数据整合
1. 背景及前期准备
1.1 背景介绍
在参加比赛过程中,需要获取江苏省科学技术奖近十年的数据,因此需要在官网上获取相应的数据,再查找数据的过程中发现,官网中给出的数据,并不是完整的可以直接拿来用的
比如:
① 2018-2019年的人员及项目名单是pdf的形式给出,
② 2015、2017年的内容直接附在发布的公告后面(纯文字的)
③ 2008-2011、 2014、2016年的内容是以doc的形式给出
④ 2012-2013年的可以找到xls形式数据
因此需要将数据进行整合,数据最后的表现形式就是每一年的数据,都提取整合到Excel表中。
具体要求:
① 将doc、pdf和网页里面的文字数据提取到Excel表格中,表格的名称为:xxx年年度江苏省科学技术奖.xlsx

② 将一、二、三等奖数据分别放置在该表格下的三个sheet中,sheet的名称为:一等奖、二等奖、三等奖
1.2 需要安装的库
这里用到python自带的库:os库(系统文件创建)、re(字符数据匹配)、glob(文件路径选择)
用到的python第三方库有:pandas(数据处理的)、pdfplumber(pdf表格数据提取)、python-docx(doc文本数据提取)
安装上诉第三方库,推荐使用镜像安装,安装的指令如下
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pandas pdfplumber python-docx
2. 数据处理
2.1 数据提取
① 因为获取的doc形式的数据,使用python-docx库无法直接处理,所以将doc形式的数据转到新建的docx文件中
② 网页的文本数据,直接复制粘贴到docx文件中
③ xls数据直接转化为目标格式的xlsx数据
④ pdf数据直接提取表格数据
2.2 具体过程
2.2.1 docx数据的处理
难点:
① 目标数据的提取
② 一二三等奖的数据划分
③ 将数据写入同一个Excel表格的不同sheet中并命名
前面的数据提取已经将所有待处理的doc数据都转化为docx数据,这里进行数据提取,docx文件中的数据格式如下:

通过观察发现,docx中列举出的数据是有一定的数据格式的,因此可以将数据读取之后用正则表达式进行目标数据的匹配
这里以2016年的数据进行试错,代码如下
import re
from docx import Document
import pandas as pd
doc = Document('2016年度江苏省科学技术奖.docx')
content = ''
for paragraph in doc.paragraphs:
content += paragraph.text
print(content[:1000])
→ 输出的结果为:(可以发现数据直接存在着空格,为了方便匹配数据,需要将空格先去掉)

接着进行空格的替换处理
s = content[:1000].replace(' ','')
print(s)
→ 输出的结果为:(之前的空格已经被剔除了)

★★★★★难点1: 提取目标字段的数据,这一步需要有一定正则匹配数据的功底,代码如下,提取的数据格式可以直接转化为用来生成DataFrame的数据
infos = re.findall(r'(\d+).(.*?)完成单位:(.*?)主要完成人:(\D+)',content)
data = pd.DataFrame(infos, columns = ['序号','项目名称','完成单位','完成人'])
→ 输出的结果为:(直接查看data变量的值,这里只列举部分)
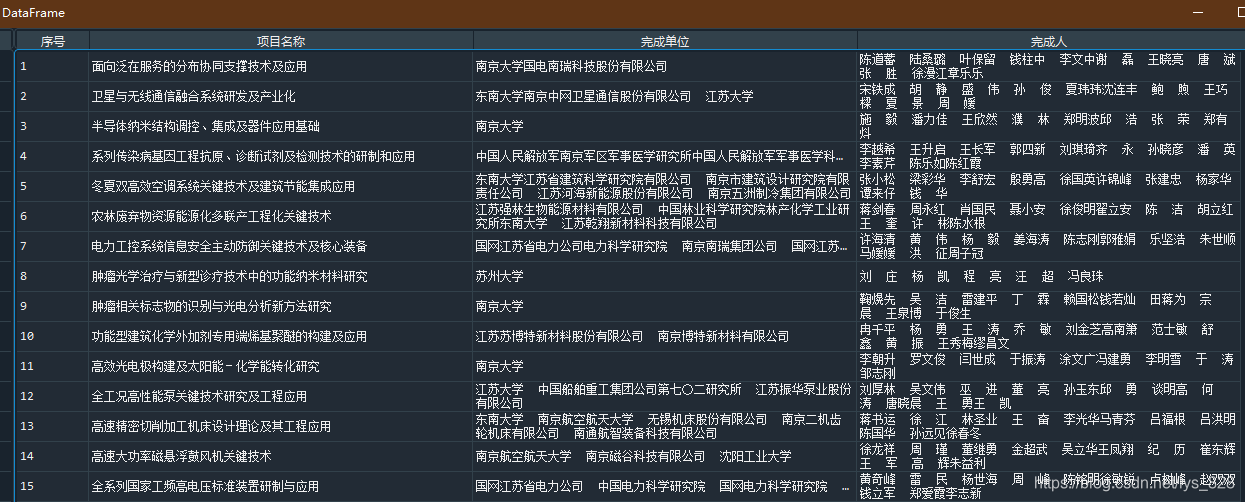
★★★★难点2: 因为一、二、三等奖都是整个DataFrame中,因此困难在于找到数据的分割点,好在这里公布的数据是每个奖项进行排序,都是从1开始,因此只要找到1的位置并获取对应的索引即可,然后获取一、二、三等奖
split_row = data[data['序号'].isin(['1'])].index.tolist()
print(split_row)
data_1 = data.iloc[:split_row[1]]
data_2 = data.iloc[split_row[1]:split_row[2]]
data_3 = data.iloc[split_row[2]:]
→ 输出的结果为:(数据提取就是基于1所在的索引位置进行切片)
[0, 30, 78]
★★★ 难点3: 多DataFrame数据写入同一个Excel表格中,这里处理的方式属于先命名每一个sheet的名称,然后进行遍历数据写入,代码如下
ls = ['一等奖','二等奖','三等奖']
writer = pd.ExcelWriter('demo.xlsx')
for i in range(3):
eval(f'data_{i+1}').to_excel(writer,sheet_name = ls[i], index = False)
writer.save()
writer.close()
→ 输出的结果为:(数据已经按要求整理好了,唯一需要手动清理的就是最后一行的多出来的一点数据)

