KNN算法原理详解
KNN算法
K个最近邻法(K-Nearst-Neighbor,KNN),解决监督学习中的分类问题
1.1 解决监督学习中分类问题的一般步骤
–也是解决机器学习问题的基本流程(写代码时也是这个流程)
1.EDA数据探索性分析
2.特征工程(目的:将数据转换成满足算法需求的数据)
非数值数据做数值化处理,数值数据做非量纲处理
3.将数据集进行切分(分为训练集与测试集)
4.训练模型:用训练集来训练模型
5.测试集:用得到的训练模型对测试集进行测试
6.模型评价:准确率
注:分类问题是最常见的监督学习问题,最基础的就是二分类问题(Binary Classification)即判断是非,从两个类别中选择一个作为预测结果
1.2 什么是消极(惰性)的学习方法
分类算法:一种根据输入数据集建立分类模型的系统方法,如决策树算法,支持向量机,朴素贝叶斯和一些基于规则的分类算法
积极的学习方法:利用算法通过建立模型然后将测试数据应用于模型的方式就是积极的学习方式 –会有一个真正的训练模型
消极的学习方法:推迟对训练数据的建模,直到真正需要分类测试样例时再进行分类,这种延迟的建模技术叫做消极的学习方法 –没有真正的训练模型
也就是说这种学习方法只有到了决策时(对测试样本分类时),才会利用已有的数据(切分之前的数据集)进行决策,而在这之前不会对样本进行训练
区别:
积极学习在进行决策时需要考虑到了所有额训练样本数据,虽然耗费了训练时间,但是决策时间几乎为0.
消极学习在决策时需要计算所有样例与查询点之间的距离,但是在真正决策时却只会用几个局部训练数据,所以他是一个局部近似,虽然不需要训练其复杂度为0(n),其中n为样本的特征个数,由于每次决策需要计算质心与每个样本点的距离 --> 缺点:需要的内存空间比较大,==决策的过程缓慢
以上比对KNN算法就很好理解了
K个最近邻算是消极学习的典型例子,之所以说它具有"惰性",不是因为它看起来简单,而是因为它仅仅对训练数据集具有记忆功能,而不会从训练集中通过学习得到一个判别函数(模型)
2 首先从一个实例讲起

3 KNN分类算法入门
3.1.1算法综述
分类算法(classification)
输入基于实例的学习(instance-based learning),惰性学习(lazy learning)
3.1.2算法思想
K近邻算法,给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最近邻的K个实例,这K个实例的多数属于某类,就把该输入实例分类到这个类(label)下
3.2 KNN三要素详解
3.2.1 关于距离的衡量方法
KNN算法中要求数据的所有特征都可以做比较量化若在数据特征中存在非数值类型,必须采用手段将其量化为数值(由此也引发了量化时量纲不同的问题,最后由在距离度量中引入期望,方差来解决)

(4)闵可夫斯基距离(N个特征)
闵式距离不是一种距离,而是一组距离的定义,是对多个距离度量公式额概括性表述.

闵式距离的缺点:
将各个分量(特征)的量纲)(scale),也就是"单位"相同看待了
未考虑各个分量的分布(期望,方差)可能是不同的
对闵式距离的缺点解决:在距离度量中引入期望和方差来解决量化时量纲不同的问题
3.2.2 K值的选择问题
K值选择是KNN算法的关键,K值选择对近邻算法的结果有重大影响
K值的具体含义:在决策时通过依据测试样本的K个最近邻"数据样本"做决策判断.
(实际应用)
K值一般取较小值,通常采用交叉验证法来选取最优K值,也就是比较不同的K值时的交叉验证平均误差,选择平均误差最小的那个K值.
可以理解为对K值的选择就是对训练模型中参数的选择,交叉验证法(后面做了详细介绍)就可以理解为损失函数
3.2.3 分类决策的准则
1 投票表决
少数服从多数,输入实例的K个最近邻中哪种类(label)的实例点最多,流分为该类
2加权投票法(改进)
根据距离的远近,对K个近邻的投票做加权,距离越近权重越大(比如权重为距离的倒数)

