串(Sequence)
数据结构与算法笔记:恋上数据结构笔记目录
串(前缀、后缀)
本课程研究的串是开发中非常熟悉的字符串,是由若干个字符组成的有限序列

字符串 thank 的前缀(prefix)、真前缀(proper prefix)、后缀(suffix)、真后缀(proper suffix)

串匹配算法
- 查找一个模式串(pattern)在文本串(text)中的位置:
String text = "Hello World";
String pattern = "or";
text.indexOf(pattern); // 7
text.indexOf(pattern); // -1
几个经典的串匹配算法:
- 蛮力(Brute Force)
- KMP
- Boyer-Moore
- Karp-Rabin / Rabin-Karp
- Sunday
下面用 tlen 代表文本串 text 的长度,plen 代表模式串 pattern 的长度;
蛮力(Brute Force)
- 以字符为单位,从左到右移动模式串,直到匹配成功 ;

蛮力算法有 2 种常见实现思路:
蛮力1 – 执行过程 + 实现


/**
* 蛮力匹配
*/
public static int indexOf(String text, String pattern) {
if (text == null || pattern == null) return -1;
char[] textChars = text.toCharArray();
int tlen = textChars.length;
char[] patternChars = pattern.toCharArray();
int plen = patternChars.length;
if (tlen == 0 || plen == 0 || tlen < plen) return -1;
int pi = 0, ti = 0;
while (pi < plen && ti < tlen) {
if (textChars[ti] == patternChars[pi]) {
ti++;
pi++;
} else {
ti = ti - pi + 1;
// ti -= pi - 1;
pi = 0;
}
}
return pi == plen ? ti - pi : -1;
}
蛮力1 – 优化

/**
* 蛮力匹配 - 改进
*/
public static int indexOf(String text, String pattern) {
if (text == null || pattern == null) return -1;
char[] textChars = text.toCharArray();
int tlen = textChars.length;
char[] patternChars = pattern.toCharArray();
int plen = patternChars.length;
if (tlen == 0 || plen == 0 || tlen < plen) return -1;
int pi = 0, ti = 0;
while (pi < plen && ti - pi <= tlen - plen) { // ti - pi <= tlen - plen 是关键
if (textChars[ti] == patternChars[pi]) {
ti++;
pi++;
} else {
ti = ti - pi + 1;
// ti -= pi - 1;
pi = 0;
}
}
return pi == plen ? ti - pi : -1;
}
蛮力2 – 执行过程 + 实现


/**
* 蛮力匹配2
*/
public static int indexOf(String text, String pattern) {
if (text == null || pattern == null) return -1;
char[] textChars = text.toCharArray();
int tlen = textChars.length;
char[] patternChars = pattern.toCharArray();
int plen = patternChars.length;
if (tlen == 0 || plen == 0 || tlen < plen) return -1;
// 如果模式串的头在 tlen - plen 后面, 必然会匹配失败
int tiMax = tlen - plen;
for (int ti = 0; ti <= tiMax; ti++) {
int pi = 0;
for (; pi < plen; pi++) {
if (textChars[ti + pi] != patternChars[pi]) break;
}
if (pi == plen) return ti;
}
return -1;
}
蛮力 – 性能分析

最好情况:
- 只需一轮比较就完全匹配成功,比较 m 次( m 是模式串的长度)
- 时间复杂度为 O(m)
最坏情况(字符集越大,出现概率越低):
- 执行了 n – m + 1 轮比较( n 是文本串的长度)
- 每轮都比较至模式串的末字符后失败( m – 1 次成功,1 次失败)
- 时间复杂度为 O(m ∗ (n − m + 1)),由于一般 m 远小于 n,所以为 O(mn)

KMP
KMP 是 Knuth–Morris–Pratt 的简称(取名自3位发明人的名字),于1977年发布

蛮力 vs KMP
首先大概了解一下两者的差距:
蛮力算法:会经历很多次没有必要的比较。

KMP算法:充分利用了此前比较过的内容,可以很聪明地跳过一些不必要的比较位置。

KMP – next表的使用
KMP 会预先根据模式串的内容生成一张 next 表(一般是个数组):
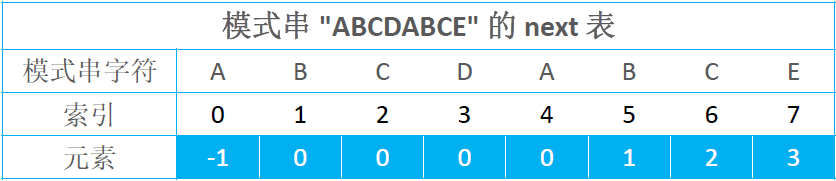
例如,下图串匹配时, pi = 7 时 失配
- 根据失配的索引 7 查表,查到的元素索引为 3
next[pi] == 3 - 将模式串索引为 3 的元素移动到失配的位置
pi = next[pi]; // pi = 3 - 向右移动的距离为
p - next[pi]