2.2.2 docx数据的处理完整代码
保留数据接口,可以使用glob进行文件路径的获取,然后遍历循环进行所有文件数据的转化,可以查看之前的使用glob整合多个Excel文件
import re
from docx import Document
import pandas as pd
def filter_docx_data(file_name):
doc = Document(f'{file_name}.docx')
content = ''
for paragraph in doc.paragraphs:
content += paragraph.text
# print(content[:1000])
content = content.replace('\xa0','')
infos = re.findall(r'(\d+).(.*?)完成单位:(.*?)主要完成人:(\D+)',content)
data = pd.DataFrame(infos, columns = ['序号','项目名称','完成单位','完成人'])
# print(data.head())
split_row = data[data['序号'].isin(['1'])].index.tolist()
# print(split_row)
data_1 = data.iloc[:split_row[1]]
data_2 = data.iloc[split_row[1]:split_row[2]]
data_3 = data.iloc[split_row[2]:]
ls = ['一等奖','二等奖','三等奖']
writer = pd.ExcelWriter(f'filtered_data/{file_name}.xlsx')
for i in range(3):
eval(f'data_{i+1}').to_excel(writer,sheet_name = ls[i], index = False)
writer.save()
writer.close()
if __name__ == '__main__':
filter_docx_data('2016年度江苏省科学技术奖')
2.2.3 pdf数据的处理及完整代码
查看一下pdf的数据样式,文件中的数据如下:
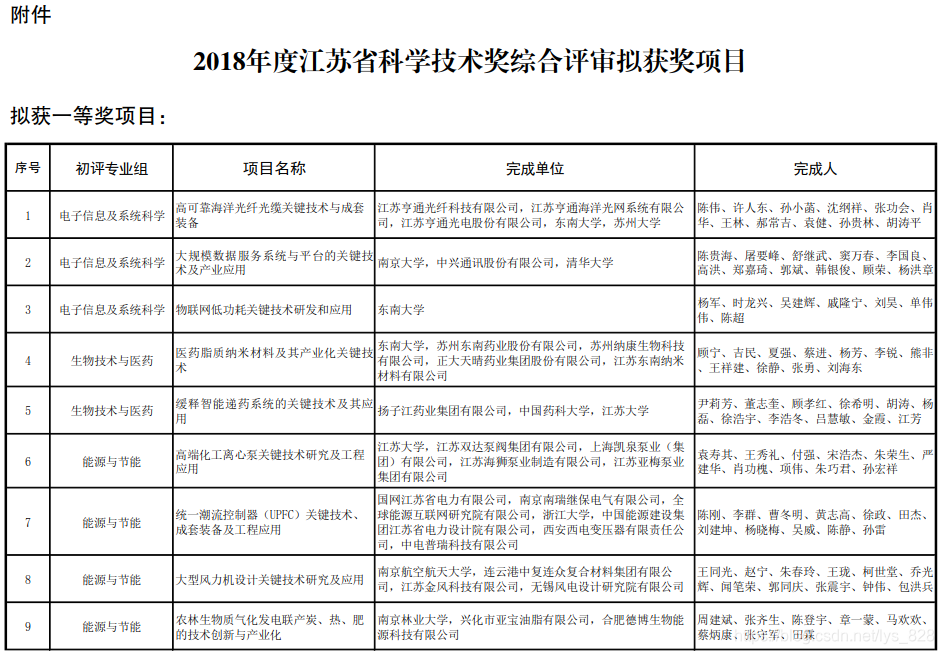
针对表格数据的提取,这里使用到了pdfplumber模块,首先提取数据,这里进行第一页的表格数据的提取代码如下
import pdfplumber
import pandas as pd
import os
with pdfplumber.open("2018年度江苏省科学技术奖.pdf") as pdf:
page_num = len(pdf.pages)
data= pdf.pages[0].extract_table()
print(data)
→ 输出的结果为:(可以发现pdf第一页表格的第一行是标题栏,对应提取表格的第一个元素,因此就可以获取第一个元素作为DataFrame数据的列标题)

