标题为什么要分层
数仓的分层不能为了分层而分层。
数据仓库的特征在于面向主题、集成性、稳定性和时变性,用于支持管理决策。数据仓库的存在的意义在于对企业的所有数据进行汇总,为企业各个部门提供统一的、规范的数据出口。数据仓库在构建过程中通常都需要进行分层处理。业务不同,分层的技术处理手段也不同。
数仓分层的主要原因:
清晰数据结构
每一个数据分层都有它的作用域,这样在使用表的时候能更方便的定位和理解。
数据血缘追踪
由于最终给业务呈现的是一个能直接使用的业务表,但是表的数据来源有很多,如果有一张来源表出问题了,我们希望能够快速准确的定位到问题,并清楚他的危害范围。
减少重复开发
规范数据分层,开发一些通用的中间层数据,能够减少极大的重复计算。
复杂问题简单化
将一个复杂的任务分解成多个步骤来完成,每一层只处理单一的步骤,比较简单和容易理解。而且便于维护数据的准确性,当数据出现问题之后,可以不用修复所有的数据,只需要从有问题的步骤开始修复。

ODS层:贴源层,贴近数据源的意思,保留原有数据模型,存放增/全量数据/历史数据,同时完成半结构化数据结构化。ODS层为了最真实的还原历史状态和防止数据丢失,历史分区是不会被修改的(最好也不要删除历史数据),为了防止出现这种情况,有些数仓的ods层是挂的外表的。(为了统一入仓策略,有些数仓会加一个staging层,将数据通过监听binlog的方式写入staging层,既能满足离线入仓也能满足准实时入仓的能力);
CDM层:数据公共层,这层是维度建模的核心,包含DWD明细层、DWS轻度汇总层、DIM维度层,我们常听到的公共逻辑下沉、一致性维度、明细大宽表、汇总大宽表、星型/雪花模型等都在这一层。
ADS层:数据应用层,follow数据应用需求,计算复杂的计算指标或者明细来提供数据能力。
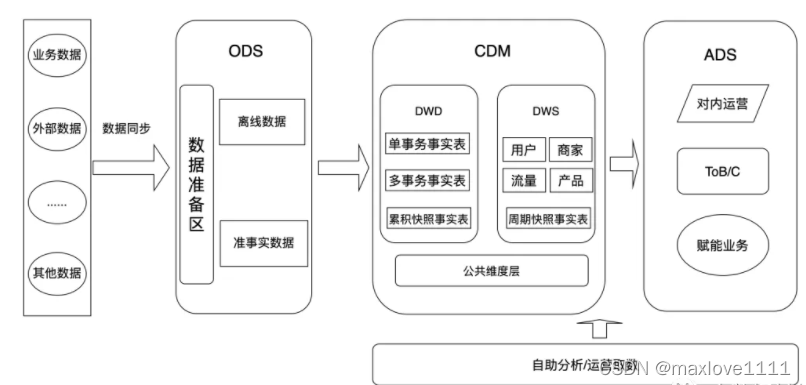
ODS层;
CDM层:
DWD明细层:根据业务过程生成事务性事实表和累积快照事实表,其中事务性事实表又分成单事务/多事务事实表,这些事实表都是明细,我们在设计的时候可以尽可能的衍生事实表的事实和属性,但是最好不能跨主题(比如交易事实表里面冗余营销域的补贴事实是不应该的);

DWS轻度汇总层:根据主题域的划分,生成周期快照事实表,将可复用的最细维度指标计算好放在这里,所以叫轻度汇总,尽可能的将同主题域/同维度/同计算周期的指标放在一起,尽可能的冗余维度属性;
DIM维度层:抽象维度,衍生、退化维度属性。
ADS层,针对不同的应用,个性化组合和计算派生/计算指标或者明细。常见应用场景有如下几种
ToB/C的数据产品:比如生意参谋,这种数据产品是直接给B/C端用户使用,所以用户保障级别较高;
对内运营:比如数据门户/用户大盘/流量大盘等,对内看数复杂性更高。
赋能业务:直接参与业务功能,比如常见的推荐系统、用户画像、电商工单系统的自动完结校验场景等。
Question
1,CDM层有DWS汇总层,ADS层也有汇总结果,那么这两层区别是什么?
2,事务/周期/累积快照事实表分别是上面哪层上的实现?
3,公共维度层如何设计?
4,数据分析师、运营如何参与取数?
Answer
1,CDM中的DWS汇总层是轻度汇总,最细维度的统计指标,比较稳定且复用性强。而ADS的汇总是follow数据应用需求,同一个维度在不同的模块,就会有不同应用表,所以数据应用是不稳定的,多变的;
首先公共逻辑下沉并不单单指指标计算的公共逻辑,还包含明细衍生、维度属性退化等逻辑的退化,公共指标逻辑下沉到dws层,公共维度属性退化或者扩展逻辑下沉到DWD和DIM层;
2,事务性/累积快照性事实表是在DWD层实现,周期快照事实表是在DWS层实现;
3,公共维度层设计主要需要考虑主维度的生成(根据数据矩阵),维度属性的扩展/拆解、维度的退化等等;
4,数据分析师、运营一般也是有探查数据的能力的,不过他们一般都只给CDM和ADS的权限;
ads应用层,为了得到ads的结果数据,需要通过业务数据计算,但是业务数据分落在不同的业务系统,需要把这些分散的数据集中到数仓,那就出现了ods层,中间的计算就在cdm层。