《数据化风控》读书笔记分享
Chapter1 信用评分基础认识与应用
一些概念的介绍
- ABC卡(Application Score;Behavior Score ; Collection Score)
- 观察期和表现期:近一年来逾期超过30天的次数为目标变量,那么近一年就是观察期,表现期是预测未来一年客户的违约情况。
- 违约定义:逾期,催收,呆账等
- 不确定定义(灰色人群)
- 实际分析中,可以使用转移分析来
- 变量分析:粗筛–>细筛(长列表到短列表)
- 模型效力测试:区分度指标(KS值和gini系数)&稳定性指标(PSI)
- 风险等级制定与累积违约(确定临界点)
- 临界点个数分为:单临界点、双临界点和多临界点
- 或者为了控制风险:银行采用两套评分卡,做交叉参考
Chapter2 信用评分模型的规格和设计
建模前的准备分析
- 数据收集以及质量问题:1. 是否有足够的坏客户 2.数据的可获得期间是否满足项目目标 3.变量数据是否准确
- 利用账龄分析(Vintage Analysis)来观察目标客户的违约成熟期长度。(观察到正常客户在12个月后转坏的比例趋于稳定,则表现期为12个月)
- 表现期需要和成熟期一致或者比成熟期更长
- 利用账龄分析,一般9-12月成熟,银行的风控的,根据建模经验和巴萨尔协议,一般表现期为12月。
Chapter3 分组目的和分析选择
- 利用客群组内差异小,组间差异大的特点,对变量分组,进而提升模型的能力。另外,经过分组进行开发的模型,稍后要进行风险校准(Calibration)
- 根据风险轮廓和客户分布来判断分组是否合适。
Chapter4 细致分组和自变量分析
- 将连续变量离散化:有以下优点1. 鲁棒性增加 2. 非线性的变量可应用于线性模型。 3. 离散变量可以了解变量和目标事件的趋势关系。
- 细致分类需要满足样本比例和目标事件趋势相同
- 单因子分析:PSI和IV
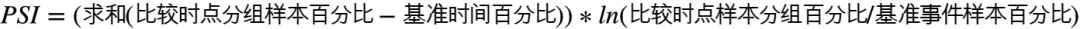
- psi衡量数值:0.1,0.25

- 相关系数
- 变量筛选:变量的PSI小于0.1且IV大于0.1,保留变量;同时考察相关系数大于0.7的变量,根据业务知识挑选适合的标量进行后续的开发
粗分类准则(具体操作仍需细化)
- 变量上升和下降和业务经验相同
- 单变量最多维持在8个区间
- 分组好坏对比值最少差距15倍以上
- 分组需要每组都包含2%的开发样本
- 每组需要至少30笔目标事件的开发样本,或者目标样本占本组样本的1%(保证每组都有坏人信息)
- 将空值,缺失值和其他特殊变量合并至同一区间,统称为空集。
- 一般空集分组好坏比比整体低。(坏人较多,坏人的有效信息比较少)
Chapter5 模型建立方法讨论
评分卡构建步骤
- 变量选择:1. 顺向选择法 2. 反向淘汰法 3. 逐步分析法,筛选规则:变量的F值
- 模型表现:T检验,F检验,
- 逻辑回归:sigma函数:

- 自变量处理:1. woe处理,避免出现极值,同时避免过拟合,增加模型鲁棒性,woe =

- Distr Good表示好件占全体好件的比例,Distr Bad 表示坏件占全体坏件的比例,2. 虚拟变量,当数字没有显著的意义,可以使用虚拟变量来的方法
- 两阶段回归步骤的确定:
- 模型建立:将样本分为7:3,70%作为开发样本,进行逐步回归
- 第一阶段回归:主要观察变量的区间给分和对应的好坏比值是否相符。不相符的,需要重新设计
- 相关分析:相关系数高于0.85的,选择iv较高的那个变量
- 重复2-3找到最佳模型
- 第二阶段回归,重复2-5找到最佳模型:第一阶段计算后的残差值,作为第二阶段的因变量
- 模型检验:利用30%的保留样本和时间外样本分别进行效度检验,利用KS和GINI来作为标准
- 得到评分卡的分数
- 模型初始化
- 变量转化(变量转化为虚拟变量,取代原有值,保证模型的稳定性)
- 逻辑回归
- 取前一阶段的残差作为因变量,联征特征作为自变量,进行线性回归分析。
Chapter6 拒绝推论
- 主要原因:评分卡用的是通过申请的用户,也就是审核通过的用户数据来建立模型,会忽略原先被拒绝客户的影响力,使模型略显乐观。需要通过拒绝推论对模型进行校准。
- 其他原因:1.增加建模样本 2. 政策变动,使得通过人群分布发生变化,但是申请用户分布不会改变 3. 决策角度,拒绝推论可以对所有的申请客户做出更正确的真实推测。 4.拒绝推论可以找到过去被拒绝的好用户
- 拒绝推论方法
- 分配法: 1. 用已知的好坏样本,建立初步的评分卡模型 2. 使用第一阶段模型来评价所有拒绝件,并且估算他们的违约概率 3.将已知好坏的样本按照评分分数进行分组,并计算各分组内的实际违约概率 4. 将拒绝件按照之前的步骤进行分组。按照每组的实际违约率作为抽样比例,随机在拒绝件中抽取坏件,其余指定为好件。 5.将打标之后的拒绝件新增至申请通过样本中,重新建立评分卡。
- 硬截断法:1. 用已知的好坏样本,建立初步的评分卡模型 2.使用已建立的评分卡模型对所有拒绝件进行评分,并建立预期核销率 3.设定核销水平,找到核销分数,低于此分数,视为坏件,高于此分数,视为好件。 4.将打标之后的拒绝件新增至申请通过样本中,重新建立评分卡。
- 模糊法:模糊法不是指定样本好坏,而是将每个拒绝件拆分为部分好件和部分坏件
- 迭代再分类法:类似硬截断法,但是是重复分组到某一临界点为止(利用VSscore的散布图)。
Chapter7 风险校准
- 模型产出
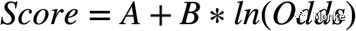
,假设平均分数为600,每隔20分Odds加倍,可以得到

