文章目录
本文档为实时计算相关的监控系统的整体说明,记录监控系统相关的部分细节。
监控大盘如图:
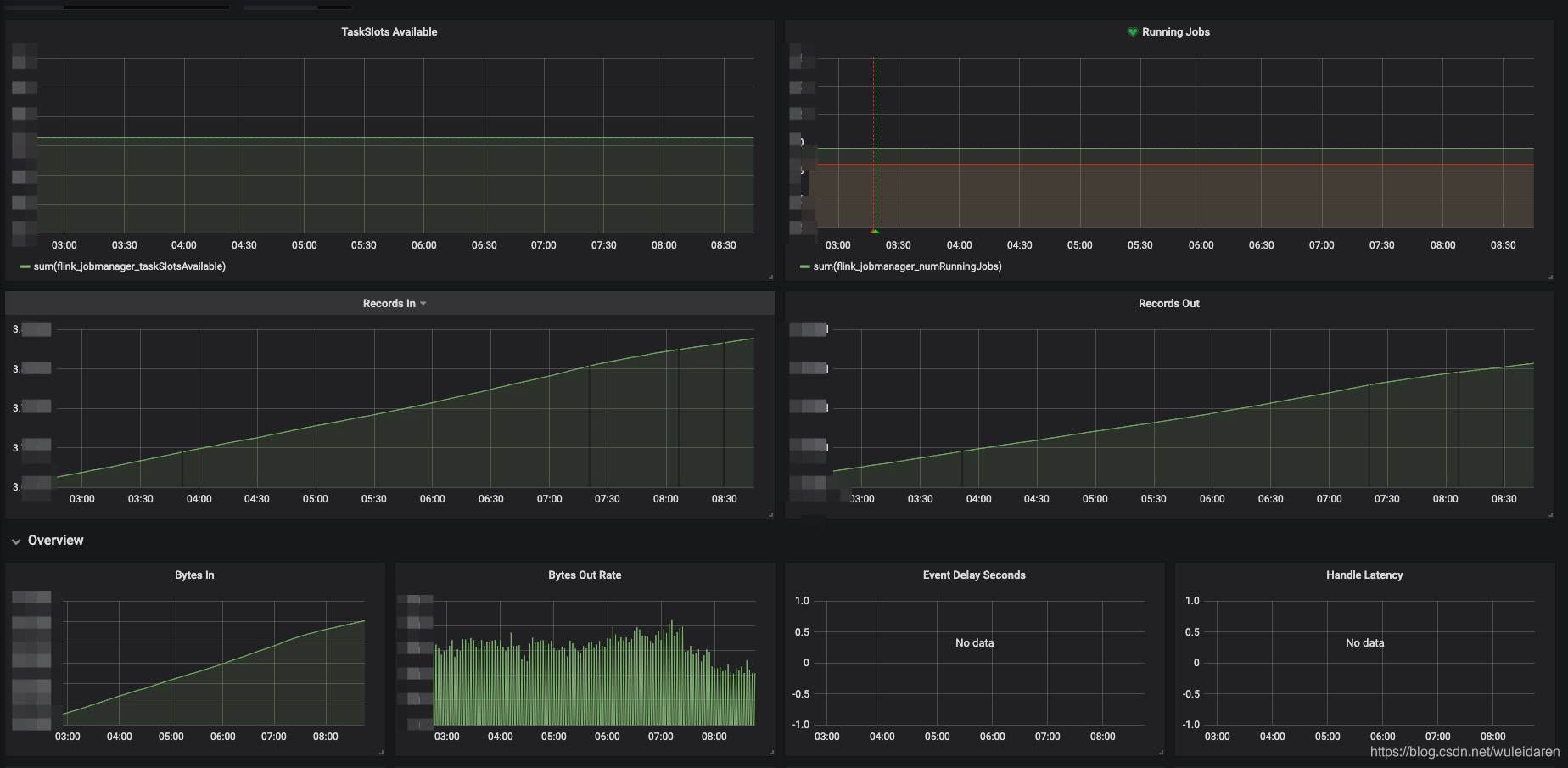
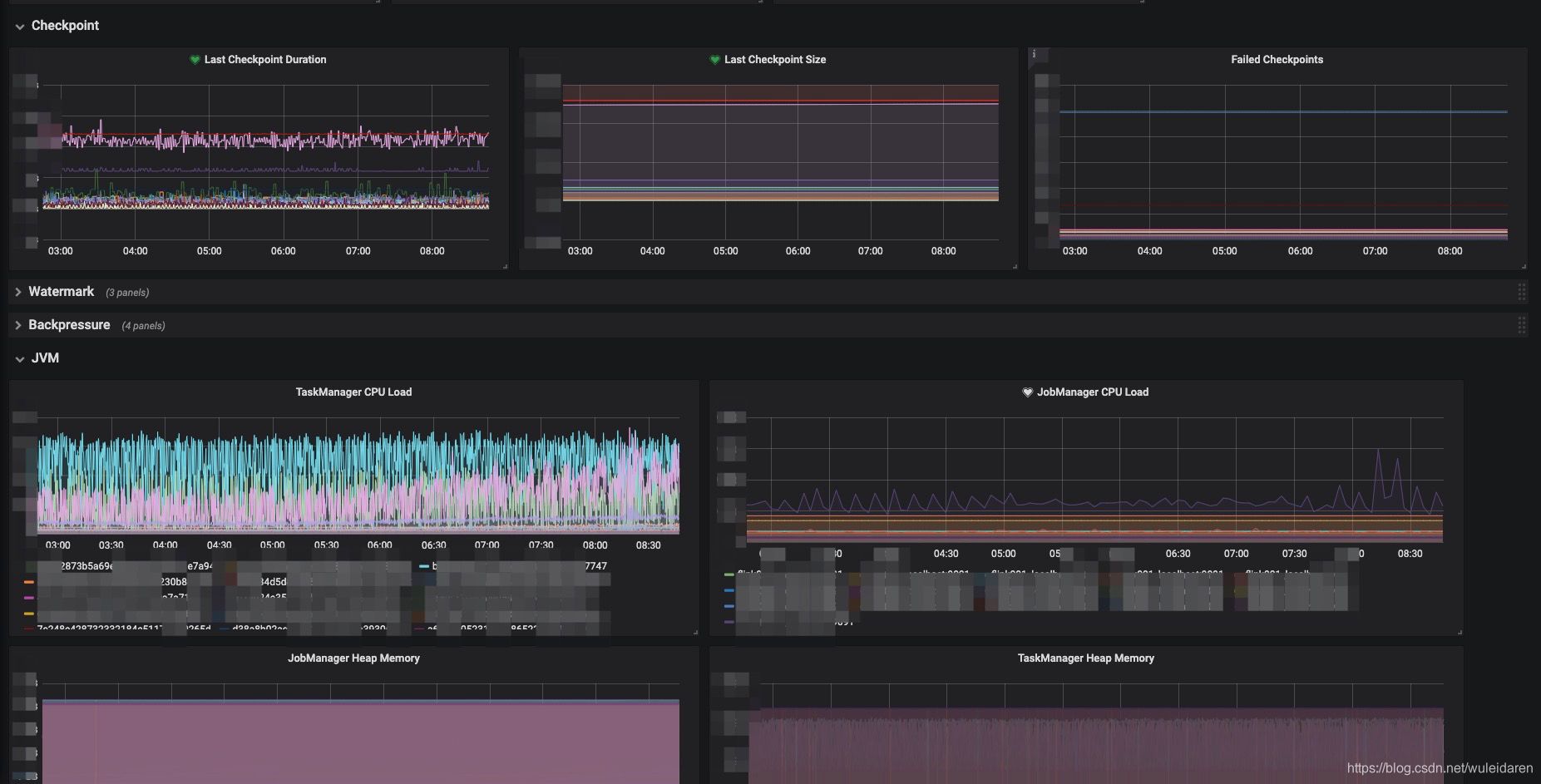
1. 功能点
- 对Flink集群(服务器)进行监控
- 对源头数据源与目的数据源进行监控
- 对指标作业进行监控
- 告警
2. 方案对比
当前市场上最为火热的时序数据库为influxdb与prometheus,可视化展示都为grafana。个人理解influxdb与prometheus的区别主要为:
在大多数资料中提及对flink的监控往往是prometheus,可能与flink较早实现其reporter相关,但是现在也支持了influxdb的reporter
influxdb采用的概念类似与传统的数据库,具有DB、table(measurement)的概念,操作语言类似SQL,prometheus则使用时序数据库的基本概念,如tag、time概念,操作语言自定义为PromSQL,与SQL相比更为简洁灵活,有点类似于Scala与Java的区别
influxdb仅仅为时序数据库,prometheus则有一个较完整的生态,如pushgateway、alertManage、node_exporter,特别是alertManage作为告警组件是influxdb当前不具备的
所以,目前,我们认为如果只是应用时序数据库的特性,如对指标的聚合检索、开发报表,考虑到使用方便,我们采用influxdb。另外,考虑到监控、报警的额外需求,以及与flink的集成,我们采用prometheus。两个时序数据库在部门中都有使用,接下去一个月将重点进行比较,前端展示都是granafa。
2.1 方案一:prometheus+flink
整体架构图
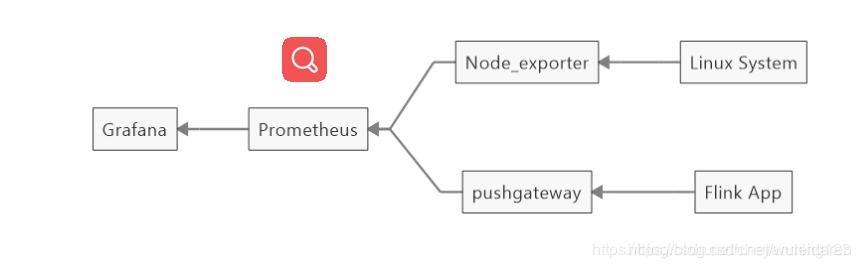
Flink App : Flink的metrics,通过reporter将数据发出去metric信息
Prometheus : 一套开源的系统监控报警框架,本身为时序数据库
Pushgateway : Prometheus生态中一个重要工具,Flink可通过配置此reporter直接将数据写入Prometheus
Node_exporter : 跟Pushgateway一样是Prometheus生态中的一个组件,采集服务器的运行指标如CPU, 内存,磁盘等信息
Grafana: 一个跨平台的开源的度量分析和可视化工具,可以通过将采集的数据查询然后可视化的展示,并及时通知
