rdt 3.0 协议性能分析
假设有两台主机,分别位于美国西海岸和东海岸,它们之间的往返传播实验 RTT 大约为 30ms,假定它们通过一条速率 R 为 1Gbps 的信道相连。包括首部字段和数据的分组长 L 为 1000 bytes(8000 bits),所以发送一个分组进入 1Gbps 链路实际所需时间是:
t_trans = L / R = (8000 bit/pkt) / (10^9 bit/s) = 8 μs/pkt
所以,如果发送端在 t = 0 时刻开始发送分组,则在 8μs 后,该分组全部进入了发送端信道。接着该分组经过 15ms 的旅途到达接收端,即该分组的最后 1 bit 在时刻 t = RTT/2 + L/R = 15.008ms 时到达接收端。假设 ACK 分组很小,可以忽略其发送时间,且接收端一旦收到一个数据分组的最后 1bit 后立刻发送 ACK,则 ACK 在时刻 t = RTT + L/R = 30.008ms 时回送到发送端。也就是说,经过 30.008ms 后发送端才可以发送下一个分组。
设利用率为:发送端实际忙于将发送比特送进信道的那部分时间与发送时间之比。则
U_sender = (L/R) / (RTT + L/R) = 0.008 / 30.008 = 0.00027
可以看到,利用率极其低下,这是不可容忍的,所以我们需要改进性能。
流水线技术
流水线技术是解决这种特殊性能问题的一个非常简单的方法:不使用停等方式运行,允许发送端发送多个分组而无需等待确认。
虽然流水线可以直线提升 rdt 3.0 协议的性能,但是也会带来如下的影响:
- 必须增加序号的范围。因为每个传输中的分组(不计算重传的)必须有一个唯一的序号,而且也许有多个在输送中尚未确认的分组
- 协议的发送端和接收端也必须缓存多个分组。发送方最低限度应当能缓冲那些已发送但没有确认的分组,接收方或许也需要缓存那些已正确接收的分组
- 所需序号范围和对缓冲的要求取决于数据传输协议如何处理丢失、损坏和延时过大的分组。
解决流水线的差错恢复有两种基本方法,分别为 回退 N 步(Go-Back-N, GBN) 和 选择重传(Selective Repeat, SR)。
GBN 协议(回退 N 步协议)
在 GBN 协议中,允许发送方发送多个分组(当有多个分组可用时)而不需等待确认,但它也受限于在流水线中未确认的分组数不能超过某个最大允许数 N。

上图显示了发送方看到的 GBN 协议的序号范围。将基序号(base)定义为最早的未确认分组的序号,将下一个序号(nextseqnum)定义为最小的未使用序号(即下一个待发分组的序号),则可将序号范围分割成 4 段。在 [0, base-1] 段内的序号对应于已经发送并确认的分组。[base, nextseqnum-1] 段对应已经发送但未被确认的分组。[nextseqnum, base+N-1] 段内的序号能用于那些要立即发送的分组,如果有数据来自于上层的话。最后,大于或等于 base+N 的序号是不能使用的,直到当前流水线中未确认的分组(特别是序号为 base 的分组)已得到确认为止。
在上图中,把 [base, base+N-1] 看做一个长度为 N 的窗口。随着协议的运行,该窗口在序号空间向前滑动。因此,N 常被称为窗口长度(window size),GBN 协议也常被称为滑动窗口协议(sliding-window protocol)。至于为什么需要限制 N 的范围,是因为这是流量控制的方法之一。
在实践中,一个分组的序号承载在分组首部的一个固定长度的字段中。如果分组序号字段的比特数是 k,则该序号范围是 [0, 2^k - 1]。在一个有限的序号范围内,所有涉及序号的运算必须使用模 2^k 运算。