接下来的处理就有点和docx数据的处理类似了,转化为DataFrame数据后进行一、二、三等奖的提取,最后再存入Excel中。
但是这里有个小细节的问题,2018年pdf的列举获奖名单的方式和2019年的不一样,其中2018年的是按照docx数据一样,一二三等奖都是以1开头,但是2019年的是只有一个1,其余的二三等奖的序号都是基于一等奖序号的累加,因此这里需要着重注意一下,代码如下
import pdfplumber
import pandas as pd
import os
#这一步是创建一个文件夹,将处理好的数据文件放置在其中
if not os.path.exists('filtered_data'):
os.mkdir('filtered_data')
def filtering_data_2018(file_name):
data_list = []
with pdfplumber.open(f"{file_name}.pdf") as pdf:
page_num = len(pdf.pages)
data_columns = pdf.pages[0].extract_table()[0]
for i in range(page_num):
data_page = pdf.pages[i].extract_table()[1:]
data_list.extend(data_page)
data = pd.DataFrame(data_list,columns = data_columns)
split_row = data[data['序号'].isin(['1'])].index.tolist()
print(split_row)
data_1 = data.iloc[:split_row[1]]
data_2 = data.iloc[split_row[1]:split_row[2]]
data_3 = data.iloc[split_row[2]:]
ls = ['一等奖','二等奖','三等奖']
writer = pd.ExcelWriter(f'filtered_data/{file_name}.xlsx')
for i in range(3):
eval(f'data_{i+1}').to_excel(writer,sheet_name = ls[i], index = False)
writer.save()
writer.close()
def filtering_data_2019(file_name):
data_list = []
with pdfplumber.open(f"{file_name}.pdf") as pdf:
page_num = len(pdf.pages)
data_columns = pdf.pages[0].extract_table()[0]
for i in range(page_num):
data_page = pdf.pages[i].extract_table()[1:]
data_list.extend(data_page)
data = pd.DataFrame(data_list,columns = data_columns)
split_row = data[data['序号'].isin(['46','129'])].index.tolist()
print(split_row)
data_1 = data.iloc[:split_row[0]]
data_2 = data.iloc[split_row[0]:split_row[1]]
data_3 = data.iloc[split_row[1]:]
ls = ['一等奖','二等奖','三等奖']
writer = pd.ExcelWriter(f'filtered_data/{file_name}.xlsx')
for i in range(3):
eval(f'data_{i+1}').to_excel(writer,sheet_name = ls[i], index = False)
writer.save()
writer.close()
if __name__ == '__main__':
filtering_data_2018('2018年度江苏省科学技术奖')
filtering_data_2019('2019年度江苏省科学技术奖')
关于xls数据的处理,就不介绍了,本来数据整理的格式就是很好,只需要将表格的数据复制粘贴到对应的sheet中命名,最后另存为xlsx数据即可(只是为了和之前生成文件的格式一致)
3. 最终结果
数据处理完毕后,就会在创建的filtered_data文件夹下,如下图
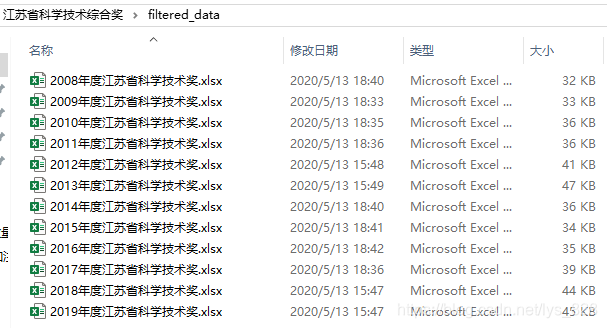
代码测试所需要的文件已经全部上传到资源