引言
本文代码已提交至Github,有兴趣的同学可以下载来看看:https://github.com/ylw-github/taodong-shop
在前面的博客,主要是讲解了在Docker下搭建ELK,以及实现搜索功能,有兴趣的同学可以看下:
在本文,主要讲解ELK的另外一种用途,即当前主流的分布式日志采集系统(ELK+Kafka)的原理。
本文目录结构:
l____引言
l____ 1. 为什么选ELK+Kafa作为分布式日志采集系统?
l____2. ELK+Kafka日志收集原理
1. 为什么选ELK+Kafa作为分布式日志采集系统?
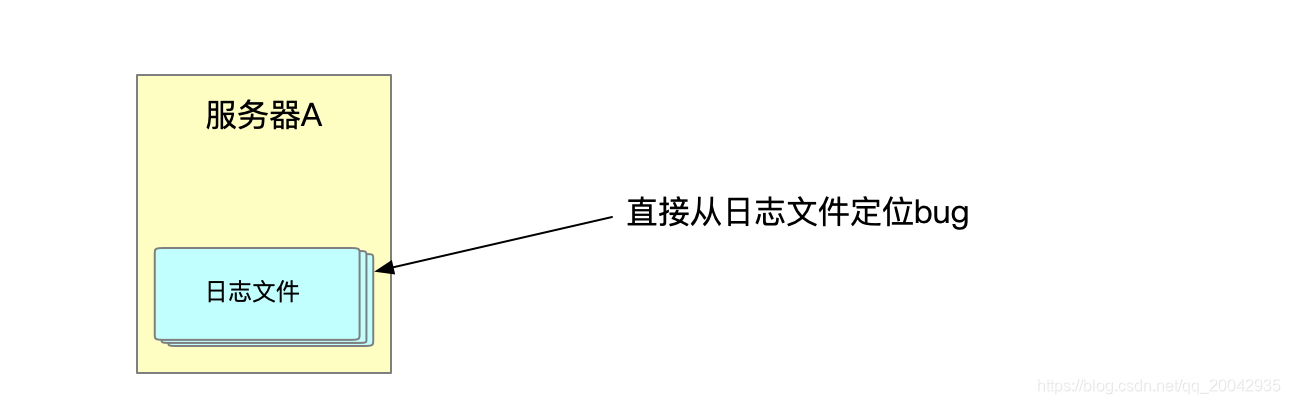
在以往的传统单体系统中,我们通常都是把日志记录在文件里,如果出现了bug是直接找日志文件定位问题,如下图:
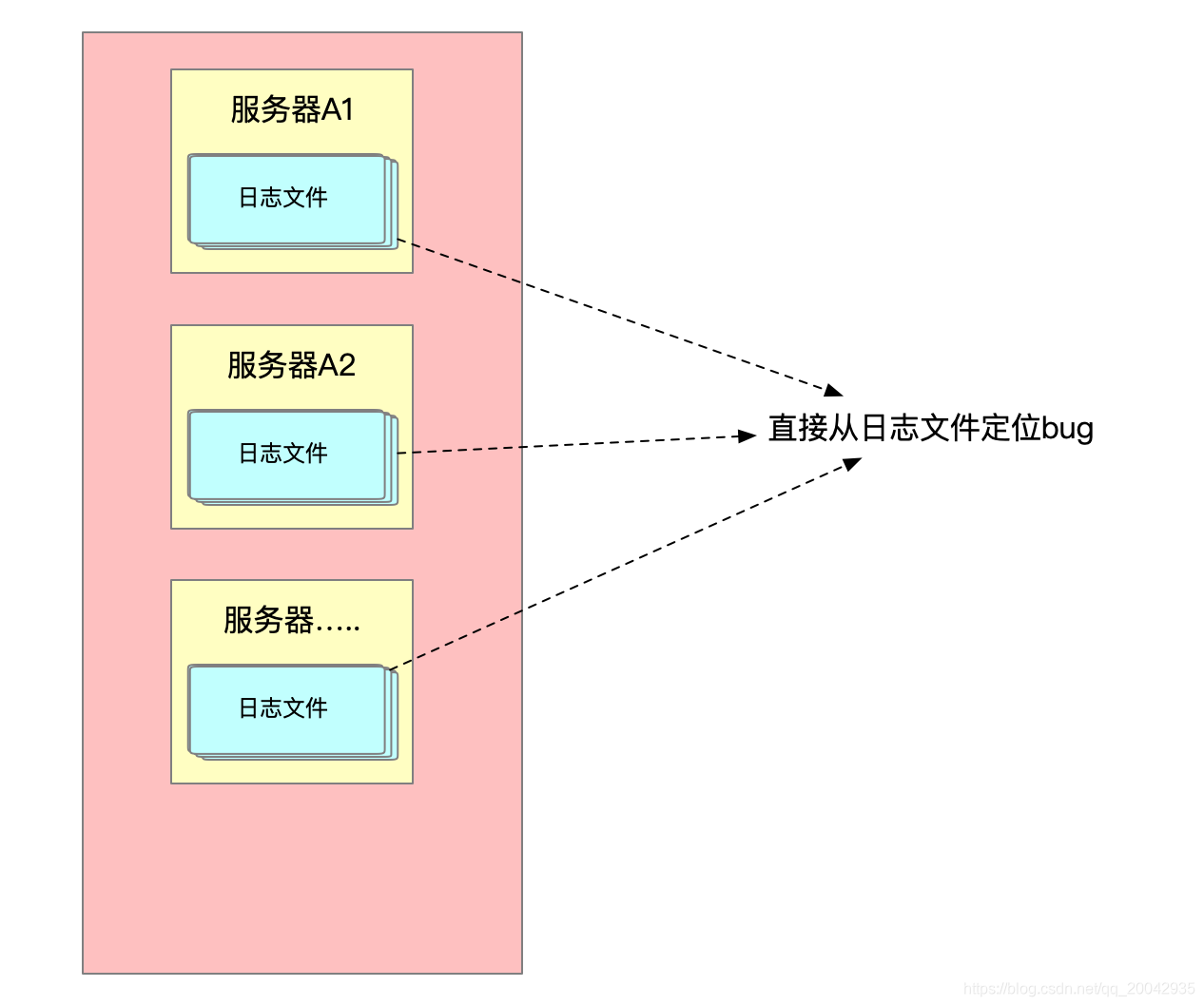
但是随着用户量的增大,不得不弄集群了,如果出现了bug,不得不去查询每一台机器的日志文件:
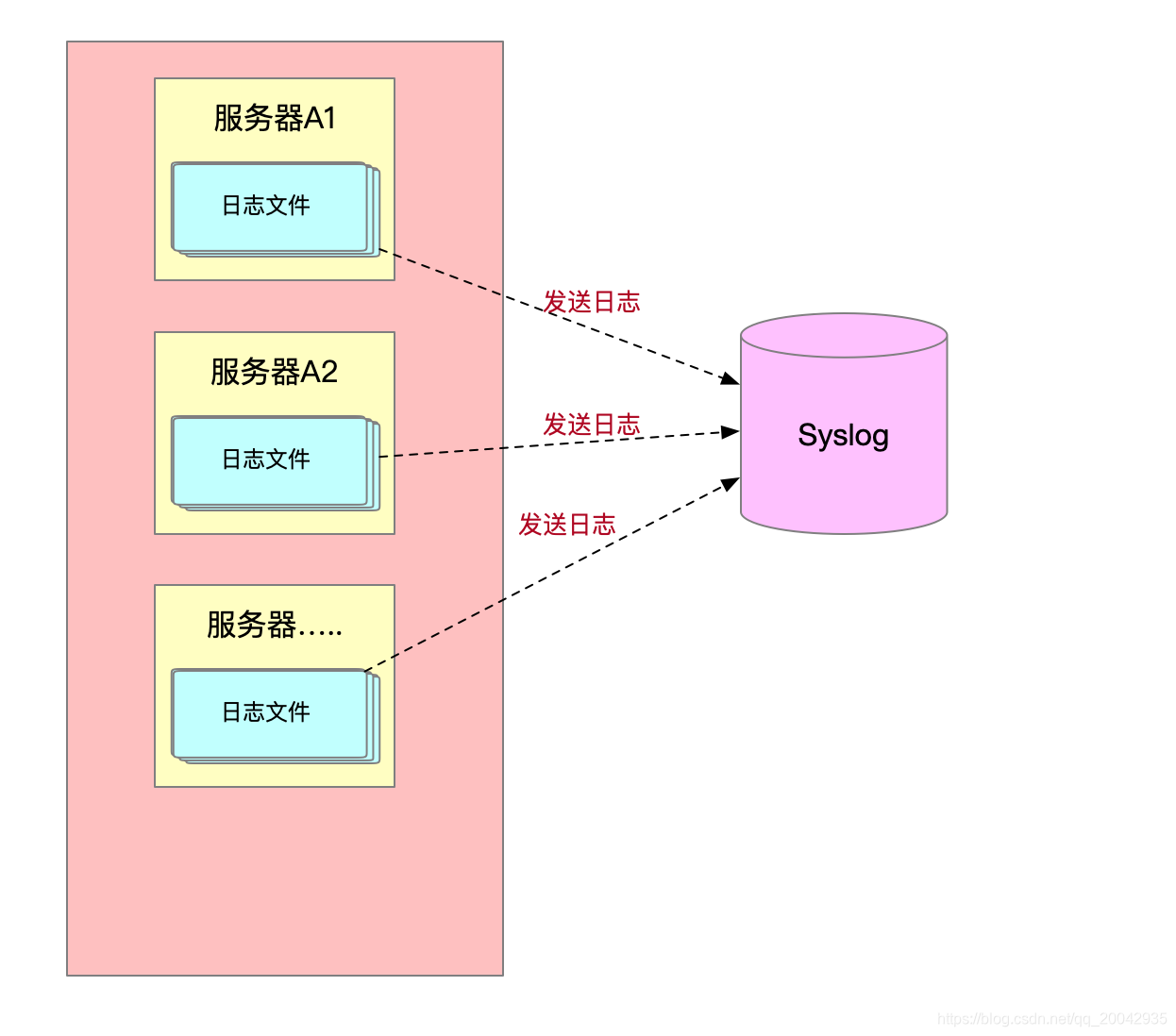
这时候,有什么解决方方案了,为了统一日志管理,出现了很多的日志统一管理工具,例如:syslog,主要是汇总收集日志。
