风控数据—手机App数据挖掘实践思路
引言
作为移动互联网时代的主要载体,智能手机逐渐成为人们日常生活中不可或缺的一部分,改变着人们的生活习惯。比如,可以用“饿了么”点外卖,“支付宝”可以用来种树,“抖音”可以用来上厕所......强大的App给我们的生活带来了巨大的便利。
 图 1 - App的正确打开方式
图 1 - App的正确打开方式
正因为如此,App与用户之间存在着密不可分的联系,用户在频繁使用这些App过程中也积累了大量的个人历史数据。这些App数据能帮助我们更好地去理解用户,推测用户的性别、职业、收入、兴趣、偏好等属性,也就是所谓的KYC(Know your customer)。
在风控中,App数据也有其重要价值,常用于反欺诈、风控建模特征工程等。本文将分享App数据的一些挖掘思路,以及实践建议。
首先,让我们思考下几个问题:如何获取数据?数据长啥样?数据如何和业务相结合去理解?可以采用什么算法实现高效提取信息?如何利用这块数据服务业务?
接下来为大家慢慢揭开App数据的庐山真面目。
目录
Part 1. App数据长啥样?
Part 2. App如何有效分类?
Part 3. App 分类统计类特征
Part 4. App one-hot特征
Part 5. 基于App安装列表的item2vec特征
Part 6. 基于App安装序列的app2vec特征
Part 7. 基于App名称的语义召回
致谢
版权声明
参考资料
Part 1. App数据长啥样?
根据资料显示,当前手机App数据主要包括:App安装包名称、App中文名、App安装列表、App安装序列。
为便于区分,常把App中文名记为app_name,App包名称(package)记为pkg_name。其中pkg_name是App的唯一ID,app_name则因为下载渠道、版本更新、数据采集等因素影响导致不唯一。例如,"企业微信"的pkg_name为“com.tencent.wework”,而app_name可能会有“企业微信”、“微信企业版”、“微信(企业版)”等多个值。
至于如何获取手机App package?可以参考这里:实现获取appPackage和appActivity的方法
 图 2 - App安装包名与中文名
