原标题:运用Python爬虫下载熊猫办公上面的视频模板和音效
1.怎样实现
1.1 需要的模块
requests(urllib亦可)、bs4、os、time、sys
前两个模块都需要额外安装,后面模块是Python自带的,我们按住win+R,在弹出来的窗口中输入cmd,来到命令窗口,输入下面语句即可安装
requests: pip install requests
bs4:pip install bs4
如果在运行小编的代码的时候出现如下报错

建议安装lxml :pip install lxml,就不会出现错误了。
1.2 实现
我们来到这个网址:
https://www.tukuppt.com/videomuban/xuexi.html
这就是视频模板的界面,我输入的是有关 学习 类型的视频模板,这个网址其实有两部分组成的,第一就是模板类型,在这个网址中是 videomuban,另一部分是 xuexi 在这里是这个模板下面的类型。
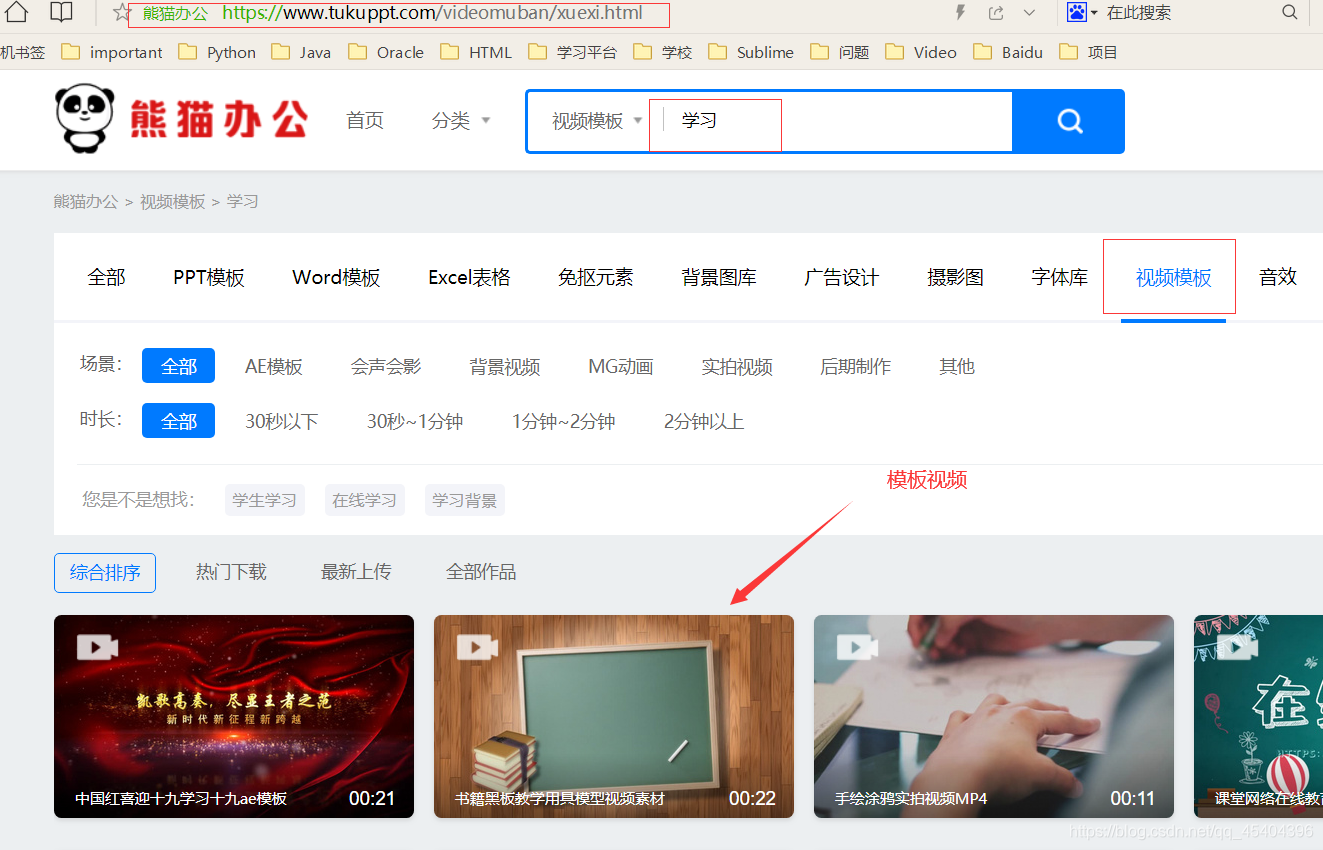
我们要做的就是下载这个网址下面的视频,通过按电脑键盘F12来到开发者工具,可以发现这些视频下载链接都在这个div.b-box标签下面:
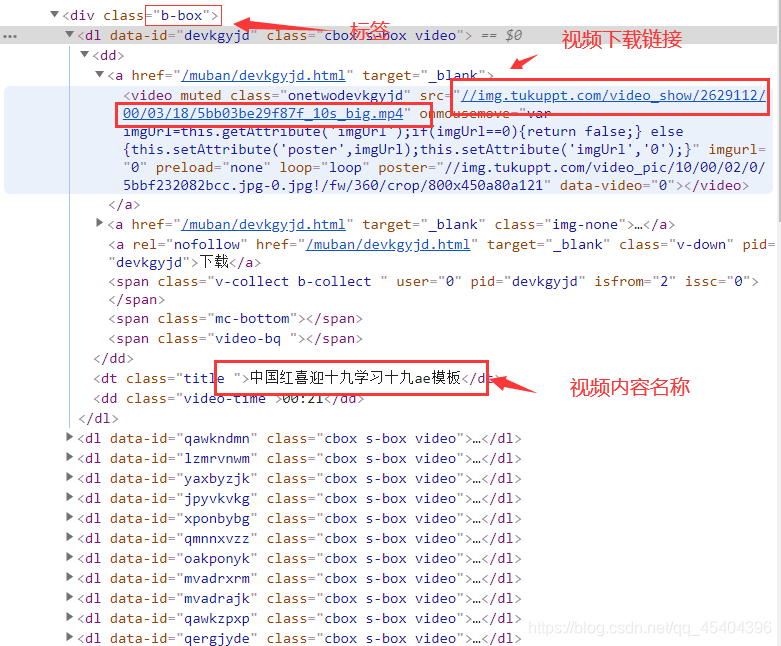
我们只需得到这个标签下面的内容即可。
代码实现:
def get_video(name):
url='https://www.tukuppt.com/videomuban/%s.html'%name
responce=requests.get(url=url)
soup=BeautifulSoup(responce.text,'lxml')
list1=soup.select('div.b-box>dl') # 列表
list2=[] # 用于存储视频链接的列表
list3=[]
for i in range(len(list1)):
str1='http:'+list1[i].select('dd>a>video')[0]['src'] # 一个视频的下载链接
list2.append(str1)
str2=list1[i].select('dt.title')[0].get_text() # 视频的名称
list3.append(str2)
print('->【{}】----{}'.format(i+1,str2))
str_id=input('------>请输入你想下载的视频序号(可输入一连串序号,中将用","隔开):')
id=[int(i) for i in str_id.split(',')]
for i in id:
cb=requests.get(url=list2[i-1]).content # 用来得到视频的二进制文件 c content b 二进制
with open(file='./{}/{}.mp4'.format(name,list3[i-1]),mode='wb') as f:
