激活函数
本文介绍了ReLU、sigmoid、tanh三种常用激活函数及其导数,并用代码绘制了图像
重点应掌握sigmoid函数、tanh(x)函数的导数推导过程
ReLU
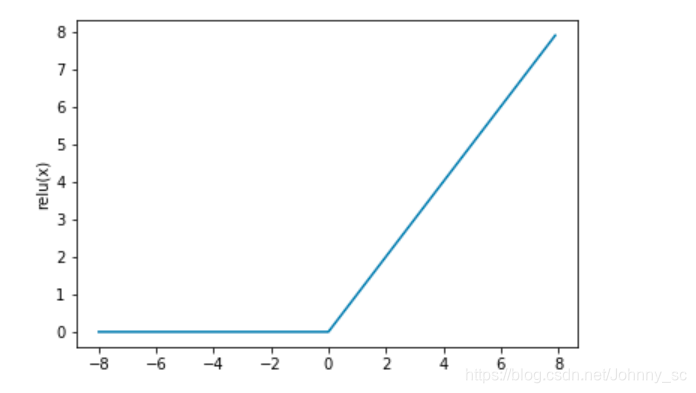
ReLU(rectified linear unit)函数提供了一个很简单的非线性变换。给定元素 x ,该函数定义为ReLU(x)=max(x,0).
可以看出,ReLU函数只保留正数元素,并将负数元素清零。为了直观地观察这一非线性变换,我们先定义一个绘图函数xyplot。
%matplotlib inline
import torch
import numpy as np
import matplotlib.pyplot as plt
import sys
sys.path.append("/home/kesci/input")
import d2lzh1981 as d2l
print(torch.__version__)
def xyplot(x_vals, y_vals, name):
d2l.set_figsize(figsize=(5, 2.5)) #设置图像大小
plt.plot(x_vals.detach().numpy(), y_vals.detach().numpy()) #描点绘制图像
plt.xlabel('x') #对横轴纵轴命名
plt.ylabel(name + '(x)')
x = torch.arange(-8.0, 8.0, 0.1, requires_grad=True)
y = x.relu()
xyplot(x, y, 'relu')
打印一下ReLU的形状:
y.sum().backward()
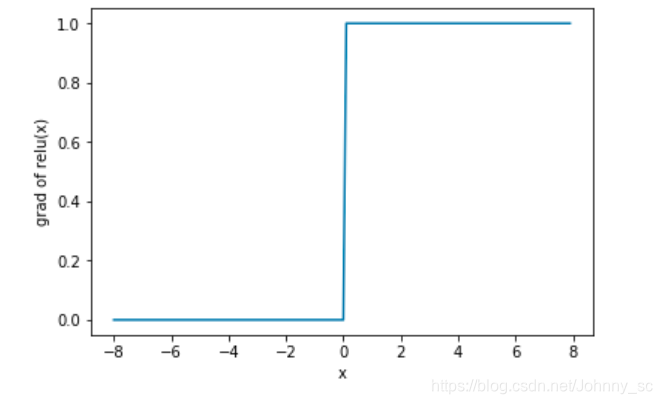
xyplot(x, x.grad, 'grad of relu')
再看一下ReLU导数 的形状:
Sigmoid函数
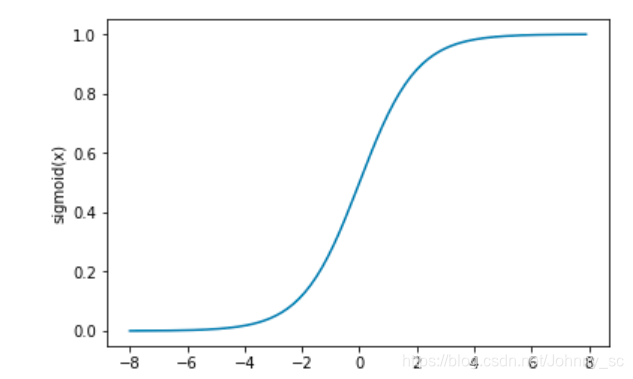
sigmoid函数可以将元素的值变换到0和1之间:
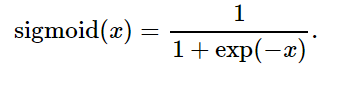
Sigmoid函数:
依据链式法则,sigmoid函数的导数:
sigmoid′(x) = sigmoid(x)(1−sigmoid(x)).