图 2 - App安装包名与中文名
- App安装列表(App List):指手机上安装的所有App的集合,一般用逗号隔开,如:“com.alibaba.android.rimet,com.tencent.mm,com.citiccard.mobilebank,com.icbc,com.hongxin1.rm”。可以认为是一个集合,因此是无序的。
- App安装序列(App Seq):指手机上包含安装时间的App序列。如:["微信","1558014854044","com.tencent.mm",,"7.0.4"],分别代表App中文名、App安装时间戳、App包名称和版本号。由于可根据安装时间戳得到安装顺序,因此是有序的。
我们拿“微信”的package在腾讯应用宝中检索,那么就可以找到以下App描述数据:
- 分类标签:标签精确表达了App的核心功能。但可能是开发者在发布App时从可选项中主观选择了一个标签,也有可能腾讯会在后期维护标签。标签不一定准确,但可作为一个重要的参考维度。
- 下载量:可作为判断App是否小众的一个参考维度。然而,能在应用宝上架的App一般是合规的;对于一些质量较差无法上架的app就无法获取到下载量。
- 应用描述:开发者对App的主要功能给出的描述性文本,可提取关键词、主题等内容。但如果只是根据关键词匹配,很容易出错。比如微信中藏有游戏中心入口,文本中出现“游戏”关键词,但这并不是一个游戏类App。
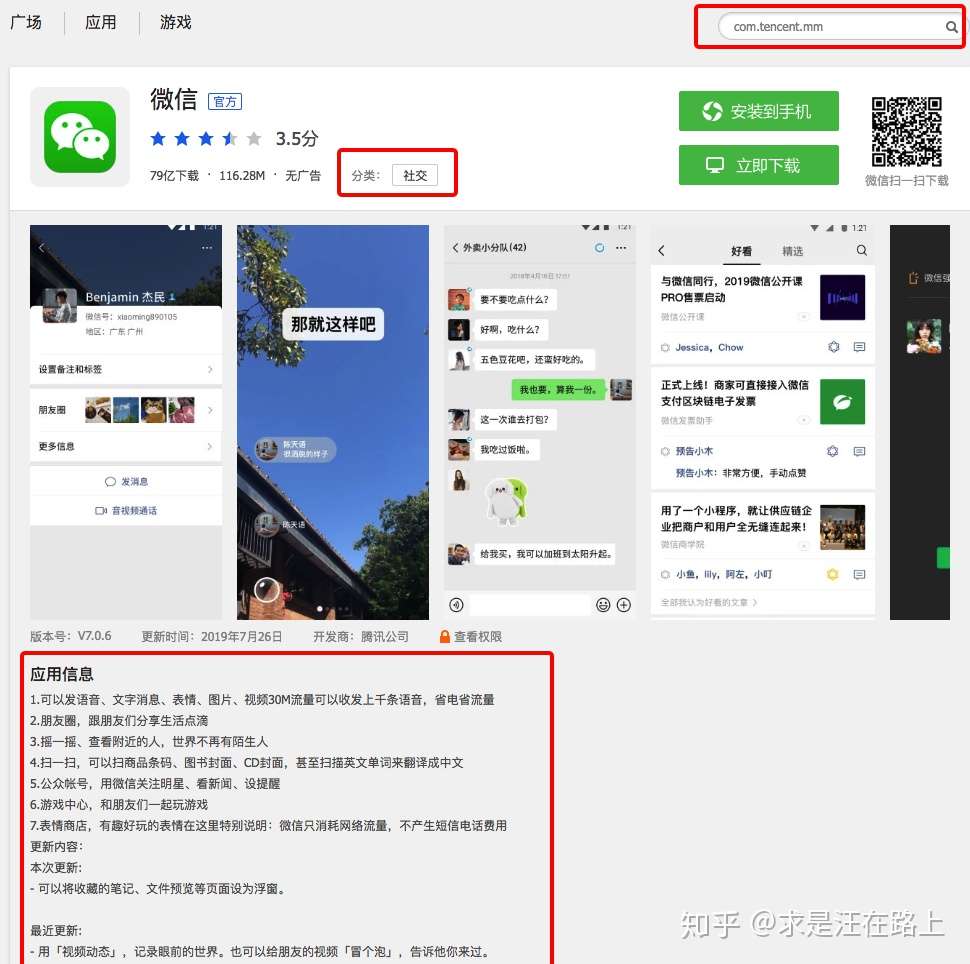 图 3 - 腾讯应用宝快照
图 3 - 腾讯应用宝快照
Part 2. App如何有效分类?
作为一个有逼格的命题,我们一开始就得想是不是该建立一个分类指标体系?下图是应用宝的App分类,其中有值得我们参考的内容。比如,直接把分类拿过来作为一级目录,进而再去思考二级目录,甚至三级目录,实现App多级目录精细化管理。
事实上,我们在实践中会发现这种分类体系下的App覆盖率很低,大量App依然“逍遥法外”。因此就需要针对特定场景进行补充类别。例如,反欺诈场景中主要关注一些负面App,包括:赌博类、借贷类等等。
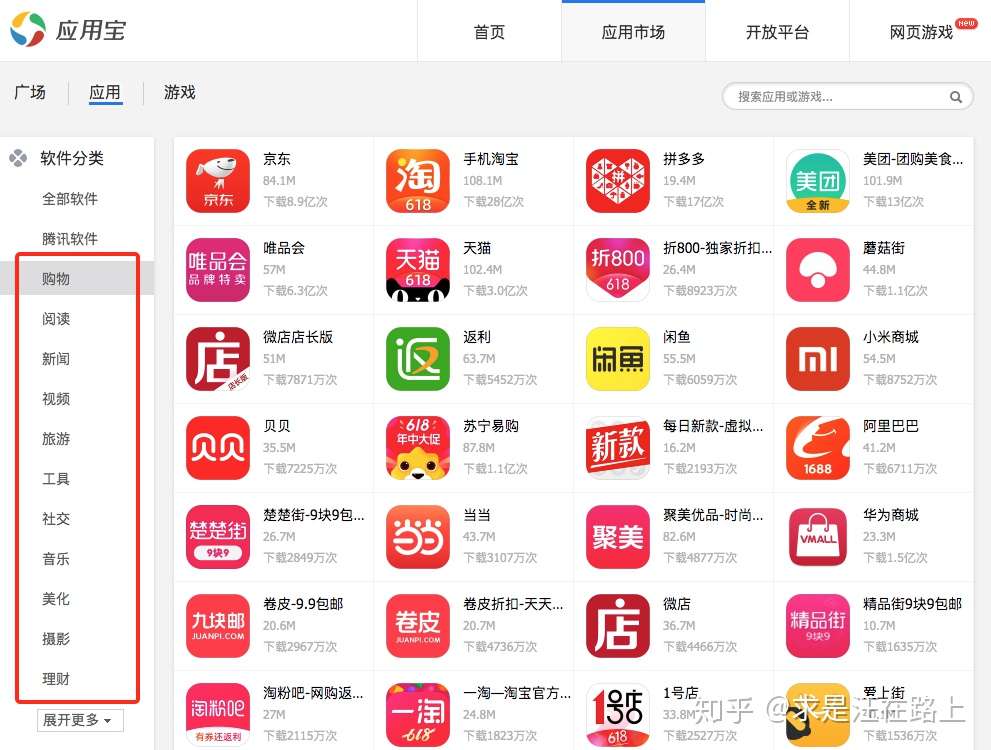 图 4 - 应用宝App分类
