上一篇我们学习了server层对于表对象缓存的处理,表对象获取到之后,通过handler才具备了与存储引擎交互的能力。那么存储引擎层又是怎么个流程呢?
mysql文件结构

这些文件都可以在文件目录中找到,我们来看看都是做什么的。
my.cnf,大家都懂。
slow.log,记录慢查询日志,当语句执行时间超过参数long_query_time的值时,会被记录到该log,需要开启配置后才有。
error.log,记录错误和警告信息。
general.log,记录所有在数据库上执行的语句,可以用来追踪问题,文件增长很快,也很大,一般不会打开,偶尔要调试时可以打开。
系统默认库有4个,具体是干什么的自行查询,做过元数据的应该比较熟悉,有一些框架就是根据元数据来完成的,譬如eova。没做过也不要紧,大概理解为存储系统信息的,譬如你的表名、列名、列属性等等。
innodb文件结构
大图里面黑框里的就是innodb的东西了。
有两个默认的日志文件,logfile0和logfile1,大小可以手工设定。
如果你创建了一个数据库userdb,并且创建了几个表,你可以在数据目录看一下。

每个表会对应一个frm文件,一个ibd文件。frm文件是表结构,ibd是数据。如果你想让两个表共用一个数据文件的话,就像最上面图中那样t2、t3共用一个ibdata,可以通过innodb_file_per_table控制。还有一个db.opt文件,这个存储的是mysql的一些配置信息,如编码、排序的信息,如果在创建数据库时指定了一些非默认参数的话,也会存到该文件。
这里,我们要讲一个知识点了,ibd文件。
上面说了,ibd就是存表数据的,那么在计算机里,所有的存储都是有最小存储单元的。在磁盘上,最小的单元是扇区,一个扇区是512字节,操作系统中最小单元是块(block),最小单位是4K,而innodb也有自己的最小存储单元——页(page),一页是16K。
这意味着什么呢,你一个文件放到电脑上,哪怕它是空的,也要占用4K,它占用的空间永远是4K的整数倍。
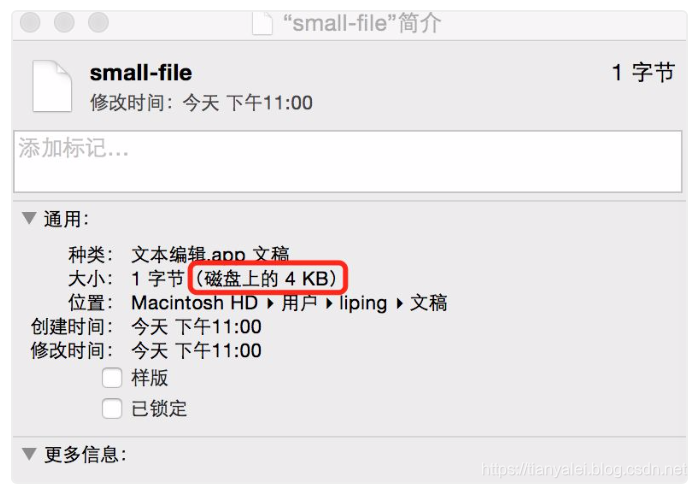

你可以去查看每个ibd文件的大小,它永远是16384(16k)的整数倍。
这个希望记好了,它对将来理解索引已经加载表数据都是非常有用的。形成一个基本概念,mysql的数据最小是16K,也就是哪怕你只取一条,可能还不到1K,那么mysql也会取出16K的数据。因为“页”是最小单位。“页”还决定了b+ tree在某个高度下,能存放的数据量,学完后就能明白为什么一个表存2万数据,和存1500万数据,查询速度一样。大家可以看我这一篇,来更深入理解一下《 InnoDB一棵B+树可以存放多少行数据?》
innodb体系结构

innodb的体系结构还是比较清晰的,做为一个支持事务、索引、异常恢复及性能优异的数据引擎,靠的就是上面的体系架构。
目前我们已经知道的就是Handler API是供mysql server层调用的,server层定义了一些接口,譬如insert、delete,具体怎么实现,是由每个存储引擎自己实现的。其他的,刚学了ibd文件是存数据的。其他的,后面慢慢学。
简单说明
以上图中间虚线为分界,上面的是逻辑层,每个访问都会产生事务,事务处理会产生锁(表锁、行锁),操作对象是表、索引、b+ tree。对数据页面的访问需要物理事务,为了读写一致性,需要读写锁(物理锁)。为了高效定位和管理“页”,需要用到文件管理系统。
这些都是基于逻辑的处理,再往下就是物理层了。
首先我们知道,在逻辑处理和磁盘文件之间,都是有一层缓存的,这里主要是日志缓冲区和innodb_buffer_pool。和其他大家常用的kafka、elasticsearch、rocksDB等等一样,要保持性能,必然都遵循相同或类似的规则,那就是写pageCache、顺序写磁盘,这是决定任何一个带存储功能的性能的关键点。
请务必记着innodb_buffer_pool,未来能对性能起决定性作用的一个重要因子。要明白,任何时候,决定读写速度的都是内存,只要你要读的数据在内存里,它就比在磁盘上快。redis就是靠内存,mysql的数据缓存,就取决于innodb_buffer_pool。
缓冲层提供了高效的读写性能,再下面就是物理文件层了,是落到磁盘上的。
磁盘上重要的地方有REDO日志,和表数据(页)

 博客专家
博客专家