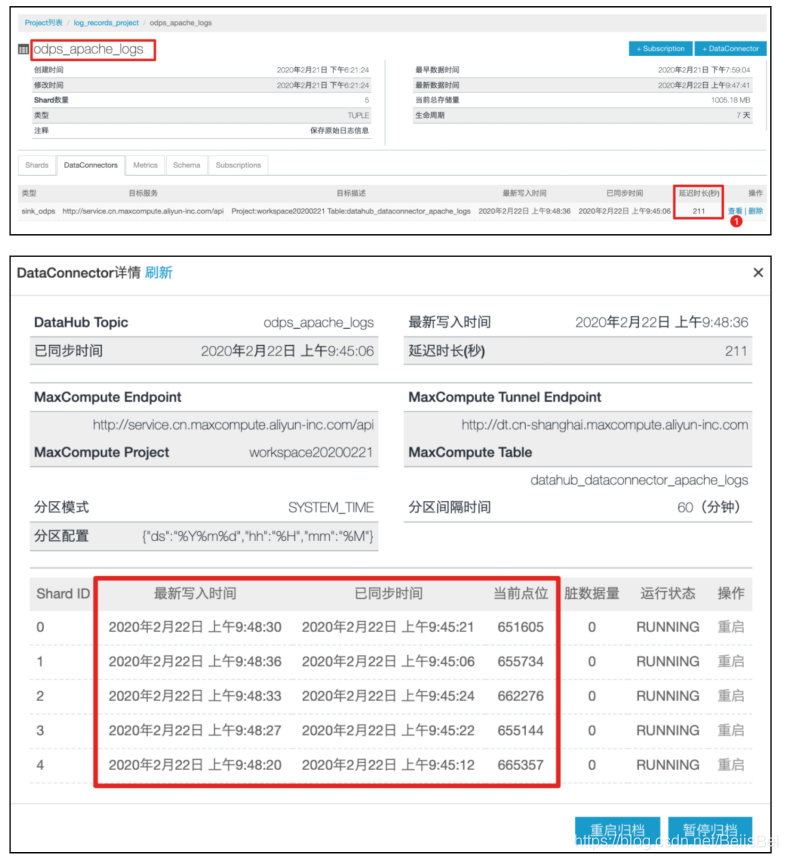
在MaxCompute中查看分区信息。
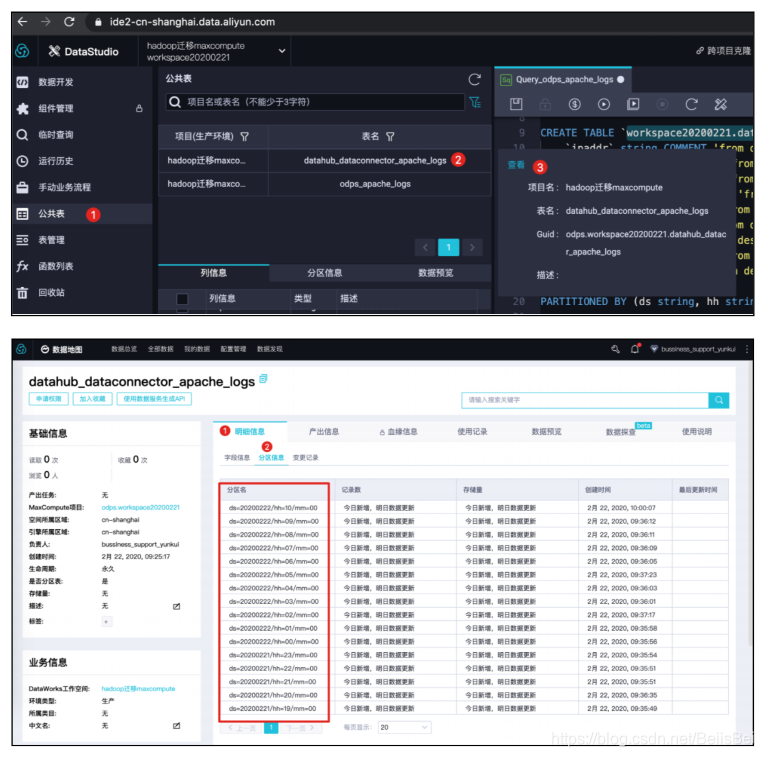
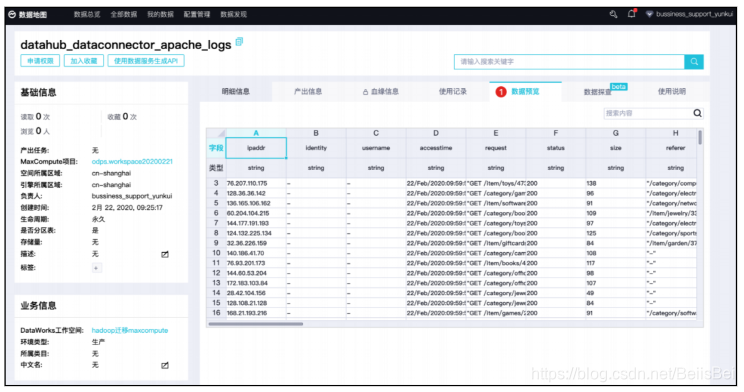
预览数据。
十、Azkaban定时任务迁移和改造

10.1 将表datahub_dataconnector_apache_logs数据灌入odps_apache_logs
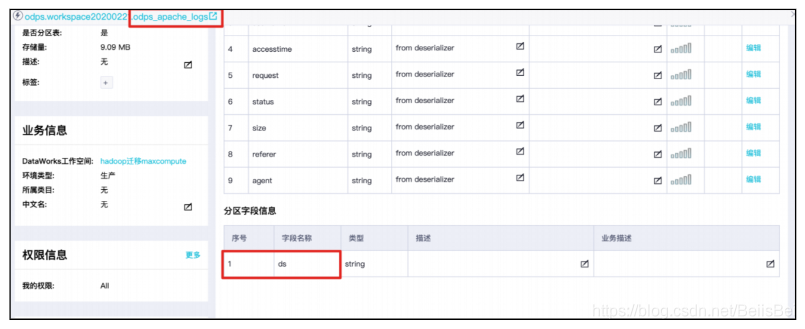
本实践方案中Hive数据仓库中的原始表apache_logs有一个分区字段ds(日期值),每天生成一个分区。在使用MMA工具迁移到MaxCompute表odps_apache_logs的过程中,保留了该分区字段,因此在MaxCompute上可以看到该表有一个分区字段:
Datahub Topic中数据同步到MaxCompute表datahub_dataconnector_apache_logs,有3个分区字段,每小时生成一个分区:
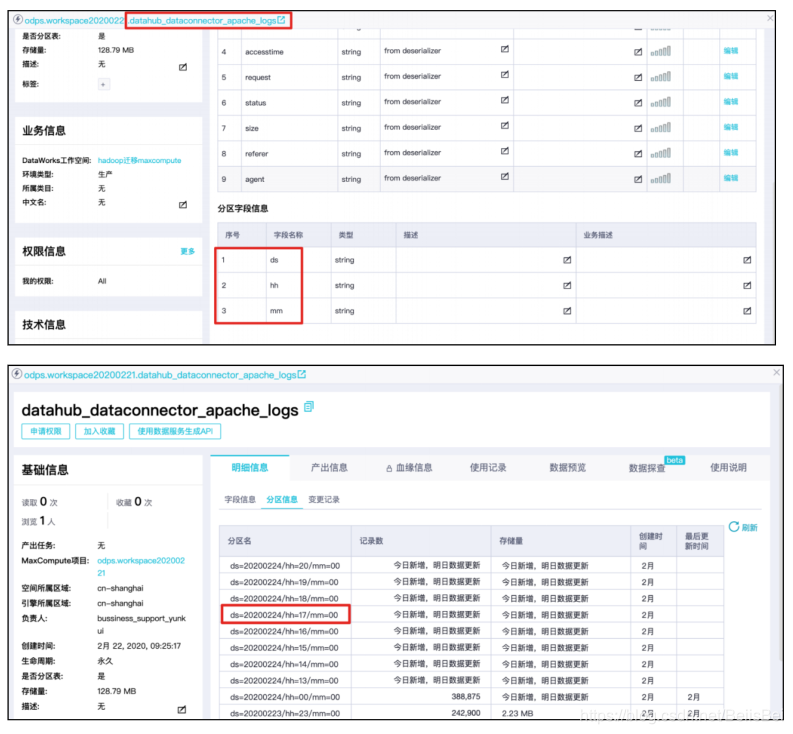
下面步骤我们将创建一个定时调度任务:每小时的第10分钟执行数据集成任务,将datahub_dataconnector_apache_logs表中上一小时分区的数据灌入到表 odps_apache_logs中。例如上面截图中:
