摘要
本章学习 retinanet的代码,每次学习一个新的代码都会对目标检测的理解加深,这次的代码风格和以往的又不一样,很值得大家细细品味源码,https://github.com/kuangliu/pytorch-retinanet 本章的代码在数据处理方面就将框的产生和挑选出合格的框全部处理好,能够加深大家对目标检测的理解。
FPN 多特征图预测
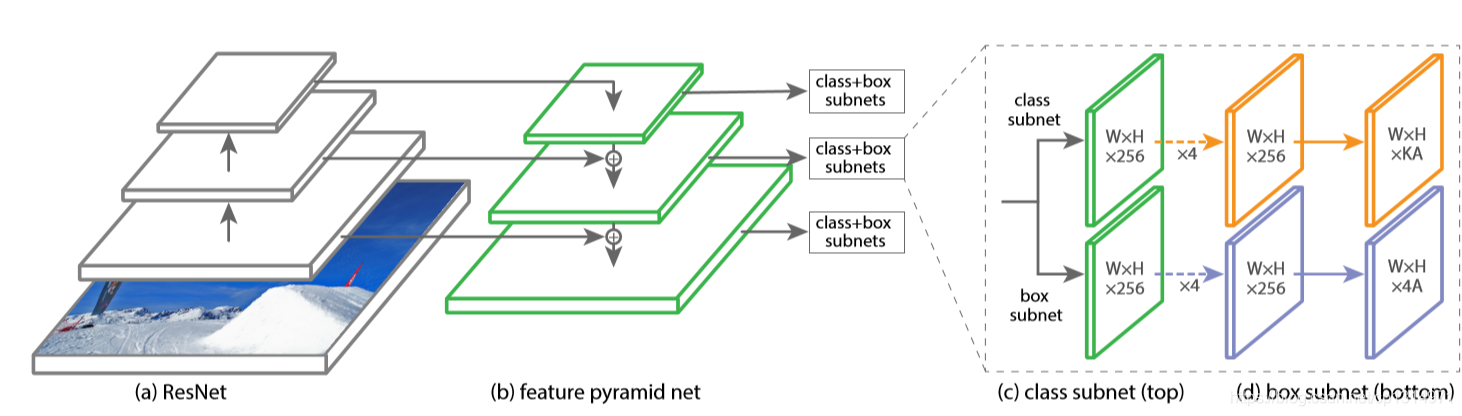
目标检测多尺度预测最重要的一点就是不同级别的特征图融合,不同层输出的特征图大小不同,所以融合需要保持特征图大小一致和通道数一致,这里的fpn只有深层(特征图小于浅层特征图)特征图向浅层特征图融合,这里的深层特征图没有融合到浅层的特征图是最基础的做法,在最新的efficientdet当中多尺度融合相当复杂,所以学会这个是为后面BIFPN打下基础,
'''RetinaFPN in PyTorch.'''
'''RetinaFPN in PyTorch.'''
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
class Bottleneck(nn.Module): #这部分的网络和resnet很相近,可以先去参考我博客写的resnet的网络
expansion = 4
def __init__(self, in_planes, planes, stride=1): #这里传入stride是为后面stride=2做准备,省去了池化,通过stide将特征图变小一般
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, self.expansion*planes, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(self.expansion*planes)
self.downsample = nn.Sequential()
if stride != 1 or in_planes != self.expansion*planes: #每个版块会使用多次,只有第一次使用版块才会激活这个函数,
self.downsample = nn.Sequential(
nn.Conv2d(in_planes, self.expansion*planes, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(self.expansion*planes)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = F.relu(self.bn2(self.conv2(out)))
out = self.bn3(self.conv3(out))
out += self.downsample(x)
out = F.relu(out)
return out
class FPN(nn.Module):
def __init__(self, block, num_blocks):
super(FPN, self).__init__()
self.in_planes = 64
#stide=2 特征图会小一般
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
# Bottom-up layers 每个版块多次使用,layer1的特征图大小不变
self.layer1 = self._make_layer(block, 64, num_blocks[0], stride=1)
self.layer2 = self._make_layer(block, 128, num_blocks[1], stride=2)
self.layer3 = self._make_layer(block, 256, num_blocks[2], stride=2)
self.layer4 = self._make_layer(block, 512, num_blocks[3], stride=2)
self.conv6 = nn.Conv2d(2048, 256, kernel_size=3, stride=2, padding=1) #从这里通道数变为256,就是为了后面融合
self.conv7 = nn.Conv2d( 256, 256, kernel_size=3, stride=2, padding=1)
# Lateral layers
self.latlayer1 = nn.Conv2d(2048, 256, kernel_size=1, stride=1, padding=0)
self.latlayer2 = nn.Conv2d(1024, 256, kernel_size=1, stride=1, padding=0)
self.latlayer3 = nn.Conv2d( 512, 256, kernel_size=1, stride=1, padding=0)
# Top-down layers
self.toplayer1 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1)
self.toplayer2 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1)
def _make_layer(self, block, planes, num_blocks, stride):
strides = [stride] + [1]*(num_blocks-1)
layers = []
for stride in strides:
layers.append(block(self.in_planes, planes, stride))
self.in_planes = planes * block.expansion
return nn.Sequential(*layers)
def _upsample_add(self, x, y): #上采样就可以小的特征图变大
'''Upsample and add two feature maps.