图 4 - 应用宝App分类
这个分类指标体系工作量显得比较庞大,适合规划长期项目。那么,我们先以反欺诈中的一个小场景入手。比如,当遇到这样的需求:最近案件调研发现逾期用户安装某类App比较多,找了一批种子App,希望扩散挖掘出更多的App,做成策略规则使用。
接到这种需求,我们一般会怎么做呢?。根据种子App人工观察提取特征,比如:看看前缀是不是同一家公司出品?看看中间是否明显有一些局部特征?看看后缀是不是一样?例如,在挖掘借贷类App时,package中常会出现“hua(花)、jieqian(借钱)、koudai(口袋)、daikuan(贷款)、qianbao(钱包)、bao(包)、loan(借贷)、qianzhuang(钱庄)”这类的包特征。作为一个合格的SQL工程师,拿出必备的正则表达式,匹配找出符合这一模式的app,人工核验筛选入库。搞定!✌️
这个流程完美诠释了:人工智能 = “智能”不够,“人工”来凑。
这种方法强依赖于人力跟进。不过当你接到需求时,脑袋一片空白,那么可以考虑这种方法来做,至少足够应付业务需求。但是我们并不满足这种低效的方法。尤其是业务爸爸每隔一个月让你迭代更新一版的时候,估计你内心是拒绝的。所以,我们来一场头脑风暴,从算法角度谈谈如何来做这件事?
首先,我们回到已有App数据,思考下可以提取什么特征?有了特征,有了种子App作为正样本,就可以用有监督算法帮助我们进行分类了。
- package如何提取特征?
- 字母统计类:package本质是由26个英文字母组成的,那么我们可以统计各个字母出现的次数、占比、熵。这种词袋模型(Bag-of-words)并不考虑上下文,因此损失了这部分信息。这类特征可能很弱,但作为潜在有用的特征,我还是列在这里。
- ngram切片:此时我们考虑上下文信息,切片相当于对上下文进行采样。如果我们限定切片窗口长度为W,package长度为M,那么就可以切片出M-W+1个片段。例如,对于zifu.payment,设定长度为4,我们可以得到以下片段:zifu、ifu.、fu.p、u.pa、.pay、paym…… 这些片段是package的局部特征。当然,你会发现这时就出现特征维度爆炸 ,所以就要考虑通过TF-IDF等方法来筛选特征。
2. app name如何提取特征?
