系统综合实践第四次作业博客
实践内容
(1)使用Docker-compose实现Tomcat+Nginx负载均衡
工作目录
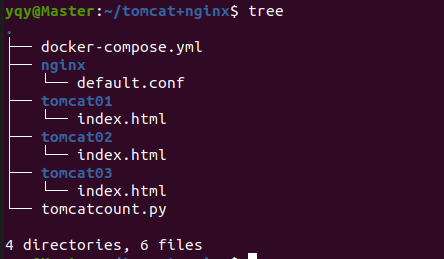
需要编写docker-compose文件和修改nginx配置
---------------------------------------------------------docker-compose.yml--------------------------------------------------------
version: "3"
services:
nginx:
image: nginx
container_name: cgh-docker-4
ports:
- 8080:2537
volumes:
- ./nginx/default.conf:/etc/nginx/conf.d/default.conf # 挂载配置文件
depends_on:
- tomcat01
- tomcat02
- tomcat03
tomcat01:
image: tomcat
container_name: tomcat1
volumes:
- ./tomcat01:/usr/local/tomcat/webapps/ROOT # 挂载web目录
tomcat02:
image: tomcat
container_name: tomcat2
volumes:
- ./tomcat02:/usr/local/tomcat/webapps/ROOT
tomcat03:
image: tomcat
container_name: tomcat3
volumes:
- ./tomcat03:/usr/local/tomcat/webapps/ROOT
---------------------------------------------------------default.conf(nginx)---------------------------------------------------------
upstream tomcats {
server tomcat1:8080; # 主机名:端口号
server tomcat2:8080; # tomcat默认端口号8080
server tomcat3:8080; # 默认使用轮询策略
}
server {
listen 2537;
server_name localhost;
location / {
proxy_pass http://tomcats; # 请求转向tomcats
}
}
用python编写一个小程序(访问36次)来了解nginx的负载均衡策略(至少两种)
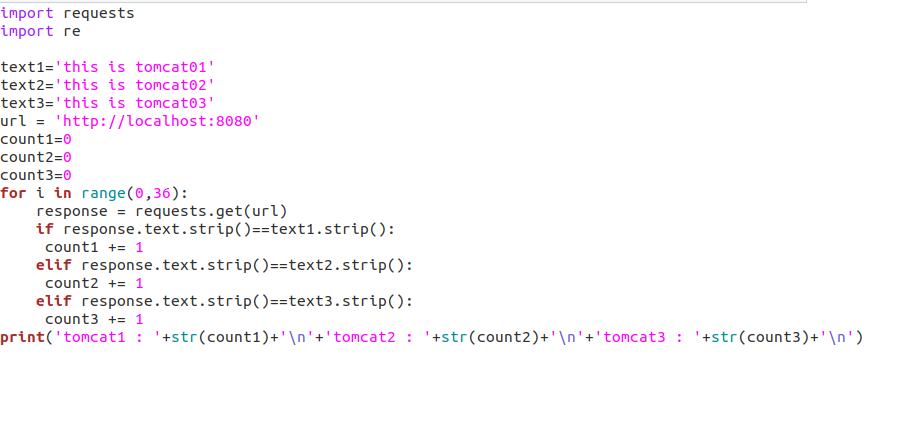
(1)轮询策略
如果三个tomcat服务器的权重都相等,则使用的是轮询策略 访问tomcat1、tomcat2、tomcat3次数比为1:1:1
这里贴上程序运行结果

(2)权重策略
权重策略:每个服务器以正比于其权重的概率被访问
upstream tomcats {
server tomcat1:8080 weight=1; # 主机名:端口号
server tomcat2:8080 weight=2; # tomcat默认端口号8080
server tomcat3:8080 weight=3; # 默认使用轮询策略
}
运行结果也符合1:2:3的结果