f.write(cb)
Time_1()
print('--->一下载{}.mp4完毕!'.format(list3[i - 1]))
这是一个自定义的方法,传入的参数就是自己输入的名称,在这里就是上面 输入的 xuexi(学习)
,这里面有一个Time_1()方法,是用来显示进度条的。
Time_1()方法:
def Time_1(): # 进度条函数
for i in range(1,101):
sys.stdout.write('\r')
sys.stdout.write('{0}%|{1}{2}'.format(i,int((i%101)/2)*'-','>'))
sys.stdout.flush()
time.sleep(0.05)
sys.stdout.write('\n')
下载音效吗?跟上面的过程一样,我就不详细讲了,
实现代码:
def get_yin(name1):
url='https://www.tukuppt.com/yinxiaomuban/%s.shtml'%name1
responce=requests.get(url=url).text
soup=BeautifulSoup(responce,'lxml')
list1=soup.select('div.b-box>dl')
list2=[]
list3=[]
for i in range(len(list1)):
url='http:'+list1[i].select('audio>source')[0]['src'] # 音频下载链接
name=list1[i].select('dt>a')[0].get_text()
list2.append(url)
list3.append(name)
print('--->【{}】-{}'.format(i+1,name))
str_id = input('------>请输入你想下载的视频序号(可输入一连串序号,中将用","隔开):')
id = [int(i) for i in str_id.split(',')]
for i in id:
cb = requests.get(url=list2[i - 1]).content # 用来得到视频的二进制文件 c content b 二进制
with open(file='./{}/{}.mp3'.format(name1,list3[i - 1]), mode='wb') as f:
f.write(cb)
Time_1()
print('--->一下载{}.mp3完毕!'.format(list3[i - 1]))
另外,在这个了我还定义了一个方法,主要用来创建文件的
def get_name():
name=input('请输入你想下载模板的名称(拼音):')
try:
os.mkdir('./{}'.format(name))
except:
sys.exit() # 如果程序出错,直接退出程序
return name
不过这里输入的要是拼音,切记!