梯度消失相关问题
sigmoid梯度消失问题:
sigmoid的梯度消失是指输入值特别大或者特别小的时候求出来的梯度特别小,当网络较深,反向传播时梯度一乘就没有了,这是sigmoid函数的饱和特性导致的。
ReLU函数也有梯度消失问题吗?
ReLU在一定程度上优化了梯度消失的影响,是因为用了max函数,对大于0的输入直接给1的梯度,对小于0的输入则不管。
ReLU在x<0部分会有梯度消失问题,只有一半,ReLU存在将神经元杀死的可能性,这和他输入小于0那部分梯度为0有关,当学习率特别大,对于有的输入在参数更新时可能会让某些神经元直接失活,以后遇到什么样的输入输出都是0。但是相比于sigmoid梯度最大值0.25并且大部分区域都非常小,ReLU只有一半区域还是缓解很多
那有比ReLU更好的函数吗?
后续有Leaky ReLU来缓解这个问题,Leaky ReLU输入小于0的部分用很小的斜率,有助于缓解这个问题。
为什么选择的激活函数普遍具有梯度消失的特点?
开始的时候我一直好奇为什么选择的激活函数普遍具有梯度消失的特点,这样不就让部分神经元失活使最后结果出问题吗?后来看到一篇文章的描述才发现,正是因为模拟人脑的生物神经网络的方法。在2001年有研究表明生物脑的神经元工作具有稀疏性,这样可以节约尽可能多的能量,据研究,只有大约1%-4%的神经元被激活参与,绝大多数情况下,神经元是处于抑制状态的,因此ReLu函数反而是更加优秀的近似生物激活函数。
所以第一个问题,抑制现象是必须发生的,这样能更好的拟合特征。
那么自然也引申出了第二个问题,为什么sigmoid函数这类函数不行?
1.中间部分梯度值过小(最大只有0.25)因此即使在中间部分也没有办法明显的激活,反而会在多层中失活,表现非常不好。
2.指数运算在计算中过于复杂,不利于运算,反而ReLu函数用最简单的梯度
在第二条解决之后,我们来看看ReLu函数所遇到的问题,
1.在负向部分完全失活,如果选择的超参数不好等情况,可能会出现过多神经元失活,从而整个网络死亡。
2.ReLu函数不是zero-centered,即激活函数输出的总是非负值,而gradient也是非负值,在back propagate情况下总会得到与输入x相同的结果,同正或者同负,因此收敛会显著受到影响,一些要减小的参数和要增加的参数会受到捆绑限制。
这两个问题的解决方法分别是
1.如果出现神经元失活的情况,可以选择调整超参数或者换成Leaky ReLu 但是,没有证据证明任何情况下都是Leaky-ReLu好
2.针对非zero-centered情况,可以选择用minibatch gradient decent 通过batch里面的正负调整,或者使用ELU(Exponential Linear Units)但是同样具有计算量过大的情况,同样没有证据ELU总是优于ReLU。
所以绝大多数情况下建议使用ReLu。
*公式推导
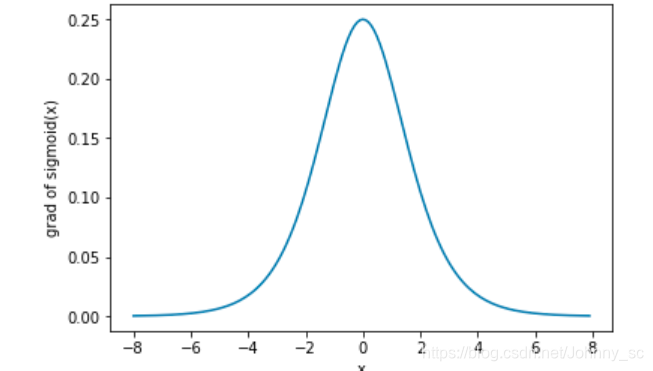
下面绘制了sigmoid函数的导数。当输入为0时,sigmoid函数的导数达到最大值0.25;当输入越偏离0时,sigmoid函数的导数越接近0。