(2)使用Docker-compose部署javaweb运行环境
这里直接用作业链接上的项目
工作目录
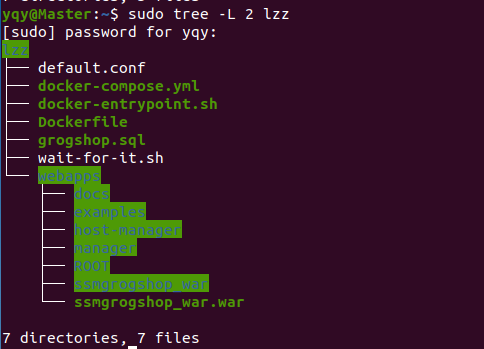
准备所需要的文件
---------------------------------------------------------docker-compose.yml---------------------------------------------------------
version: "3" #版本
services: #服务节点
tomcat: #tomcat 服务
image: tomcat #镜像
hostname: hostname #容器的主机名
container_name: tomcat00 #容器名
ports: #端口
- "5050:8080"
volumes: #数据卷
- "./webapps:/usr/local/tomcat/webapps"
- ./wait-for-it.sh:/wait-for-it.sh
networks: #网络设置静态IP
webnet:
ipv4_address: 15.22.0.15
mymysql: #mymysql服务
build: . #通过MySQL的Dockerfile文件构建MySQL
image: mymysql:test
container_name: mymysql
ports:
- "3309:3306"
#红色的外部访问端口不修改的情况下,要把Linux的MySQL服务停掉
#service mysql stop
#反之,将3306换成其它的
command: [
'--character-set-server=utf8mb4',
'--collation-server=utf8mb4_unicode_ci'
]
environment:
MYSQL_ROOT_PASSWORD: "123456"
networks:
webnet:
ipv4_address: 15.22.0.6
nginx:
image: nginx
container_name: "nginx-tomcat"
ports:
- 8080:8080
volumes:
- ./defaultconf:/etc/nginx/conf.d # 挂载配置文件
tty: true
stdin_open: true
networks:
webnet:
ipv4_address: 15.22.0.7
networks: #网络设置
webnet:
driver: bridge #网桥模式
ipam:
config:
-
subnet: 15.22.0.0/24 #子网
---------------------------------------------------------Dockerfile(mysql)---------------------------------------------------------
# 这个是构建MySQL的dockerfile
FROM registry.saas.hand-china.com/tools/mysql:5.7.17
# mysql的工作位置
ENV WORK_PATH /usr/local/
# 定义会被容器自动执行的目录
ENV AUTO_RUN_DIR /docker-entrypoint-initdb.d
#复制gropshop.sql到/usr/local
COPY grogshop.sql /usr/local/
#把要执行的shell文件放到/docker-entrypoint-initdb.d/目录下,容器会自动执行这个shell
COPY docker-entrypoint.sh $AUTO_RUN_DIR/
#给执行文件增加可执行权限
RUN chmod a+x $AUTO_RUN_DIR/docker-entrypoint.sh
# 设置容器启动时执行的命令
#CMD ["sh", "/docker-entrypoint-initdb.d/import.sh"]
---------------------------------------------------------default.conf(nginx)---------------------------------------------------------
upstream tomcat123 {
server tomcat00:5050;
}
server {
listen 8080;
server_name localhost;
location / {
proxy_pass http://tomcat123;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
}
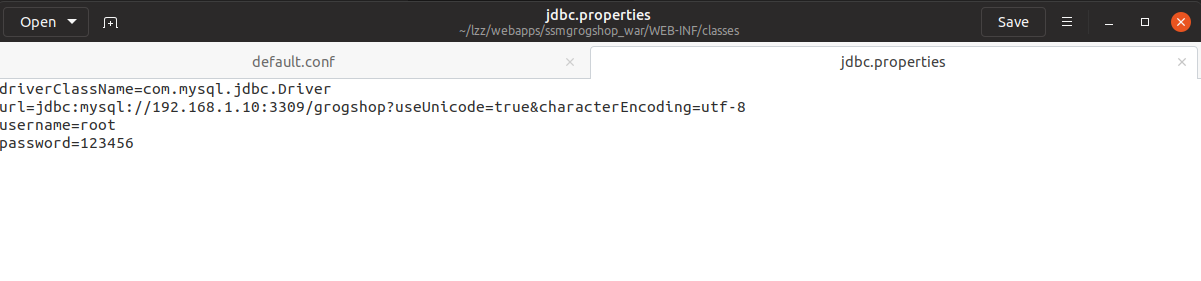
还要修改jdbc的属性配置,将ip地址换为主机的ip地址
启动容器 $ sudo docker-compose up -d