再比如:pi = 3 时失配, next[3] = 0,将 0 位置的元素移到失配处:pi = next[pi]

KMP – 核心原理(构造next表)

d、e 失配时,如果希望 pattern 能够一次性向右移动一大段距离,然后直接比较 d、c 字符
- 前提条件是 A 必须等于 B
所以 KMP 必须在失配字符 e 左边的子串中找出符合条件的 A、B,从而得知向右移动的距离
向右移动的距离:e左边子串的长度 – A的长度,等价于:e的索引 – c的索引,
且 c的索引 == next[e的索引],所以向右移动的距离:e的索引 – next[e的索引]
总结:
- 如果在 pi 位置失配,向右移动的距离是
pi – next[pi],所以next[pi]越小,移动距离越大 next[pi]是 pi 左边子串的真前缀后缀的最大公共子串长度
真前缀后缀的最大公共子串长度
如何求 真前缀后缀的最大公共子串长度:

构造 next 表
根据最大公共子串长度得到 next 表:

-1的精妙之处
为什么要将首字符设置为 - 1?

KMP – 主算法代码实现

KMP – 为什么是“最大“公共子串长度?
假设文本串是 AAAAABCDEF,模式串是 AAAAB:


KMP – next表的构造思路及实现

已知 next[i] == n;
① 如果 pattern.charAt(i) == pattern.charAt(n)
- 那么
next[i + 1]==n + 1
② 如果 pattern.charAt(i) != pattern.charAt(n)
- 已知
next[n]==k - 如果
pattern.charAt(i)==pattern.charAt(k)
那么next[i + 1]==k + 1 - 如果
pattern.charAt(i)!=pattern.charAt(k)
将 k 代入 n ,重复执行 ②
构造 next 表 代码实现:
private static int[] next(String pattern) {
char[] chars = pattern.toCharArray();
int[] next = new int [chars.length];
next[0] = -1;
int i = 0;
int n = -1;
int iMax = chars.length - 1;
while (i < iMax) {
if (n < 0 || chars[i] == chars[n]) {
next[++i] = ++n;
} else {
n = next[n];
}
}
return next;
}
KMP – next表的不足之处
假设文本串是 AAABAAAAB,模式串是 AAAAB
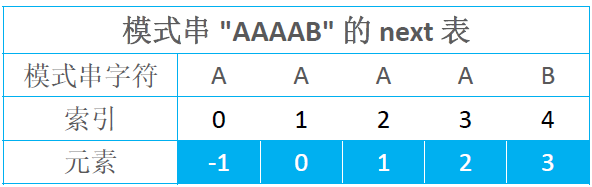

KMP – next表的优化思路及实现

- 如果
pattern[i]!=d,就让模式串滑动到next[i](也就是n)位置跟d进行比较; - 如果
pattern[n]!=d,就让模式串滑动到next[n](也就是k)位置跟d进行比较; - 如果
pattern[i]==pattern[n],那么当i位置失配时,
模式串最终必然会滑到k位置跟d进行比较,
所以next[i]直接存储next[n](也就是k)即可;
next 表 的优化代码实现:
private static int[] next(String pattern) {
char[] chars = pattern.toCharArray();
int[] next = new int [chars.length];
next[0] = -1;
int i = 0;
int n = -1;
int iMax = chars.length - 1;
while (i < iMax) {
if (n < 0 || chars[i] == chars[n]) {
// 优化
++i;
++n;
if (chars[i] == chars[n]) {
next[i] = next[n];
} else {
next[i] = n;
}
} else {
n = next[n];
}
}
return next;
}
KMP – next表的优化效果

KMP – 性能分析
KMP 主逻辑:
- 最好时间复杂度:O(m)
- 最坏时间复杂度:O(n),不超过O(2n)
next 表的构造过程跟 KMP 主体逻辑类似:
- 时间复杂度:O(m)
KMP 整体:
- 最好时间复杂度:O(m)
- 最坏时间复杂度:O(n + m)
- 空间复杂度: O(m)

