摘要: 本文讲述了从在fast.ai库中读论文,到根据论文复制实验并做出改进,并将改进后的开源代码放入fast.ai库中。

介绍
去年我发现MOOC网上有大量的Keras和TensorKow教学视频,之后我从零开始学习及参加一些Kaggle比赛,并在二月底获得了fast.ai国际奖学金。去年秋天,当我在全力学习PyTorch时,我在feed中发现了一条关于新论文的推文:“平均权重会产生更广泛的局部优化和更好的泛化。”具体来说,就是我看到一条如何将其添加到fast.ai库的推文。现在我也参与到这项研究。
在一名软件工程师的职业生涯中,我发现学习一门新技术最好的方法是将它应用到具体的项目。所以我认为这不仅可以练习提高我的PyTorch能力,还能更好的熟悉fast.ai库,也能提高我阅读和理解深度学习论文的能力。
作者发表了使用随机加权平均(SWA)训练VGG16和预激活的Resnet-110模型时获得的改进。对于VGG网络结构,SWA将错误率从6.58%降低到6.28%,相对提高了4.5%,而Resnet模型则更明显,将误差从4.47%减少到3.85%,相对提高了13.9%。
论文
背景
随机加权平均(SWA)方法来自于集成。集成是用于提高机器学习模型性能的流行的技术。例如,ensemble算法获得了Nekix奖,因为Netkix过于复杂不适用于实际生产,而在像Kaggle这样的竞争平台上,集成最终性能表现结果可以远超单个模型。
最简单的方式为,集成可以对不同初始化的模型的若干副本进行训练,并将对副本的预测平均以得到整体的预测。但是这种方法的缺点是必须承担n个不同副本的成本。研究人员提出快照集成(Snapshot Ensembles)方法。改方法是对一个模型进行训练,并将模型收敛到几个局部最优点,保存每个最优点的权重。这样一个单一的训练就可以产生n个不同的模型,将这些预测平均就能预测出整体。
在发表SWA论文之前,作者曾发表过快速几何集成(FGE)方法的论文,改方法改进了快照集成的结果,FGE方法为“局部最优能通过近乎恒定损耗的简单曲线连接起来”也就是说,通过FGE作者能够发现损耗曲面中的曲线具有理想的特性,以及通过这些曲线集成模型。
在SWA论文中,作者提供了SWA接近FGE的证据。然而,SWA比FGE的好处是推理成本较低 。FGE需要产生n个模型的预测结果,而对于SWA而言,最终只需要一个模型,因此推断可以更快。
算法
SWA算法的工作原理相对简单。首先制作你正在训练的模型的副本,以便用于跟踪平均权重。在完成epoch训练后,通过以下公式更新副本的权重:
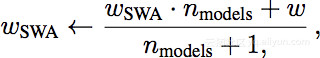
其中n_models是已经包含在平均值中的模型数量,w_swa表示副本的权重,w表示正在训练的模型的权重。这相当于在每个epoch训练时期结束时存储模型的运行平均值。这就是该算法的精髓,但论文还介绍了一些细节,首页作者制定了具体的学习率计划,以确保SGD在开始平均模型时就能够找到出最优点。其次,对网络进行预训练以达到开始时就有一定数量的epochs,而不是一开始就追踪平均值。另外,如果使用周期性学习率,那么需要在每个周期结束时存储平均值,而不是在每个epoch后。
