前两天,有个小伙伴问了黑马哥这样一个问题:Python可以爬到视频网站上vip才能看到的视频吗?听到这个问题,你是什么反应?我当时的内心:开玩笑,还有Python爬不到的东西吗?
今天黑马哥就给大家总结了一些Python爬取各种东西的案例,让你看看Python到底有多强大,而且黑马哥还给大家准备了源码或者是项目地址哦,是不是对我的爱又多了几分。
既然要在网络上爬取资源,首先要了解下基本的爬虫工作原理。
爬虫是怎么工作的?
想象你是一只蜘蛛,现在你被放到了互联“网”上。那么,你需要把所有的网页都看一遍。怎么办呢?没问题呀,你就随便从某个地方开始,比如说人民日报的首页,这个叫initial pages,用$表示吧。
在人民日报的首页,你看到那个页面引向的各种链接。于是你很开心地从爬到了“国内新闻”那个页面。太好了,这样你就已经爬完了俩页面(首页和国内新闻)!暂且不用管爬下来的页面怎么处理的,你就想象你把这个页面完完整整抄成了个html放到了你身上。
突然你发现, 在国内新闻这个页面上,有一个链接链回“首页”。作为一只聪明的蜘蛛,你肯定知道你不用爬回去的吧,因为你已经看过了啊。所以,你需要用你的脑子,存下你已经看过的页面地址。这样,每次看到一个可能需要爬的新链接,你就先查查你脑子里是不是已经去过这个页面地址。如果去过,那就别去了。
- 理论上如果所有的页面可以从initial page达到的话,那么可以证明你一定可以爬完所有的网页。
- 基本的http抓取工具,scrapy
- 如果需要大规模网页抓取,你需要学习分布式爬虫的概念。
- rq和Scrapy的结合:darkrho/scrapy-redis · GitHub
- 后续处理,网页析取 ( grangier/python-goose · GitHub),存储(Mongodb)
今天的福利时刻
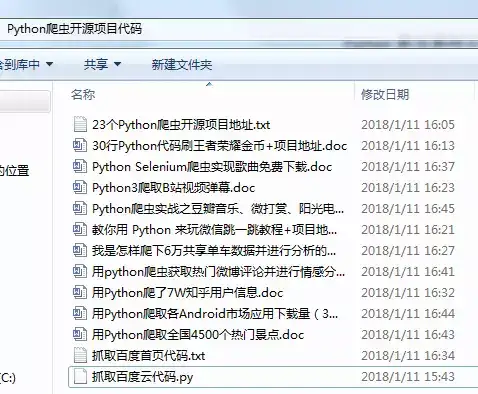
35个项目实战:链接:https://pan.baidu.com/s/1htA3p3I 密码:pt3r
黑马哥还给大家准备了Python的Scrapy教程,其中包括:
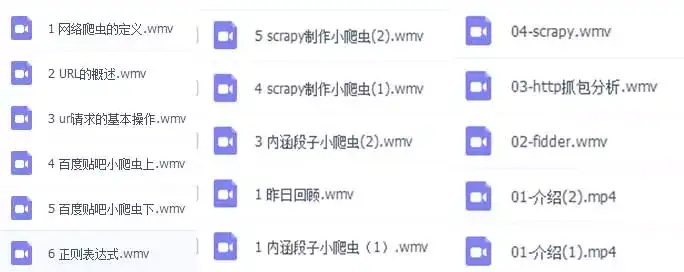
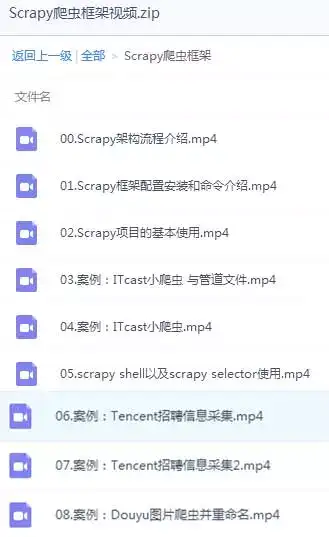
http://yun.itheima.com/course/258.html?sttyun.itheima.com
资料链接:https://pan.baidu.com/s/1eTSiguu 密码:cb66
这个分享,小伙伴们是否满意呢?满意的话动一动小手吧。Thanks♪(・ω・)ノ