在20200224的18点10分,将源表datahub_dataconnector_apache_logs分区ds=20200224/hh=17/mm=00分区的数据,灌入到目标表odps_apache_logs的分区 ds=20200224中。
步骤1 登录到Dataworks数据库开发控制台。(https://ide2-cn-shanghai.data.aliyun.com/)
步骤2 新建业务流程。
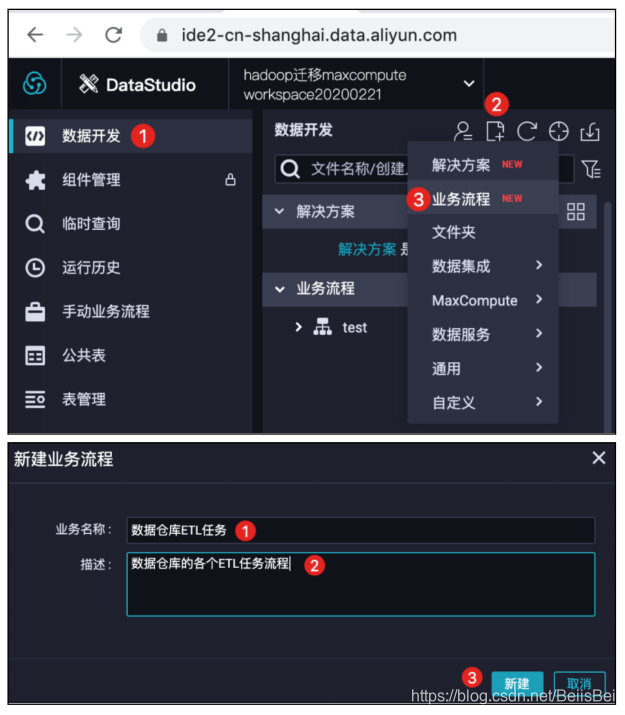
步骤3 新建数据集成离线同步任务。
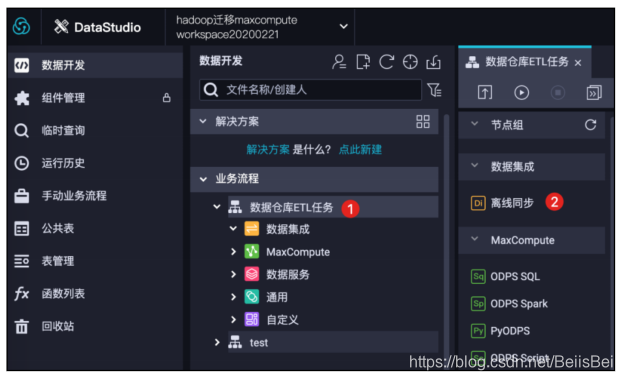

步骤4 双击离线同步任务节点,进行编辑。
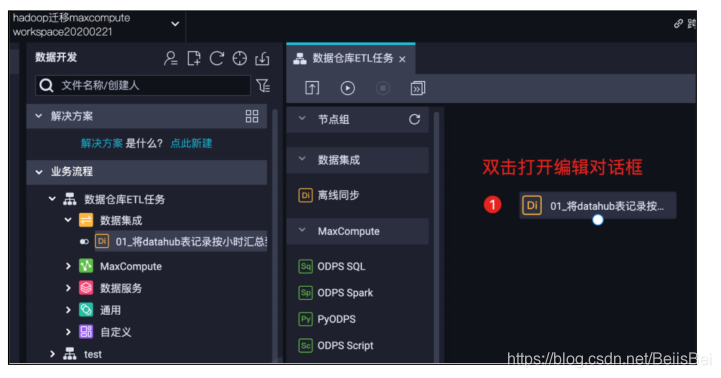
选择数据源并设置分区信息。
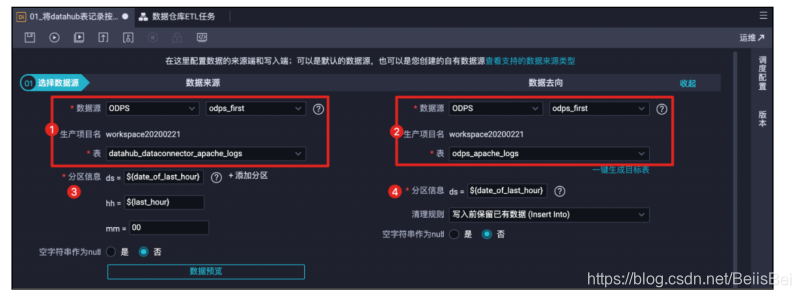
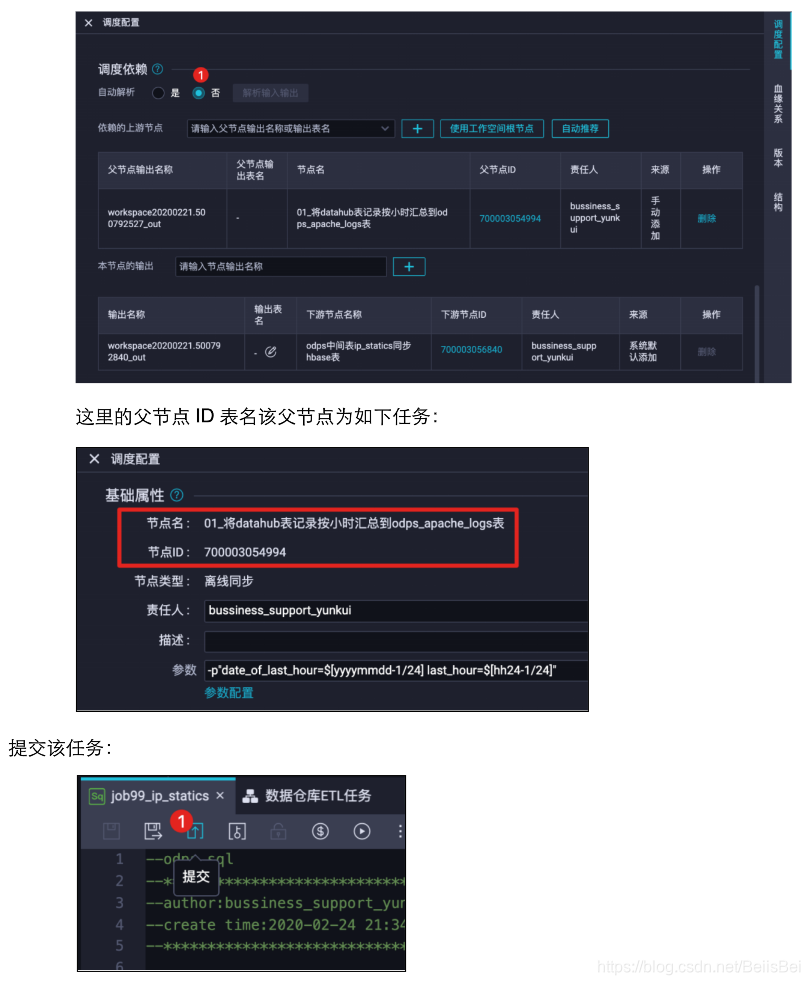
说明:分区信息将决定,抽取源表中的哪些分区的数据,并插入到目标表的哪个分区,是整个数据同步任务的关键。
在本例中,源表datahub_dataconnector_apache_logs有3个分区字段,分别表示日期(ds)、小时(hh)、分钟(mm)。设置抽取数据的规则为:抽取定时任务执行时前一个小时分区的数据。例如,该任务在2020年2月24日18点10分运行,那么将抽取ds=20200224/hh=17/mm=00,并加载到目标表odps_apache_logs的ds=20200224分区中。