KMP完整源码
public class KMP {
public static int indexOf(String text, String pattern) {
// 检测数据合法性
if (text == null || pattern == null) return -1;
char[] textChars = text.toCharArray();
int tlen = textChars.length;
char[] patternChars = pattern.toCharArray();
int plen = patternChars.length;
if (tlen == 0 || plen == 0 || tlen < plen) return -1;
// next表
int[] next = next(pattern);
int pi = 0, ti = 0;
while (pi < plen && ti < tlen) {
// next表置-1的精妙之处, pi = -1 则 pi = 0, ti++ 相当于模式串后一一位
if (pi < 0 || textChars[ti] == patternChars[pi]) {
ti++;
pi++;
} else {
pi = next[pi];
}
}
return pi == plen ? ti - pi : -1;
}
/**
* next 表构造 - 优化
*/
private static int[] next(String pattern) {
char[] chars = pattern.toCharArray();
int[] next = new int [chars.length];
next[0] = -1;
int i = 0;
int n = -1;
int iMax = chars.length - 1;
while (i < iMax) {
if (n < 0 || chars[i] == chars[n]) {
++i;
++n;
if (chars[i] == chars[n]) {
next[i] = next[n];
} else {
next[i] = n;
}
} else {
n = next[n];
}
}
return next;
}
/**
* next表构造
*/
private static int[] next2(String pattern) {
char[] chars = pattern.toCharArray();
int[] next = new int [chars.length];
next[0] = -1;
int i = 0;
int n = -1;
int iMax = chars.length - 1;
while (i < iMax) {
if (n < 0 || chars[i] == chars[n]) {
next[++i] = ++n;
} else {
n = next[n];
}
}
return next;
}
}
蛮力 vs KMP
蛮力算法为何低效?
当字符失配时:
- 蛮力算法
ti回溯到左边位置
pi回溯到 0 - KMP 算法
ti不必回溯
pi不一定要回溯到0
Boyer-Moore
Boyer-Moore 算法,简称 BM 算法,由 Robert S.Boyer 和 J Strother Moore 于 1977 年发明;
- 最好时间复杂度:O(n / m),最坏时间复杂度:O(n + m)
- 该算法从模式串的尾部开始匹配(自后向前)
BM 算法的移动字符数是通过 2 条规则计算出的最大值:
- 坏字符规则(Bad Character,简称 BC)
- 好后缀规则(Good Suffix,简称 GS)
坏字符规则(Bad Character)

当 Pattern 中的字符 E 和 Text 中的 S 失配时,称 S 为 坏字符;
- 如果 Pattern 的未匹配子串中不存在坏字符,直接将 Pattern 移动到坏字符的下一位
- 否则,让 Pattern 的未匹配子串中最靠右的坏字符与 Text 中的坏字符对齐
好后缀规则(Good Suffix)

MPLE 是一个成功匹配的后缀,E、LE、PLE、MPLE 都是 好后缀;
- 如果 Pattern 中找不到与好后缀对齐的子串,直接将 Pattern 移动到好后缀的下一位
- 否则,从 Pattern 中找出子串与 Text 中的好后缀对齐
BM算法最好情况与最坏情况
最好情况,时间复杂度:O(n / m);

最坏情况,时间复杂度:O(n + m) ,其中 O(m) 为构造表的时间;

Karp-Rabin / Rabin-Kary
Rabin-Karp 算法(或 Karp-Rabin 算法),简称 RK 算法,是一种 基于hash 的字符串匹配算法
- 由 Richard M.Karp 和 Michael O.Rabin 于 1987 年发明
大致原理:
- 将 Pattern 的 hash 值与 Text 中每个子串的 hash 值进行比较
- 某一子串的 hash 值可以根据上一子串的 hash 值在 O(1) 时间内计算出来
Sunday
Sunday 算法由 Daniel M.Sunday 在 1990 年提出,它的思想跟 BM算法 很相似
- 从前向后匹配(BM算法是从后往前)
- 当匹配失败时,关注的是 Text 中参与匹配的子串的下一位字符 A
如果 A 没有在 Pattern 中出现,则直接跳过,即 移动位数 = Pattern长度 + 1
否则,让 Pattern 中最靠右的 A 与 Text 中的 A 对齐
