在适应机器学习等模型来进行实验的时候,我们往往事先需要对原始数据样本的分布有一定的了解,初步了解我们的样本数据一共有多少类别,各个类别中样本数据的比例是否均衡,因为对于不均衡的数据比例会采用不同的模型,如:对于正负样本数据失衡的情况我们往往会采用异常点检测等方法,而不是SVM这类常规的检测模型。
下面是简单的方法,通过对样本数据类别标签的展示来可视化不同类别样本数据的占比情况:
from collections import Counter
def sample_class_show(y,savepath='res.png'):
'''
绘制饼图,其中y是标签列表
'''
target_stats=Counter(y)
labels=list(target_stats.keys())
sizes=list(target_stats.values())
explode=tuple([0.1] * len(target_stats))
fig, ax=plt.subplots()
ax.pie(sizes, explode=explode,labels=labels, shadow=True,autopct='%1.1f%%')
ax.axis('equal')
plt.savefig(savepath)
简单测试如下:
实验一:
y=[0,0,1,2,0,2,2,0,0,0,0,1,1,2,2,2,0,0,2,2,2,2,2,2,2,2,1,1,1,2,2,2,2,0,0]
sample_class_show(y,savepath='label_distribution.png')
结果如下:
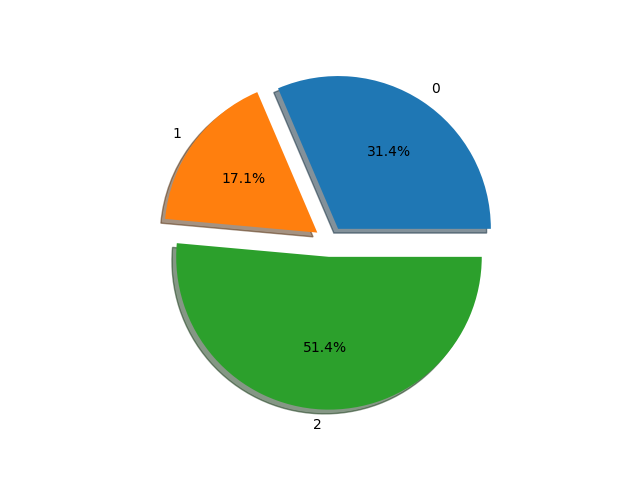
实验二:
y=[0,0,1,2,0,2,2,0,0,0,3,3,3,3,3,0,1,1,2,2,3,3,3,3,2,0,0,2,2,2,2,2,2,2,2,1,1,1,2,2,2,2,0,3,3,0,1,1,1,2,2,2,0,0,3,3,3] sample_class_show(y,savepath='label_distribution2.png')
结果为:

从上面的饼图中,我们可以很直观地看出来不同类别样本数据的不同占比情况,对于后续的处理有一定的帮助。