- 源表分区取值:
ds=${date_of_last_hour} 变量date_of_last_hour表示取上一个小时的日期
值。
hh=${last_hour} 变量last_hour表示取上一个小时的小时值。
mm=00 因为源表分区是每小时创建的,所以使用00。
- 目标表分区取值:
ds=${date_of_last_hour} 变量date_of_last_hour表示取上一个小时的日期
值。
- 变量的赋值,将在步骤7自定义参数配置中进行。
字段映射和通道控制,在本例中保持默认即可。
设置调度参数:任务被正确调度的关键信息,详情请查看产品文档:
https://help.aliyun.com/document_detail/137548.html
- 基础属性,自定义参数配置:
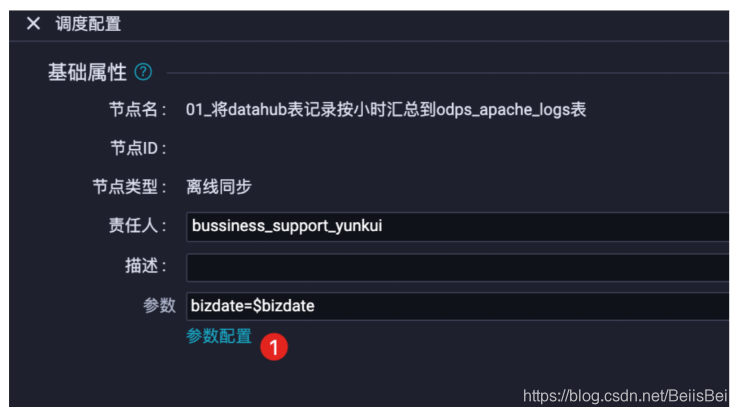
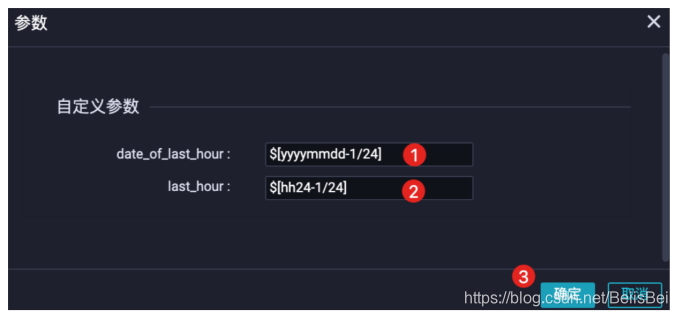
- date_of_last_hour: $[yyyymmdd-1/24]表示取任务执行时间前一个小时的日期值。
- last_hour: $[hh24-1/24]表示取任务执行时间前一个小时的小时值。
结果如下所示:
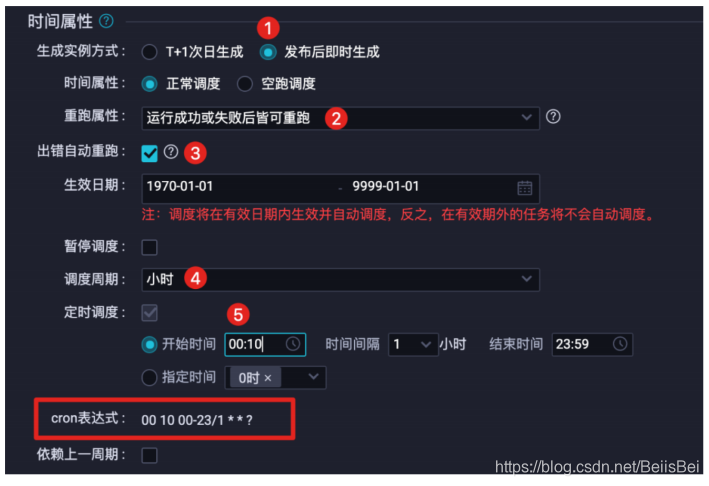