虽然Syslog可以收集到日志,但是还是有缺陷的,比如需要去查询日志我们不得不使用命令去查询,还有我们想要统计和排序日志并以图形化的形式显示,Syslog的功能是做不到的。到这里我们很容易想到使用ELK(elasticsearch+logstash+kibana)的方式实现,如下图:
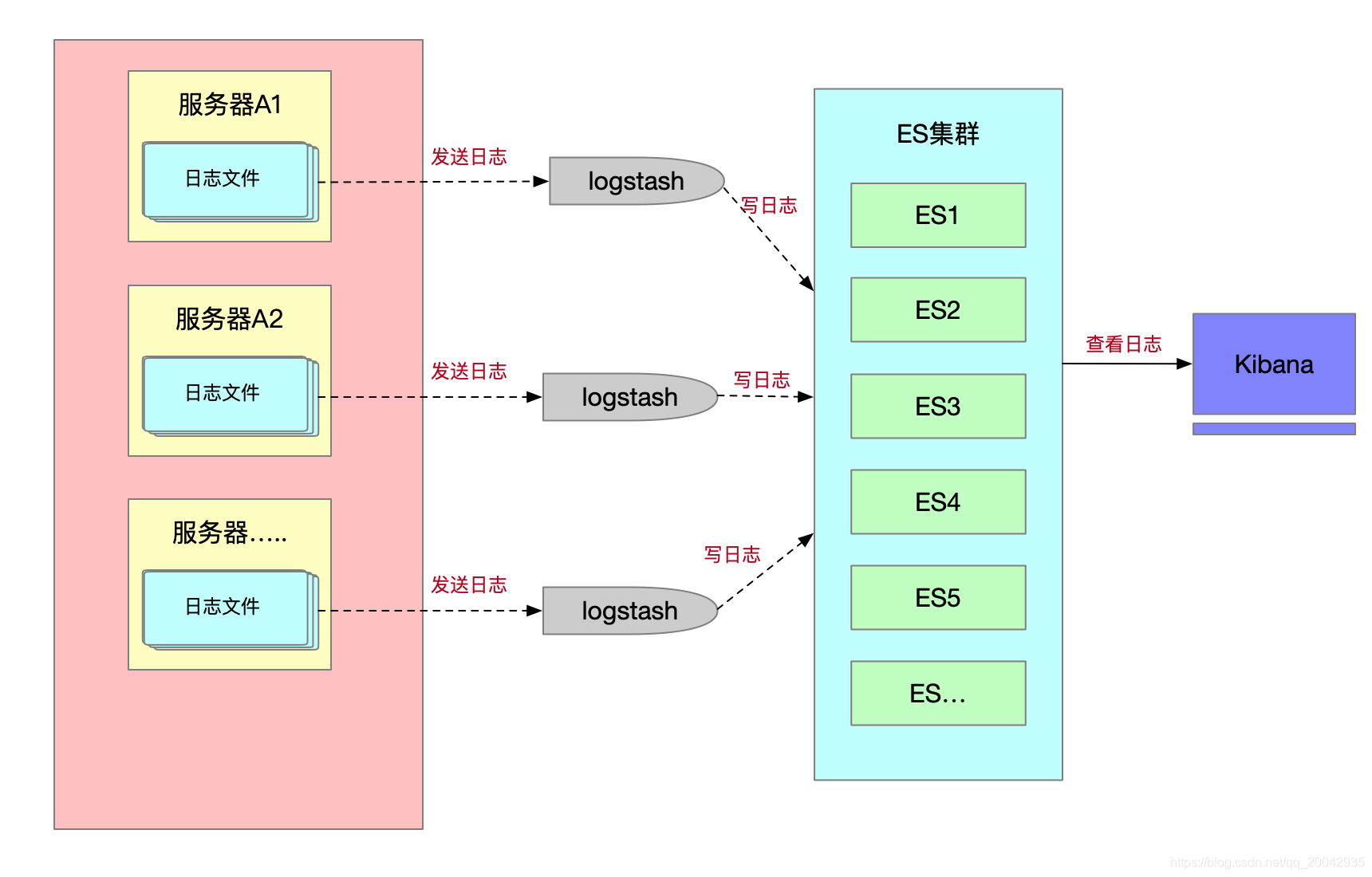
从上图,我们基本满足日志采集的需求了,可以通过kibana来实现图形化的查看。但是,细心的同学肯定还会注意到,每一个服务器都要绑定一个logstash,这样也是不合理的,那么该如何解决呢?