寻找更广泛的最优点
SWA的算法的工作方式,作者提供了证据,证明与SGD相比,它能使模型达到更广泛的局部最优,从而能够提高模型的泛化能力,因为训练损失和测试数据可能不完全一致。因此,对训练数据进行更广泛的优化使得模型对测试数据进行优化。
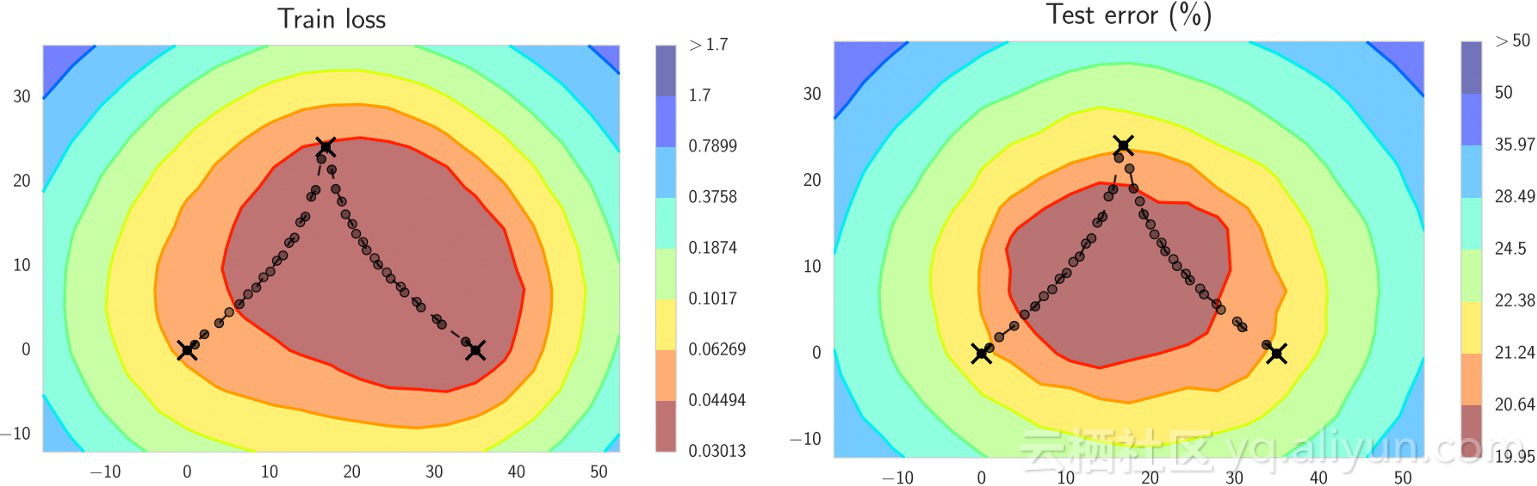
图三的一部分
由图可得,训练损失(左)和测试错误(右)相似但不完全相同。例如,最右边的X处于训练损失表面的最佳点,但距离最优测试误差有一定距离。正是这些差异能更容易的寻找更广泛的最优点,这更可能成为训练和测试损失的最佳点。
作者提出观点:SWA可以找到更广泛的最优点。并在论文Optima Width章节中通过实验给出了证据,将损失作为给定方向上的Optima距离的函数,来比较SGD和SWA能够发现的最优点宽度。作者对10个不同的方向进行了采样,并测量了用SGD和SWA对CIFAR-10进行训练的Preactivation Resnet的损失,结果如下:
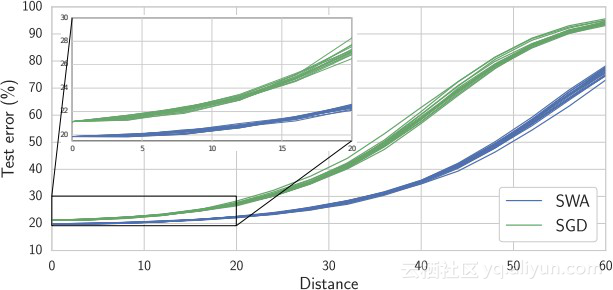
图4:“测试误差...作为随机射线上的点函数,起始于CIFAR-100上预激活ResNet-110的SWA(蓝色)和SGD(绿色)解决方案。”
图中数据提供了证据,表明SWA发现的optima比SGD所发现的更广泛,因为它与SWA最优的距离比增加同样数量的测试错误的距离更大。例如,要达到50%的测试误差,你必须从距离SGD的最佳距离为30,而SGD为50。
实验
作者进行了大量的实验来验证SWA方法在不同的数据集和模型架构上的有效性。首先,我将详细描述为了实现该算法做的实验设置,然后讲解一些关键结果。
使用VGG16和预激活的Resnet-110体系结构在CIFAR-10上进行了复制实验。每个体系结构都有一定的预算,以表示仅使用SGD +动量来训练模型收敛所需的时间数。VGG预算为200,而Resnet则为150。然后,为了测试SWA,模型用SGD +动力培训约75%的预算,然后用SWA进行额外的epochs训练,达到原始预算的1、1.25和1.5倍。对每个测试训练了三个模型,并报告平均值和标准偏差。
除了对CIFAR-10的实验外,作者还对CIFAR-100进行了类似的实验。他们还在ImageNet上测试了预训练模型,使用SWA运行了10个epochs,并发现在预训练的ResNet-50、ResNet152和DenseNet-161的精度提高了。最后,作者通过使用固定学习速率的SWA,成功地从scratch中训练了一个宽的ResNet-28-10。
实现
阅读并理解该论文后,我尝试在fast.ai库中找出哪个位置添加代码能够使SWA正常工作。该位置已经找到了,因为fast.ai库提供了添加自定义回调的功能。如果我用每个epoch结束时调用的hook来写回调,那么就能在适当的时间更新权重的运行平均值。这是结束的代码:

回调采用三个参数:model、swa_model和swa_start。前两个是我们正在训练的模型,以及我们将用来存储加权平均的模型副本。swa_start参数是平均开始的时间,因为在论文中,模型总是在开始跟踪平均权重之前,用SGD+动量对一定数量的epochs进行训练。
从这里你可以看到SWA回调如何将算法从文件转换成PyTorch代码。在SWA开始的epoch中,我们将更新参数的运行平均值,并增加平均值中包含的模型数量。
在SWA模型进行推断前,我们还需要用包含代码修复batchnorm的运算平均值。batchnorm层通常在训练期间计算这些运行统计数据,但由于模型的权重是作为其他模型的平均值计算的,所以这些运行统计数据对于SWA模型是错误的,因此需要再次单次传递数据让batchnorm层计算正确的运行统计数据。修复代码如下:

测试
测试非常重要,但是在机器学习代码中应用单元测试是很困难的,因为有一些不确定的因素或者测试的状态需要较长时间。为了确保所做工作实际上是有效的,我做了两个测试,一个是“功能”测试,它们是较小的代码块,通常运行在比较简单的模型上,旨在回答:“这个功能是否按照我的想法实现了?”例如,一项功能测试表明,在经过几个阶段的训练后,SWA模型实际上等于所有SGD模型参数的平均值:

这些测试通常在30秒内就能运行完成,所以在编写实现代码遇到问题时能快速提醒我。由于fast.ai库的开发速度非常快,这些测试还能在试图解决master分支合并问题时快速识别问题。
第二个测试为“实验”测试。它的目的是回答:“如果我用自己的实现和fast.ai库重新进行论文中的实验,我是否能观察到与论文相同的结果?”每次我实现一个功能就会运行这个测试,以确定SWA是否对库做出有用的贡献。实验测试要比功能测试花费的时间长,但能确保一切都按预期运行。
最后我可以复述论文的结果-随机权重平均确实在CIFAR-10上产生了比一般SGD更高的准确性,并且随着训练时期的增加,这种改善通常会增加。正如下表所示,我所有的结果都比原始论文结果更准确。其中一个因素可能是数据增强的方式——对于CIFAR-10,通过将每个图像填充4个像素并随机裁剪进行增强,并且我发现fast.ai默认使用不同类型的填充(rekection填充)。然而,可以清楚地看到SWA改善超过SGD +momentum的模式。
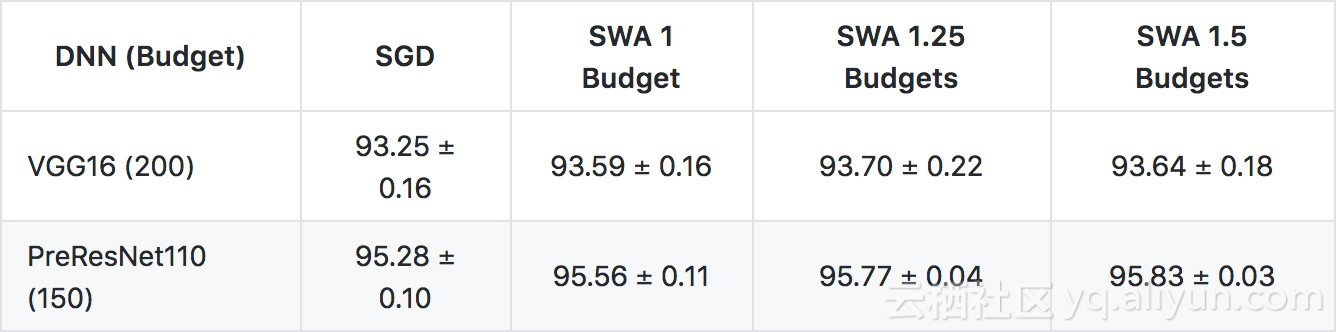
原始论文的结果
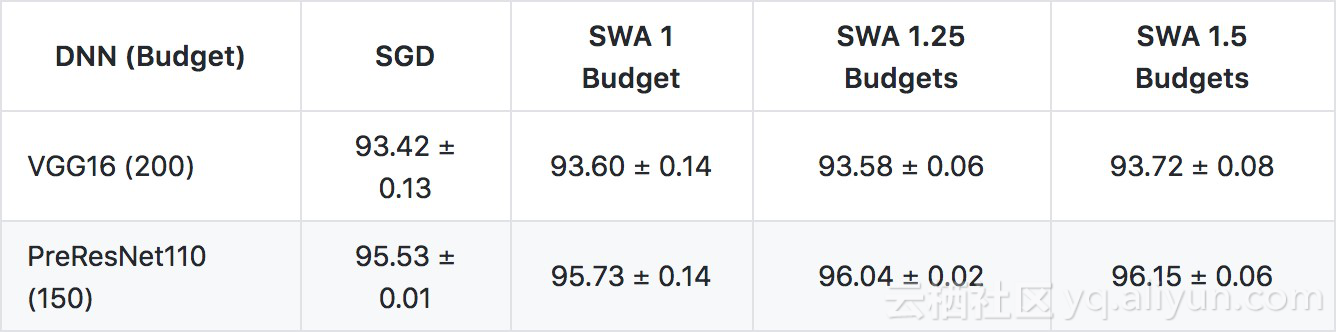
我的结果
获取测试代码请点击代码。
结论
我对这个项目的最终结果非常满意,因为我从最前沿的研究论文中复制了一个实验,并为机器学习开源代码做出了自己的第一个贡献。我想鼓励大家下载fast.ai库,并尝试一下SWA吧!
本文为云栖社区原创内容,未经允许不得转载。