- 时间属性:将在下一个小时的10分被首次调度。
- 调度依赖。
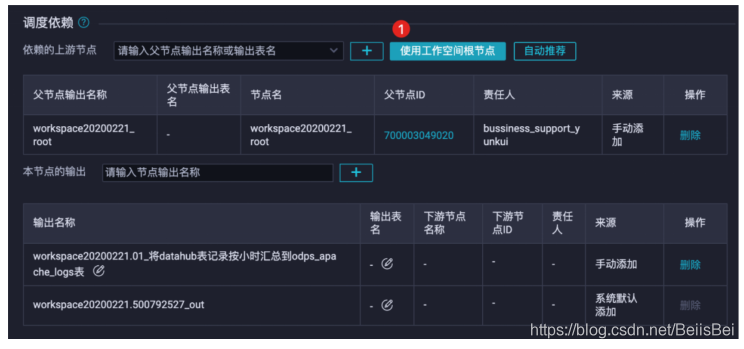
- 节点上下文保持默认。
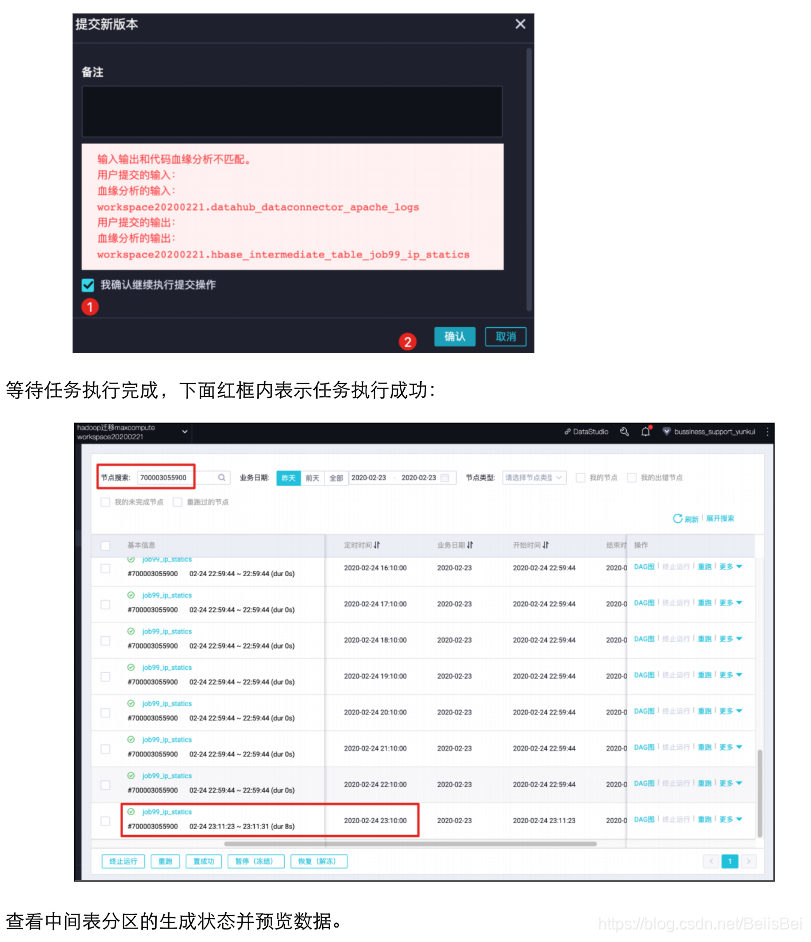
提交任务。
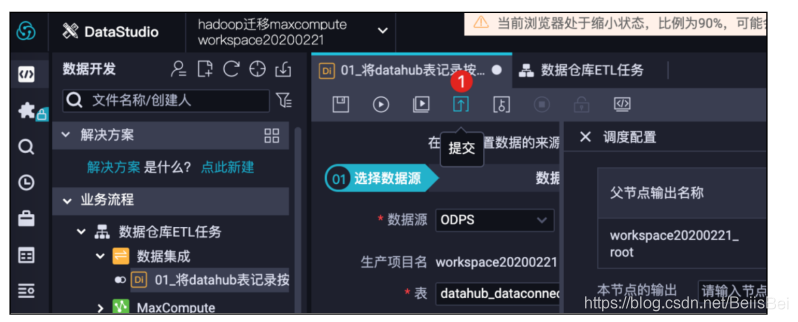
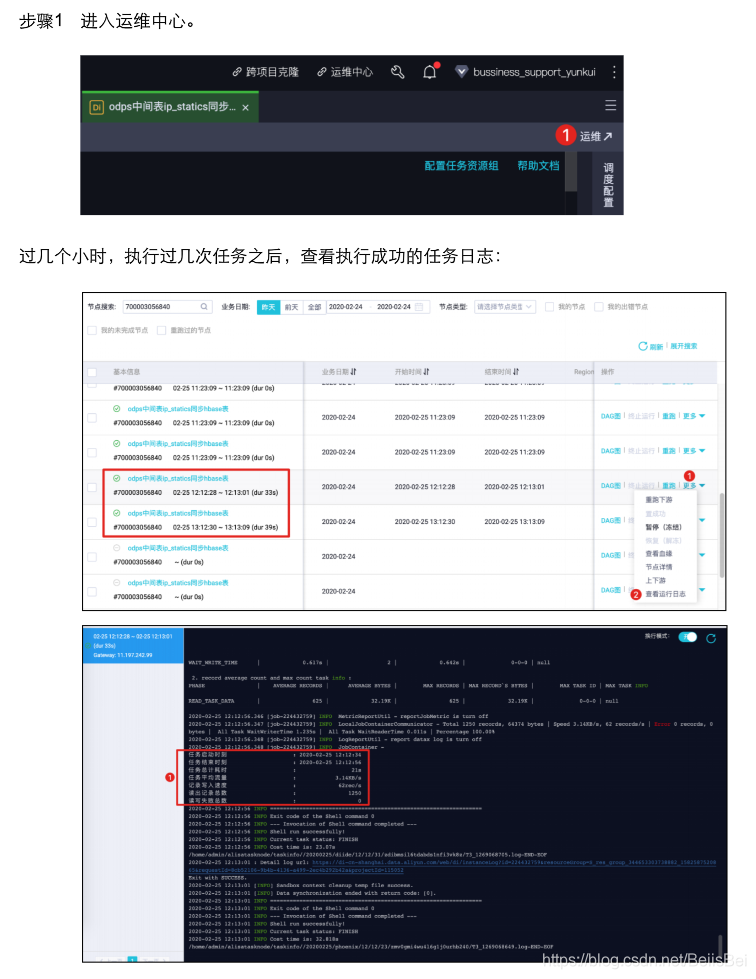
进入右上角运维,进入该任务的运维中心。
查看到下一个被调度的任务:

在任务被调用之前,目标表odps_apache_logs仅有4个分区。
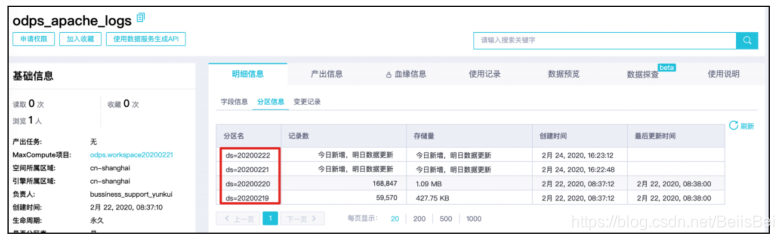
当第一个任务(定时时间为2020-02-24 18:10:00)运行成功之后,预期源表
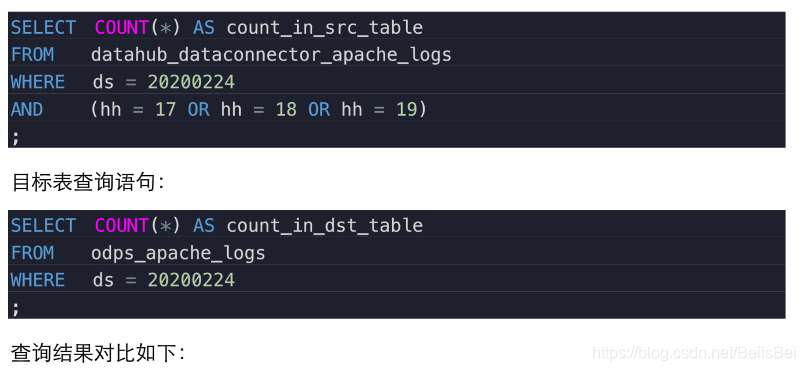
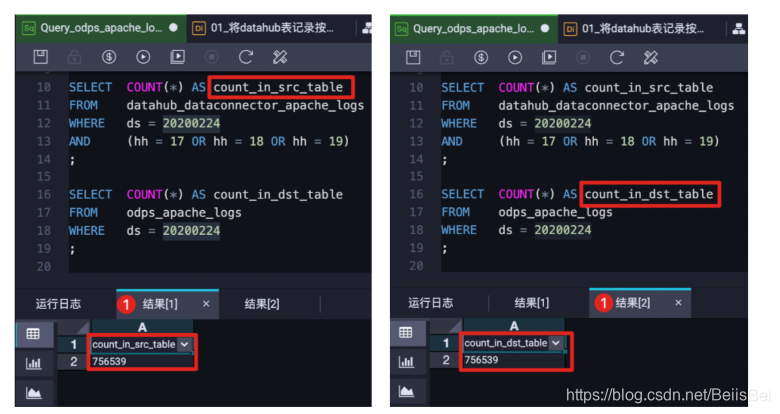
datahub_dataconnector_apache_logs中ds=20200224/hh=16/mm=00分区的记录,将被插入到目标表odps_apache_logs的ds=20200224分区中。本最佳实践编写过程中,已经执行了3个定时任务:2020-02-24 18:10:00、2020-02-24 19:10:00和2020-02-24 18:10:00。因此,在目标表odps_apache_logs的分区中应该包含源表datahub_dataconnector_apache_logs如下3个分区的数据:
- ds=20200224/hh=17/mm=00
- ds=20200224/hh=18/mm=00
- ds=20200224/hh=19/mm=00
使用者可以通过SQL对目标表和源表进行数据查询,确认数据记录条数相同。例如:
源表查询语句:
10.2 改造Azkaban测试工程中Job 99_ip_statics
10.2.1 修改HiveSQL并提交ODPS SQL任务
该Job执行周期为每天1点钟执行1次,执行的操作为:对Hive数据仓库表apache_log表中前一天的日志数据,计算IP地址的访问次数,并将结果保存到Hive外部表 hbase_external_table_job99_ip_statics(关联hbase表99_ip_statics)。
在MaxCompute改造后的任务执行规则如下:在每小时执行完任务01_将datahub表记录按小时汇总到odps_apache_logs表之后,将表datahub_dataconnector_apache_logs中前一个小时的日志记录,处理后的结果插入到中间表hbase_intermediate_table_job99_ip_statics中,后续使用数据集成任务同步到云数据库Hbase表99_ip_statics中。
原Job的详细HiveSQL语句如下所示:

HiveSQL需要进行一定的语法重新适配、表名修改等步骤才可以运行成功,这里用黄色背景标识出修改点。
步骤1 修改原始HiveSQL的语法格式、自建函数等内容,上面黄色修改点按照ODPS SQL语法标准修改后,用红色字体标识:

关于HiveSQL修改为ODPS SQL的过程,目前暂未提供自动化工具进行修改,但是根据经验大部分的HiveSQL关键字、数据类型、自建函数,都可以在ODPS SQL中找到,有少部分需要进行语法改造。
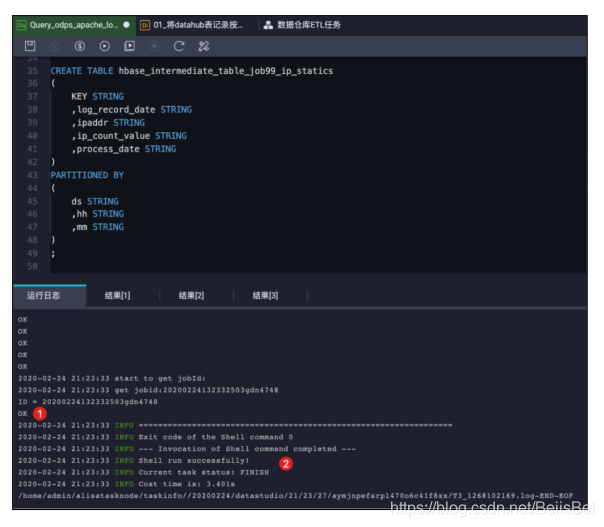
创建MaxCompute中间表hbase_intermediate_table_job99_ip_statics由于目前MaxCompute还不支持外部表关联到Hbase表的方式,因此我们需要将步骤1的ODPS SQL执行结果保存到中间表hbase_external_table_job99_ip_statics,后续通过数据集成任务将中间表的数据同步到云数据库Hbase表job99_ip_statics中。在临时查询窗口中执行下面的建表语句:
CREATE TABLE hbase_intermediate_table_job99_ip_statics
(
KEY STRING
,log_record_date STRING
,ipaddr STRING
,ip_count_value STRING
,process_date STRING
)