Alertmanager:跟Pushgateway一样是Prometheus生态中的一个组件,为处理报警,比grafana更灵活强大,但是采用的是配置json文件的方式,并且需要重启,没有grafana自带的可视化告警方便(未采用)
更详细的架构可参考:
2.1.1 安装部署
https://blog.csdn.net/cheyanming123/article/details/101298609
2.1.2 有价值资料
- grafana官网:https://grafana.com/docs/grafana/latest/
- prometheus git:https://github.com/prometheus/pushgateway/blob/master/README.md
- prometheus中文帮助文档:https://www.kancloud.cn/yetship/prometheus_practice/462166
- prometheus官网:https://prometheus.io/docs/introduction/overview/
2.1.3 错误总结
1、prometheus一旦启动占用大量内存,原因是pushgateway积累了大量的数据会push到prometheus,需要手动清除pushgateway中的数据。prometheus中日志会出现‘level=info ts=2020-04-08T11:40:55.581381661Z caller=head.go:526 component=tsdb msg=“head GC completed” duration=286.757915ms’,其中duration正常的数值应该是1~2ms。清除数据可以参考prometheus git的readme中的‘curl -X PUT http://pushgateway.example.org:9091/api/v1/admin/wipe’
2、grafana alert告警无效。具体情况是直接在‘Notification Channels’进行Test是可以发送钉钉通知的,但是到实际panel中时好时坏,后来总结有以下几点:
2.1 配置完告警进行Test Rule,如果是True表示告警成功,但是这时是无法收到告警的,只有进行右上角的‘Save’后实际触发才会真正收到告警通知
2.2 一个panel最多同一时刻只会发出一次告警,也就是说如果一个panel此刻已经有一个处于‘Alerting’状态的告警,即使再次达到告警阈值,也不会重复触发告警,只有将告警状态自动恢复为‘OK’,或者删除这条Rule才行
