语义分割:基于openCV和深度学习(一)
Semantic segmentation with OpenCV and deep learning
介绍如何使用OpenCV、深度学习和ENet架构执行语义分段。阅读完今天的文章后,能够使用OpenCV对图像和视频应用语义分割。深度学习有助于提高计算机视觉的前所未有的准确性,包括图像分类、目标检测,现在甚至分割。
传统的分割方法是将图像分割为若干部分(标准化切割、图形切割、抓取切割、超像素等);然而,算法并没有真正理解这些部分所代表的内容。
另一方面,语义分割算法试图:
把图像分成有意义的部分,同时,将输入图像中的每个像素与类标签(即人、路、车、公共汽车等)相关联,语义分割算法非常强大,有很多用例,包括自动驾驶汽车——展示如何将语义分割应用于道路场景图像/视频!要学习如何使用OpenCV和深度学习应用语义分割,请继续阅读!
寻找这篇文章的源代码?直接跳到下载部分。OpenCV语义分割与深度学习 在文章的第一部分,将讨论ENet深度学习体系结构。
在这里,将演示如何使用ENet对图像和视频流应用语义分割。在这一过程中,将分享来自分段的示例输出,将语义分段应用于项目时感受到预期的结果。
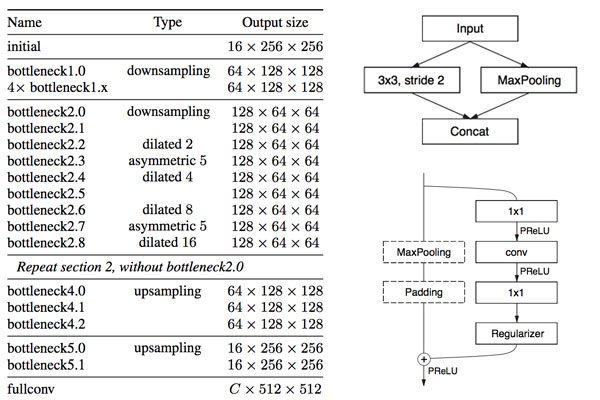
The ENet semantic segmentation architecture

Figure 1: The ENet deep learning semantic segmentation architecture.
ENet的一个主要优点是它的速度比大型模型快18倍,需要的参数比大型模型少79倍,具有相似或更好的精度。型号本身只有3.2兆! 在的计算机上,一次CPU转发需要0.2秒——如果使用GPU,这个分段网络可以运行得更快。Paszke等人。在Cityscapes数据集上训练该数据集,这是一个语义的、实例化的、密集的像素注释,包含20-30个类(取决于使用的模型)。顾名思义,城市景观数据集包括可用于城市场景理解的图像示例,包括自动驾驶车辆。
使用的特定模型在20个课题中进行了训练,包括:

如何应用语义分割来提取图像和视频流中每个类的密集像素映射。如果有兴趣,在自定义数据集上训练自己的ENet模型进行分段。
Semantic segmentation with OpenCV and deep learning
$ tree --dirsfirst
.
├── enet-cityscapes
│ ├── enet-classes.txt
│ ├── enet-colors.txt
│ └── enet-model.net
├── images
│ ├── example_01.png
│ ├── example_02.jpg
│ ├── example_03.jpg
│ └── example_04.png
├── videos
│ ├── massachusetts.mp4
│ └── toronto.mp4
├── output
├── segment.py
└── segment_video.py
4 directories, 11 files
项目有四个目录:
enet cityscapes/:包含预先训练的深度学习模型、项目列表和与项目对应的颜色标签。
images/:选择四个样本图像来测试图像分割脚本。
videos/:包括两个用于测试深度学习分段视频脚本的示例视频。这些视频的点数列在“视频分割结果”部分。
output/:出于组织目的,喜欢让脚本将处理过的视频保存到output文件夹中。不包括在下载的输出图像/视频,因为文件的大小相当大。需要使用的代码自行生成它们。 将回顾两个Python脚本:
segment.py:对单个图像执行深度学习语义分割。将通过这个脚本来学习分割的工作原理,然后在转到视频之前对单个图像进行测试。
{kind=link}