#内置函数
# print(all(['1','1','2']))#判断all里是否都为真,返回true可以传元组,字符串,字典 list,非空即真
# print(any([0,'',False]))#只要有一个元素是真,就返回真
# print(bin(10))#十进制转二进制
# print(chr(homework))#对应的ascii !
# print(ord('b'))# 98
# s = ''
# print(dir())#传入对象可调用的方法
# print(hex(111))#十进制转换16进制
# print(oct(111))#十进制转8进制
#print(globals())#返回全局变量值
# print(locals())#返回局部变量
# def func():
# name ='ab'
# age = 18
# {'name':'ab','age':10}
# print(locals())#返回函数里面的所有局部变量
# func()#返回的是字典
#常用的:
# print(max([1,4,6,8,9,5]))#取最大值,不要写字符串
# print(sum([1,4,6,8,9,5]))#求和 要求写数值,不要写字符串
# print(divmod(10,3))#取余 (3,1)商,余
# print(round(11.23434,3))#取小数 ,保留几位 后面写几
# print(zip())#把两个list 合成一个二维数组
# l = ['1','2','3']
# l2 = ['p1','p2','p3']
# print(list(zip(l,l2)))#压为一个二维数组 zip创建的是一个对象,需要转成list ,哪怕多写一个数组也不会报错,无法对应,只取能对应的
# print(dict(zip(l,l2)))#压为一个字典
# 区别:l.sort是list里面的方法,print的(l)
# 区别:sorted这个方法,是传入了一个list,返回了一个新的list
# l3 = [1,23,4,5,6,7,88,5,4,66]
# l3.sort()#对l3进行排序
# print(sorted(l3,reverse=True))#传入了list
# print(l3)
#
# l4 = [ #可以对二维数组排序
# ['xiaoming',5],
# ['xiaohei',19],
# ['xiaobai',6],
# ['xiaoliu',38]
# ]
# l5 = sorted(l4,reverse=True,key = lambda x:x[-1])
# print(l5)
# #key的作用是传一个函数名,sorted会把l4里面的元素传进去,会循环每个元素
# #第一次会把xiaomig和5这个元素传进去,传给了lambda之后,lambda把5给返回了
# #之后sorted就把5给保存下来,进行排序,依次类推
# #传给key指定的函数,然后根据函数的返回值来进行排序
# #key不是必传,如果不是二维数组,没有必要传,默认排序,因为二维数组需要指定一个排序的元素
# #lambda这个函数用过依次就会失效
# def use_key(x):
# print('x',x)
# return x[1]
#
# l6 = sorted(l4,reverse=True,key=use_key)
# print(l6)
#
# l7 = [
# ['xiaoming',5,['xiao8',9]],
# ['xiaohei',19,['xiao9',11]],
# ['xiaobai',6,['xiao10',12]],
# ['xiaoliu',38,['xiao11',14]]
# ]
# l8 = sorted(l7,reverse=True,key=lambda x:x[-1][-1])
# l9 = sorted('sdfdfs1324',reverse=True)#根据ascii来排
# l10 = sorted('14534534',reverse=True)#数字也可以排
# l11 = sorted((1,2,3,4,),reverse=True)#元组
# l12 = sorted({43,22,64,6,5,6},reverse=True)#集合也可以排
# l13 = sorted({'a':1,'b':2},reverse=True)#对字典排序,只是对key进行排序
# #如果传一个字典,那就是对字典的key进行排序
# #那怎么对字典key和value进行排序,转成二维数组,可以随意对哪个元素排序都可以
# d = {'a':1,'b':2}
# l14 = sorted(d.items(),reverse=True,key=lambda x:x[0])
# l14 = sorted(d.items(),reverse=True,key=lambda x:x[1])
# print(dict(l14))#转回字典
# def filter_test(x):#过滤
# return x>5
#
# # result = filter(lambda x: x>5,[2,3,5,7,8,9,])
# result = filter(filter_test,[2,3,5,7,8,9,])
# #filter是用来过滤数据的,按照某一个规则过滤元素
# #lambda是用来保存true的数据
# #filter_test也是循环,把list里面每个元素传给这个函数,第一个数字2>5吗?
# #不大于返回的是false,不保存 ,大于返回的是true,保留
# #filter函数的第一个元素也是传的函数名,filter会自动循环元素里的每一个元素
# #传给filter_test,根据返回值true或者是false,来过滤掉
# #跟上面的lambda是一样的,循环返回值传给X ,X在进行比较是否大于5,大于保留
# print(list(result))#转成lsit
#
#区别