4 算法步骤详解
4.1 KNN算法的步骤

4.2 算法的优缺点
优点:
简单
易于理解
容易实现
通过K值的选择可具备丢噪音数据的健壮性
缺点:
需要大量空间存储已知实例
算法复杂度高(需要比较所有已知实例与要分类的实例)
当样本的分类不均时,新的未知数据容易被归类到占主导样本的类别中
5 补充:KDTree
K近邻法如何对训练数据进行快速K近邻搜索(快速找到K个最近邻样本实例)是个问题.最简单粗暴的方法:线性描述,就是通过计算输入样本与每个训练样本的距离,来找到最近邻的K个训练样本,当训练样本很大时,计算很耗时,此时使用KDTree,可以大幅提高K近邻搜索的效率
kd树算法分为两大部分:1.kd树这种数据结构建立的算法 ,2.在kd树上如何进行最近邻查找的算法
5.1 构造KD树的算法
输入:K维空间数据集T={(x1,y1),(x2,y2)…(x3,y3)},xi为实例的特征向量,yi={c1,c2…ck}为实例类别.这里K为2,所以K-1就可以理解为训练样本中特征的个数.
输出:KD树
split一般按照数据点中,从左到右把每个特征命名为0,1,2…K
算法步骤: 本例中采用的是二维数据集 -->对应空间x-y坐标, 三位数据集–>对应空间x-y-z坐标
开始:构建根节点(根节点的树的深度为0,用j代指),选择x轴(究竟选择哪个轴是以所有数据点中x,y…每个方向的方差最大的那个),然后以T中所有样本点中x坐标中的中位数xj值作为切分点(二维空间中的表示是条直线切分,多维空间中就是超平面切分了).将根节点的矩形切分为两个子区域,切分平面的方程是x=xj,左结点(left)中的点的x<xj,右结点(right)中的点的x>xj.然后循环的对根节点的两个子域中构建子根节点.循环下去.
结束:直到所有结点的两个子域中没有样本存在时,切分停止,得到kd树
问题1:后面如何选择哪个轴(方向)呢?
这里是有一个公式的:
l=j(modk)+1
其中j为当前构建的子根节点树的深度,k为数据点的维度(j对k取模),算出l为1,则选x轴,为2选y轴,…为k选k轴 j(modk)是取模操作,所以l的最大值是k,此时选的就是k轴了.
所以深度为1的子根节点都是通过x轴选出来的
问题2:中位数的选取:
KD树中中位数的求取是:获取所有样本点中对应轴的数值,然后做升序排序,样本点个数/2向下取整后+1,得到的值为N,则就是排序为第N个数了(从1开始算起)
5.1.1 KDTree实例
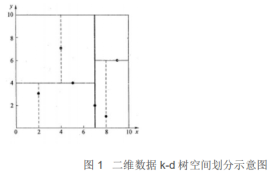
&emps;先通过简单的直观案例来介绍kd树算法.假设有六个数据点{(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)},.数据点位于二维空间中(如下图),kd树算法就是要确定下图中这些分割空间的分割线(多维空间即为分割平面,一般为超平面)
下面就是一步步展示kd树如何确定这些分割线的
kd树算法可以分为两个部分,一部分是关于kd树本身这种数据结构建立的算法,另一部分是建立在kd树这种数据结构上如果进行最近邻查找的算法


补充:树的深度与高度的区别:
深度:对于任意节点n,n的深度为从根到n的唯一路径长,根的深度为0.
高度:对于任意节点n,n的高度为从n到一片树叶的最长路径长,所有树叶的高度为0.
5.2 构造KD树的最近邻查找算法
输入:KD树,样本x
输出:样本x的最近邻点
步骤:
(1)在kd树中找到包含样本x的叶节点,方法就是从根节点出发,递归的向下访问kd树

并以此节点为”当前最近的xnst”,而真实最近点一定在x与”当前最近点”构成的球体内,x为球心.
(2)设”当前最近的xnst”为xi,递归向上回退,设回退到的结点为xii(每次回退都回退到kd树的父节点),考察结点xii与以x为球心,x到xi为半径的球是否相交
若相交:
若x是xii的左结点(此时的xi也是xii的左结点),则进入xii的右结点,然后先进行向下搜索(找到xi右),判断xii与以x为球心,x到xi右为半径做圆是否相交,若还相交退到xiii,做考察结点xiii与以x为球心,x到xii为半径的球是否相交(相交然后又判断xii是xiii的左结点还是右结点,依次循环下去)
若x是xii的右结点,步骤与上面的一样
若不相交:
直接退回,此时与x做圆且与它的父结点不相交的那个点就是x点的最近邻点了
(3)若回退到了根节点了,搜索结束,最后的那个”最近邻点”(与x做圆的点)即为x的最近邻点.
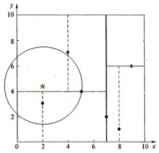
x的”当前最近邻点”应该是(4,7),以x为圆心做圆,发现与(4,7)的父节点(5,4)相交,进入左结点:
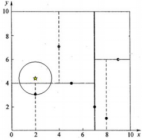
从而得到了x的最近邻点
6 测试案例:鸢尾花的训练