运行结果
输入账号密码进入主界面
进入mymysql容器查看增加的数据

修改default.conf以实现多负载运行
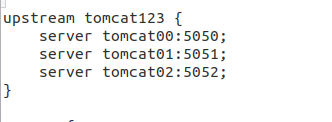

(3)使用Docker搭建大数据集群环境
配置环境,至少包含三个节点(master、slave1、slave2)
先在终端输入$ sudo docker pull ubuntu 拉取Ubuntu镜像
挂载本地目录启动

将hadoop和jdk放到本地挂载的目录
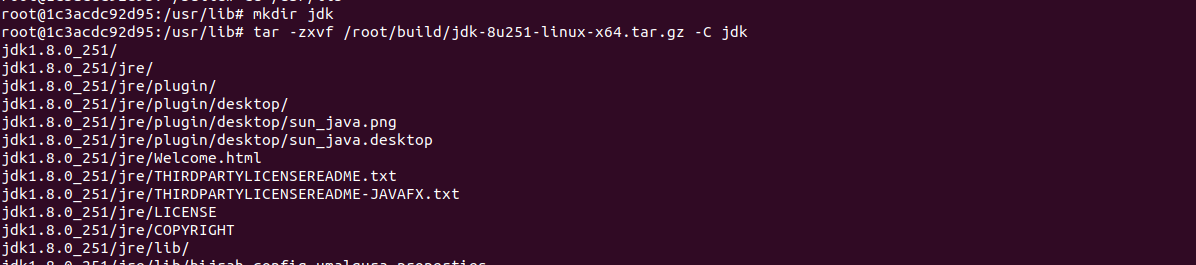
进入到容器相应的目录加压hadoop和jdk

输 入$ vim ~/.bashrc 添加环境变量
export JAVA_HOME=/usr/lib/jdk/jdk1.8.0_251
export JRE_HOME=$JAVA_HOME/jre
export HADOOP_HOME=/usr/local/hadoop-3.1.3
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$JAVA_HOME/bin
更改完毕后要输入 $ source ~/.bashrc 使改动生效
验证jdk和hadoop的安装


配置ssh
先输入 $ apt-get install ssh 安装ssh
输入以下三条命令进行ssh的免密配置
ssh-keygen -t rsa # 一直Enter
cd ~/.ssh
cat id_rsa.pub >> authorized_keys
然后一一修改以下必要的配置文件
在start-dfs.sh和stop-dfs.sh前加入下列参数