PARTITIONED BY
(
ds STRING
,hh STRING
,mm STRING
)
;
执行结果如下图所示:
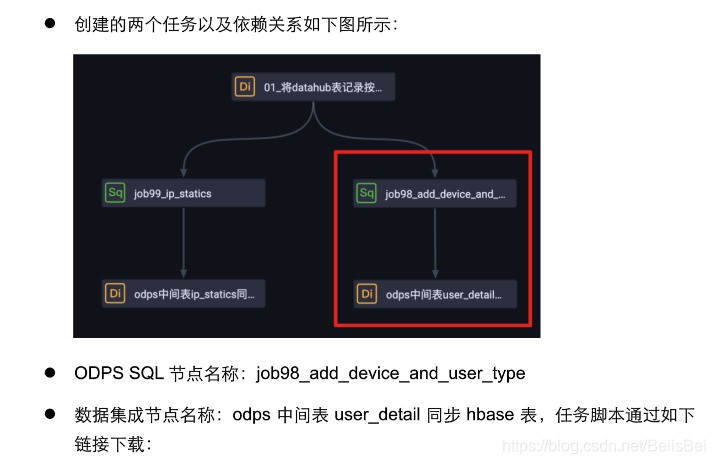
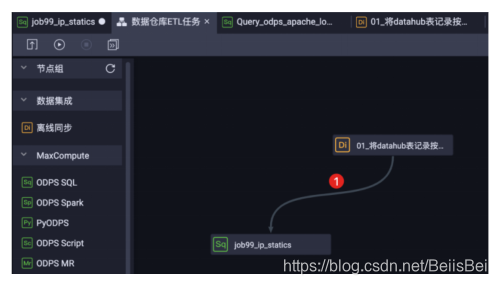
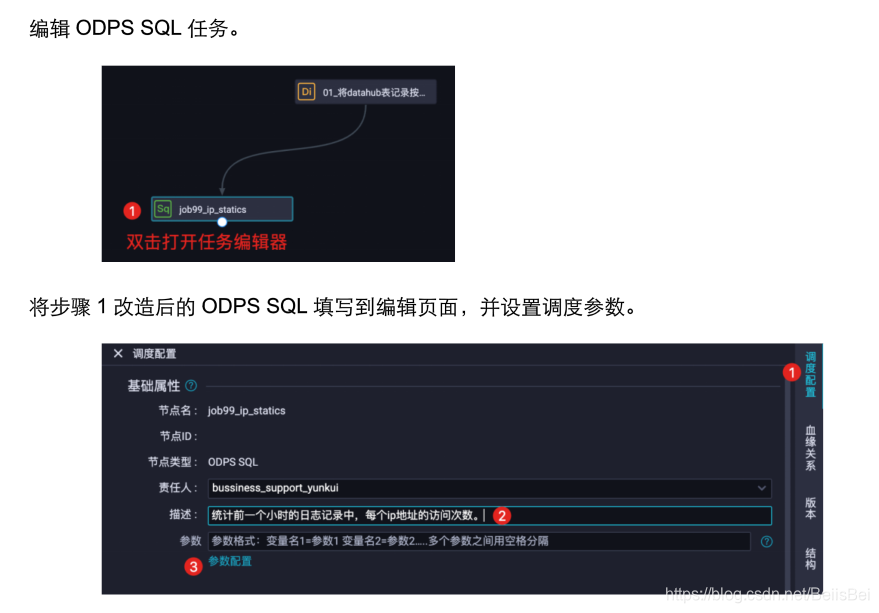
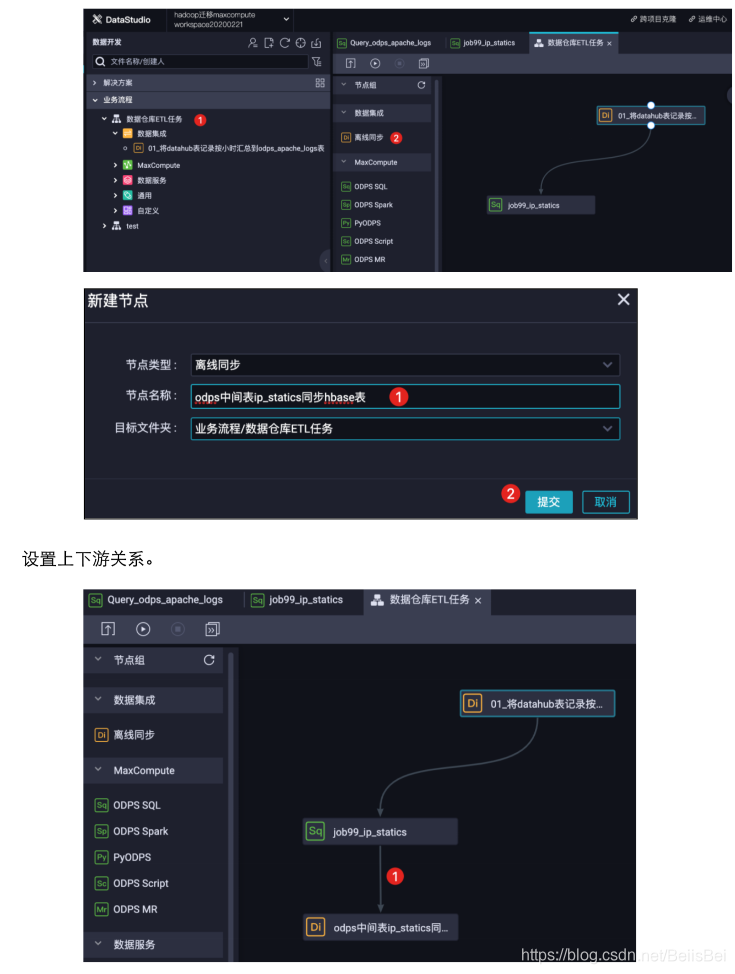
步骤2创建ODPS SQL执行任务,在业务流程中,添加ODPS SQL节点:
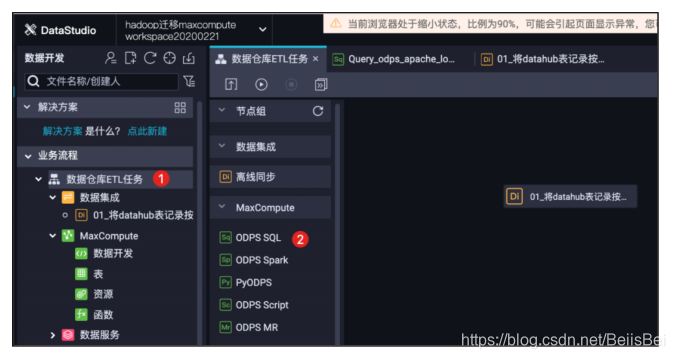

将目前已有的两个节点连接起来,使得这两个任务节点具有上下游的依赖关系。

通过 https://dmc-cn-shanghai.data.aliyun.com/dm/mydata/ihave 登录控制台。
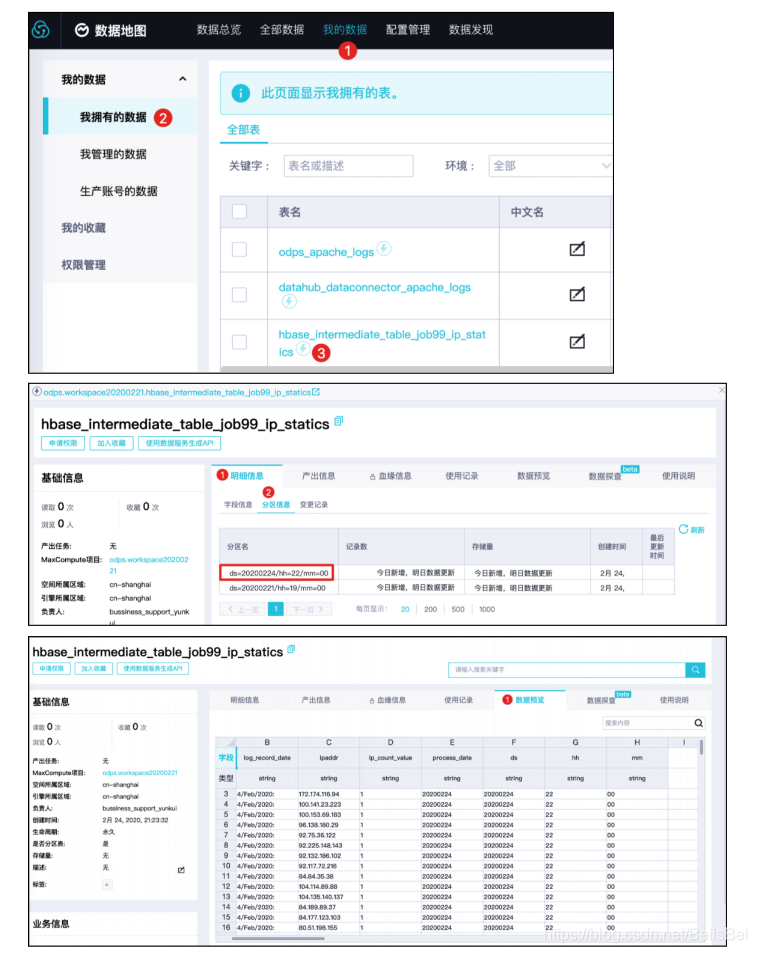
10.2.2 将中间表同步到云数据库Hbase实例
本节将演示如何通过独享数据集成资源组将中间表数据同步至云数据库Hbase实例的表中。
源表:ODPS hbase_intermediate_table_job99_ip_statics
目标表:云数据库Hbasejob99_ip_statics
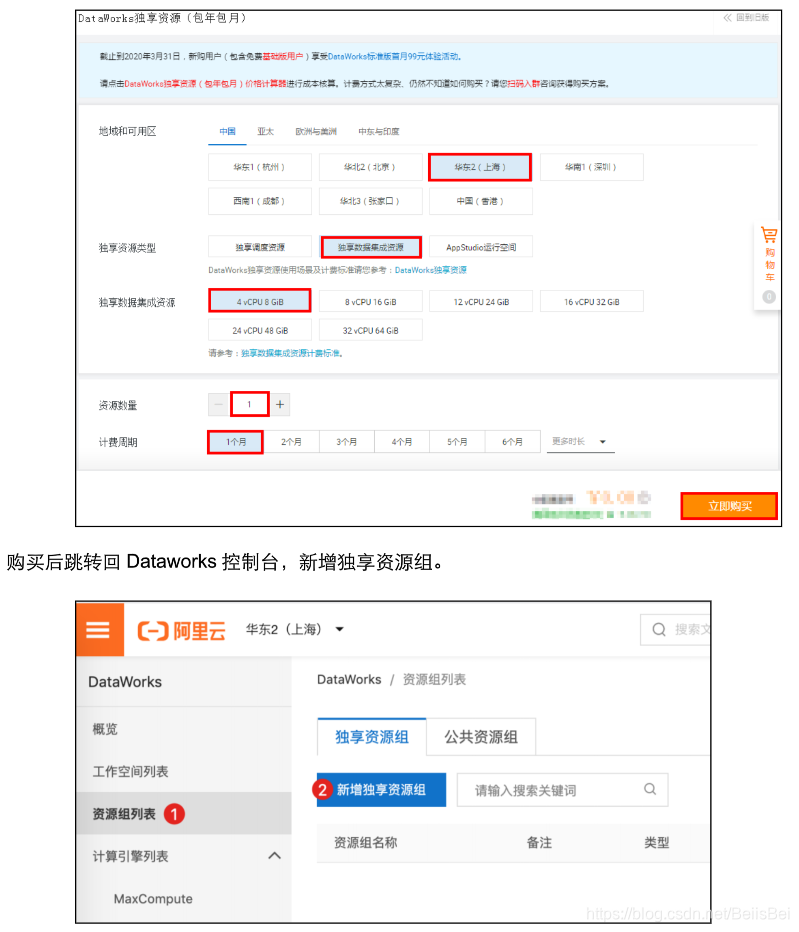