下图是GBN 协议发送方扩展 FSM 描述:
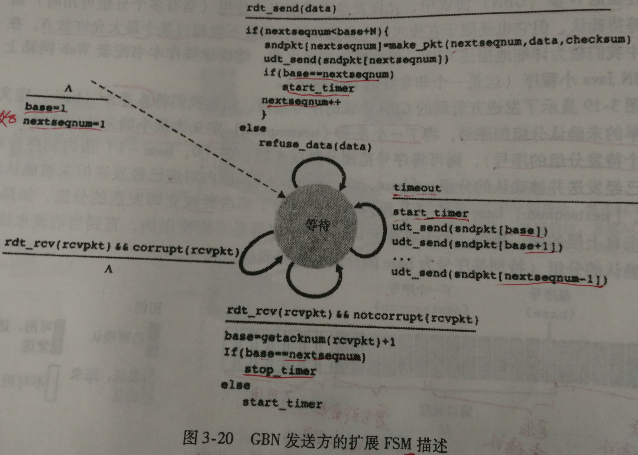
发送方必须响应三种类型的事件:
- 上层的调用。当上层调用
rdt_send()时,发送方首先检查发送窗口是否已满,即是否有 N 个已发送但未被确认的分组。如果窗口未满,则产生一个分组并将其发送,并相应地更新变量。如果窗口已满,发送方只需将数据返回给上层,隐式地指示上层该窗口已满。然后上层可能会过一会儿再试。在实际实现中,发送方更可能缓存这些数据,或者使用同步机制(如一个信号量或标志)允许上层在仅当窗口不满时才调用rdt_send()。 - 收到一个ACK。在 GBN 协议中,对序号为 n 的分组的确认采取累积确认(cumulative acknowledgment)的方式,表明接收方已正确接收到序号为 n 的以前且包括 n 在内的所有分组。
- 超时事件。协议的名字“回退 N 步”来源于出现丢失和时延过长分组时发送方的行为。就像在停等协议中那样,定时器将再次用于恢复数据或确认分组的丢失。如果出现超时,发送方重传所有已发送但未被确认过的分组。上图中发送方仅使用一个定时器,如果收到了一个 ACK,但仍有已发送但未被确认的分组,则定时器被重新启动。如果没有已发送但未被确认的分组,该定时器被终止。
下图是 GBN 协议接收方扩展 FSM 描述:

如果一个序号为 n 的分组被正确接收到,并且按序(即上次交付给上层的数据是序号为 n - 1 的分组),则接收方为分组 n 发送一个 ACK,并将该分组中的数据部分交付到上层。
在所有其他情况下,接收方将丢弃该分组,并为最近按序接收的分组重新发送 ACK。
注意到因为一次交付给上层一个分组,如果分组 k 为已接受并交付,则所有序号比 k 小的分组也已经交付。因此,使用累积确认是 GBN 的一个自然的选择。
虽然 GBN 协议看起来很浪费,因为它会丢弃一个正确接收(但失序)的分组。但这样做是有道理的。因为接收方必须将数据按序交付给上层,假设现在期望接收分组 n,而分组 n + 1 却到了,因为数据必须按序交付,所以接收方可能缓存分组 n + 1,然后,在它收到并交付分组 n 后,再将该分组交付到上层。但是,如果分组 n 丢失,则该分组及分组 n + 1 最终将在发送方根据 GBN 重传规则而被重传,所以,接收方只需要直接丢弃分组 n + 1 即可。
这种方法的优点是接收方不需要缓存任何失序分组,唯一需要维护的信息就是下一个按序接收的分组的序号。缺点就是随后对该分组的重传也许会丢失或出错,进而引发更多的重传。
可以看到,GBN 协议本身相对于 rdt 3.0 协议有了长足进步,但是仍然有它自己的性能问题,尤其是当窗口长度和带宽时延都很大的时,流水线中有很多分组更是如此。任何单个分组的差错就能引起 GBN 协议重传大量分组,事实上是很多分组根本没必要重传,所以,有了一个更加优化的协议,就是下面要说的 选择重传(SR) 协议。
SR 协议(选择重传协议)
SR 协议在 GBN 协议的基础上进行了改进,它通过让发送方仅重传哪些它怀疑在接收方出错(即丢失或受损)的分组而避免了不必要的重传。
下图描述了发送方与接收方的序号空间:
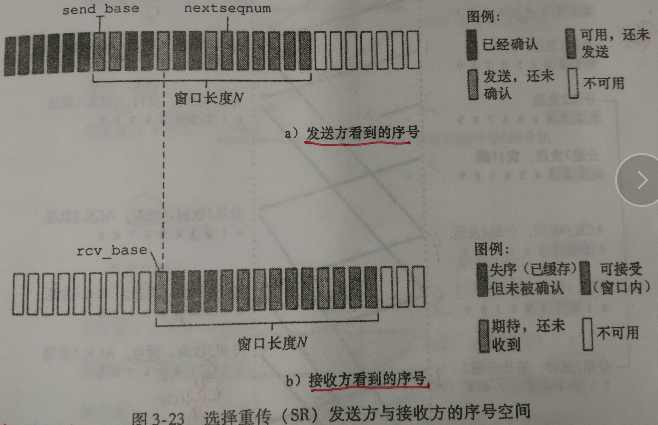
发送方的事件与动作:
- 从上层收到数据。当从上层接收到数据后,SR 发送方检查下一个可用于该分组的序号。如果序号位于发送方的窗口内,则将数据打包并发送;否则就像在 GBN 中一样,要么将数据缓存,要么将其返回给上层以便以后传输。
- 超时。定时器再次被用来防止丢失分组。然而,现在每个分组必须拥有其自己的逻辑定时器,因为超时发生后只能发送一个分组。