3、启动问题:
level=error ts=2018-11-19T06:04:47.83421089Z caller=main.go:625
err=“error starting web server: listen tcp 0.0.0.0:9090: bind: address already in use”
解决:查找使用9090端口的PID并删掉
lsof -i :9090
4、告警异常,test可以发送钉钉消息,但是实际中无法发送,查看日志’tail -500f /var/log/grafana/grafana.log’, 如是timeout,可能是image的问题,可以关闭Notification Channel 中的‘Include image’选项;如是‘invalid character ‘\t’’,可以换个panel试试;如是‘context deadline exceeded’,可以清理pushgateway的内容
5、pushgateway启动是直接启动进程的,与session绑定,需要使用nohup命令解除session与进程的关系(除非用server启动,否则会出现关闭shell窗口以后进程死亡的现象。 如 nohup ./pushgateway &> /dev/null &
6、收到的告警信息链接是localhost,修改grafana.ini中参数‘root_url’,并重启grafana
7、若在flink日志中出现‘Failed to push metrics to PushGateway with jobName_xx. java.io.IOException: Response code from http://XX:9091/metrics/job/was 200’,若是允许flink重启,可以调整为debug级别看看具体错误原因,本次遇到的问题是版本问题,即在用Flink1.9.1配置prometheus监控,把metrics数据上报到PushGateway1.0.0的时候报错,把PushGateway的版本降到0.9.0就可以了
2.1.4 参考命令
netstat -apn | grep -E ‘9091|3000|9090|9100’
lsof -i :9091 pushgateway
lsof -i :9100 node_exporter
2.2 方案二:influxdb(当前与监控系统无关)
2.2.1 influxdb常用命令
