目录
1、定义
在我们日常编程中, 使用正则表达式最多的地方就是对账户密码字符的限定了,还有就是在一个文本中查找指定的子字符串。

我们的正则表达式由3种基本操作和作为操作数的字符组成。
1.1、连接操作
我们普通的所有字符串就是连接操作,就比如字符串“ABC” ,A和B和C是相连的并且他们的顺序是确定的,如果你要在一个文本中查找这个字符串,就必须按照它的连接顺序来对比查找。
1.2、或操作
或操作其实就是用我们的或运算符(“|”)来指定的。就比如 “A|BC” 指的是“A” 或者 “BC” 两个子字符串。连接操作优先级高于或操作。
或操作还能用其他记号来扩展。
1、比如“·” 一个点就是表示任意字符的通配符。
2、“[]” 方括号括中的字符,表示你可以拿其中的任何一个字符。
3、如果在方括号中以“^”记号开头,那表示的意思是除了括号中的字符不行,其他字符都可以。

1.3、闭包操作
闭包基本操作可以将模式的部分重复任意的次数。 用(“*”)来标记闭包操作。例如“A*B”就表示0个或者多个A和一个B组成的字符。“ABC*”表示一个AB和0或多个C组成的字符串。
如果你想控制字符的复制次数,可以用以下记号:
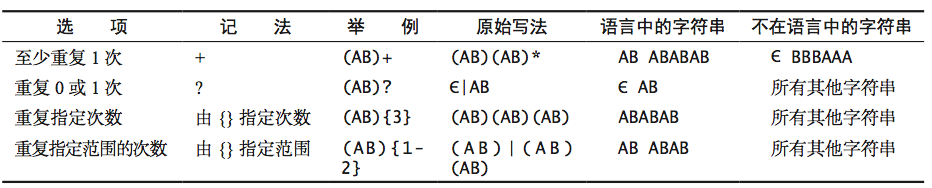
1.4、准确定义
一个正则表达式可以是:
- 空字符串 Є;
- 单个字符;
- 包含在括号中的另一个正则表达式;
- 两个或多个连接起来的正则表达式;
- 由或运算符分隔的两个或多个正则表达式; 由闭包运算符标记的一个正则表达式。
2、特殊记号
2.1、空字符串
空字符串的记号是“Є”。它存 在于所有文本字符串之中(包括 A*)。
2.2、括号
我们使用括号来改变默认的优先级顺序。例如,C(AC|B)D 指定的语言是 {CACD,CBD},(A|C) ((B|C)D) 指定的语言是 {ABD,CBD,ACD,CCD},(AB)* 指定的语言是由将 AB 连接任意多次得到的 所有字符串和空字符串组成的 {Є,AB,ABAB,...}

2.3、转义字符
我们用“\" 反斜杠来将特殊字符转换成字符本身。就比如“\\”就表示一个"\"。还有一些特殊的转义字符。

3、Java实例
在Java中,我们只要写好正则表达式利用内带的Pattern函数我们就能实现。
public static void main(String[] args) {
/**
* 1、子字符串的查找匹配
*/
String pat = ".*NEEDLE.*";
String txt = "A HAYSTACK NEEDLE IN";
// 方式1:String 的 matches 方法
boolean isHas1 = txt.matches(pat);
// 方式2:Pattern 对象的 matches 方法
boolean isHas2 = Pattern.matches(pat, txt);
// 方式3: Matcher 对象的 matches 方法
Pattern p = Pattern.compile(pat);
Matcher m = p.matcher(txt);
boolean isHas3 = m.matches();
System.out.println("txt中是否含有pat1=" + isHas1);
System.out.println("txt中是否含有pat2=" + isHas2);
System.out.println("txt中是否含有pat3=" + isHas3);
/**
* 账号密码的匹配
*/
String pat1 = "[0-9]*";
String txt1="1491984910";
String txt2="8998aba";
Pattern p1=Pattern.compile(pat1);
Matcher m1 = p1.matcher(txt1);
Matcher m2 = p1.matcher(txt2);
System.out.println("txt1文本是否符合pat1要求的字符="+m1.matches());
System.out.println("txt2文本是否符合pat1要求的字符="+m2.matches());
}4、正则表达式匹配算法
Digraph----算法-19-有向图(拓扑排序+最短路径)
Stack---算法-2-下压栈(能够自动调整数组大小)
public class NFA {
private Digraph graph; // digraph of epsilon transitions
private String regexp; // regular expression
private final int m; // number of characters in regular expression
/**
* Initializes the NFA from the specified regular expression.
*
* @param regexp the regular expression
*/
public NFA(String regexp) {
this.regexp = regexp;
m = regexp.length();
Stack<Integer> ops = new Stack<Integer>();
graph = new Digraph(m+1);
for (int i = 0; i < m; i++) {
int lp = i;
if (regexp.charAt(i) == '(' || regexp.charAt(i) == '|')
ops.push(i);
else if (regexp.charAt(i) == ')') {
int or = ops.pop();
// 2-way or operator
if (regexp.charAt(or) == '|') {
lp = ops.pop();
graph.addEdge(lp, or+1);
graph.addEdge(or, i);
}
else if (regexp.charAt(or) == '(')
lp = or;
else assert false;
}
// closure operator (uses 1-character lookahead)
if (i < m-1 && regexp.charAt(i+1) == '*') {
graph.addEdge(lp, i+1);
graph.addEdge(i+1, lp);
}
if (regexp.charAt(i) == '(' || regexp.charAt(i) == '*' || regexp.charAt(i) == ')')
graph.addEdge(i, i+1);
}
if (ops.size() != 0)
throw new IllegalArgumentException("Invalid regular expression");
}
/**
* Returns true if the text is matched by the regular expression.
*
* @param txt the text
* @return {@code true} if the text is matched by the regular expression,
* {@code false} otherwise
*/
public boolean recognizes(String txt) {
DirectedDFS dfs = new DirectedDFS(graph, 0);
Bag<Integer> pc = new Bag<Integer>();
for (int v = 0; v < graph.V(); v++)
if (dfs.marked(v)) pc.add(v);
// Compute possible NFA states for txt[i+1]
for (int i = 0; i < txt.length(); i++) {
if (txt.charAt(i) == '*' || txt.charAt(i) == '|' || txt.charAt(i) == '(' || txt.charAt(i) == ')')
throw new IllegalArgumentException("text contains the metacharacter '" + txt.charAt(i) + "'");
Bag<Integer> match = new Bag<Integer>();
for (int v : pc) {
if (v == m) continue;
if ((regexp.charAt(v) == txt.charAt(i)) || regexp.charAt(v) == '.')
match.add(v+1);
}
dfs = new DirectedDFS(graph, match);
pc = new Bag<Integer>();
for (int v = 0; v < graph.V(); v++)
if (dfs.marked(v)) pc.add(v);
// optimization if no states reachable
if (pc.size() == 0) return false;
}
// check for accept state
for (int v : pc)
if (v == m) return true;
return false;
}
}