在start-yarn.sh和stop-yarn.sh前加入下列参数

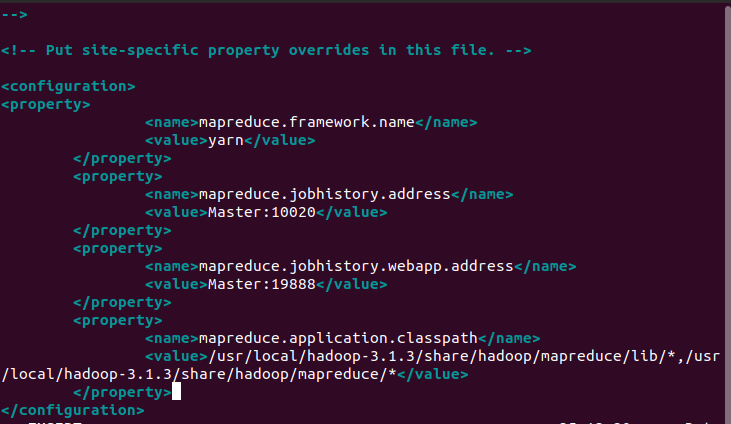
配置mapred-site文件
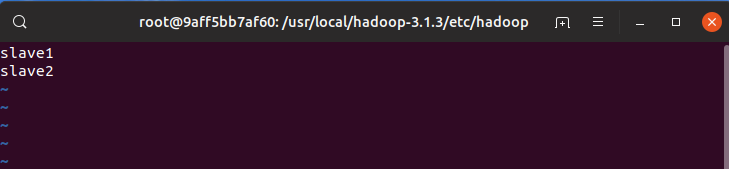
修改workers
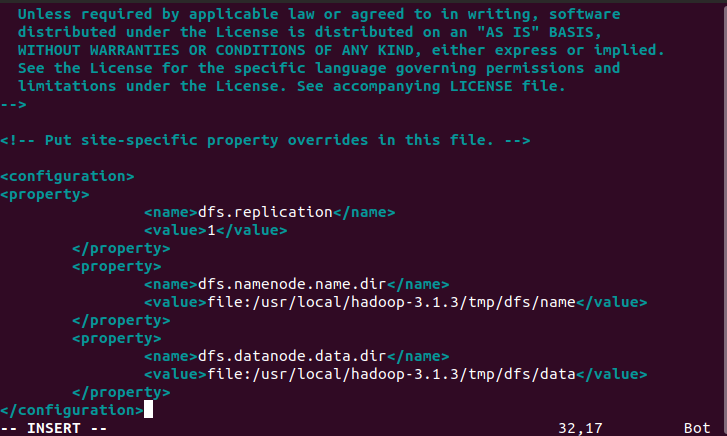
配置hdfs-site文件
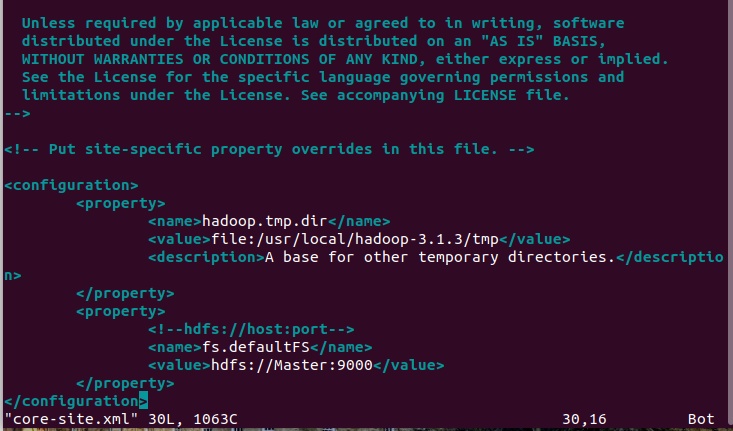
配置core-site文件
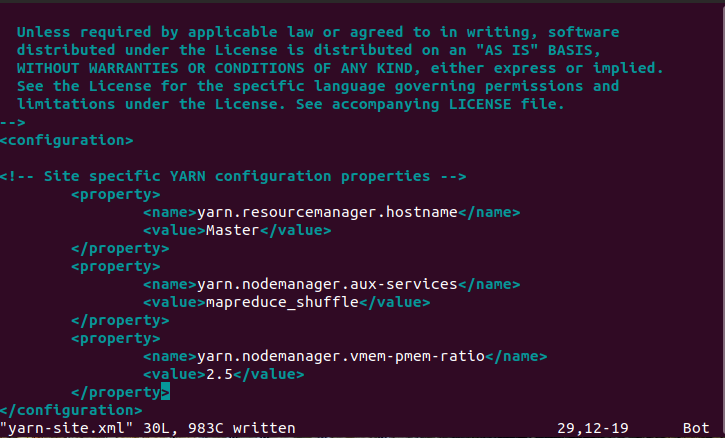
配置yarn-site文件
进入hadoop-env.sh中配置JAVA_HOME

配置完以上文件后通过docker commit来提交此镜像(镜像名 ubuntu/hadoop)

