两天前骤降的气温依然没有恢复,甚至又开始下起了雪来,慢慢悠悠飘下来的雪花好像一点留在这里的想法都没有,一边下一边化,好不容易才捕获到一点

慢慢悠悠地下雪,就导致小区里面,,,满是泥水:(取完快递回来的时候才发现裤脚已经凌乱到不行= =,听比我家更北方的同学说,他们家已经连着下两天暴雪了(????)
慢慢悠悠地讲到了第七天,终于说到了列表,而有了列表就意味着我们已经可以完成一些基本的算法了,今天就来说一下我学习的时候接触到的第一个算法:冒泡法
冒泡法的原理
如又下是一些前言,不影响本文内容
以前我在学校学到冒泡法的时候,写下第一遍就保存下来,以后每次用就直接复制粘贴,
第一次听老师讲的时候只是听了个大概。直到考试之前,我发现如果让我自己完成的话,
尽管原理很简单,可我还是不能做到脱口而出,提笔就写,只会Ctrl C、Ctrl V。
就很难受,只能老老实实背,就算那时候我还仅仅是背下来,
直到有一天我突然想起来这事,感慨我天资愚钝,只是背下来了原理,考试的时候也都是默写下来的程序,
上机的时候也只是编译运行看到了结果,可我从来没有亲自提笔算一遍。(不是所有人都需要像我这样哈)
“实践是检验真理的唯一标准”
于是我亲按着记忆中的冒泡法自己写一遍程序,又从第一次循环开始算到了循环结束,真的得出来一个排列好顺序的数组。
我想,那一次我才是真正的理解了冒泡法。
废话讲完了/doge,开始正文:
以一个列表为例:[3,7,2,5,0]
冒泡法的原理其实非常简单,如果按总左至右从小到大排列的话,就是每次循环相邻两个数比较一次,然后把大的数放后面,小的放前面,下一次循环亦然。
如果从大到小就是每次比较把大的放前面,小的放后面。
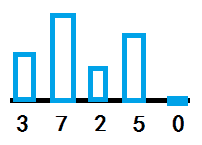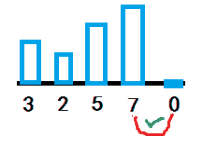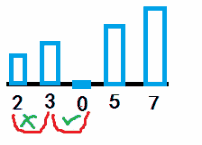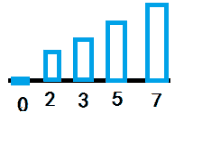
意思很好理解,但是实际在写程序的时候,冒泡法循环是要有一个外循环和一个内循环的
- 外循环,变量 i
外循环用于控制循环次数的,每循环一次,i+1,直到 i 和数据总长度相同为止。每次 i+1 以后的一次循环,循环总长度都要 -1,因为上一次循环中已经把最大的数放在最后面了,就没必要再跟它对比一次了
- 内循环,变量 j
内循环是控制单次外循环以及交换数据位置用的,每次内循环都会把相邻的两个数据作比较,然后大的放后面,小的放前面,而内循环的次数有跟外循环变量 i 的大小有关,前面说过, i+1 以后的一次循环长度 -1,因为没必要再和最大的数据比较一次
- 数据交换位置
经典老三行,让 a 和 b 换位置,加一个中间变量就好
c=b
b=a
a=c
还有另外一种更为简洁的写法:
a,b=b,a
之前说的原理都是按照从左至右从小到大的方式排列的,从大到小的话只要在每次比较的时候把大的放前面,小的放后面就好
用while实现冒泡法
Num=[3,7,2,5,0]
i=0
Num_len=len(Num)
while i<Num_len:
j=1
while j<Num_len-i:
if Num[j-1]>Num[j]:#这里如果把j 和j-1 换一下,就会得到顺序相反的列表
Num[j-1],Num[j]=Num[j],Num[j-1]#数据换位简便写法
j+=1
i+=1
print(Num)
'''
“if Num[j-1]>Num[j]”时的输出:[0, 2, 3, 5, 7]
“if Num[j]>Num[j-1]”时的输出:[7, 5, 3, 2, 0]
'''
这里的len()函数是输出被检测对象的长度的
Num=[3,7,2,5,0]
len(Num)
'''
输出:5
'''
用for实现冒泡法
Num=[3,7,2,5,0]
