四、前几天一直忙着摸鱼和休息,明天就要正式上课了开始。也要忙起来了,但正事还是不能忘,今天学习的是python自动化的第四节(拆分),主要还是利用的是xlrd,xlutils这两个,所以没有下载的可以根据前两篇文章进行下载。话不多少,先上图
(1)
这个是运行前的表格:
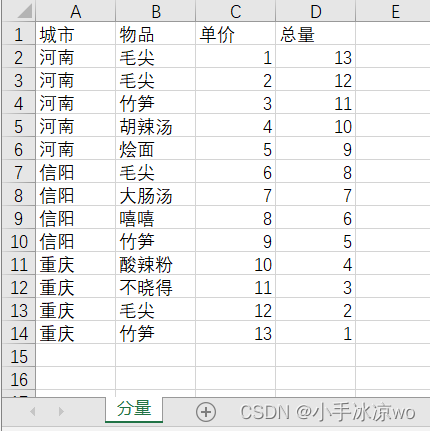
2.这是运行之后的表格
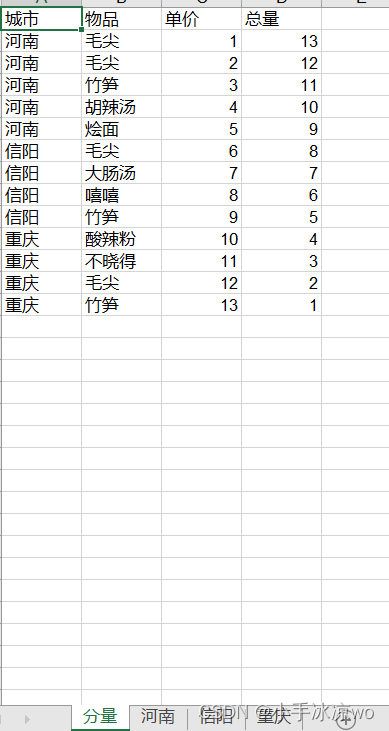
其他几个工作簿如上
代码如下
import xlrd
from xlutils.copy import copy#插入两个包,类似以前的操作
def readdata():
sh=xlrd.open_workbook('分量.xlsx')#利用xlrd读取excel文件
sh1=sh.sheet_by_index(0)#定位到第一个工作簿
data={
}#设置一个词典,用于存在一行数据以及所代表的的意义
for i in range(1,sh1.nrows):#对列数进行循环
d={
'type':sh1.cell_value(i,1),'danjia':sh1.cell_value(i,2),'zongjia':sh1.cell_value(i,3)}#
#将每一列数据存入一个字典
key=sh1.cell_value(i,0)#将第一列的每行元素选为key
if(data.get(key)):#如果数据存储过之后
data[key].append(d)#那么将这个元素继续添加在这个之后
else:
data[key]=[d]#如果没有则将这个添加进去
return data#返回一个字典
def caozuo(data):
sh=xlrd.open_workbook('分量.xlsx')
sh1=copy(sh)#用于修改的时候一般就要用copy
sh1.get_sheet(0)#copy之后选择第一个就要用get_sheet
for key in data.keys():#循环字典中的关键字
sheet1=sh1.add_sheet(key)#将关键字作为工作簿名字插进去
for i,d in enumerate(data.get(key)):#这个在前面有解释
sheet1.write(i,0,d.get('type'))#get(‘type’)#可以得到这个关键字对应的值
sheet1.write(i,1,d.get('danjia'))
sheet1.write(i,2,d.get('zongjia'))
sh1.save("now.xls")
if __name__ == '__main__':
c=readdata()
caozuo(c)```
好的,今天结束 2022.9.12