#filter是过滤参数
#map是保留返回值
# def filter_test(x):#过滤
# return x>5
# #map保存的是每一次调用函数的返回值 true 或者false
#
# #map方式实现
# result = map(lambda x: x>5,[2,3,5,7,8,9,])
# print(list(result))#转成list
# result1 = map(lambda x: str(x).strip().zfill(3),[2,3,5,7,8,9,])
# print(list(result1))#转成list
#
# #传统方式实现
# l = [2,3,5,7,8,9,]
# l2 = []
# for i in l:
# new_i = str(i).strip().zfill(3)
# l2.append(new_i)
# print(l2)
#
# #列表生成式也能实现
#
# l3 = [str(i).strip().zfill(3)for i in l]
# print(l3)
#枚举函数:想同时输出下标
# l4 = [1,24,6,6,866,3,3]
# index = 0
# for i in l4:
# print('%s--%s'%(index,i))
# index+=1
#enumerate会自动帮你循环下标,取两个元素,第一个是下标,第二个是元素
# for index,i in enumerate(l4):#其实就是生成1个二维数组
# for index, i in enumerate(l4,1):#指定下标下开始 :不传从0开始,传级就从几开始
# print('%s...%s' % (index, i))
#exec 运行合法的代码
str_code = '''
l = [1,24,6,6,866,3,3]
print([str(i).strip().zfill(3) for i in l])
print('哈哈哈')
'''
#os.remove('/*.*')#当前目录下所有的东西都删掉了 加上/根目录下都删掉
if 'import os'in str_code:
print('os模块不能用')
exec(str_code)
# str_code =''' #死循环
# while True:
# open('%s'$count,'w')
# count+=1
# '''
#执行简单的代码,数据类型和运算
result = eval('1+1')
result1 = eval('{"code":1,"name":"xiaohei"}')
#字符串通过eval执行后,变为字典{'code': 1, 'name': 'xiaohei'}
print(result1)
#也是一个函数,是一个简单的函数,没有名字,只能实现一些简单的功能
lambda x:x+1 #:钱是入参 :后是返回值
f1 = lambda x,y:x+y #可以有多个参数
def f2(x):#f1和f2是一样的
return x+1
print(f2(1))
print(f1(1,2))
#从当前目录里面找
#从python环境变量里面找
import sys #查找环境变量,把python文件放入下方任意目录下, 均可以导入
print(sys.path)
sys.path.append(r)
#导入python文件执行文件 ,用import 和 from是没有问题的
# 导入目录 ,只能用from这种形式
# import 一个文件夹的时候,就是执行这个文件夹下面的__init__.py
# import sys
import day05
# # result = day05.tools.test('5')#会报错
#
# from day05 import tools#这种方式没问题,#从目录下找到py文件
# result = tools.test('5')
#
# from day05.tools import test#这种方式没问题,导入day5目录下的py文件
# result = test('5')#从py文件中找到这函数
#
result = day05.tools.test('')
print(result)
递归:
#函数 自己调用自己,就是递归,递归最大次数999
# count = 1
# def xiake():
# global count
# print(count)
# print('下课')
# count+=1
# xiake()
# xiake()
def enter():#递归效率没有循环高
choice = input('请输入:1登录,2注册 ,3后台管理')
if choice not in ['1','2','3']:
print('输入有误')
enter()
else:
print('登录')
enter()
#函数名即变量名
安装第三方模块:
傻瓜式
在cmd命令行中,使用pip install 模块名,模块名可通过搜索获得,选择带有pypi的标识网址
实例1:

|
1
2
|
pip install redis
#安装redis模块
|
返回结果:
|
1
2
|
Requirement already satisfied: redis
in
c:\users\
13457
\appdata\local\programs\python\python38\lib\site
-
packages (
3.5
.
