上一篇,我们学习了innodb文件系统内部大的存储结构,包括段(segment),簇(extent),页(page)各自的含义。
简单回顾一下,段是组成表空间的最大结构,当创建一个表时,会同时创建两个段(内节点段,叶子段),分别管理非叶子节点数据和叶子节点数据。其实还有一个段(回滚段),是存放回滚数据的,只不过回滚段不是放在每个表的表空间,而是放在共享表空间的,希望还能记得共享表空间是什么。
簇,是段的下一级,每个簇固定大小是64个page,共64*16K=1M。为了保证数据存储时,页能尽量保持物理磁盘上的连续性,innodb会一次性申请4-5个簇。
页,最小的存储单位。常见的页类型有数据页、undo页、系统页、事务数据页、插入缓冲位图页、插入缓冲空闲列表页、未压缩的二进制大对象页、压缩的二进制大对象页。
OK,回到B+ tree这里。
B+ tree是如何构成的,里面的数据是怎么存放的呢。
以一个简单的2层b+ tree为例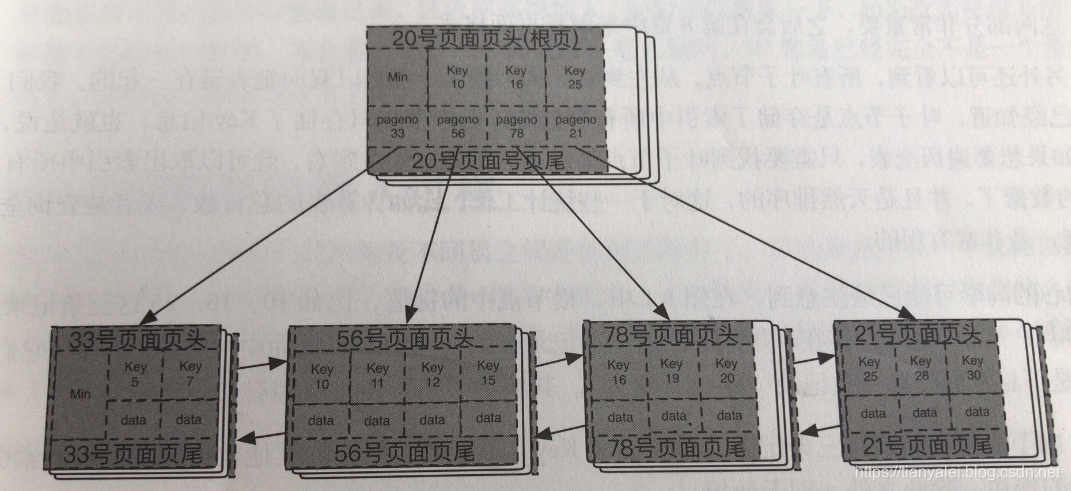
这个树只有2层,首先每个page都有自己的唯一编号,将来就要通过编号来找对应的page。根页做为一个第一层的索引页,里面是不存在叶子数据(行数据)的,只存放Key,同时还包含了pageNo信息,用来将来去找对应的页。
所有的记录节点都是按键值的大小顺序存放在同一层的叶子节点上,由各叶子节点指针进行连接(双向指针)。所以查询时,无论正序倒序,其实是一样的扫描速度。
每一层的最左边节点页面的最左边位置,会有一个Min记录,该记录由2部分组成,第一部分就是一个Min标记,代表这就是 最小值;第二部分是一个pageNo指针,指向下一层中最左边的记录。注意看根页的Min记录,就是这样的。而33号page的Min记录由于没有下一层了,所以没有pageNo指针。
可以看到,上一层的Key,在下一层对应的page中,也会重复存在,譬如Key=10的记录。但是,每个page,只有第一条数据会和上层有重复,其他的不会有重复。
每一个page还会有一个最大记录和最小记录,用来标记该page的边界,便于查询。
由此结构可以看到,做一次查询的耗时,每一层只需要一次内存级的二分查找,定位后就进入下一层,再一次二分查找。
譬如查询Key=11,那么可以定位到56号page,因为11小于78号page的最小值,之后找到56号page,在做一次二分查询。就能找到11。2层只需要2次IO,就能找到一条数据。3层3次,之前已经说过,3层和4层分别能存多少数据,这个查询效率其实是非常高的。
通过这样的方式,我们就知道了一颗树是怎么构成的了。下面来看看具体到每个page内部是怎么存放的。
每个Page内详细结构

这就是一个page内的存储,共16K的空间,要放的所有东西。
分为几个大部分,文件管理头信息、页面头信息、页面尾信息、最小记录最大记录、用户记录、可重用空间、未使用空间、页面槽信息。
从名字就能看出来,用户记录就是行数据,可重用就是曾经被分配过数据后来被删了,未使用就是没分配过的空间。
文件管理头信息:
它占用38个字节,里面存储的东西主要有——
该页面的checkSum信息,校验文件是否被损坏的;
该页面在当前表空间的页面号(pageNo);
当前页面的上一个页面的pageNo;
下一个页面的pageNo;
当前页面最后一次被修改时,对应日志的LSN值,与后面的日志系统有关;
当前页面的类型;
只有第0号页面会存一个LSN值,用来存储当前Innodb引擎最大的被flush的LSN值,将来做checkPoint时用;
标记属于哪个表空间的(避免多个表空间,有相同的pageNo的页)
页面头信息:
这里面存的东西也巨多,挑几个重要的——
槽的个数;
未使用空间的指针;
存储的记录数,包括最大最小记录的管理;
已被删除的记录的链表的首指针;
已被标记删除的记录数;
最后被插入的记录的位置;
当前节点在b+ tree处于第几层,叶子就是0,往上就加1;
页面尾部:
这8个字节还是用来做完整性校验的。
页面重组
一个页面会频繁的插入删除,在插入过程中,都会去已经删除的可重用链表去找合适的空间,如果放得下,就会放进去,放不下,另寻空间。时间一长,就会有空间碎片产出,譬如累计的空闲空间还有很多呢,但就是找不到能放下一条新数据的合适空间。
那么带来的问题很明显,page增加,每个page存储数据量下降,磁盘占用很大,但存的数据并不多,IO数增加,性能下降。
如果是一张表的话,如果大量数据被删,就需要及时处理回收空间,可以通过一个空的alter命令,如alter table tablename engine innodb,就可以将表的空间给回收重组了。
对于页面也一样,在数据库向某一个页面插入时,如果找不到大小合适的空间,就会做一次页面重组操作。重组的方式是,新建一个buffer pool页面,然后将老页面的数据一条一条插入到新页面,插入完成后,将老页面空间释放掉,再修改指针位置,指向新页面。
Innodb索引插入和删除
这个有点复杂,主要是树的节点分裂、迁移,扩容等操作。好比Hashmap一样,空间不够时,就扩容,但b+ tree是有序的,每次插入都要保持严格的顺序,就会比普通的扩容多一些排序查找的操作。
细节我就不想写了,可以去网上搜一搜。
删除相对简单一些,只有当一个page里完全没有数据了,才会将整个page从b+ tree里删掉。细节不谈。
下一篇就要进入缓存层,对性能起决定性影响的因素,和增删改查时,Innodb所做的内存处理。

 博客专家
博客专家