基本与标准SQL相同,安装启动可参考阿里文档https://help.aliyun.com/document_detail/113093.html?spm=5176.12574288.0.0.38e64f91ruScGd
- use xxdb //选择db
- drop measurement xxmeasurement
//删除名字为‘xxmeasurement’的measurement,需要admin权限,一般使用delete删除数据 - delete from xxmeasurement //不能加where条件,只能全部删除
- select count(*) from xxmeasurement
//只会对field进行count,对只能作为where条件的tag无法统计
2.2.2 使用经验
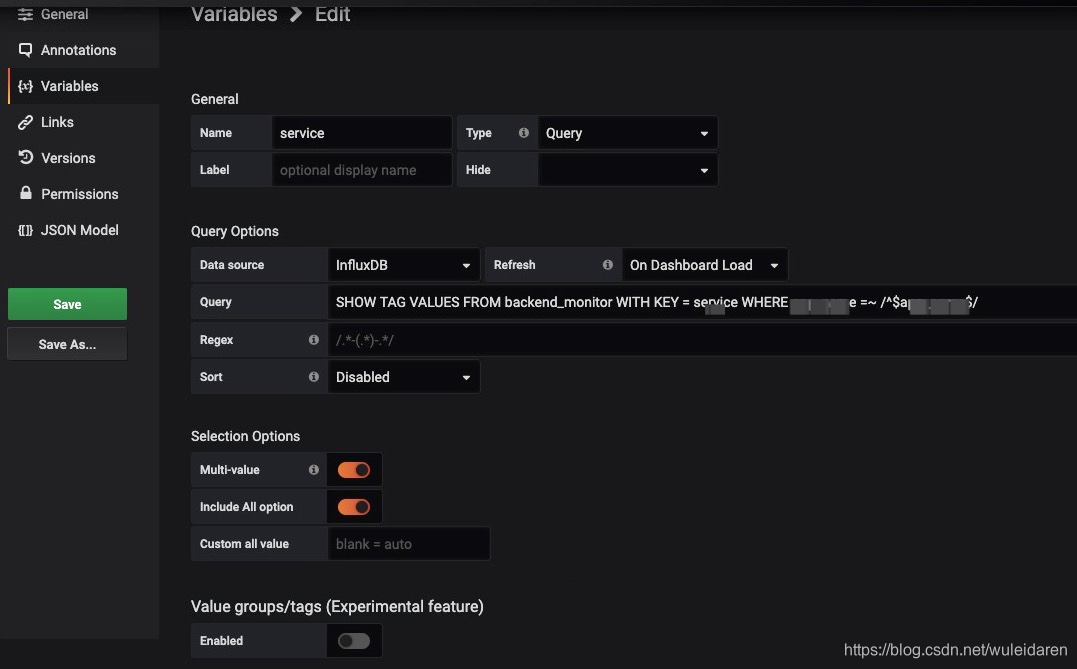
- variable配置,查询tag的value,并且与其他tag进行联动
- 配置variable后,若是variable参数过多,且开启了‘All’,则会导致‘get’查询时出现‘Network Error:
undefined(undefined)’的错误,原因是因为get查询的长度是有限制的,可以将Custom all value 配置为.*
并且保存Dashboard,查看Query Inspector.。可以参考:https://github.com/grafana/grafana/issues/8109
2.2.2 错误总结
- time、tags构成唯一,如果time和tags在两条数据中重复,则只会插入一条
- insert时需要注意除非是在tag和field之间需要一个空格以外,其他地方加空格会报错,如果measurement后面加了空格,报错,如图:

- 类型不匹配。工程中用的Java基本类型是String时,如果需要手动insert对应字段则需要加双引号,否则报错,如图:

- 若新插入数据的time在influxdb的时间保留策略之外,会出现错误:‘Apr 14, 2020 2:21:15 PM org.influxdb.impl.BatchProcessor write SEVERE: Batch could not be sent. Data will be lost org.influxdb.InfluxDBException: {“error”:“partial write: points beyond retention policy dropped=1000”}’。 特殊情况是插入的time是精确到秒时也会出现这个错误。