7 KNN的分类KNeighborsClassifier的API详解
from sklearn.neighbors impotent KNeighborsClassifier

以上参数中有值的都是默认参数中的默认值
7.1 参数
n_neighbors:整数类型,指定K值
Weights:一个字符串或可调用对象,指定投票权重类型,即这些邻居的投票权重可以是相同的或不同(根据距离来设置权重)
uniform:近邻投票的权重相同
distance:近邻投票的权重与近邻到样本x的距离成反比
callable:一个可调用对象,它传入距离的数组,返回同样大小的权重数组
Algorithm:字符串类型,指定使用的最近邻算法
ball_tree:使用BallTree算法
kd_tree:使用KDTree算法
brute:使用暴力搜索算法
auto:自动决定最合适的算法
leaf_size:整数类型,指定BallTree或KDTree叶结点的规模.它影响树的构建和查询速度
P:整数类型,指定minkowski(闵可夫斯基)度量上的指数,P=1曼哈度距离度量,P=2欧式距离度量
Metric:指定距离度量,默认使用minkowski距离
n_jobs:并行性,默认为-1,表示派发任务到所有计算机的CPU上
7.2 方法
fit(x,y):训练模型
predict(x):使用模型对测试集进行预测,返回带测试样本的标记
score(x,y):返回在测试集(x,y)上的准确率(accuracy)
predict_proba(x):返回样本为每种样本的概率
kneighbord([x,n_neighbors,return_distance]):返回样本点的k个近邻值,如果return_distance=true同时返回到这些点的距离
kneighbors.graph([x,n_neighbors,model]):返回样本点的连接图
8 KNN算法回归问题的解决
对于回归问题(平均法):输出一个实例的值,回归时,对于新的实例,取其k个最近邻的训练实例的平均值作为预测值
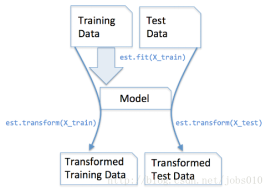
9 StandardScaler中fit_transform与transform方法的区别

标准化数据,保证了每个维度的特征数据均值为0,方差为1.
fit_transform的参数是训练集
功能:对数据先进行拟合处理,然后再将其标准化
transform的参数是测试集
功能:对数据进行标准化
由此可知:两者的差别在于fit_transform函数多了一个fit操作.那么为什么需要进行fit处理?这是因为数据归一化的过程中,需要计算出数据集的均值与方差,而这个过程fit函数能实现
那为什么只求出训练集的均值与方差?
1当求出一个数据集的均值与方差后,就可以使用如下公式做数据的归一化处理(transform).
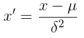
然后把训练集求出来的均值与方差当做测试集的均值与方差(因为来自同一数据集),对测试集数据做归一化处理.
1虽然测试集真实的均值与方差与训练集求出来的有一定的差异,不会太大.
2且无论是传统机器学习还是深度网络学习的数据预处理,对训练集与测试集都要采用同样的预处理策略,保持其处理的一致性.
对训练集与测试集的预处理(特征工程)如下:
10 交叉验证法与留一法
10.1 简单交叉验证法
简单的交叉验证法步骤如下:
1.将数据集分为训练数据集与测试数据集
2.使用训练集训练模型
3.使用测试集测试模型的分类正确率
4.选择具有最大分类正确率的模型
KNN默认用的就是这样,通过对不同K值的简单交叉验证,选择分类正确率最高的模型
10.2 交叉验证法
k折交叉验证k-fold cross validation
步骤:
1.将全部数据集分成K个不相交的子集,假设数据集有m个样本,则每个子集中就有m/k个样本
2.每次从分好的子集中拿出一作为测试集,其余的k-1个作为训练集
3.使用训练集训练模型(相当于对模型训练K次)
4.把这个模型放到测试集上,得到正确分类率
5.计算模型k次测试求得的正确分类率的平均值作为该模型的真实正确分类率
交叉验证实例:

score中的内容就是一个K值对应的10个子集作为训练集时模型的正确分类率
结果图示:

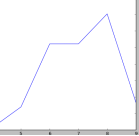
这种方法充分利用了所有样本,但是计算比较繁琐,需要训练k次,测试k次
10.3 留一法
leave-one-out cross validation
留一法就是每次只留下一个样本作为测试集,其他样本作为训练集,如果有m个样本,则需要训练m次,测试m次.
留一法计算最繁琐,但是样本利用率最高.适合与小样本的情况