x.grad.zero_() #梯度清零
y.sum().backward()
xyplot(x, x.grad, 'grad of sigmoid')
tanh(x)函数
tanh(双曲正切)函数可以将元素的值变换到**-1和1之间**:
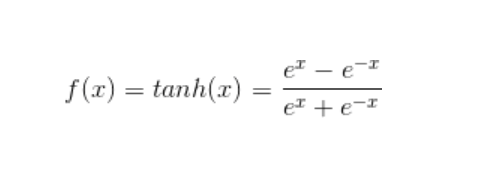
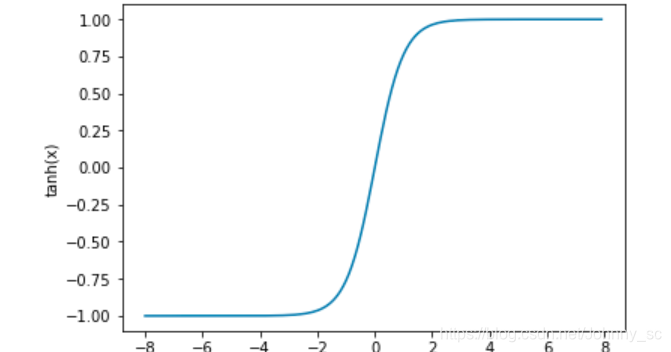
用代码看看tanh函数的形状:
y = x.tanh()
xyplot(x, y, 'tanh')
依据链式法则,tanh函数的导数推导过程:
原函数:
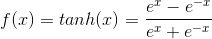
求导:
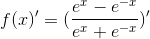
替代:a = e^x b = e^-x

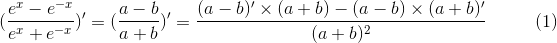
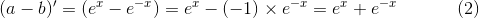
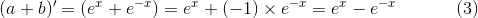
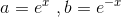
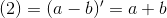
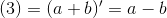
把上式的(2)、(3) 带入(1),得到
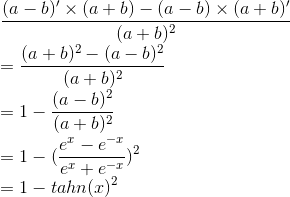
优点:非常优秀,几乎适合所有的场景。
缺点:该导数在正负饱和区的梯度都会接近于 0 值,会造成梯度消失。还有其更复杂的幂运算。
可视化:
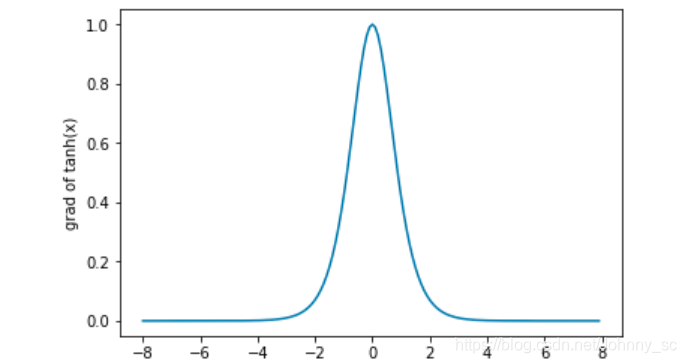
下面绘制了tanh函数的导数。当输入为0时,tanh函数的导数达到最大值1;当输入越偏离0时,tanh函数的导数越接近0。
x.grad.zero_()
y.sum().backward()
xyplot(x, x.grad, 'grad of tanh')
关于激活函数的选择
ReLu函数是一个通用的激活函数,目前在大多数情况下使用。但是,ReLU函数只能在隐藏层中使用。
用于分类器时,sigmoid函数及其组合通常效果更好。由于梯度消失问题,有时要避免使用sigmoid和tanh函数。
在神经网络层数较多的时候,最好使用ReLu函数,ReLu函数比较简单计算量少,而sigmoid和tanh函数计算量大很多。
在选择激活函数的时候可以先选用ReLu函数如果效果不理想可以尝试其他激活函数。
错题:

第二个选项说的欠妥,二者有因果关系??
从形式上看,tanh确实可以由sigmoid平移伸缩得到,tanh的取值范围(-1,1),sigmoid的取值范围是(0,1),与sigmoid的区别是,tanh是0均值的,因此实际应用中tanh会比sigmoid更好。具体使用得看应用场景。第三个问题在于Relu函数也会出现梯度消失问题,没有哪个激活函数能够防止梯度消失问题的,只是ReLU能够有效地改善,工程实践中用的最多。