- 关键词:可以通过分词,统计各关键词出现的次数。比如,我们想挖掘借贷类App,那么就可以统计app name中是否出现“钱”、“包”、“极速”、“下款”、“花”等关键词。
- 词向量:如果我们把app name看作一个单词,那么就可以根据一批用户的App列表来训练词向量。下文将会介绍。
3. app 描述信息如何提取特征?
- 通常可使用分词(比如jieba、TextRank)、word2vec训练词向量等文本处理算法来提取特征。
不知道大家有没有注意到罗列的顺序?这里是考虑到数据覆盖率在逐渐减少:package覆盖率100%,而app name覆盖率则可能会下降至50%,App描述信息覆盖率可能就只有10%了。
因此,我们只能在package上多思考如何挖掘更多的特征
算法的选择
此时,我们还会注意到:正样本(Positive)很少,大量样本是属于无标签(Unlabeled)的。很明显,无标签样本中隐藏着很多“正样本“,只是我们不知道罢了。那么,直接利用有监督算法会不会有问题?作为一种有效的思路,我们可以基于主动学习(Active Learning)+ PU Learning框架来帮助我们提升算法的性能。
主动学习主要考虑到以下几个问题:
- 样本对模型训练的贡献是有优劣差异的。例如,练习1+1=2的习题和微积分的题目,对于提高数学功底的贡献肯定不一样。因此,我们需要为模型筛选出含金量高的样本。
- 模型性能提升曲线是符合S型的,也就是说,随着样本量不断增加,模型性能的增益会越来越少。但实际中,人们总是觉得样本量越多越好。虽然这种直觉通常是可靠的。
- 样本标注需要花费大量人力时间。这就告诉我们,不能人工埋头搬砖,要有目的性搬砖。
在以上约束下,主动学习告诉我们要人机结合,迭代优化。在此不展开赘述,可以参考蚂蚁金服 发表的一篇佳作。后续也将分享这块的实践应用。
分享|主动学习与半监督算法结合在支付宝风控的应用mp.weixin.qq.com
Part 3. App 分类统计类特征
根据App分类名单库,我们就可以统计下用户最近N天(7、30、60、90、180)内安装某类App的数量和占比,生成最基础的风险特征。
接下来,我们可以作为策略规则,或者作为特征输入风控模型使用。这种变量实现简单、业务可解释性强,通常也能达到不错的效果。
Part 4. App one-hot特征
想必大家都非常熟悉one-hot编码,在推荐场景(比如CTR预估)中常把商品item进行one-hot编码后输入LR模型。这种方案经常能达到不错的效果,主要原因在于样本量足够大。
然而,业务场景常常会限制算法的应用。在风控场景中,样本量相对较少,如果item过多(比如达到100w+),没有足够的样本量拟合LR模型的参数估计,就会导致估计出的参数不可靠。因此,我们需要进行降维——对app进行筛选。这也是one-hot特征的核心。
