图像识别实战(二)----读取数据reader
从本地、网络、分布式文件系统HDFS等读取文件,同时也可随机生成数据,并返回一个或多个数据项。
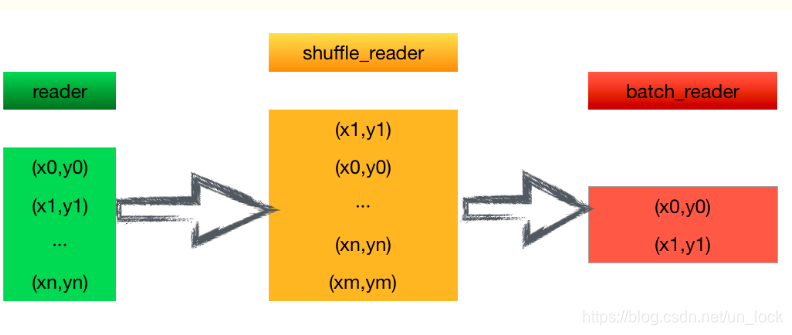
reader的实质是一个迭代器(yield),每次返回一个数据
创建reader
reader = paddle.dataset.uci_housing.train()
但是很多数据集非常规范,即所有相同的标签存在聚集效应,这就造成了,模型训练某一个标签的时候要不就全部训练,要不就一点也训练不了,
为了解决这一问题就有了shuffle_reader()&batch_reader()
shuffle_reader
shuffle就是一个装满了reader的容器,装了很多很多reader(buf_reader)个,shuffle的功能就是把他们的顺序打乱
shuffle_reader,可以将reader中的数据放进去,同时返回reader,
shuffle_reader存在一个buf_size参数,int类型,配置buf_reader之后就可以每次读取buf_reader个数据,之后将这buf_reader个数据打乱,随机化。
每次读取buf_size个数据,就完美的契合机器学习,每次选择一定数量的训练数据进行训练。
shuffle_reader = paddle.reader.shuffle(reader ,buf_size = 100)
batch_size
每次读取打乱过后的batch_size个数据进行训练
batch_reader = paddle.batch(shuffle_reader,batch_size = 2)
高级用法:
三个函数组合起来
reader = paddle.batch(
paddle.reader.shuffle(
uci_housing.train(),
buf_size = 100),
batch_size=2)
如果想了解图像识别实战的全过程,请务必点击博主名字,进入主页查看全部。
别忘了留下,你的点赞、评论和关注偶~