独享资源组详细内容请查看 https://help.aliyun.com/document_detail/137838.html
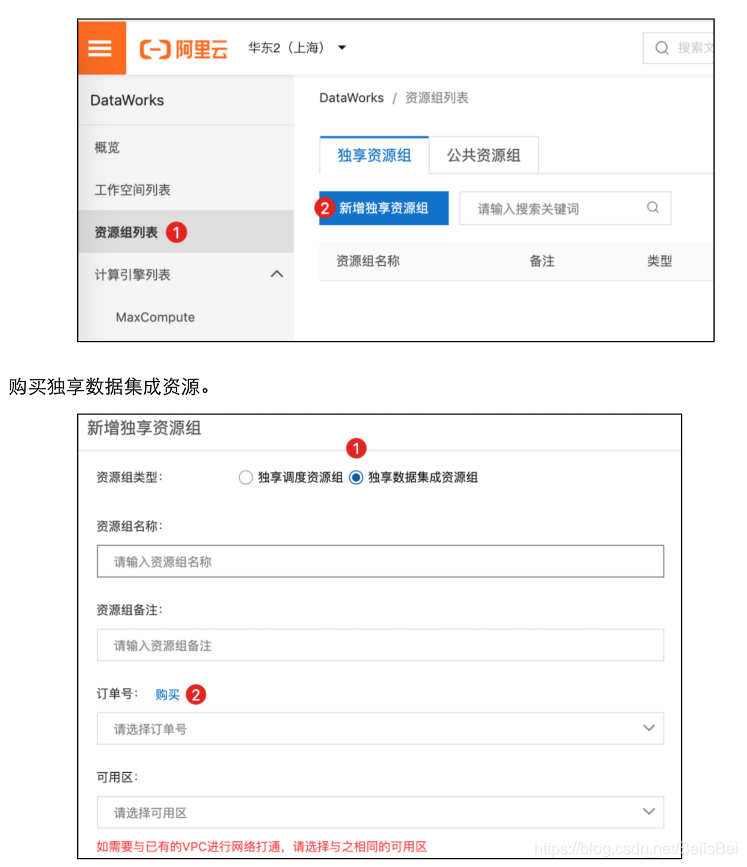
步骤1 登录Dataworks控制台。(https://workbench.data.aliyun.com/consolenew?#/)
步骤2 在左侧导航栏选择资源组列表,确认地域为华东2(上海),在独享资源组页签下单击
新增独享资源组。
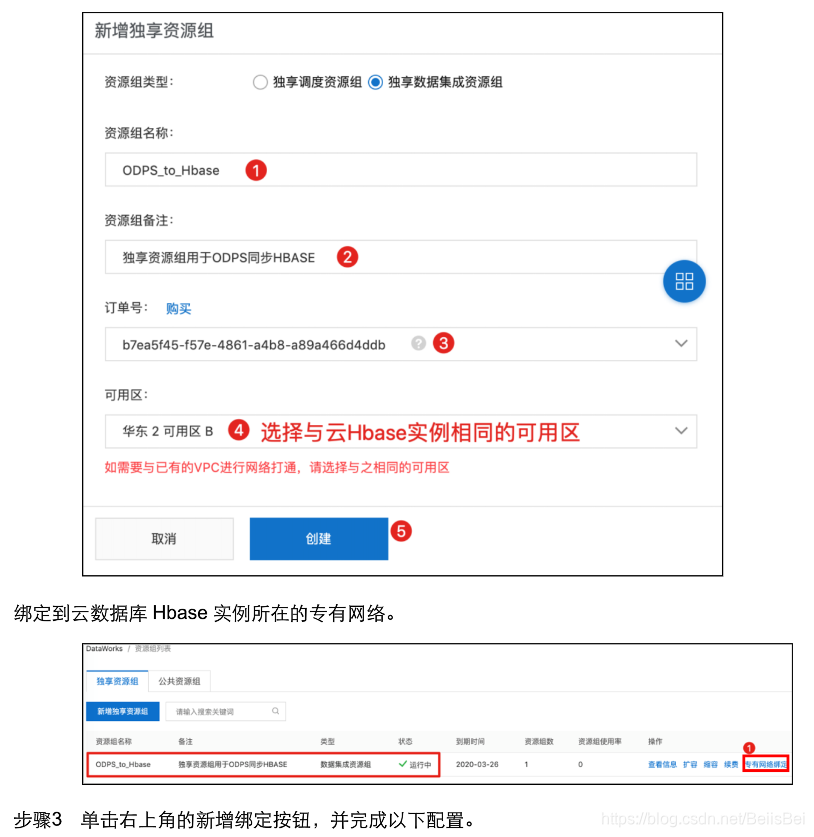
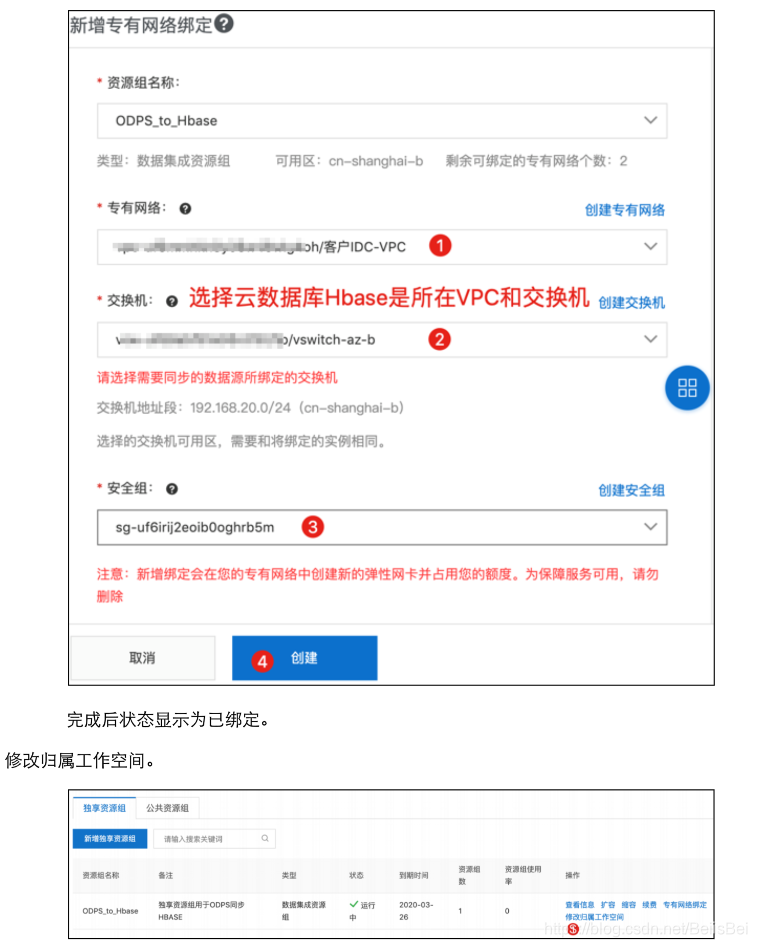
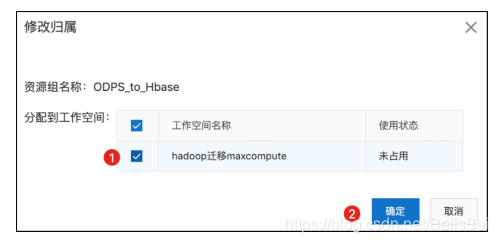
将独享数据集成资源组所绑定的VPC网段添加到云数据库Hbase实例的访问控制表中:
https://hbase.console.aliyun.com/hbase/cn-shanghai/clusters
创建ODPS到Hbase数据集成同步任务。
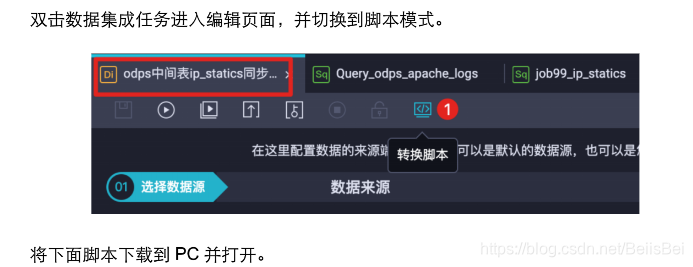
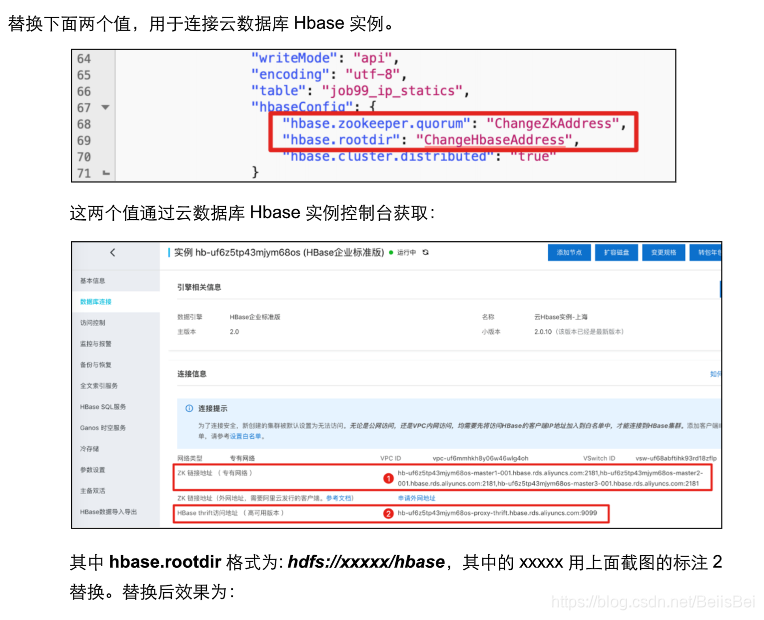
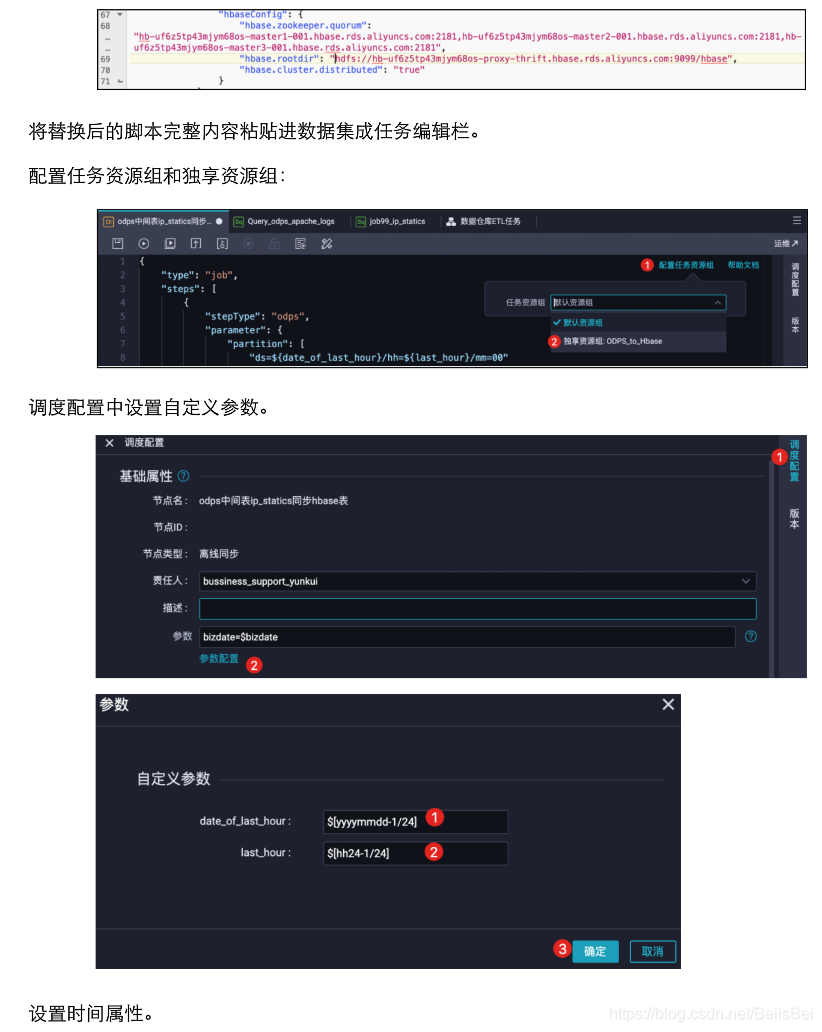
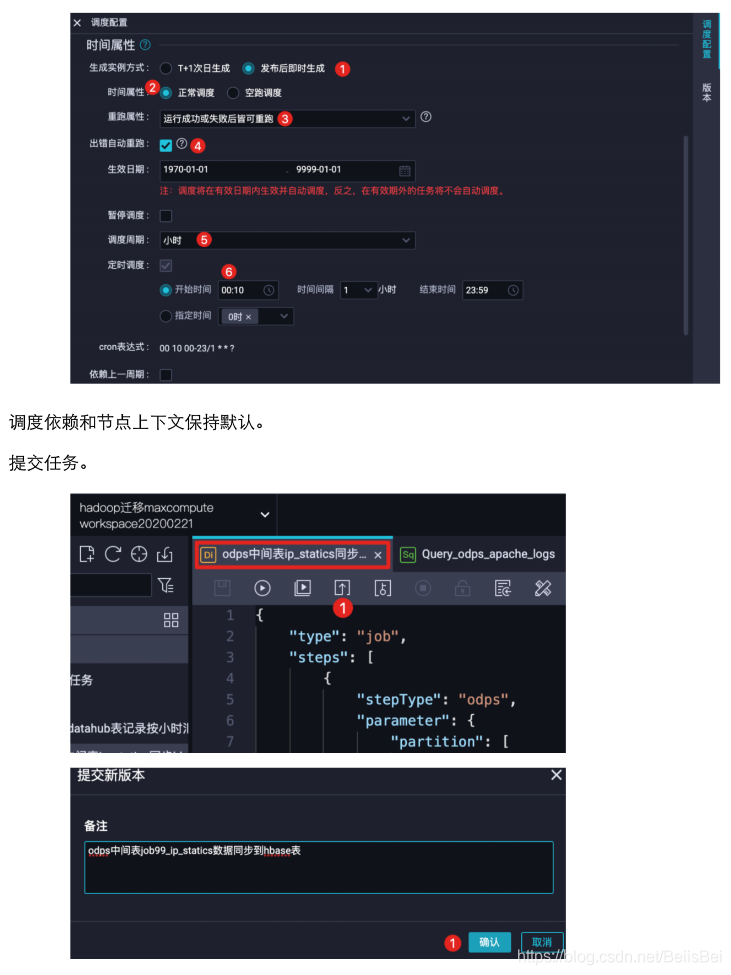
10.2.3 查看执行成功的任务