接着开启三个终端分别启动三个容器
# 第一个终端
docker run -it -h master --name master ubuntu/hadoop
# 第二个终端
docker run -it -h slave1 --name slave1 ubuntu/hadoop
# 第三个终端
docker run -it -h slave2 --name slave2 ubuntu/hadoop
分别查看master、slave1、slave2三个容器的IP地址
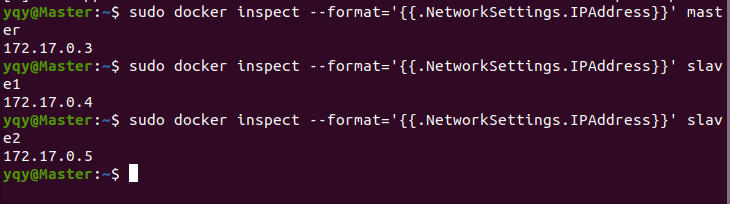
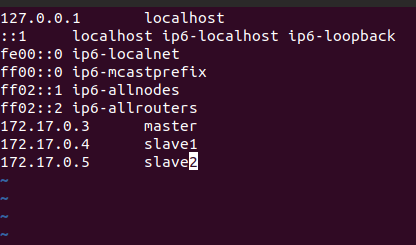
输入 $ vim /etc/hosts 修改主机信息(三个容器都要)
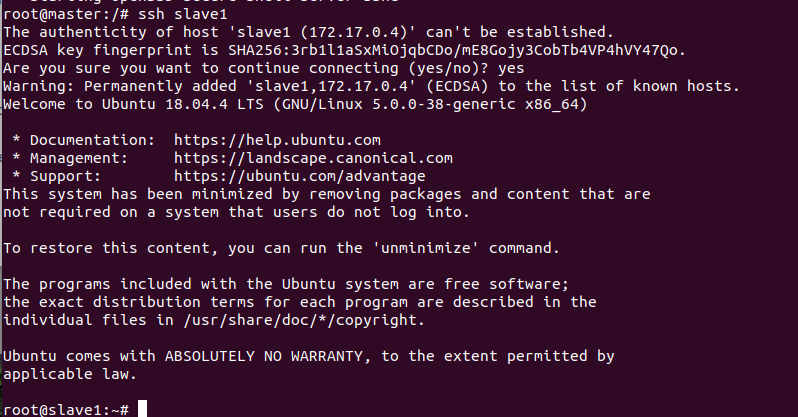
尝试通过ssh连接其他容器(master连接slave1)
开启hadoop服务,在master中输入以下命令以启动服务
cd /usr/local/hadoop-3.1.3
bin/hdfs namenode -format # 格式化文件系统
sbin/start-dfs.sh # 开启NameNode和DataNode服务
sbin/start-yarn.sh
分别在三个master、slave1、slave2节点输入jps查看节点启动情况
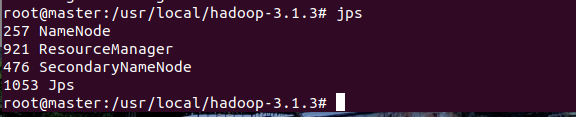
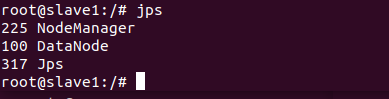
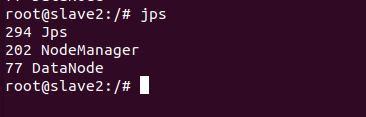
以上进程皆启动成功接下来就可以运行hadoop上的实例(这里运行的是grep)了
依次输入以下命令
hdfs dfs -mkdir -p /user/root/input #新建input文件夹
hdfs dfs -put /usr/local/hadoop-3.1.3/etc/hadoop/*s-site.xml input #将部分文件放入input文件夹
hadoop jar /usr/local/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar grep input output 'dfs[a-z.]+' #运行示例程序grep

需要等比较长一段时间,接下来输入 $ hdfs dfs -cat output/* 来查看运行的结果

最后
所花时长:12小时左右
总结:这次实践巩固了上次实践学习到的多容器交互的知识,加深了理解。要注意的是挂载最好不要直接挂载文件,直接挂载目录,如果直接挂载文件会出现本地文件修改而容器内文件无法进行同步的情况(这一点尝试了好久)。同时还学习了服务器多负载的配置,以及正向代理和反向代理两个概念:正向代理代理的是客户端,而反向代理代理的是服务器。每次实践的开始还是会不知所措,你永远不知道每一步会遇到啥奇葩的错误,还是需要非常耐心地反回去检查之前的步骤查出出错的地方,时不时返工、浏览器同时打开十几个标签页都是很正常的事情。