解决方案就是接下来要讲解的ELK+Kafka日志收集的原理了。
2. ELK+Kafka日志收集原理
直接上原理图:
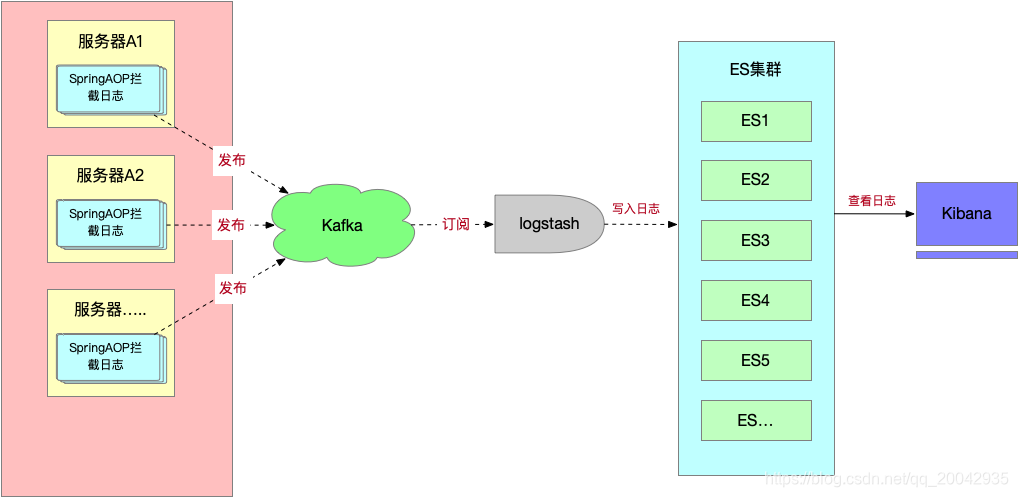
原理分析:从上图可以看到,首先每个应用程序使用的是Spring AOP技术来拦截日志,获取到日志之后,发布到Kafka,Kafka会推送消息给订阅者,logstash作为消息的订阅者会接收到日志信息,然后logstash会把日志写入到ES,通过Kibana我们可以可视化的实时查看日志信息,并可以以数据图标的形式展现。
我们来看下每个角色的职责:
| Kafka | Logstash | elasticsearh | kibana |
|---|---|---|---|
| 用来实时接收日志和发送日志到logstash,解耦和流量削峰 | logstash做日志对接,接收来自应用系统的log,然后将其写入到elasticsearch中。logstash可以支持N种log渠道,kafka渠道写进来的、和log目录对接的方式、也可以对reids中的log数据进行监控读取,等等。 | elasticsearch存储日志数据,方便的扩展特效,可以存储足够多的日志数据。 | kibana则是对存放在elasticsearch中的log数据进行:数据展现、报表展现,并且是实时的。 |
为什么要选择Kafka,而不选择其它的MQ,比如RabbitMQ和ActiveMQ呢?主要是Kafka具有以下的几个优点(下面的优点是从网上查找整理的):
- 可扩展:Kafka集群可以透明的扩展,增加新的服务器进集群。
- 高性能:Kafka性能远超过传统的ActiveMQ、RabbitMQ等,Kafka支持Batch操作。
- 容错性:Kafka每个Partition数据会复制到几台服务器,当某个Broker失效时,Zookeeper将通知生产者和消费者从而使用其他的Broker。
- 高吞吐量:keep big data in mind,kafka采用普通的硬件支持每秒百万级别的吞吐量。
- 分布式:明确支持消息的分区,通过kafka服务器和消费者机器的集群分布式消费,维持每一个分区是有序的。
- 持续的消息:为了从大数据中派生出有用的数据,任何数据的丢失都会影响生成的结果,kafka提供了一个复杂度为O(1)的磁盘结构存储数据,即使是对于TB级别的数据都是提供了一个常量时间性能。
讲到这里,相信大家都知道为什么分布式采集系统要使用ELK,而且为什么要选择Kafka作为MQ中间件了。
本文完!