0
)
#表明模块已安装好
|
二、官网上下载安装包
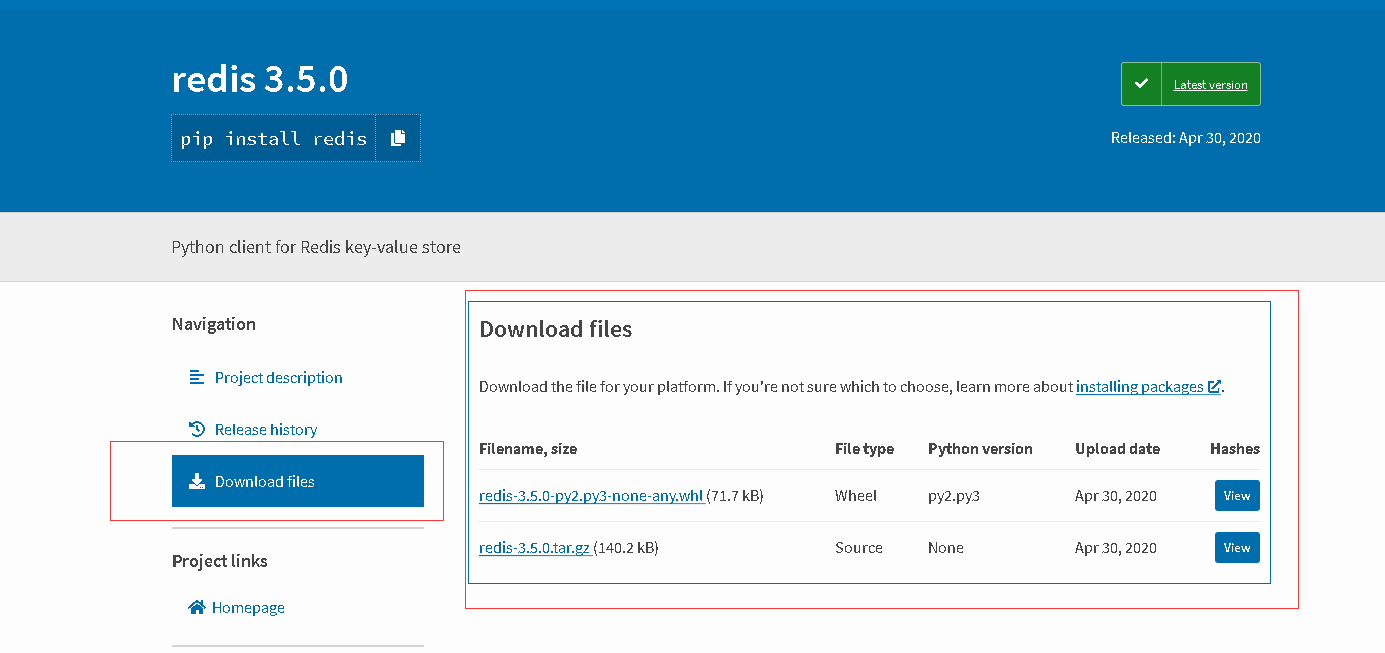
1、首先打开Pypi网址,搜索需要安装的模块,比如redis,点击download files
扫描二维码关注公众号,回复:
11199979 查看本文章

2、下载whl格式的安装包
使用pip install 文件所在的路径
例如:
pip install /Users/nhy/Downloads/PyMySQL-0.9.3-py2.py3-none-any.whl
3、下载tar.gz格式的安装包
1、先将tar解压
2、进入解压目录,找到setup.py文件
3、cmd 命令行执行命令 : python setup.py install
注意:建议使用pip 安装和whl安装,tar容易在解压时出错