那么如何筛选App?常见的方案有以下几种:
1. 基于安装用户量
我们可以取最近几个月的内的活跃安卓用户进行分析,统计每个App的安装用户量,降序排列后取Top N。这种方案最为简单直接,但其不足在于忽略了很多小众App,只保留了QQ、微信、支付宝、淘宝这类大App。这就会导致大部分用户的one-hot特征向量都是相似的,也就无法区分风险。
但我们注意到,小众App反而更能反映风险。比如某用户安装了一个最近1个月出现的714高炮App,说明最近出现资金短缺的趋势,不得不去撸高炮口子。但是,由于这类App很小众,根据安装用户量来筛选的话,大概率会不会被选中。另一方面,小众App的生命周期短。有些App可能这个月出现,过几个月就彻底消失了。
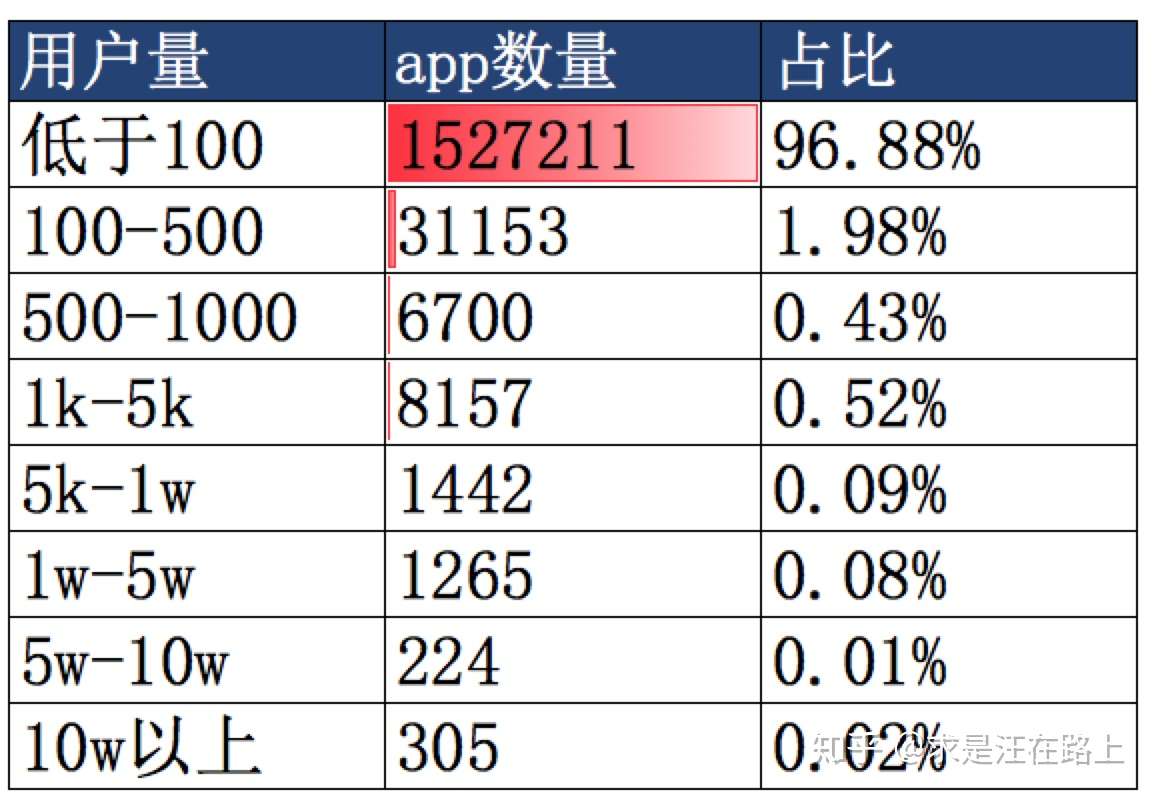 图 5 - App安装用户量分布
图 5 - App安装用户量分布
2. 基于TF-IDF值
TF-IDF的主要思想是:如果某个单词在一篇文章中出现的频率TF高,并且在其他文章中很少出现,那么认为此词或者短语具有很好的类别区分能力,适合用来分类。
词频(Term Frequency,TF)表示词条(关键字)在文本中出现的频率。TF值越大,说明越能代表这篇文本。
逆向文件频率 (Inverse Document Frequency,IDF) :某一特定词语的IDF,可以由总文件数目除以包含该词语的文件的数目,再将得到的商取对数得到。如果包含词条t的文档越少, IDF越大,则说明词条具有很好的类别区分能力。
因此,我们可以用来选择一批用户的App安装列表来计算TF-IDF。那主要问题就在于如何定义“文章”?由于一个用户的App列表是无序不重复的,那么就可以把一批用户的App列表组合起来看作一篇文章,用以计算TF。也就是:
TF = 安装某App的逾期用户数 / 所有逾期用户数。用以衡量该App对于逾期风险的代表性。
IDF = Log(所有用户数 / 安装某App的用户数)。用以衡量该App安装的普遍性。
3. 分箱(binning)合并
我们会发现,以上2种方案可能还是不能很好解决筛选的难题,那么就可以考虑分箱策略:
1) App需要去除版本号。不同版本号App版本本质上属于同一个。
2) 对于已经分类,具有具体业务含义的app单独成一个分箱;但对于微信、QQ这类用户量大的App,可考虑一个App单独成箱。
3)对于安装人数少于N的App合并为一个分箱。
4)对于安装人数大于N的App,根据贷后定义某个bad指标计算woe值。先按等距均分,将woe值相近的小分箱进行合并。后续考虑不等距,对woe曲线平缓部分,增大间距;反之,减小间距。
5)检验分箱的稳定性。跨时间窗统计各箱里的app占比是否稳定。
