本文为论文阅读笔记,不当之处,敬请指正。
A Review on Deep Learning Techniques Applied to Semantic Segmentation:原文链接
5.1度量标准
为何需要语义分割系统的评价标准?
- 为了衡量分割系统的作用及贡献,其性能需要经过严格评估。并且,评估须使用标准、公认的方法以保证公平性。
- 系统的多个方面需要被测试以评估其有效性,包括:执行时间、内存占用、和精确度。
- 由于系统所处背景及测试目的的不同,某些标准可能要比其他标准更加重要,例如,对于实时系统可以损失精确度以提高运算速度。而对于一种特定的方法,尽量提高所有的度量性能是必须的。
5.1.1 执行时间
速度或运行时间是一个非常有价值的度量,因为大多数系统需要保证推理时间可以满足硬实时的需求。某些情况下,知晓系统的训练时间是非常有用的,但是这通常不是非常明显,除非其特别慢。在某种意义上说,提供方法的确切时间可能不是非常有意义,因为执行时间非常依赖硬件设备及后台实现,致使一些比较是无用的。
然而,出于重用和帮助后继研究人员的目的,提供系统运行的硬件的大致描述及执行时间是有用的。这可以帮助他人评估方法的有效性,及在保证相同环境测试最快的执行方法。
5.1.2 内存占用
内存是分割方法的另一个重要的因素。尽管相比执行时间其限制较松,内存可以较为灵活地获得,但其仍然是一个约束因素。在某些情况下,如片上操作系统及机器人平台,其内存资源相比高性能服务器并不宽裕。即使是加速深度网络的高端图形处理单元(GPU),内存资源也相对有限。以此来看,在运行时间相同的情况下,记录系统运行状态下内存占用的极值和均值是及其有价值的。
5.1.3 精确度
图像分割中通常使用许多标准来衡量算法的精度。这些标准通常是像素精度及IoU的变种,以下我们将会介绍常用的几种逐像素标记的精度标准。为了便于解释,假设如下:共有k+1个类(从L0L0到LkLk,其中包含一个空类或背景),pijpij表示本属于类i但被预测为类j的像素数量。即,piipii表示真正的数量,而pij pjipij pji则分别被解释为假正和假负,尽管两者都是假正与假负之和。
- Pixel Accuracy(PA,像素精度):这是最简单的度量,为标记正确的像素占总像素的比例。
- Mean Pixel Accuracy(MPA,均像素精度):是PA的一种简单提升,计算每个类内被正确分类像素数的比例,之后求所有类的平均。
Mean Intersection over Union(MIoU,均交并比):为语义分割的标准度量。其计算两个集合的交集和并集之比,在语义分割的问题中,这两个集合为真实值(ground truth)和预测值(predicted segmentation)。这个比例可以变形为正真数(intersection)比上真正、假负、假正(并集)之和。在每个类上计算IoU,之后平均。
Frequency Weighted Intersection over Union(FWIoU,频权交并比):为MIoU的一种提升,这种方法根据每个类出现的频率为其设置权重。
在以上所有的度量标准中,MIoU由于其简洁、代表性强而成为最常用的度量标准,大多数研究人员都使用该标准报告其结果。
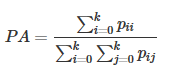
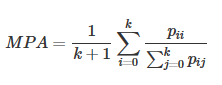
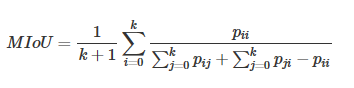
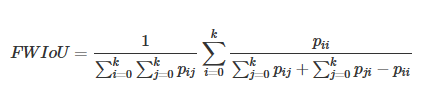
直观理解
如下图所示,红色圆代表真实值,黄色圆代表预测值。橙色部分红色圆与黄色圆的交集,即真正(预测为1,真实值为1)的部分,红色部分表示假负(预测为0,真实为1)的部分,黄色表示假正(预测为1,真实为0)的部分,两个圆之外的白色区域表示真负(预测为0,真实值为0)的部分。
- MP计算橙色与(橙色与红色)的比例。
- MIoU计算的是计算A与B的交集(橙色部分)与A与B的并集(红色+橙色+黄色)之间的比例,在理想状态下A与B重合,两者比例为1 。