Num_len=len(Num)
for i in range(Num_len-1):
for j in range(Num_len-i-1):
if Num[j]>Num[j+1]:#这里如果把j 和j+1 换一下,就会得到顺序相反的列表
Num[j],Num[j+1]=Num[j+1],Num[j]
print(Num)
'''
if Num[j]>Num[j+1]输出[0, 2, 3, 5, 7]
if Num[j+1]>Num[j]输出[7, 5, 3, 2, 0]
'''
冒泡排序作为一种原理简单,又十分简洁的算法,通常被教给刚刚入门的学生,以便于了解和学习算法。冒泡法虽然原理简单程序简洁且稳定性强,但是使用起来效率低下,面对超多数量的数据时往往耗时很长。这里主要涉及到时间复杂度、空间复杂度还有稳定性的问题
时间复杂度
以冒泡法为例,冒泡法排序的最坏情况就是每组数据都要交换一次,即:[5,4,3,2,1]变成[1,2,3,4,5]。那么在这个过程里,第一次外循环,“5”被交换了4次;第二次“4”被交换了3次…以此类推,总共交换了4+3+2+1次,相应的就是
(n-1) + (n-2) + …+ 2 + 1,总共是 n(n-1)/2 次
而冒泡法的时间复杂度是 n^2,这个是怎么来的呢
当n=10000的时候,带入公式,10000*(10000-1)/2=(100000000-10000)/2,而10000太小了就被忽略掉了。(至于1/2,我认为它也是被忽略掉了)于是得到的n^2就是冒泡法的时间复杂度
空间复杂度
冒泡法的空间复杂度是O(1),就是在交换数据时临时变量占的内存空间。
可能我水平有限,在实际编程的时候需要考虑空间复杂度的情况不多。因此对于空间复杂度的了解我只限于某某算法的空间复杂度的具体数值,并没有深入研究过。
稳定性
稳定性其实常常被忽略掉,但却是个非常重要的特性。冒泡法就是一种稳定的算法。限于我的水平,我尽管曾经为了效率而使用不稳定的堆排序(不用归并是因为当时我只想换一个试试手),可是在当时我并没有在意不稳定所带来的后果,因为当时我们要做到的只是排个序,而我们最后也在排序后对数据取了平均值,所以当时我也并没有在意这一点。(稍后会说明稳定性什么时候有意义)
可是稳定性依然很重要,先来说明一下我所知的稳定性的意思,大意如下:
在排序中,如果两个元素大小相同,在排序后这两个元素的相对位置没有发生改变,则称这个排序算法是稳定的,否则为不稳定
稳定的算法是可以变得不稳定的,比如if Num[j-1]>Num[j] 写成 if Num[j-1]>=Num[j] 这样,在排序时如果遇到两个相等的元素,他们的位置依旧会被调换,这就是不稳定的算法
而稳定性在什么时候有意义呢?
只有被排序内容的初始位置有意义时,稳定性才有意义,比如,商店统计销量,纸抽和卷纸都是6元,但纸抽卖得比卷纸多,在排序的时候,如果加上单价这一元素,在用不稳定算法的时候,卷纸有可能被排到纸抽前面,而这与我们希望得到的结果不符,这种情况就应该用稳定性的算法。
而在我之前说的我个人的例子里,我需要的只是一个数字顺序,更何况最后我还取了平均值,这时稳定性就没有意义。
…
…
今天就说这么多了哈,原本想的是昨天说了不少了,今天就少说一点,结果写着写着就停不下来了:)
这里要补充一点
其他算法性质补充
- 不稳定的算法有:希尔排序、快速排序、堆排序等
- 稳定的算法有:冒泡排序、归并排序、插入排序等
- 计算时间复杂度的时候要考虑最坏情况、最好情况以及平均,在最坏情况下,时间复杂度是n^2的排序算法有:冒泡排序、希尔排序、快速排序等。
- 最好情况下,时间复杂度是nlogn的排序算法有:堆排序、归并排序、快速排序等
- 平均下来,时间复杂度是nlogn的排序算法有:对排序、归并排序、快速排序、希尔排序等
声明:文章仅供学习交流使用,若有程序错误和写法不当之处烦请私信我,我将及时改正,还请海涵,谢谢!