- 收到ACK。如果收到 ACK,倘若该分组序号在窗口内,则 SR 发送方将那个被确认的分组标记为已接收。若该分组的序号等于 send_base,则窗口基序号向前移动到具有最小序号的未确认分组处。如果窗口移动了并且有序号落在窗口内的未发送分组,则发送这些分组。
接收方的事件与动作:
- 序号在 [rcv_base, rcv_base+N-1] 内的分组被正确接收。在此情况下,收到的分组落在接收方的窗口内,一个选择 ACK 被回送给发送方。如果该分组以前没收到过,则缓存该分组。如果该分组的序号等于接收端的基序号(rcv_base),则该分组以及以前缓存的序号连续的(起始于 rcv_base 的)分组交付给上层。然后,接收窗口按向前移动分组的编号向上交付这些分组。
- 序号在 [rcv_base-N, rcv_base-1] 内的分组被正确收到。在此情况下,必须产生一个 ACK,即使该分组是接收方以前确认过的分组。
- 其他情况。忽略该分组。
注意上面的第二步,接收方需要重新确认(而不是忽略)已收到过的那些序号小于当前窗口基序号的分组。为什么要返回 ACK?加入按照上图中所示的发送方和接收方的序号空间,如果分组 send_base 的 ACK 没有从接收方传播回发送方,则发送方最终将重传分组 send_base,即使显然接收方已经收了该分组。如果接收方不确认该分组,则发送方窗口将永远不能向前滑动。
上面的例子说明了对于 SR 协议(和很多其他协议一样) 对于哪些分组已经被正确接收,哪些没有,发送方和接收方并不总能看到相同的结果。也就是说,发送方和接收方的窗口并不总是一致。
窗口长度与序号空间大小
下面这个例子说明了,如果窗口长度与序号空间大小选择不当,将会产生严重的后果。

在这个例子中,有四个分组序号 0、1、2、3 且窗口长度为 3。假定发送了分组 0 至 2,并且接收方被正确接收且确认了。此时,接收方窗口落在 4、5、6 个分组上,其序号分别为 3、0、1.现在考虑两种情况。
在第一种情况下,如上图中的 a 图所示,对前 3 个分组的 ACK 丢失,因此发送方重传这些分组。因此,接收方下一步要接收序号为 0 的分组,即第一个发送分组的副本。
在第二种情况下,如上图中的 b 图所示,对前 3 个分组的 ACK 都被正确交付。因此发送方向前移动窗口并发送第 4、5、6 个分组,其序号分别为 3、0、1.序号为 3 的分组丢失,但序号为 0 的分组到达(一个包含新数据的分组)。
显然,接收方并不知道发送方那边出现了什么问题,对于接收方自己来说,上面两种情况是等价的。没有办法区分是第一个分组的重传还是第 5 个分组的初次传输。所以,窗口长度比序号空间小 1 时协议无法正常工作。但窗口应该有多小呢?
答案是:窗口长度必须小于或等于序号空间大小的一半。
可靠数据传输过程中的分组重新排序问题
在前面的所有假设中,我们都是假定分组在发送方与接收方之间的信道中不能被重新排序。但是当连接两端的信道是一个网络时,分组重新排序是可能会发生的。
分组重新排序的一个表现就是一个具有序号或确认号 x 的分组的旧副本可能会出现,即使发送方或接收方的窗口中都包含 x。
对于分组重新排序,信道可被看成基本上是在缓存分组,并在将来任意时刻自然地释放出这些分组。由于序号可以被重新使用,那么必须小心,以免出现这样的冗余分组。
实际应用中采用的方法是:**确保一个序号不被重新使用,直到发送方“确信”任何先前发送的序号为 x 的分组都不再在网络中为止。通过假定一个分组在网络中的“存活”时间不会超过某个固定最大时间量来做到这一点。在高速网络的 TCP 扩展中,最长的分组寿命被假定为大于 3 分钟 [RFC 1323]。