需要指出的是,one-hot特征仍然存在着稀疏性、缺少非线性等问题。FM算法可作为一种解决方案。
Part 5. 基于App安装列表的item2vec特征
item2vec借鉴了word2vec的思想,学习item在低维隐含空间的嵌入表示(embedding)。其理论介绍可参考其他文章。这里主要介绍如何实践,下面是实施步骤:
- 数据准备:随机打乱App列表,得到若干App序列。如果我们考虑用户手机App列表是一个购物篮,那么每个App就可以看作item。为了营造上下文环境,我们可以选择随机打乱这个篮子。例如,对于App列表“app1,app2, app3,app4”,我们可以得到“app2,app1, app3,app4”、“app2,app3, app1,app4”等等。
- 算法调用:调用word2vec,得到App词向量。由于步骤1中已经得到了序列,那么就可以调用gensim算法包中的word2vec,训练App的词向量。作为一个合格的调包侠,你还是得去理解embedding_size、skip_window、num_skips等参数的含义。
- 模型上线:这种特征上线后的最大问题是,由于App词向量表是离线预训练的,上线后容易衰减。因此,考虑如何加固(维持稳定)就显得尤为重要。
那么我们在实践中又该注意哪些事项呢?
1. 剔除预安装的App。大多安卓手机在出厂时都会由厂商预先安装一些App,然而这些App并不能反映用户的属性,反而会引入噪声。因此,需要根据手机品牌和型号,维护一个厂商预安装App名单库。例如:
小米手机预安装App列表(不完全):com.xiaomi.midrop,com.miui.calculator,com.miui.cleanmaster,com.xiaomi.scanner,com.xiaomi.pass
oppo手机预安装App列表(不完全):
com.oppo.camera.raw,com.oppo.camera.professional,com.oppo.pcassistant,com.oppo.camera.microspurmode
2. 小众App分箱处理。分箱(binning)可以提高变量鲁棒性,但同时也会带来信息损失。但这点可以提高词向量的稳定性。
3. 用户App列表样本筛选。实践中发现训练词向量的用户样本是很重要的。另一方面,训练过程计算量大(10w用户的App列表训练时间达到4~5小时),因此有必要进行采样。
在得到App的词向量后,我们可以如何使用呢?这里列出了2种思路:
1)App向量化后,计算不同App的相似度。根据种子App召回更多的目标App。
2)App向量池化(pooling),聚合到user维度,作为用户特征。
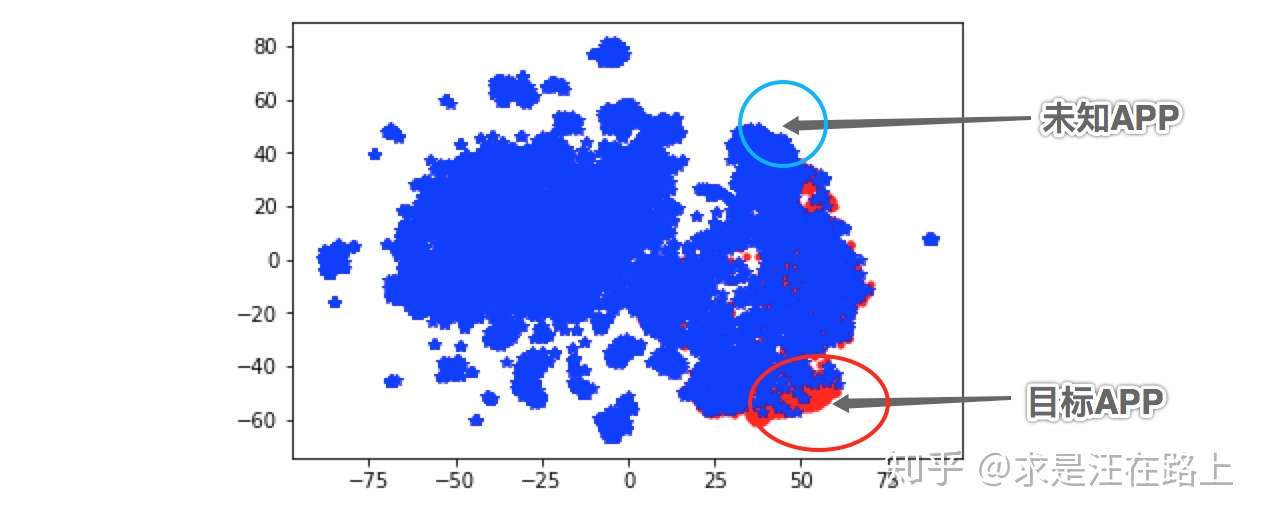 图 6 - App词向量聚类效果