2.最终代码
完整我已经上传到github,l链接为:ppt.py
运行结果:
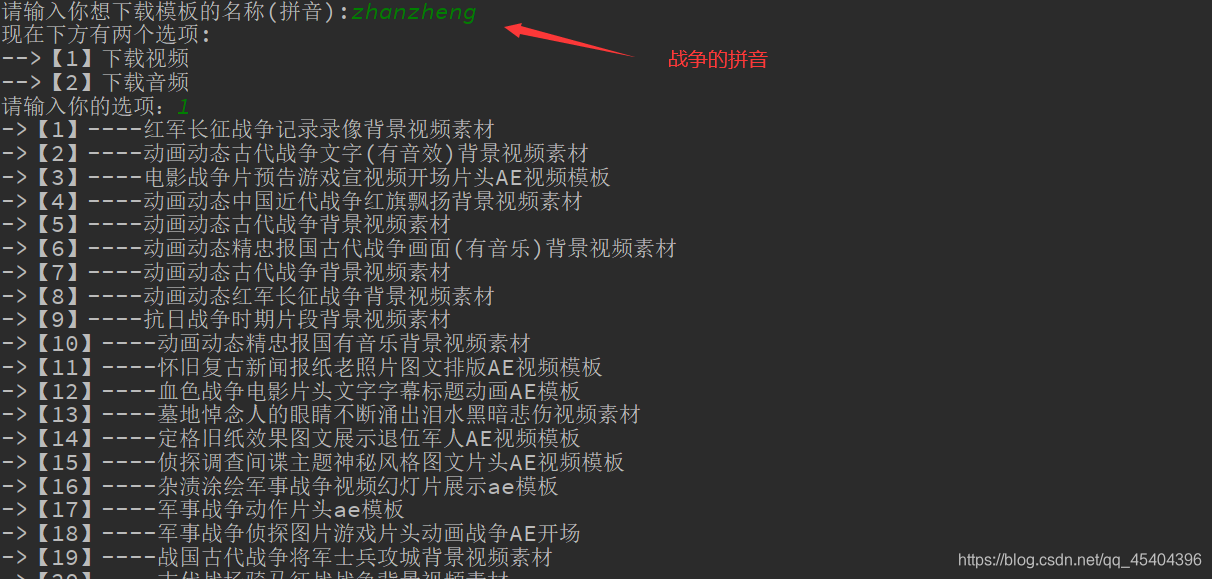
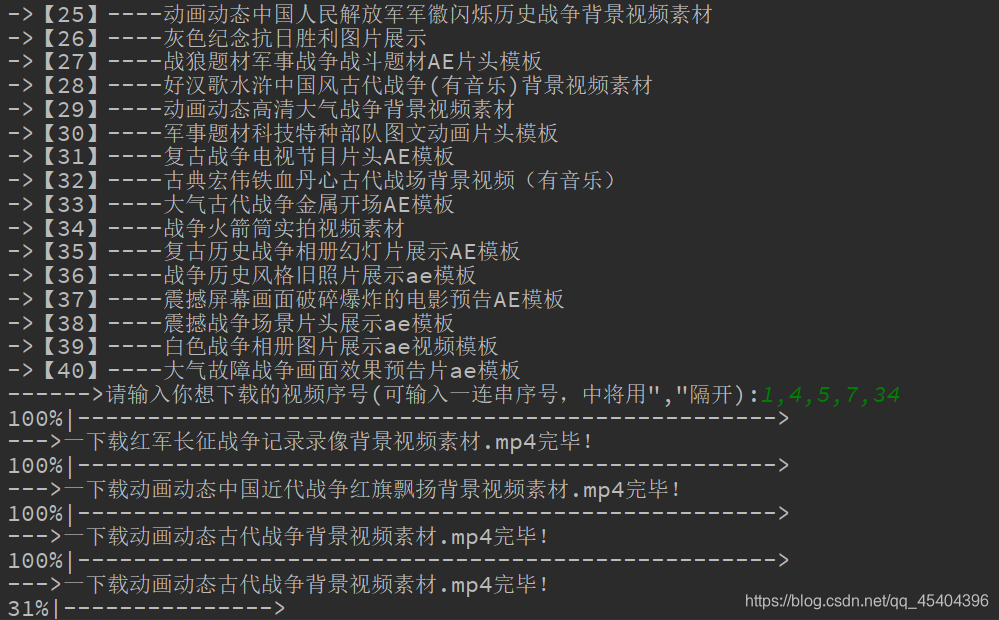
下载完成之后,会在同一个文件夹下面多出文件夹,所下载的内容就在这个文件夹下面,
如:
3.总结
这个项目比较简单,希望那些python小白们能看懂,如果觉得可以,记得给我点一个小小的赞,我会更加努力地推出新的博文的。