Args:
x: (Variable) top feature map to be upsampled.
y: (Variable) lateral feature map.
Returns:
(Variable) added feature map.
Note in PyTorch, when input size is odd, the upsampled feature map
with `F.upsample(..., scale_factor=2, mode='nearest')`
maybe not equal to the lateral feature map size.
e.g.
original input size: [N,_,15,15] ->
conv2d feature map size: [N,_,8,8] ->
upsampled feature map size: [N,_,16,16]
So we choose bilinear upsample which supports arbitrary output sizes.
'''
_,_,H,W = y.size()
return F.upsample(x, size=(H,W), mode='bilinear') + y
def forward(self, x):
# Bottom-up
c1 = F.relu(self.bn1(self.conv1(x)))
c1 = F.max_pool2d(c1, kernel_size=3, stride=2, padding=1)
c2 = self.layer1(c1)
c3 = self.layer2(c2)
c4 = self.layer3(c3)
c5 = self.layer4(c4)
p6 = self.conv6(c5)
p7 = self.conv7(F.relu(p6))
# Top-down
p5 = self.latlayer1(c5)
p4 = self._upsample_add(p5, self.latlayer2(c4)) #变成一样大小,方便融合
p4 = self.toplayer1(p4)
p3 = self._upsample_add(p4, self.latlayer3(c3))
p3 = self.toplayer2(p3)
return p3, p4, p5, p6, p7 #这里的p3,p4都是融合深层的特征图的
def FPN50():
return FPN(Bottleneck, [3,4,6,3])
def FPN101():
return FPN(Bottleneck, [2,4,23,3])
def test():
net = FPN50()
fms = net(Variable(torch.randn(1,3,600,300)))
for fm in fms:
print(fm.size())
# test()

这里是输出的特征图,大的特征图对小物体检测效果更好,所以使用多种特征图
retinanet 网络构建
前面只是构建特征图的提取部分,在目标检测中我们通过预测框的位置和分类来定义loss函数来让网络学习预测。
import torch
import torch.nn as nn
from fpn import FPN50
from torch.autograd import Variable
class RetinaNet(nn.Module):
num_anchors = 9 #对应前面输出的特征图,每一个单元格都会预测9个框,想faster rcnn那样
def __init__(self, num_classes=20):
super(RetinaNet, self).__init__()
self.fpn = FPN50()
self.num_classes = num_classes
self.loc_head = self._make_head(self.num_anchors*4) #用来预测框的四个坐标点
self.cls_head = self._make_head(self.num_anchors*self.num_classes) #预测分类
def forward(self, x):
fms = self.fpn(x)
loc_preds = []
cls_preds = []
for fm in fms: #有五个特征图,所以需要遍历每一个
loc_pred = self.loc_head(fm)
cls_pred = self.cls_head(fm)
loc_pred = loc_pred.permute(0,2,3,1).contiguous().view(x.size(0),-1,4) # [N, 9*4,H,W] -> [N,H,W, 9*4] -> [N,H*W*9, 4]
cls_pred = cls_pred.permute(0,2,3,1).contiguous().view(x.size(0),-1,self.num_classes) # [N,9*20,H,W] -> [N,H,W,9*20] -> [N,H*W*9,20]
loc_preds.append(loc_pred)
cls_preds.append(cls_pred)
return torch.cat(loc_preds,1), torch.cat(cls_preds,1) #这样就将全部的特征图预测连接在一起了
def _make_head(self, out_planes):
layers = []
for _ in range(4):
layers.append(nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1))
layers.append(nn.ReLU(True))
layers.append(nn.Conv2d(256, out_planes, kernel_size=3, stride=1, padding=1))
return nn.Sequential(*layers)
def freeze_bn(self):
'''Freeze BatchNorm layers.'''
for layer in self.modules():
if isinstance(layer, nn.BatchNorm2d):
layer.eval()
def test():
net = RetinaNet()
loc_preds, cls_preds = net(Variable(torch.randn(2,3,300,300)))
print(loc_preds.size())
print(cls_preds.size())
test()
输出如下
torch.Size([2, 17451, 4])
torch.Size([2, 17451, 20])
总结
这样就将全部网络的预测连接在一起,方便之后loss的训练,这里的17451是在(38,38),(19,19),(10,10),(5,5),(3,3)每个特征图上的单元格上全部预测9个框,20分类的类别,现在里面的数都是随机的,下一步我们需要定义那些数值才是我们需要的,就是label,让产生的随机数是我们想要的这样数,所以我们在下一步就要将过滤大部分的框,一张图片基本只有几个物体,现在产生的17451太多了,所以需要处理相当大一部分不参与训练。