图 6 - App词向量聚类效果
在上图中,我们发现目标App基本都聚类在一起,说明训练出的词向量能有效反映App的特征。那么,对于目标App邻居的未知App(蓝色区域),我们有理由相信其是目标App的概率较大,就可以从邻居中召回更多的目标App。这是一种可视化的App挖掘方式。另一方面,我们也可以借助算法来帮助我们分类。
Part 6. 基于App安装序列的app2vec特征
与item2vec不同,该特征构建的前提是我们拥有app序列数据。这种序列可以是下载序列、安装序列、使用序列等。
我们为什么要获取序列呢?如果说item2vec是把无序状态有意去打乱以构建上下文,那么app2vec所依赖的序列数据则是天然的上下文,这种上下文蕴藏着某种业务逻辑,例如用户行为偏好、app之间的关联性。
想象一个场景,当你用“相机”拍完照,再去打开“美图秀秀”,再去打开“微信”。这一串使用序列表示这几个App之间存在功能上的衔接性。当然,像微信这类的高频app(不知道每天大家要打开多少次?)在序列中还是得预先剔除以降低噪音。( 划重点:剔除高频App)
app2vec相比于item2vec,在数据预处理上多了一些操作:
1)将app安装时间先后进行排序,同时计算使用时间间隔,形成app使用序列:app1,gap1,app1, gap2, app1, gap3, app2,gap4,app3,gap4,...
2)考虑到目标是学到不同app之间的上下文, app使用序列处理为:app1, gap3, app2,gap4,app3,gap4,...
3)考虑不同gap之间的差异,引入上下文app的weight,例如:log(1 + gap)
Part 7. 基于App名称的语义召回
我们考虑这样一个场景,当你在搜索引擎 中查找一个关键词时,比如输入“周杰伦”,发现没有找到合适的内容,你还会重新输入“jay chou”。因为——内容主题是一样的,变化的只是描述词。
在App数据中也是相同的道理,同一个package(App的唯一ID)可能在不同时间点,不同渠道采集的App Name是不完全一样的。但是这些名称都是围绕App功能这一主题的短词。作为App分类的衍生品,可以用来建设目标词库(如赌博类、借贷类等)。有了词库之后,你就可以干很多事,比如:识别短信中是否含有赌博内容?
例如,“炸金花”这个App具有多个名称。哪怕没有接触过这个名词,但是可通过“棋牌”、“现金”、“大赢家”这些关键词推测出这是一个属于赌博类的App。
app_package:cn.xtgames.zjh
app_name:快乐炸金花,欢乐炸金花,全民炸金花,土豪赢三张,休乐炸金花,快乐三张牌,鑫途大赢家,炸金花,吉祥棋牌,红包现金三喜,全民扎金花