,其中PDO为每隔多少分Odds加倍。
- 风险校准
- 步骤:
- 1. 计算出所有样本的最终模型评分
- 2. 各分组样本分数由低到高的排序
- 3.按排序后切成n份,再计算每一等分的好件数、坏件数、好坏比和

以及平均分数。
- 4. 建立切分的平均分数和
的回归式。根据决定回归式。
- 5. 最后
其中
是将平均分数以及对数好坏比值间建立的最佳回归式。、
- 6. 校准后的分数为因变量,入模变量为自变量,建立校准分的评分卡。(若为树模型,则在每次得到初始分后,进行校准)
- 模型验证
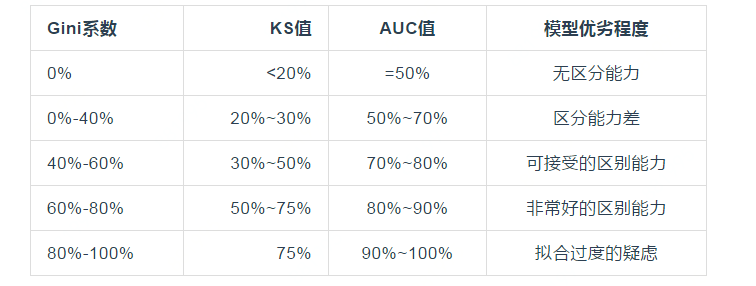
- 基尼系数:横纵坐标分别为分数从小到大的累积坏人占比以及累积好人战力,曲线和中轴线的面积/中轴线和坐标轴的三角形面积
- ks值:横坐标为分数,分别做违约客户占比和正常客户占比,他们的差为ks曲线,ks曲线最大的点为ks值
- roc面积:roc曲线是误授率(将违约客户评为好客户)和1-误拒率(将好客户误评为坏客户)
- 样本外验证: 1.开发样本及保留样本 2.时间样本外
Chapter8 决策点设置
- 按照业务需求,一般根据一下指标确定决策点 1.好坏件比率 2.核准率 3.核准件中好客户比率(好人通过率) 4. 核准件中坏客户比例(坏人占比)目前用此指标确定决策点
Chapter9 模型监控报告
- 前端监控:观察期的稳定度,监控过去开发的样本和现在的客户样本差异。
- 后端监控:表现期的鉴别度,确保过去开发样本建立的模型在经过一段时间后仍具有鉴别能力。
- 前端监控:
- 评分分布表:显示客户评分变化(由高到低,由低到高),具体发生的原因,可以参考变量稳定性和产品大事记来进行分析。
- 群体稳定性指标:衡量整体评分卡在开发样本和现在样本的差异度。具体变化还需要结合评分分布表来看。
- 变量稳定性指标:

- 变量分布差距绝对值越大,此变量越不稳定。变量分布差距为正值,表示分布向高分移动,反之,向低分移动。
- 人工否决分析:上线前,确定高分否决率和低分否决率,上线监控此两个指标。
- 数据错误分析:评分在正常范围
- 产品大事记:1.内部事件: 营销活动,目标市场发生改变,授信策略,核准点改变 2.外部事件:监管,经济事件
- 后端监控:
- 好坏客户评分分布表:同一时间点的评分客户,目的是观察模型对好坏用户的鉴别能力。
- 母体鉴别度指标(KS,Gini):ks值仅表示某一单一评分组的好坏客户的差距,不嗯能代表所有评分组的好坏客户的分离程度。Gini系数用来衡量模型鉴别全体客户好坏能力的数值。
- 变量鉴别度分析:计算变量iv值,一般阈值为0.1,大于0.1的变量有较好的对好坏客户预测的能力。
- 好坏概率与评分分析:鉴别能力好的模型应该出现高评分组有较多的好客户以及低评分组有更多的坏客户的状态。
- 人工否决分析:加入人工干预,同模型做ABtest